














纯文本大模型方兴未艾,多模态领域也开始涌现出多模态对话大模型工作,地表最强的 GPT-4 具备读图的多模态能力,但是迟迟未向公众开放体验,于是乎研究社区开始在这个方向上发力研究并开源。MiniGPT-4 和 LLaVA 问世不久,阿里达摩院便推出mPLUG-Owl ,一个基于模块化实现的多模态对话大模型。mPLUG-Owl 是阿里巴巴达摩院 mPLUG 系列的最新工作,延续了 mPLUG 系列的模块化训练思想,把 LLM 升级为一个多模态对话大模型。在 mPLUG 系列工作中,之前的 E2E-VLP 、mPLUG 、mPLUG-2 分别被 ACL2021 、EMNLP2022、ICML2023 录用,其中 mPLUG 工作在 VQA 榜单首超人类的成绩。本文将分享mPLUG的工作,即多模态对话大模型技术与应用解析。
https://github.com/X-PLUG/mPLUG-Owl。
一、多模态大模型技术发展历程
首先介绍一下多模态大模型技术的发展历程。ChatGPT4展现了非常强的多模态能力。在今年之前多模态的研究热点主要围绕在多模态预训练。

多模态预训练大概开始于18年前后,是多模态领域最重要的研究方向之一,并且在实际业务中有着非常广的应用场景。多模态预训练最经典的四个任务,比如VQA视觉问答,上传一张图片以及一个问题,就可以让机器回答出相关答案;ImageCaption,给一张图片,可以生成answer;还有跨模态检索,以及Visual Grounding。

刚开始的18,19年是基于检测特征的两阶段方法,包括UNITER,LXMERT等经典方法。2021年,进入了端到端的方法,包括CLIP、ViLT等。2022年开始尝试大一统的方法,通过一个统一的模型解决图文、视频文本这种单模态的相关任务,以及Scaling up增加模型size以及预训练的数据量。最近几个月最主要的工作就是多模态对话大模型。因为GPT4并没有公开其模型和demo,所以最近有很多类GPT4的工作,包括miniGPT4以及mPLUG-Owl的工作。
在多模态预训练领域最重要的榜单就是VQA Leaderboard。mPLUG在2021年VQA Challenge排名第一,以81.26的成绩首次超越了人类。现在最高的效果已经达到了86.26,并且是一个端到端的模型。这些都向我们展示了多模态预训练发展的迅速。无论是从预训练的角度还得对话的角度,都是多模态研究最重要的方向。
下面介绍一下多模态预训练技术的发展历程。

在18,19年,多模态预训练开始成为最重要的一个研究方向的时候,大家主要是基于目标检测的视觉特征抽取,做单/双流的图文特征融合,其中代表性工作包括单流UNITER,双流LXMERT。
进入2020年,大家开始尝试端到端的方法,因为之前的两阶段方法存在效率不高的问题,以及领域迁移的问题。其中代表性工作基于Resnet的Pixel-BERT、E2E-VLP,以及Transformer的VILT。
2021年,开始了数据以及模型规模的Scaling-up,其中代表性的工作包括ALBEF、SimVLM、mPLUG。
2022之后,大家开始基于大一统的方法,可以做单/多模态,其中代表性工作包括Coca,Flamingo以及mPLUG-2。

今年ChatGPT大火,我们通过GPT4的一些case可以看到,它有着非常强的视觉内容细粒度理解与推理能力,这已经超越了很多之前的方法。比如上图中左侧的这个例子,它已经能识别出插口是VGA的,以及手机是iPhone的,并且能够给出比较详细的结果。右侧图的这个case是对笑话的理解能力,也是非常细粒度的。

GPT4还展示了非常强的视觉内容富文本图片表格理解与推理能力。
这非常符合自动化办公的要求,documentAI 之前都是用一个非常复杂的系统来做的,既需要做OCR,还需要理解图片布局,才能做summary,其中的步骤是非常复杂的。GPT4能用一个端到端的方法非常详细地理解表格中的内容,并且具有非常强的文本生成能力。

上图左侧是一个数学公式,GPT4能够理解其中的内容,并给出数学推导。右侧是一篇论文,GPT4能够理解得非常详细。惊喜点在于这里的文本是比较长的,并且里面既有图片又有表格,格式复杂,而GPT4能够理解这篇论文讲的是什么,要解决的是什么,并给出非常好的summary。这些都展示了GPT4非常强大的富文本图片理解能力和表格理解能力。
但GPT4并没有开源demo,现有的demo还是纯文本模型,所以从三四月份开始相继发布了很多类GPT4的模型。

多模态对话大模型主要分成两类,第一类基于系统,将ChatGPT作为一个中枢,将视觉信息转换成文本信息,通过ChatGPT进行信息的整理与回复。其中代表性工作有Visual ChatGPT、MM-REACT以及HuggingGPT。

第二类模型是端到端的,这种更类似ChatGPT。这类工作主要基于一个非常强的文本大模型,通过一个视觉backbone来做文本的对齐。这种类GPT4的工作希望能够通过一个模型同时拥有多模态与文本的能力。代表性工作有MiniGPT-4、LLAVA、Kosmos,以及达摩院的mPLUG-Owl。
二、多模态对话大模型mPLUG技术与应用解析

mPLUG是一个模块化的多模态模型,图文的mPLUG以及大一统的mPLUG-2这两个工作分别在EMNLP2022和ICML2023发表。mPLUG系列多模态预训练工作,借鉴了人脑的模块化思想,针对不同模态input,不同模态output,因为不同模态特有属性针对不同的功能设计不同的模块,进行层次化的预训练,这样可以轻量化,可拆拔的灵活应用到各种Zero/Few-Shot、Continue Pretrain、下游Finetuning,以及多模态表征等层次化应用场景。所以mPLUG系列工作的主要思想就是层次模块化、轻量化,这样我们可以用一个比较统一的模型应用到各种复杂的场景。
上图左侧是mPLUG-2的一个工作,我们针对不同的模态拆分成不同的模块来做特定的任务,比如Video captioning需要做Video-Encoder和Text-Encoder,Universal Layers用来做对齐,VL Fusion用来做模态融合然后输入到Video-Decoder输出结果。右侧给出了现有的大一统模型,比如BEiT-3、Coca、Flamingo这些都很难在CV和NLP任务取得SOTA效果。我们分析其原因都是因为没有这种模块化、轻量化的概念,所以很难用一个大一统的模型来做各种模态的任务,并且不同模态之间没有做好协同,不同模态之间的差距还是很大的。所以我们就提出了mPLUG模块化多模态模型。
右下角是mPLUG给出的一个table,对于不同的单模态或多模态任务如何组合不同的module。这就是我们之前做的两个工作,一个是图文mPLUG,一个是大一统模型mPLUG-2。我们在30+的任务上取得了SOTA。这个工作也发表在了ICML上。如果大家感兴趣,可以去看一下具体的文章。

接下来将重点介绍多模态对话大模型mPLUG-Owl的工作。这个工作我们也在github上进行了开源。最近我们也在第三方上海人工智能实验室OpenGVLab组织的人工标注评测多模态LLM榜单排名第一!与其对比的是前面提到的一些比较经典的模型,比如LLaVA,MiniGPT4,Otter等等。
mPLUG-Owl有非常多的应用场景,比如下图的旅游指南和创意文案。
比如给出一个富士山的图片,让模型给出一个两天的行程计划。mPLUG-Owl可以给出非常详细的旅游指南。右侧的例子是创意文案,给出一张图片让模型写一首诗,mPLUG-Owl可以给出比较优美的一首诗。
应用场景还包括使用指南和展览向导。

比如给出一个锤子,问模型该如何使用。我们还对说明书,以及非常长的document进行了测试,mPLUG-Owl都可以给出非常详细的描述。右侧这种展览向导,给模型一个图片,模型可以为我们展示非常详细信息,比如图片的源头,以及一些发散性的创作。
下面具体介绍一下mPLUG-Owl的工作。

mPLUG-Owl是模块化的结构, Visual Encoder我们拿了一个预训练好的VIT。文本的大模型包括LLaMA,GPT等。我们也上线了中文的多语言模型。
我们拿两种模块化的单模态的模型加入Visual Abstractor的model,因为在多模态里面端到端的方法存在一个问题,视觉的长度比较长,所以我们需要做降序列的操作,将序列长度降下来,就很容易拟合到纯文本的LLaMA、GPT这种结构里面。
我们采用了两阶段的方法,第一阶段进行预训练,用海量的图文pair,主要是为了学习视觉的对象,把文本和视觉对应起来,比如人物、地点以及概念,通过预训练将它们对齐。所以在预训练阶段,将视觉的Encoder、 abstract以及summarize这些模块放开,文本模块freeze住。让视觉特征和文本特征更好的对齐,从而更好地学习视觉的一些概念。第二阶段是为了开发视觉的一些能力,所以我们把视觉的abstract和Encoder板块freeze住,文本的部分打开,加轻量化的LoRA。

我们也与现有方法进行了对比,像MiniGPT4、Kosmos、LLaVA,大家的工作都是比较类似的,区别就在于如何做预训练。与其它方法相比,我们的特点主要在第一阶段将视觉放开,因为我们认为视觉和文本对齐是非常重要的,需要学习这些视觉的概念;第二阶段是要把文本部分放开,这样就能开发出文本的SFD能力以及多模态的SFD的能力。

之前的工作比如MiniGPT4、LLaVA等,并没有做详细的性能评测,只是开源了一些demo让大家来体验。我们构建了一个多模态指令评测集OwlEval来评测不同的模型,包括OpenFlamingo、BLIP-2、MiniGPT4,LLaVA,以及我们的mPLUG-Owl。
评分指标主要分为四类,进行人工评测。A:听懂人类的指令,且回答满意;B:听懂指令,但是回答部分会存在一些错误;C:听懂指令,但是回答错误或者用户不满意;D:听不懂指令或者无效的回答。
我们首先对知识问答进行评测。

对比的模型有MM-REACT、MiniGPT-4,可以看到mPLUG-Owl给出的回复非常正确。能够清楚的理解人类的意图,并且回答的也是非常正确的。所以我们给出的score是A,MiniGPT-4是B,而MM-REACT的knowledge不太好。
第二个是多轮对话的评测。

首先模型要能够不停的聊,并且能够理解指代关系,比如姚明和杜峰的这个例子,问第二个问题的时候问模型左边是谁?更高的是谁?这种有指代关系的问题,mPLUG-Owl回复的都比较好。

接下来我们也进行了笑话理解的测试。
MM-REACT很难理解,最终得分是c。GPT-4回答的就非常好,GPT-4的笑话理解和细粒度理解能力确实非常强。mPLUG-Owl回答的也算不错,至少明白了它的意图,给出的答案是有一些错误的,稍微有一些幻觉,但整体来说回答的还是不错的,也展示了mPLUG-Owl非常强的细粒度理解能力。
我们在评测的时候也发现了mPLUG-Owl的涌现能力,超出了我们的想象。

我们在预训练的时候主要是通过图文pair,并没有加入多图和OCR的能力,我们进行了一些多图的能力测试。对于上图左侧两张姚明相关的图片,mPLUG-Owl也展示了给出多图之间关系的能力。右侧四张图的漫画,也进一步说明了mPLUG-Owl的能力。
还有OCR的能力。

针对给出的文章首页截图,mPLUG-Owl能够很好的理解文章的标题和摘要,展现了mPLUG-Owl的OCR的能力。
我们也将其扩展到了视频。我们与优酷联合发布了一个最大的中文数据集YouKu-mPLUG,基于此又将其扩展到了mPLUG-Owl视频理解。

例如上图左侧,模型能够很好地理解视频内容。右侧是基于视频进行一些创作。并且明白了视频里面的步骤。这些都展示了模型较强的视频理解能力。
前面也提到了我们发布的多语言版本。

我们希望模型能够支持更多的中文场景,我们也开源了一个多语言版本,上图是几个case,都展现了mPLUG-Owl的多语言能力。多语言还包含其他语言,比如法语、日语、葡萄牙语等。

这些都展示了mPLUG-Owl的多语言能力。
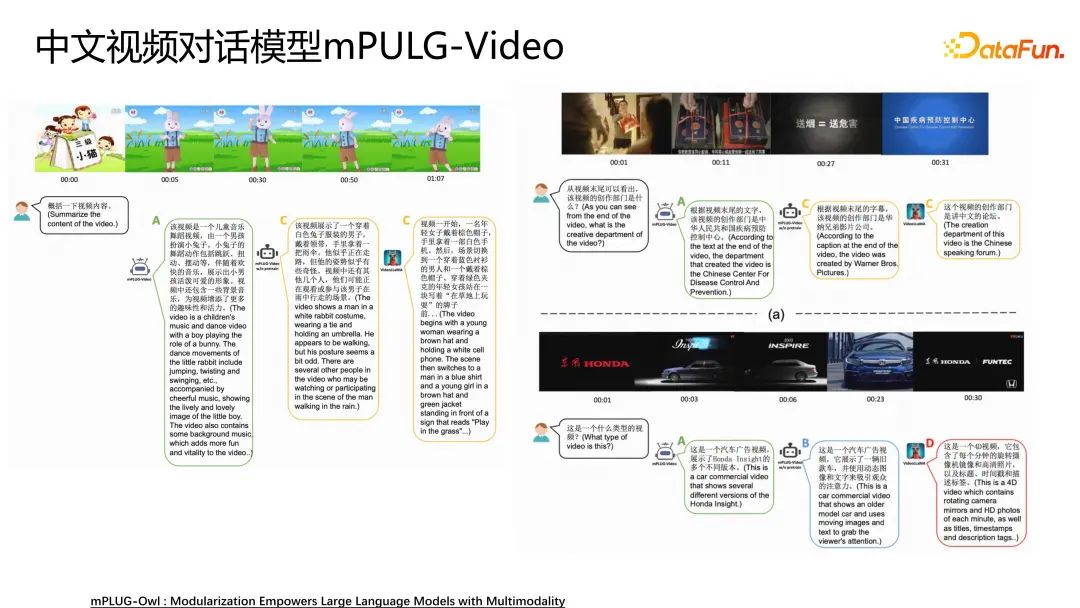
刚刚也提到了我们与优酷联合发布了一个业内最大的中文视频数据集YouKu-mPLUG,也是为了推动中文社区的发展。我们也训练mPLUG-Video中文视频对话模型。我们可以基于视频进行多轮的对话,以及刚刚提到的OCR的能力。以及knowledge的能力都表现的非常好。因为现在中文没有海量的视频数据集,如果大家对我们这个视频数据集比较感兴趣也可以到我们这个链接下进行下载。
我们还做了mPLUG-Owl的消融实验。

证明了多模态预训练和文本的instruction以及多模态instruction相关的能力,针对上图的六项能力,我们的策略对模型的提升是比较明显的,也证明了我们的训练策略和多模态指令微调数据的有效性。

刚刚提到了我们与优酷联合发布了一个业内最大的中文视频数据集YouKu-mPLUG,我们也加入了非常多的安全策略,对数据集做了一些过滤。我们的数据集分布比较均匀,大概有45个类,我们基于数据集标注了一个benchmark,包含了分类,检索等等。都是为了推动中文多模态社区发展。因为中文多模态社区发展受限的一个主要原因就是没有中文预训练多模态数据集。第二是没有benchmark,无法做公平的对比。这也是YouKu-mPLUG的初心。

上面是我们数据的一些case,分布还是比较广泛的,包括影视,综艺等等。模型的结果跟mPLUG-Owl比较类似,只是将一个文本的模块扩展成视频的模块。对应的任务包括Video Category Prediction以及Video Captioning,基于mPLUG-Owl的结构都取得了不错的效果和明显的提升。
三、ModelScope实战分享

mPLUG-Owl在ModelScope上开源了很多的模型,包括mPLUG-Owl模型以及mPLUG图文模型、视频模型等等。大家在ModelScope上搜索模型库输入mPLUG就能查看相关模型。

使用也是非常简单,将ModelScope安装之后,直接导入指定好的模型,输入图片以及输入问题,就可以得到模型给出的答案。比如我们问这个人的情绪是怎么样的?模型会给出“he is angry”。
ModelScope创空间给出了一些demo。

mPLUG-Owl的两个demo包括英文版本和多语言版本也在创空间进行了开源。点开后是一个聊天的界面,如果大家对我们的工作感兴趣也可以通过上图中的链接到ModelScope创空间进行体验。

同时,我们的工作也在huggingface和github进行了开源,左侧是huggingface的使用指南,也欢迎大家进行使用体验。
四、mPLUG项目主页

文中提到的mPLUG的工作都已在github进行了开源,github项目名为X-PLUG,里面包含了mPLUG-2多模态模块化大一统模型,以及mPLUG-Owl多模态对话大模型。项目主页上还包括文中提到的我们与优酷联合发布的中文视频数据集YouKu-mPLUG,我们的论文、代码以及数据集的链接。欢迎大家star和fork!
如果对创空间感兴趣,可以直接扫描上面的二维码进行体验,包括英文和多语言两个版本。
整个X-PLUG体系还包含了很多其它模型,我们也建立了一个讨论区,欢迎大家扫码加入讨论区,或者访问我的知乎链接,进行交流。
五、问答环节
Q1:刚刚提到了和优酷联合发布的中文视频数据集,能否介绍一下这个数据集可以用到什么场景去解决什么样的问题?
A:YouKu-mPLUG这个数据集的初衷是要补齐中文社区没有中文视频预训练多模态数据集的短板。我们现在的应用场景更多的是短视频,比如抖音、快手等等,没有这种视频数据集,会非常影响这种视频应用场景的发展。并且我们也加入了非常多的安全策略,对数据集做了一些过滤。
第一是为了推动中文多模态社区发展。第二是视频领域比较经典的任务没有benchmark大家不好做公平的对比。第三是为了推动更多的视频应用场景,包括视频生成和视频编辑。公开这个数据集也是为了让工业界和学术界来做更多的应用和研究,这也是YouKu-mPLUG的初心。
Q2:多模态在NLP方面可以怎么使用?用在什么方面?
A:现在的多模态和NLP是联系紧密的,当前的多模态更偏向NLP,因为模型的output是文本。output是视觉的,比如视频生成、图片生成是属于另外一个分支。output是文本的跟NLP走的是比较紧密的。区别只是输入多了一个图片而已,所以NLP的很多技术也是在多模态有应用的。多模态预训练这部分工作应该很多都是做NLP出身的,现在的很多应用场景,很难是单文本的,包括ChatGPT让我们经验的一个点也是他是多模态的。无论我们输入图片还是文本,都能够非常流畅地进行对话,所以多模态在NLP的应用场景是非常广的,多模态可能跟文本唯一不一样的地方就是需要你完全理解图片,所以我觉得这两个方向是不分家的。




























