CPU Cache知识回顾
CPU 的高速缓存,通常可以分为 L1、L2、L3 这样的三层高速缓存,也称为一级缓存、二级缓存、三级缓存。
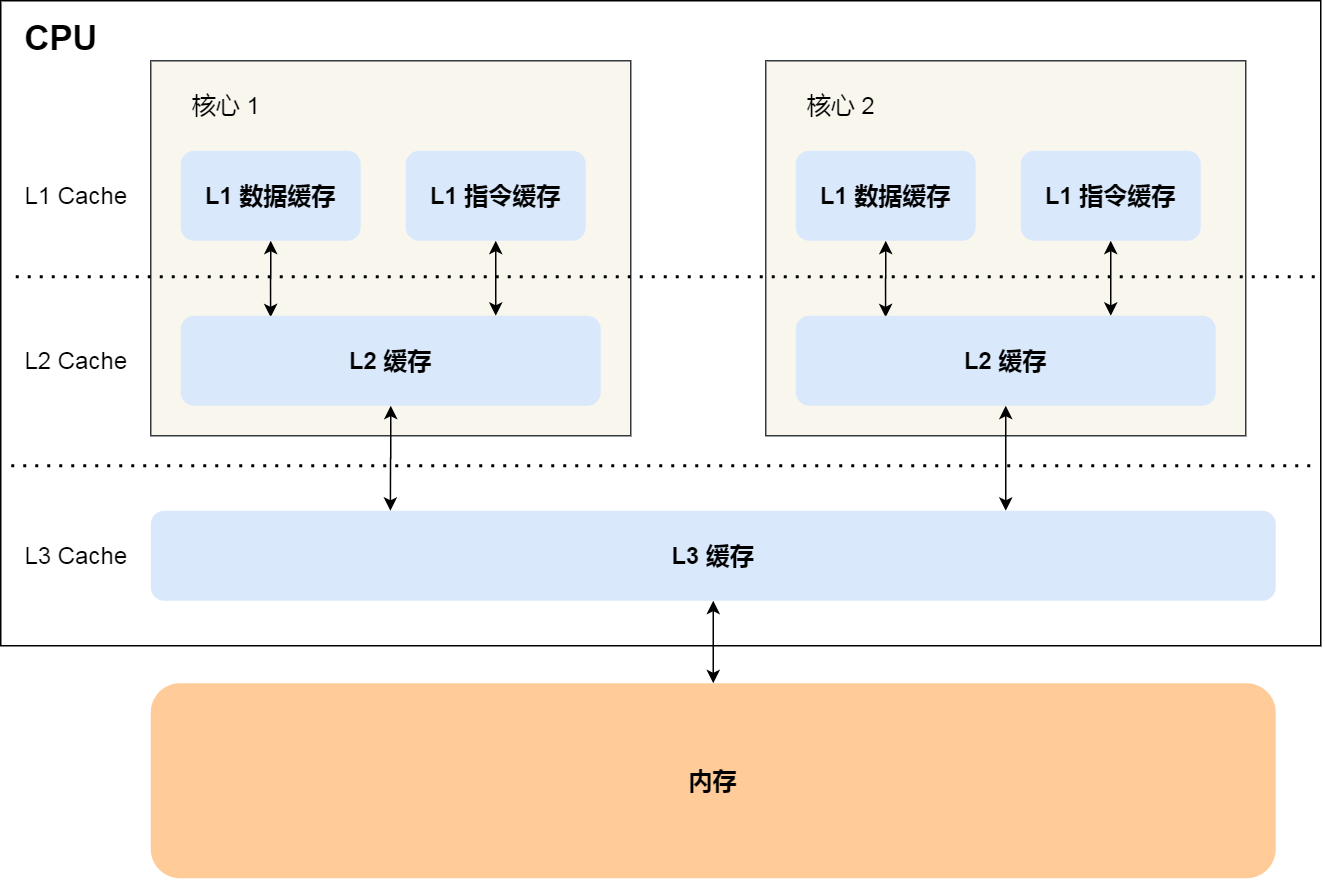
L1 高速缓存访问速度几乎和寄存器一样快,大小在几十 KB 到几百 KB 不等。每个 CPU 核心都有一块属于自己的 L1 高速缓存。
L2 高速缓存同样每个 CPU 核心都有,但是 L2 高速缓存位置比 L1 高速缓存距离 CPU 核心 更远,它大小比 L1 高速缓存更大,CPU 型号不同大小也就不同,通常大小在几百 KB 到几 MB 不等,访问速度则更慢。
L3 高速缓存通常是多个 CPU 核心共用的,位置比 L2 高速缓存距离 CPU 核心 更远,大小也会更大些,通常大小在几 MB 到几十 MB 不等。
cpu cache 结构
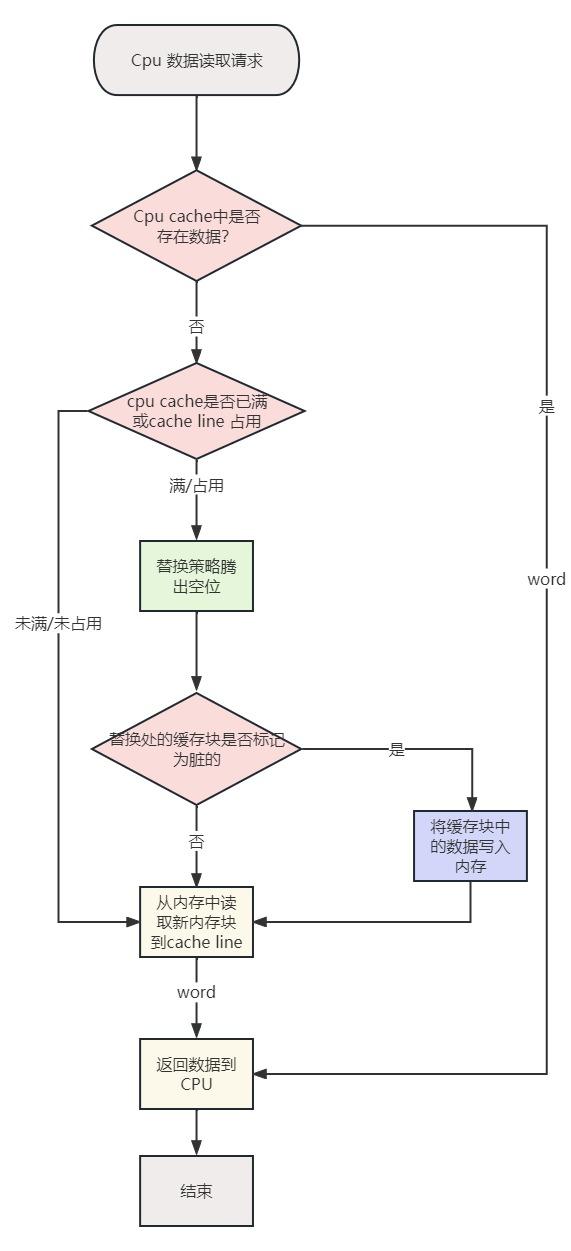
CPU Cache 是由很多个 Cache Line 组成的,CPU Line 是 CPU 从内存读取数据的基本单位,而 CPU Line 是由各种标志(Tag)+ 数据块(Data Block)组成,你可以在下图清晰的看到:

Cpu cache数据写入的两种方式
多核CPU同时工作的时候,每个核心都会从内存中读取一份数据并缓存到自己的Cache中,当发生写操作的时候,有两种情况
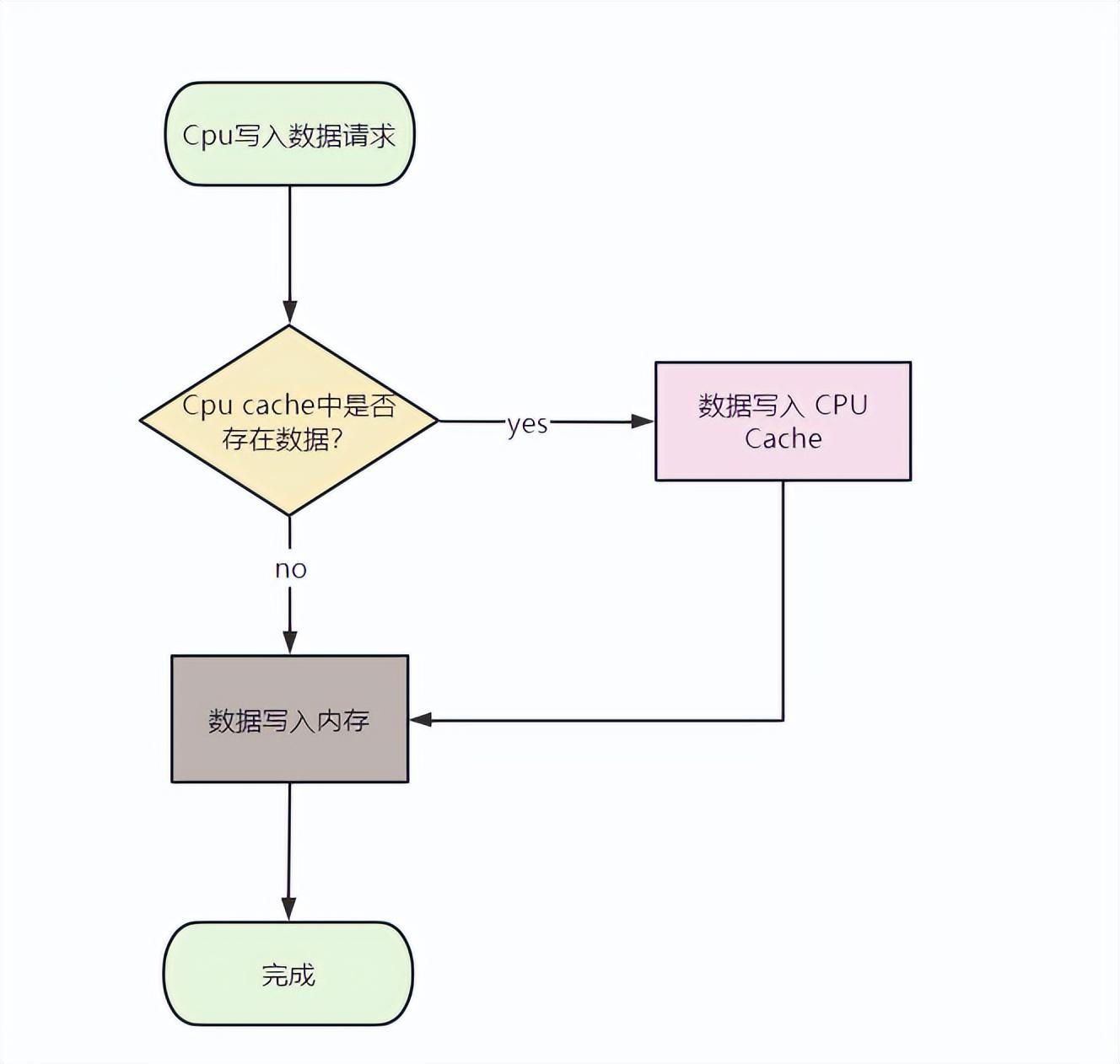
- 写直达:只要有数据写入,都会把数据同时写入内存和 Cache 中,这种方式简单直观,但是性能就会受限于内存的访问速度;
- 写回:对于已经缓存在 Cache 的数据的写入,只需要更新其数据就可以,不用写入到内存,只有在需要把缓存里面的脏数据交换出去的时候,才把数据同步到内存里,这种方式在缓存命中率高的情况,性能会更好;
写直达
写回
写直达由于每次写操作都会把数据写回到内存,而导致影响性能,于是为了要减少数据写回内存的频率,就出现了写回的方法。
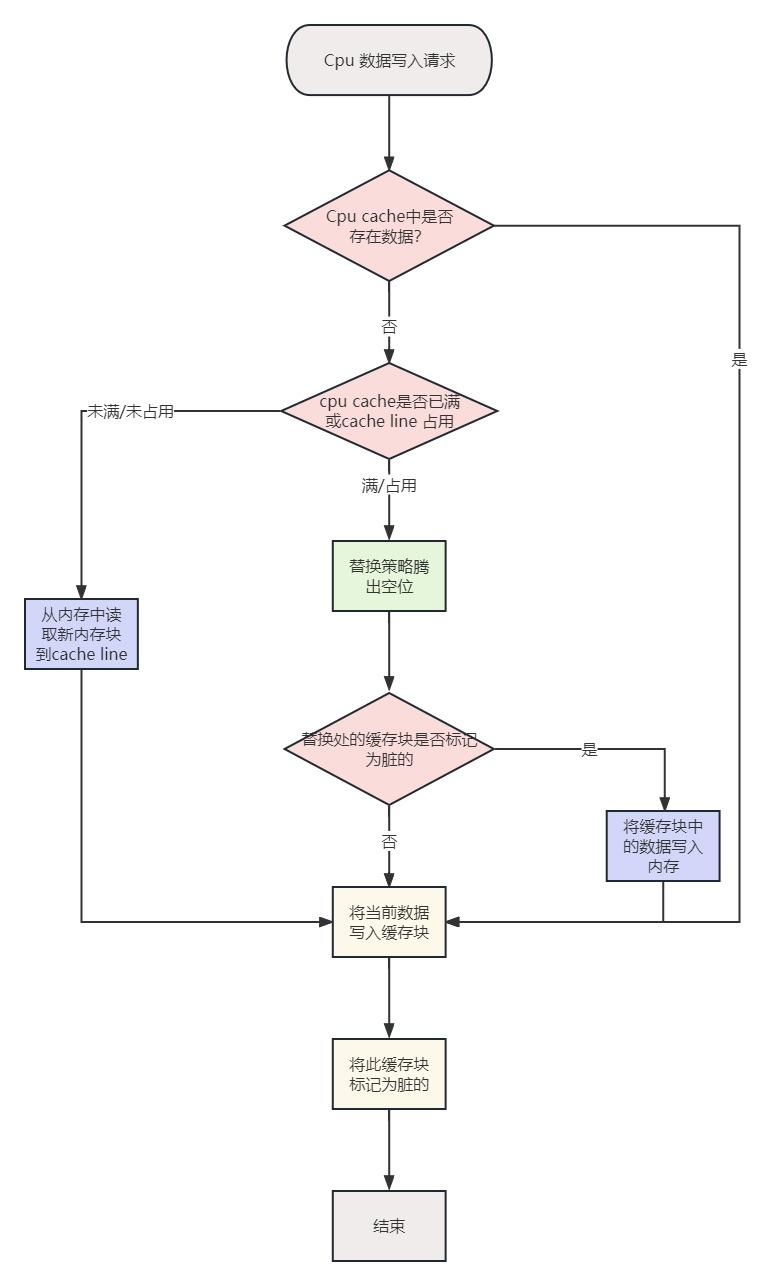
- 写回策略会在每个 Cache 块上增加一个 “脏(Dirty)” 标记位 ,当一个 Cache 被标记为脏时,说明它的数据与内存数据是不一致的;
- 在写入操作时,我们只需要修改 Cache 块并将其标记为脏,而不需要写入内存;
- 那么,什么时候才将脏数据写回内存呢?—— 就发生在 Cache 块被替换出去的时候:
写回策略能够减少写回内存的次数,性能会比写直达更高。当然,写回策略在读取的时候,有可能不是纯粹的读取了,因为还可能会触发一次脏 Cache 块的写入。
这里还有一个设计: 在目标内存块不在 Cache 中时,写直达策略会直接写入内存。而写回策略会先把数据读取到 Cache 中再修改 Cache 数据,这似乎有点多余?其实还是为了减少写回内存的次数。虽然在未命中时会增加一次读取操作,但后续重复的写入都能命中缓存。否则,只要一直不读取数据,写回策略的每次写入操作还是需要写入内存。
写回操作-写入逻辑
写回操作-读取逻辑
实现缓存一致性
在单核 CPU 中,我们通过写直达策略或写回策略保持了Cache 与内存的一致性。但是在多核 CPU 中,由于每个核心都有一份独占的 Cache,就会存在一个核心修改数据后,两个核心 Cache 不一致的问题。
举个例子:
- Core 1 和 Core 2 读取了同一个内存块的数据,在两个 Core 都缓存了一份内存块的副本。此时,Cache 和内存块是一致的;
- Core 1 执行内存写入操作:
在写直达策略中,新数据会直接写回内存,此时,Cache 和内存块一致。但由于之前 Core 2 已经读过这块数据,所以 Core 2 缓存的数据还是旧的。此时,Core 1 和 Core 2 不一致;
在写回策略中,新数据会延迟写回内存,此时 Cache 和内存块不一致。不管 Core 2 之前有没有读过这块数据,Core 2 的数据都是旧的。此时,Core 1 和 Core 2 不一致。
- 由于 Core 2 无法感知到 Core 1 的写入操作,如果继续使用过时的数据,就会出现逻辑问题。
由于两个核心的工作是独立的,在一个核心上的修改行为不会被其它核心感知到,所以不管 CPU 使用写直达策略还是写回策略,都会出现缓存不一致问题。 所以,我们需要一种机制,将多个核心的工作联合起来,共同保证多个核心下的 Cache 一致性,这就是缓存一致性机制。
写传播 & 事务串行化
缓存一致性机制需要解决的问题就是 2 点:
- 特性 1 - 写传播(Write Propagation): 每个 CPU 核心的写入操作,需要传播到其他 CPU 核心;
- 特性 2 - 事务串行化(Transaction Serialization): 各个 CPU 核心所有写入操作的顺序,在所有 CPU 核心看起来是一致。
总线嗅探 & 总线仲裁
写传播和事务串行化在 CPU 中是如何实现的呢?
写传播 - 总线嗅探: 总线除了能在一个主模块和一个从模块之间传输数据,还支持一个主模块对多个从模块写入数据,这种操作就是广播。要实现写传播,其实就是将所有的读写操作广播到所有 CPU 核心,而其它 CPU 核心时刻监听总线上的广播,再修改本地的数据;
可以发现,总线嗅探方法很简单, CPU 需要每时每刻监听总线上的一切活动,但是不管别的核心的 Cache 是否缓存相同的数据,都需要发出一个广播事件,这无疑会加重总线的负载。
事务串行化 - 总线仲裁: 总线的独占性要求同一时刻最多只有一个主模块占用总线,天然地会将所有核心对内存的读写操作串行化。如果多个核心同时发起总线事务,此时总线仲裁单元会对竞争做出仲裁,未获胜的事务只能等待获胜的事务处理完成后才能执行。
基于总线嗅探和总线仲裁,现代 CPU 逐渐形成了各种缓存一致性协议,例如 MESI 协议。
MESI协议
MESI 协议其实是 CPU Cache 的有限状态机,一共有 4 个状态(MESI 就是状态的首字母):
- M(Modified,已修改): 表明 Cache 块被修改过,但未同步回内存;
- E(Exclusive,独占): 表明 Cache 块被当前核心独占,而其它核心的同一个 Cache 块会失效;
- S(Shared,共享): 表明 Cache 块被多个核心持有且都是有效的;
- I(Invalidated,已失效): 表明 Cache 块的数据是过时的。
在 「独占」 和 「共享」 状态下,Cache 块的数据是 “清” 的,任何读取操作可以直接使用 Cache 数据;
在 「已失效」 和 「已修改」 状态下,Cache 块的数据是 “脏” 的,它们和内存的数据都可能不一致。在读取或写入 “已失效” 数据时,需要先将其它核心 “已修改” 的数据写回内存,再从内存读取;
「独占」和「共享」的差别在于,独占状态的时候,数据只存储在一个 CPU 核心的 Cache 里,而其他 CPU 核心的 Cache 没有该数据。这个时候,如果要向独占的 Cache 写数据,就可以直接自由地写入,而不需要通知其他 CPU 核心,因为只有你这有这个数据,就不存在缓存一致性的问题了,于是就可以随便操作该数据。
另外,在「独占」状态下的数据,如果有其他核心从内存读取了相同的数据到各自的 Cache ,那么这个时候,独占状态下的数据就会变成共享状态。
那么,「共享」状态代表着相同的数据在多个 CPU 核心的 Cache 里都有,所以当我们要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为「无效」状态,然后再更新当前 Cache 里面的数据。
事实上,完整的 MESI 协议更复杂,但我们没必要记得这么细。我们只需要记住最关键的 2 点:
- 关键 1 - 阻止同时有多个核心修改的共享数据: 当一个 CPU 核心要求修改数据时,会先广播 RFO 请求获得 Cache 块的所有权,并将其它 CPU 核心中对应的 Cache 块置为已失效状态;
- 关键 2 - 延迟回写: 只有在需要的时候才将数据写回内存,当一个 CPU 核心要求访问已失效状态的 Cache 块时,会先要求其它核心先将数据写回内存,再从内存读取。
提示: MESI 协议在 MSI 的基础上增加了 E(独占)状态,以减少只有一份缓存的写操作造成的总线通信。
写缓冲区 & 失效队列
MESI 协议保证了 Cache 的一致性,但完全地遵循协议会影响性能。 因此,现代的 CPU 会在增加写缓冲区和失效队列将 MESI 协议的请求异步化,以提高并行度:
- 写缓冲区(Store Buffer)
由于在写入操作之前,CPU 核心 1 需要先广播 RFO 请求获得独占权,在其它核心回应 ACK 之前,当前核心只能空等待,这对 CPU 资源是一种浪费。因此,现代 CPU 会采用 “写缓冲区” 机制:写入指令放到写缓冲区后并发送 RFO 请求后,CPU 就可以去执行其它任务,等收到 ACK 后再将写入操作写到 Cache 上。
- 失效队列(Invalidation Queue)
由于其他核心在收到 RFO 请求时,需要及时回应 ACK。但如果核心很忙不能及时回复,就会造成发送 RFO 请求的核心在等待 ACK。因此,现代 CPU 会采用 “失效队列” 机制:先把其它核心发过来的 RFO 请求放到失效队列,然后直接返回 ACK,等当前核心处理完任务后再去处理失效队列中的失效请求。
事实上,写缓冲区和失效队列破坏了 Cache 的一致性。
因为在未同步的情况下,程序可能会有多种执行顺序。这也是为什么Java里还需要volatile关键字,因为引入写缓冲区或失效队列后就变成弱数据一致性,不能满足 强数据一致性: 保证在任意时刻任意副本上的同一份数据都是相同的,或者允许不同,但是每次使用前都要刷新确保数据一致,所以最终还是一致。
总结
- 在 CPU Cache 的三级缓存中,会存在 2 个缓存一致性问题:
纵向 - Cache 与内存的一致性问题: 在修改 Cache 数据后,如何同步回内存?
横向 - 多核心 Cache 的一致性问题: 在一个核心修改 Cache 数据后,如何同步给其他核心 Cache?
- Cache 与内存的一致性问题有 2 个策略:
写直达策略: 始终保持 Cache 数据和内存数据一致,在每次写入操作中都会写入内存;
写回策略: 只有在脏 Cache 块被替换出去的时候写回内存,减少写回内存的次数;
- 多核心 Cache 一致性问题需要满足 2 点特性:
写传播(总线嗅探): 每个 CPU 核心的写入操作,需要传播到其他 CPU 核心;
事务串行化(总线仲裁): 各个 CPU 核心所有写入操作的顺序,在所有 CPU 核心看起来是一致。
- MESI 协议能够满足以上 2 点特性,通过 “已修改、独占、共享、已失效” 4 个状态实现了 CPU Cache 的一致性;
- 现代 CPU 为了提高并行度,会在增加 写缓冲区 & 失效队列 将 MESI 协议的请求异步化, 从内存的视角看就是指令重排,破坏了 CPU Cache 的一致性。也是为什么使用volatile关键字的原因