一、背景介绍
随着vivo业务迁移到容器平台,vivo云原生监控体系面临着指标量快速上涨带来的一系列挑战,本文将分享vivo 容器化项目中容器监控遇到的问题以及我们的解决和优化方法。
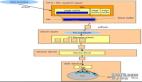
二、监控架构
首先对vivo容器监控架构进行一个简单的介绍。

- 【架构高可用】:集群维度的双副本 Prometheus 采集底层exporter数据,adapter多实例自动选主实现容灾。
- 【数据持久化】:通过remoteWrite将数据存储到后端的VictoriaMetrics中进行持久化存储,Grafana使用VictoriaMetrics做为数据源展示和告警。
- 【监控统一化】:通过remoteWrite将数据交由kafka-adapter转发到Kafka,由公司基础监控等服务通过消费Kafka中的数据来进行展示和告警。
原生Prometheus没有提供高可用的标准方案,我们通过自研 Adapter “分组选举”方式实现去重,即每个 Prometheus 副本对应一组 Adapter,两组 Adapter 之间会进行选主,只有Leader组的 Adapter才会转发数据。通过这种方式既实现了去重,也实现了Prometheus双副本高可用。
三、问题现象
过去几年来,vivo容器化服务快速增长,监控流量上涨数倍,我们主要遇到如下三个问题:监控组件负载快速升高、容器监控数据断点和数据存储组件负载陡增。

3.1 监控组件负载快速升高
容器化每次部署IP都会变化的特性,导致容器监控指标量相比物理机和虚拟机要高出好几个数量级。同时由于集群规模的不断增加以及业务的快速增长,导致监控 Prometheus、VictoriaMetrics 负载快速增高,给我们容器监控带来极大的挑战。监控总时间序列可以精简为以下的表达式,即与 Pod数量、Pod指标量、指标Label维度数量呈线性关系:
TotalSeries = PodNum * PerPodMetrics * PerLabelCount
而随着集群规模的不断增加以及容器数量的不断增多,监控序列就会快速增长,同时监控组件负载快速升高,会对容器监控系统的稳定性产生影响。
3.2 监控丢点现象
vivo容器层面(业务)的监控数据则通过自研Adapter转发给Kafka,进而存储到公司基础监控做业务监控展示和告警配置,同时也存储一份到Druid做更多维度的统计报表。我们在推送监控数据的时候发现,Pod维度的指标难以保证发送频率,即配置指标采集频率为 10s,但是在推送的数据中频率无法做到10s,且会有波动。下图为 采集频率设置 10s,查询1分钟的指标数据。
一分钟内某一容器的 container_cpu_user_seconds_total 指标的值:

可以看到只取到了4个值,与期望的 6个值不相符,即发生了“掉点”的情况,监控面板按指定频率展示数据会有频繁掉0现象。

3.3 数据存储组件负载陡增

vivo容器监控使用 VictoriaMetrics的v1.59.1-cluster版本做为后端时序数据库来持久化存储监控数据。在使用过程中发现 VictoriaMetrics的负载有不定期增高的情况,而后端数据库的延迟会导致监控查询告警功能的异常影响用户体验。
四、解法
4.1 监控组件负载快速升高
我们使用 Prometheus-Operator 管理 Prometheus,因为优化方案中有 Prometheus-Operator 相关的名词,故为了下面的理解,先对 Prometheus-Operator 做一个介绍:

上图是Prometheus-Operator官方提供的架构图,下面来介绍下图中各组件:
- Operator: Operator是最核心的部分,作为一个控制器,他会去创建Prometheus、ServiceMonitor资源对象,然后会一直监控并维持这些资源对象的状态。
- Prometheus:这种资源对象就是作为Prometheus Server存在, Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server。Prometheus 也可以通过 labelSelector 去匹配多个ServiceMonitor。
- ServiceMonitor:ServiceMonitor就是exporter的各种抽象,exporter是用来提供专门提供metrics数据接口的服务。Prometheus就是通过ServiceMonitor提供的metrics数据接口去 pull 数据的。该资源通过 Labels 来选取对应的 Service Endpoint,让 Prometheus Server 通过选取的 Service 来获取 Metrics 信息。一个 ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service。
- Service:Service是Kubernetes内建资源用于把一组拥有相同功能的Pod封装起来,并提供一个统一的入口来暴露这组Pod的服务,从而为客户端访问提供了一个稳定的访问地址,屏蔽了底层Pod的变化和故障。Service可以结合Kubernetes中的其他组件实现负载均衡、服务发现、集群内部通信等功能。
我们重点关注 ServiceMonitor,因为ServiceMonitor为我们提供了指定 target 采集的配置,例如采集频率,target内指标过滤,指标中label重命名等等操作。
对于监控组件负载快速升高问题的解决,我们主要从两个方面着手,分别是指标治理以及性能优化。
 图片
图片
4.1.1 指标治理
1、过滤未使用指标
第一个工作是过滤无用指标,Prometheus 会去从 Target 中去获取指标数据。每个 Target 下会有多个 endponit。每一个endpoint 又会提供几十上百个指标,而每个指标下的数据量也很大。但在生产环境中我们实际上用到的指标可能只有几十个,Prometheus采集过来我们又没有用到的指标就会浪费资源并降低监控系统的稳定性。因此我们需要对Prometheus 采集到的指标进行一定程度的过滤,从而减少资源的占用。
通过Prometheus提供的
scrape_samples_scraped指标对采集的 target进行分析找到采集样本量大的Target。
我们进行指标过滤主要就是关注这些数据量大的 target,在进行指标过滤之前需要收集 Prometheus所采集的所有指标数据以及当前监控告警面板以及相关依赖服务所使用到的指标。再根据采集的指标和正在使用的指标进行正则表达式的书写。最终在对应 target的 ServiceMonitor将正则表达式写入。Prometheus则会过滤掉我们不需要的指标。下面就是过滤 cAdvisor这个 target 的 container_threads 开头的指标的示例。
# 过滤 container_threads 开头的指标
- action: drop
regex: container_threads(.*)
sourceLabels:
- __name__完成指标精简后,监控单次采集样本量从 1000万降低到 250万。Prometheus 的CPU 使用量降低 70% ,内存 使用量降低 55%。



2、过滤低优先级 pod 相关指标
对精简后的指标进行分析,发现 Pod维度的监控指标占比为70%,且有相当比例的 Pod 是集群组件的 Daemonset的Pod。而Daemonset的Pod是随着集群规模的增加而增加的。
而对于大部分的集群组件Daemonset,因为设置了资源上限,我们不需要关注其资源消耗情况,只需要关注是否存活和正常提供服务即可。故可以对这部分 Pod 的指标进行一个精简,不收集这些 Pod的 memory、cpu 等容器监控指标。
一个 Daemonset 提供的 Pod 的 Namespace 是相同的,且Pod名称前缀相同。
# 名称为cadvisor的 daemonset 提供的 pod
cadvisor-xxxx1 1/1 Running
cadvisor-xxxx2 1/1 Running且 cAdvisor 提供的指标中包含了 namespace 和 pod 的 label。
container_memory_cache{cnotallow="POD", namespace="monitoring", pod="kube-state-metrics-xxxx-xxxx", service="cadvisor"}所以我们通过在 ServiceMonitor 上面组合指标的 pod 和 namespace,并与指定的规则进行匹配丢弃掉我们不需要的 daemonset pod 的序列。
# 过滤掉 monitoring namespace 下面 telegraf 这个daemosnet提供的 pod 的相关指标
- action: drop
regex: monitoring@telegraf(.*)
separator: '@'
sourceLabels:
- namespace
- pod在对集群中部分ds Pod 的指标进行过滤后。

对 cAdvisor 的单次采集数据量下降 70%。效果十分明显。
4.1.2 性能优化
1、均衡 Prometheus 负载
vivo 容器监控架构中最核心的组件就是 Prometheus了,而 Prometheus 也是日常出现问题最多的一个组件,因为 Prometheus 不仅是需要采集数据,还需要将数据通过remote_write的方式推送的VictoriaMetrics 和 Kafka中。
 图片
图片
将监控 target 进行分类交由不同的组 Prometheus 采集,且每类 Prometheus 为双副本模式。随着集群规模的增加,发现当前模式的不合理之处,即因为Pod维度监控数据量级十分高,导致container 类型 Prometheus 负载远远高于其他类型的 Prometheus。在高负载的情况下面会发生重启,remote_write 异常等情况。
我们 Prometheus组件架构为按类型采集监控指标。其中 Container类型的 Prometheus采集的指标数量远远大于 Component、Host、Resource类型。故需要手动平衡 集群中 Prometheus的负载 将集群的 container类型 Prometheus上面kubelet 和 kube-state-metrics 转移到 resource-Prometheus 上面 降低 container-Prometheus负载。(与此同时resource-Prometheus也会发送到 kafka-adapter)。且在负载低的Prometheus上 监控跳转面板用到的监控指标(核心指标)进行重复采集,尽可能防止数据丢失。降低了container-Prometheus 40%的负,极大的减少了Prometheus异常情况的发生。
2、减少Prometheus存储数据时间
我们的第2个修改点在 Prometheus的数据存储时间上,Prometheus的默认存储时间为2周,后续测试发现 Prometheus的存储数据时间对内存的影响很大,且现在监控数据的持久化存储都放在 VictoriaMetrics 上面,Prometheus存储的数据主要用于排查问题,不需要承担持久化存储的任务。故我们修改Prometheus采集的数据本地存储时间从7天改为2天。Prometheus 内存消耗降低 40%。

4.2 监控丢点现象
4.2.1 问题定位
最初我们认为是 Prometheus 在remote_write 的过程中发生了丢点的情况,但是通过在社区查询和配置问题Prometheus 远程写相关的监控指标发现Prometheus并没有在远程写的时候丢弃数据,且发现在推送数据的过程中只有kubelet 内置的 cAdvisor提供的数据有"丢点"的情况。 故我们开始研究指标提供端组件 cAdvisor,发现cAdvisor”丢点”问题的原因在于 cAdvisor 组件有自己的刷新频率 和 时间戳。cAdvisor 会去 cgroup 中读取数据并存储到内存中供外部使用。Kubelet的cAdvisor 的刷新数据频率达不到 10s,并且会根据刷新时间放到指标中。 而 Prometheus 按 10s 采集频率去采集数据时,底层的 cAdvisor 如果还没有去刷新数据,内存中则还是上次的数据。而cAdvisor 在0.31版本及之后的版本中添加了时间戳支持,即 cadvisor 提供的数据会带上自己的时间戳。当 Prometheus 去采集 cadviosr数据时会以 cAdvisor提供的时间戳为准。故当 Prometheus 按照ServiceMonitor 设置的采集频率10s去采集cAdvisor 提供的数据时,如果在此期间 cAdvisor 没有进行数据更新,则Prometheus会采集到与上次采集时间戳和值相同的情况,Prometheus 就只会记录一条数据。这就是cAdvisor “丢点”的本质。cAdvisor的刷新频率由 housekeeping相关参数 和 抖动 机制确定。
kubelet 内置 cAdvisor设置的参数:
// Kubelet 内置 cadvisor 默认参数
// cadvisor housekeeping 的间隔,刷新数据的间隔
const defaultHousekeepingInterval = 10 * time.Second
// cadvisor 是否开启动态 housekeeping
const allowDynamicHousekeeping = true
/*
cadvisor housekeeping 的最大间隔,allow_dynamic_housekeeping=true的时候, 会判断容器活跃程度动态的调整 HousekeepingInterval, 当发现一段时间为容器状态为发生改变会将 housekeeping 的间隔 设置为maxHousekeepingInterval 。
*/
const maxHousekeepingInterval = 15 * time.Second4.2.2 解决方案
根据上面的分析,定位到无法保证指标频率的根本原因在于 cAdvisor 的默认启动参数,而目前我们采集的cAdvisor是内置于 kubelet 中的,如果要修改参数的话需要改动 kubelet。故综合考虑集群稳定性和维护成本等因素,我们决定以 daemonset 的方式部署一套cAdvisor,并根据需求设置 housekeeping 相关的参数来保证 cAdvisor 刷新数据的频率,并设置 Prometheus 采集 cAdvisor 数据的时候忽略 cAdvisor 自带的时间戳,即通过单独部署的 cAdvisor 提供Pod的监控数据并保证监控数据的频率。
我们的工作主要在部署 cAdvisor 和 修改对应的 ServiceMonitor。
1、部署 cAdvisor:主要是确定cAdvisor启动参数, 主要操作为禁用dynamic_housekeeping 和 设置 housekeeping_interval 为 1s,来保证 cAdvisor 获取数据的频率。
containers:// 参数设置
- -allow_dynamic_housekeeping=false
- -housekeeping_interval=1s2、创建对应的ServiceMonitor 让 cAdvisor 让Prometheus 忽略cadviosr自带的时间戳。(因为 cadviosr自身的抖动机制,频率无法固定)
cAdvisor的抖动机制:
// return jitter(cd.housekeepingInterval, 1.0)
func jitter(duration time.Duration, maxFactor float64) time.Duration {
if maxFactor <= 0.0 {
maxFactor = 1.0
}
wait := duration + time.Duration(rand.Float64()*maxFactor*float64(duration))
return wait
}cAdvisor的 ServiceMonitor上配置忽略指标自带时间戳
通过单独部署的 cAdvisor和 Prometheus 的忽略 cAdvisor 自带的时间戳,我们成功的解决了容器监控断点的问题,保证了监控的频率。
spec:
endpoints:
- honorLabels: true
// 忽略时间戳
honorTimestamps: false
interval: 10s可以看到再去采集 1分钟内的容器相关监控数据,是很标准的 6 个数据点。至此监控“掉点”问题解决。

监控面板展示数据连续,无中断现象发生。

4.3 后端数据库负载突增
4.3.1 问题定位
从监控架构图可以看到,我们使用社区 v1.59.1-cluster版本的VictoriaMetrics 作为监控后端的时序数据库,并在Prometheus 采集的数据后通过remote_write写入到时序数据库VictoriaMetrics中进行持久化存储,Grafana会从VictoriaMetrics 读取数据展示在对应的 Dashboard上面。而在我们的实际使用中发现,Prometheus 远程写入VictoriaMetrics有不定期延迟飙升的现象。
Prometheus写入VictoriaMetrics延迟

写入数据库延迟的飙升会导致,监控面板展示延时、监控误告警等一系列问题。
我们对 VictoriaMetrics的详细指标进行分析。发现 vmstorage 组件在底层执行 indexdb merge 操作的时候,其 CPU、内存等资源使用量会有一个突增, 即indexdb 的 Merge 操作非常消耗资源。

4.3.2 解决方案
正是由于VictoriaMetrics 这些的资源突增,导致自己负载过高,无法正常响应 Prometheus的 remote_write的数据。我们所期望的是在 indexdb merge 的时候,资源使用量的增长不会影响到正常的数据插入和查询。经过查询相关资源得到VictoriaMetrics在1.73.0版本中对indexdb的 merge进行优化,提升了整体性能。故我们对VictoriaMetrics 进行了版本升级以优化这个问题。在版本升级后,未发现 VictoriaMetrics 在indexdb merge时有资源突增的情况发生。

五、总结
在Kubernetes大规模使用的今天,以 Prometheus 为核心的监控系统已成为云原生监控领域的事实标准。原生Prometheus没有提供高可用和持久化存储的标准方案,vivo通过自研adapter实现了Prometheus双副本高可用,并将数据写入到VictoriaMetrics中实现了数据的持久化存储。而在业务规模的增长的过程中,监控数据量也在快速增长,对监控采集和存储组件都带来了不小的压力,当前我们通过降低数据提供端指标数量、优化采集组件参数、升级开源存储组件版本的方式,提升了监控系统的性能。
而架构的演变是随着业务规模的增长而不断的演变改进的,未来我们将结合业务实际规模优化监控架构提升容器监控整体性能。后续我们规划在监控采集、监控查询、监控数据提供三个方向继续提升提供系统性能:
- 【监控采集】:改进数据采集端架构,应用自动分片从而降低采集端压力。
- 【监控查询】:应用 PrometheusRule以降低常用查询耗时,提升监控查询体验。
- 【监控数据提供】:在exporter端降低数量从而更稳定提供的数据。