












GPT-4根本不会推理!
近来,有两篇研究称,GPT-4在推理方面表现不尽人意。
来自MIT的校友Konstantine Arkoudas,在21种不同类型推理集中,对GPT-4进行了评估。
然后,对GPT-4在这些问题上的表现进行了详细的定性分析。
研究发现,GPT-4偶尔会展现出「最强大脑」的天赋,但目前来看,GPT-4完全不具备推理能力。

论文地址:https://www.preprints.org/manuscript/202308.0148/v2
研究一出,引来众多网友围观。
马库斯表示,「如果这是真的——正如我早就说过的那样——我们离AGI还差得远呢。我们可能需要进行大量的重新校准:没有推理就不可能有 AGI」。
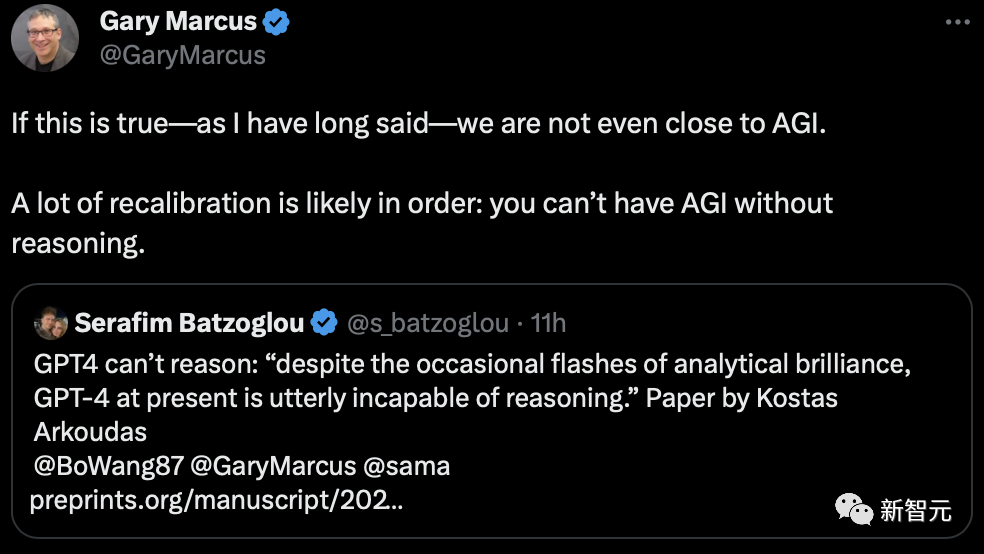
而另一篇来自UCLA和华盛顿大学的研究也发现,GPT-4,以及GPT-3.5在大学的数学、物理、化学任务的推理上,表现不佳。

论文地址:https://arxiv.org/pdf/2307.10635.pdf
研究人员引入了一个大学科学问题解决基础SCIBENCH,其中包含2个数据集:开放数据集,以及封闭数据集。
通过对GPT-4和GPT-3.5采用不同提示策略进行深入研究,结果显示,GPT-4成绩平均总分仅为35.8%。
这项研究同样再次引起马库斯的关注:
关于数学、化学和物理推理的系统调查,结果显示,目前的LLM无法提供令人满意的性能......没有一种提示策略明显优于其他策略。

下面我们就来具体看看,GPT-4如何在21个问题集,数学、物理、化学上推理惨败的。
21个问题集,GPT-4全翻车
不过,在看GPT-4回答问题之前,作者给出了一个注意事项:
GPT-4是一个非确定性系统,即使参数设置相同,在不同的运行中也可能产生不同的答案。
而以下的测试交流都是逐字记录的,根据作者的经验,文中讨论的GPT-4出错的地方往往具有鲁棒性。
1. 简单算术
能够进行基本运算,是推理的必要条件。
但是,GPT-4仍然无法可靠地执行加法、乘法等基本算术运算。
比如,让GPT-4在1381和1453之间随机选择两个数字相乘,并给出结果。
GPT-4选择了1405,以及1421,但是最后给出的结果显然是错的。因为1405×1421=1996505。

2. 简单计数
虽然具体计数并不一定是一种推理活动 ,但它肯定是任何具有一般能力推理系统的必备条件。
在这里,给GPT-4一个命题变量,并在它前面加上27个否定符号,要求它计算否定符号的个数。
对于我们来讲,这简直轻而易举,尤其是否定符号是间隔5个写成的,并且有5组,最后一对否定符号紧随其后。
然而,GPT-4却给出了「28个」答案。

3. (医学)常识
当前,我们可以将常识性论证视为,从给定信息加上未说明的条件(默认的、普遍接受的背景知识)中得出的简单推理。
在这种特殊情况下,常识性知识就是「人在死前是活着的,死后就不会再活着」这样的命题。
比如,当你问GPT-4:Mable上午9点的心率为75 bpm,下午7点的血压为120/80。她于晚上11点死亡。她中午还活着吗?

GPT-4竟回答:根据所提供的信息,无法确定Mable中午是否还活着。
但明显根据给定的信息,常识性推断(不用想)直接得出结论了。
4. 初级逻辑
如果P(x)包含Q(x),而Q(a)不成立,那么我们就可以根据模型推论出P(a)也不成立(因为如果P(a)成立,那么Q(a)也会成立)。
这是一个最基本的同义反复,但GPT-4却完全提出一个反模型:

值得注意的是,GPT-4认识到,P(x)实际上并不包含Q(x),并提出了x有可能是负数偶数,「不排除存在其他给定条件的模型」。
其实不然,一个反模型(countermodel)必须满足所有给定的条件,同时证伪结论。
此外,仅仅几句话之后, GPT-4就声称P(x)在给定的解释下确实蕴含Q(x),这与它自己之前的说法相矛盾。
说明, GPT-4还会出现内部不一致的问题。
5. 简单量词语义
请看下面三个句子:
1. [forall x . P(x) ==> Q(x)]
2. [exists x . P(x)]
3. [exists x . ∼ Q(x)]
请证伪或证明以下主张:这三个句子是共同可满足的。

显然,这三个句子都是共同可满足的,一个简单的模型是具有P(a1)、Q(a1)、¬P(a2) 和 ¬Q(a2)的域{a1, a2},然而GPT-4得出的结论确与之相反。
6. 简单图着色
首先考虑一个没有解决方案的图着色问题。
不难发现,对于这个问题中描述的图形,两种颜色是不足以满足问题中描述的图(例如,顶点0、2和4形成了一个簇,因此至少需要3种颜色)。

在这个简短的输出中,出现大量惊吓下巴的错误。
GPT-4一开始就谎称图形是完全的(显然不是,例如顶点2和3之间没有边)。
此外,显而易见的是,如果图形真是完全的,那么就不可能用2种颜色来着色,因为一个有6个顶点的完全图形至少需要6种颜色。
换句话说,GPT-4的说法不仅是错误的,而且是前后矛盾的:一会儿告诉我们(错误)这6顶点图形是完全的,这意味着不可能用2种颜色给它着色,一会儿又提供了一种双色「解决方案」。
值得注意的是,GPT-4之所以表现如此糟糕,并不是因为它没有掌握足够的图形知识或数据。
当研究人员要求GPT-4对「完全图」的了解时,它滔滔不绝地说出了「完全图」的正确定义,以及一长串关于K_n(有n个顶点的完全图)的结果。
显然,GPT-4 已经记住了所有这些信息,但却无法在新条件中应用。
7. 子集和
S = {2, 8, 6, 32, 22, 44, 28, 12, 18, 10, 14}。那么S有多少个子集的总和是37?
这个问题中,S的子集都是偶数,而偶数之和不可能是奇数,因此答案为0。
然而,GPT-4没有停下来考虑S包含的内容,而是反射性地生成它认为对这个问题合适的答案,然后继续「幻化」出一个答案「4」。

8. 初级离散数学
告诉GPT-4 A × B代表集合A和B的笛卡尔积、从A到B的关系R是A × B的子集,以及&代表集合交集之后要求它证明或证伪:
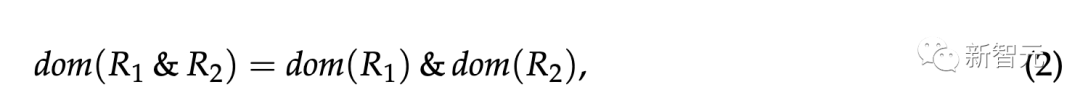
其中R1和R2是从A到B的二元关系,dom(R)表示二元关系R的域。
需要子集关系在(2)的两个方向上都成立,但它只在从左到右的方向上成立。另一个方向的反例很容易找到(例如,取A = {(1, 2)} 和 B = {(1,3)})。
然而,GPT-4却推断这是成立的,显然不正确。

9. 简单安排计划
在时间安排问题上,GPT-4同样出错了。

上下滑动查看全部
10. 罗素悖论
罗素理发师悖论是指,存在一个理发师b,他为且仅为那些不给自己刮胡子的人刮胡子。
这句话的否定是一个同义反复,很容易用一阶逻辑推导出来。
如果我们把R(a,b)理解为a被b刮胡子,那么我们就可以提出这个同义反复,并要求GPT-4证明或反证它,如下面prompt所示:
如果存在这样一个理发师x,那么对于所有y,我们将有R(y,x) <==> ∼ R(y,y),因此用x代替y将得到R(x,x) <==> ∼ R(x,x),这是矛盾的。
GPT-4对所给句子的结构和需要做的事情的理解无可挑剔。然而,随后的案例分析却糊里糊涂。

11. 积木世界
这是一个简单的推理任务,需要对倒数第三个积木B3进行案例分析。
首先,B3要么是绿色的,要么不是。
如果是绿色的,那么B3就在非绿色积木B4的上面,所以结论成立。
如果不是,那么从上数的第二个绿色积木B2,就在非绿色积木B3上面,因此结论仍然成立。
然而,结果显示,GPT-4的表现并不理想。

有五个积木从上往下堆叠:
1. 从上往下数第二个积木是绿色的
2. 从上往下数第四个积木不是绿色的
在这些条件成立的情况下,证伪或证明以下结论:在一个非绿色积木的正上方,有一个绿色积木。
首先它在证明猜想时,就已经弄错了证明的策略——PT-4假定了两种特殊情况来进行推理。
此外,GPT-4在自己的推理中已经得出了结论(虽然是错的),但在回答时仍然告诉用户问题没有被解决。而这体现的便是模型的内部不一致性问题。

12. 空间推理
这里作者选择了一个现实世界中的方位问题:
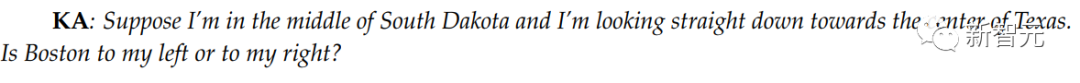
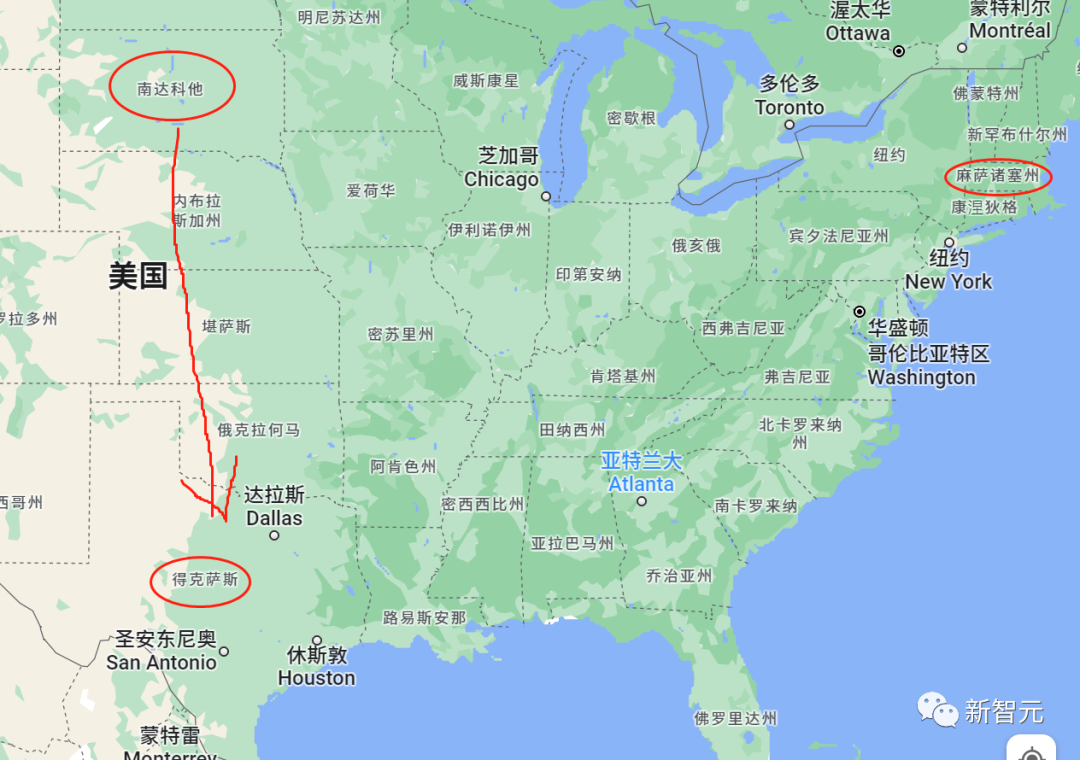
GPT-4第一次给出的答案是右边,但作者指出了它的错误,虽然从地图上来看,位于马萨诸塞州的波士顿的确在南达科他州的右边,但这里还有一个附加条件:身体的朝向是得克萨斯州。

这意味着波士顿在作者的左边。
之后,GPT-4在回答波士顿与南达科他州高低位置时,出现了更严重的问题:它在同一个回答中给出了两种矛盾的描述。

13. 时间推理
作者在这里给出了一个比较简单的时间推理问题,但GPT-4的回答依旧一塌糊涂。

Tom和Nancy上班需要乘坐交通工具。Nancy的通勤时间大约为30~40分钟,而Tom的通勤时间大约为40~50分钟。上个周五,Nancy在早上8:10~8:20之间离家,而Tom在早上8:5~9:10之间到达工作地点。此外,Nancy在Tom离开家后到达工作地点,但不会超过20分钟。你能否推断出上个星期五,Tom和Nancy何时到达工作地点?
在梳理完问题中的信息后,GPT-4给出了它的推理过程:

「如果Tom在可能最晚的时间(上午8:20)离开家...」 这句话一开篇就错了。
实际上,题目并没有给出有关Tom最晚离开家的时间,而GPT-4将Nancy的时间(「Nancy在上午8:10-8:20之间离家」)误用到了Tom身上。
同时,GPT-4给出的条件语句是混乱的,假设中包含了与结论(Nancy的到达时间)无关的信息(Tom):「如果Tom在最晚时间(上午8:20)离开家,Nancy在她最晚时间(上午8:20)离开,她的通勤时间最多是40分钟,Nancy最晚在上午9:00到达工作地点。」
这应该表述为:「如果Nancy在她最晚时间(上午8:20)离开,并且她的通勤时间最多是40分钟,那么Nancy最晚会在上午9:00到达工作地点。」
接着,GPT-4错误地推断出以下内容:「由于Tom的通勤时间最少为40分钟,这意味着他最晚会在上午9:00到达工作地点。」
这个结论显而易见根本不成立。从已知的「Tom的通勤时间最少为40分钟」这个事实中无法得出这个结论。
接下来的回答依旧是基于错误地假设Tom最早离开时间是上午8:10的条件(再次,这个出发时间是Nancy的,不是Tom的)。
然后它声称Nancy到达时间是8:45,这与早上8:10离家,不超过20分钟条件不符合。
最后,它错误地得出结论Tom和Nancy都在8:50和9:00之间到达。
在推理的过程中,GPT-4屡次出现了将信息张冠李戴的情况,最后给出的答案也是基于错误条件得出的错误回答。
14. 谋杀还是自杀?
作者构思了一个逻辑谜题,列出了9个条件要求GPT-4找出真正杀害Agatha姨妈的凶手。

1. 住在Dreadbury Mansion的某人杀了Agatha姨妈。
2. Dreadbury Mansion中唯一的居住者是Agatha姨妈、管家和Charles。
3. 杀人犯总是讨厌他的受害者,并且他的财富不会比受害者多。
4. Charles不讨厌Agatha姨妈讨厌的人。
5. Agatha姨妈讨厌所有人,除了管家。
6. 管家讨厌所有不比Agatha姨妈富有的人。
7. 管家讨厌Agatha姨妈讨厌的所有人。
8. 没有人讨厌所有人。
9. Agatha姨妈不是管家。
正确的答案是Agatha姨妈杀了自己。
首先,根据条件5,Agatha姨妈必须讨厌她自己,因为她讨厌所有除了管家以外的人。
因此,根据条件4,得出Charles不讨厌她,所以他不可能杀了她。
根据条件5和7,管家不可能讨厌他自己,因为如果他讨厌自己的话,条件8就不成立了,他会讨厌所有人。
根据条件6,得出管家比Agatha姨妈更富有,否则他会讨厌自己,这与前面我们得出的他不讨厌自己相矛盾。
根据条件3,管家也不会是凶手(第3个条件)。

在推理中,GPT-4正确地排除了Charles,但无法排除管家,并得出了错误的结论:管家是凶手。
GPT-4做出的另一个关键错误是:由于Agatha姨妈讨厌所有除管家以外的人(条件5),这意味着她至少不讨厌她自己。
这是一个奇怪的错误,从第5个条件就可以得出Agatha姨妈讨厌她自己。
同时,GPT-4又一次展示了反复出现的不一致性问题——几乎在每一条回复中,GPT-4都声称推导出某个命题及其否定形式。
15. 沃森选择任务(Wason selection task)
沃森选择任务是心理推理领域中的基本内容。
在一月份的论文中,GPT-3.5就未能通过这个测试,本次研究中,GPT-4的表现依旧不理想。

桌上放着7张牌,每张牌一面写着数字,另一面是单色色块。这些牌的正面显示的是50、16、红色、黄色、23、绿色、30。
要判断「如果一张牌正面显示4的倍数,则背面颜色为黄色」这个命题的真假,你需要翻转哪些牌?

这些回答显示,GPT-4不理解条件语句的语义。当GPT-4说卡片「50」和「30」必须翻开时,它似乎将条件误认为是充分必要条件。
而无论GPT-4的回答是对还是错,其内部的说法都是不一致的。
16. 熵
信息论的一个基本结论是:随机向量Z的熵上界不超过组成Z的随机变量的熵之和。
因此,下面问题的答案应该是「在任何情况下都不会」。

17. 简单编译器的正确性
最后给GPT-4的推理问题是最具挑战性的:证明一个简单表达式编译器的正确性。

上下滑动查看全部
但在这次测试中,GPT-4通过在表达式的抽象语法结构上设置结构归纳,正确地进行了证明。
这可能是因为它之前看过类似的证明,作者给出的例子是编程课程和教材中常见的练习类型。
然而,GPT-4还是会出现一些细节上错误。

结论:推理能力至关重要,但GPT-4不会
鉴于GPT-4是目前能力最强的LLM,因此作者基于以上分析给出了三个主要结论:
1. 在软件开发(或一般的科学和工程领域)中使用生成式AI,除了对于一些繁琐的任务外(作为一种对知识密集型编码问题的加速自动补全),充满了风险。在这些领域,规范性和正确性至关重要,而当前的LLM无法达到这些标准。
2. 随着LLM推理能力的不断提高,严格的证明检查会变得越来越重要。这种方法可以通过要求LLM将其推理形式化,或者通过训练其他LLM,来检查用自然语言表达的推理。
3. 就目前而言,AI征服人类或人类利用AI达到邪恶目的这种反乌托邦情景,都极为牵强,甚至到了荒谬的地步。当最先进的AI系统连左右都分不清时(上述第12个问题),呼吁制定政策来保护人类免受它的伤害,往好里说是为时过早,往大了说就是对资源的浪费。
不可避免地,一些人可能会说这些结果是「挑选数据」。但这是因为他们对什么是挑选数据存在着误解。根据相关命题的逻辑结构和整体背景,挑选数据有时甚至是必要的。
通过对计算机程序进行调试来发现和理解其弱点,试图证伪科学理论,试驾新车,试图找到一个假定的定理的反模型等等,从根本上来说都是「挑刺」。
举个例子,比如你发现自己新买的汽车有一个轮胎漏气,这时经销商就可以抗议称你是在「挑选数据」。毕竟,就整辆车来说,轮胎的完好率高达75%。
同样,科学、医学和工程领域的应用,尤其是软件工程,都有严格的标准。
就像我们不想要一座在90%的情况下能立柱的桥梁一样,我们需要对所有输入都有效的排序算法,而不仅仅是大部分;我们需要购物车每次都能收取正确的费用,而不仅仅是大多数时间,等等。
而这些计算和推理密集型的应用,与推荐引擎不同,它们必须非常可靠。
作者介绍
Konstantine Arkoudas
直到去年,Konstantine Arkoudas还是RPI认知科学系的研究员,也是麻省理工学院CSAIL的研究员。
目前,他是Telcordia研究实验室的高级研究科学家,主要研究AI,以及在电信和网络行业应用正式方法解决现实世界的问题。
他曾在2000年获得了MIT的计算机科学博士学位。在此之前,还获得了计算机科学硕士学位,哲学硕士学位,以及计算机科学学士学位,辅修哲学。
大学数理化,GPT-4得分35.8%
UCLA的研究中,主要评估了GPT-4,以及GPT-3.5在数学、化学、物理方面的推理能力。
当前,为了增强LLM解决数学等任务的能力,有人提出了思维连CoT策略,指导大模型逐步生成答案,从而更深入思考问题。
然而,即使这样的方法有其特定的优势,也难以完全解决复杂的科学问题。
如下,是大学物理化学的一个示例问题,以及在两种提示策略下生成的解决方案。
有CoT加持的GPT-4出现明显的计算错误,而提示用Python作为外部工具的GPT-4,也会误解数学方程。

错误标记为红色,更正内容为紫色
对此,研究中引入了一个大学水平的科学问题基准SCIBENCH。
其中,「开放数据集」包括从大学课程广泛使用的教科书中收集的5个问题,涵盖了基础物理、热力学、经典力学、量子化学、物理化学、微积分、统计学和微分方程。
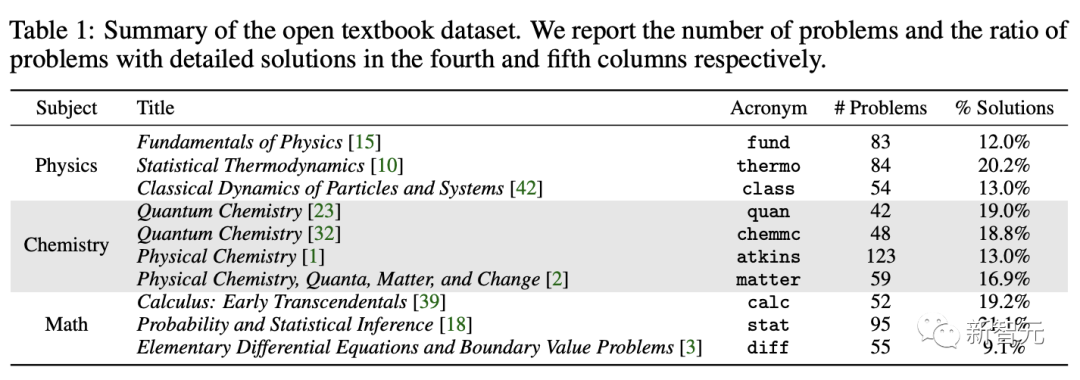
开放教科书问题摘要(包括问题数量的比例,以及有详细解决方案的比例)
另一个是「封闭数据集」,为了模拟真实世界的评估,其中包含了计算机科学和数学三门大学课程的7套期中和期末考试题。

封闭考试数据集(包含每场考试中的问题实例数,以及考试中包含详细解答的问题比例。另外,还有不同形式问题的比例,包括自由回答、多项选择和真假答案。作为参考,括号中的数字表示问题的评分点。)
与现有基准不同,SCIBENCH中的所有问题都是,开放式、自由回答的问题。
数据集中有了,研究重点评估了两个具有代表性的LLM,GPT-3.5和GPT-4,并采用了不同的提示策略,包括CoT、零样本学习、少样本学习。
另外,研究人员还提示模型使用外部工具,比如Python和Wolfram语言。
实验结果表明,在没有任何复杂提示、或使用外部工具的情况下,GPT-3.5和GPT-4在开放数据集中平均准确率分别为10.62%和16.81%。
那么,在加入CoT和外部工具后,在同一数据集上最高准确率也仅仅是35.8%。不过,相较之前,很大程度提高了准确率。
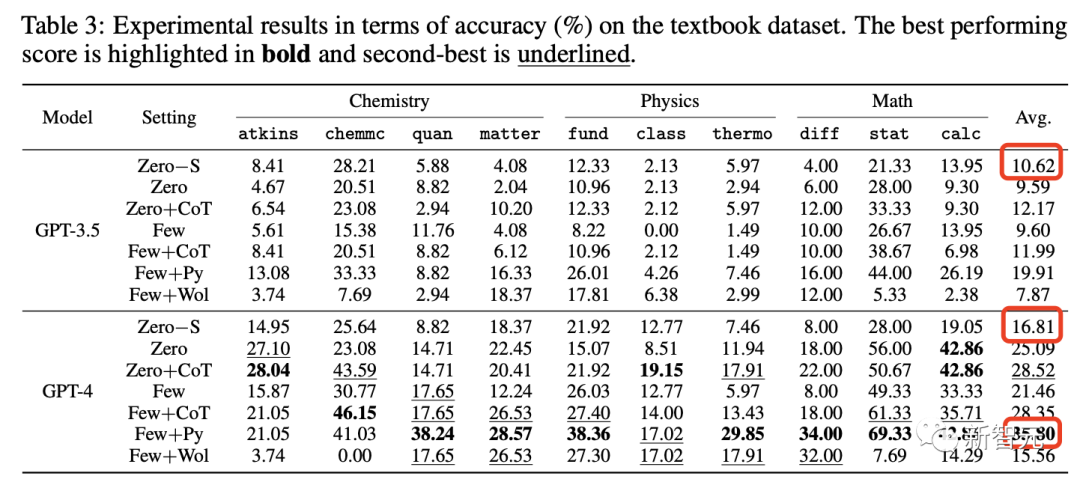
开放数据集中准确率的结果
在使用CoT提示+外部工具最强配置下,GPT-4在开放式数据集上取得了35.80%的平均分,在封闭数据集上取得了51.57%的平均分。
这些结果表明,在未来的LLM中,GPT-4有相当大的改进潜力。
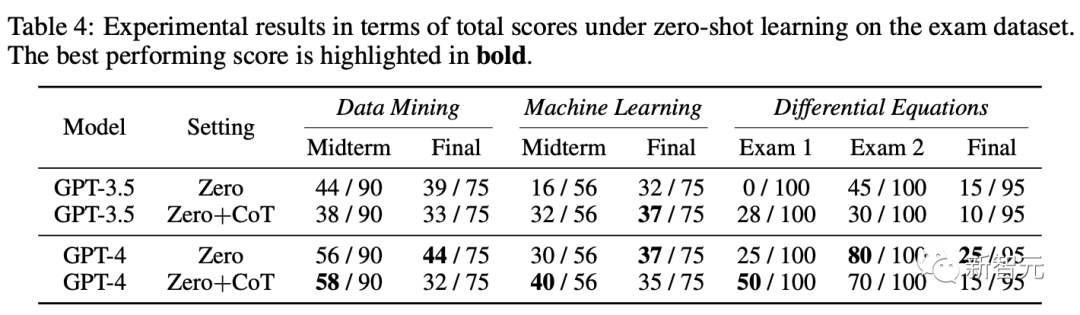
考试数据集上零样本学习下总分的实验结果
为了全面了解LLM在科学问题解决中的局限性,研究人员提出了一种全新的「自我完善」的方法,以发现LLM所做解答中的不足之处。
便是如下的「评估协议」。

首先,将正确的解决方案与LLM生成的解决方案进行比较,并在人工标注员的协助下,总结出成功解决科学问题所需的10项基本技能。
具体包括:逻辑分解和分析能力;识别假设;空间感知;因果推理;问题演绎;抽象推理;科学素养;代码转换;逻辑推理;计算能力。
随后,团队采用了一种由LLM驱动的自我评价方法,对每个实验配置下基准LLM所做的解决方案中,缺乏的技能进行自动分类。
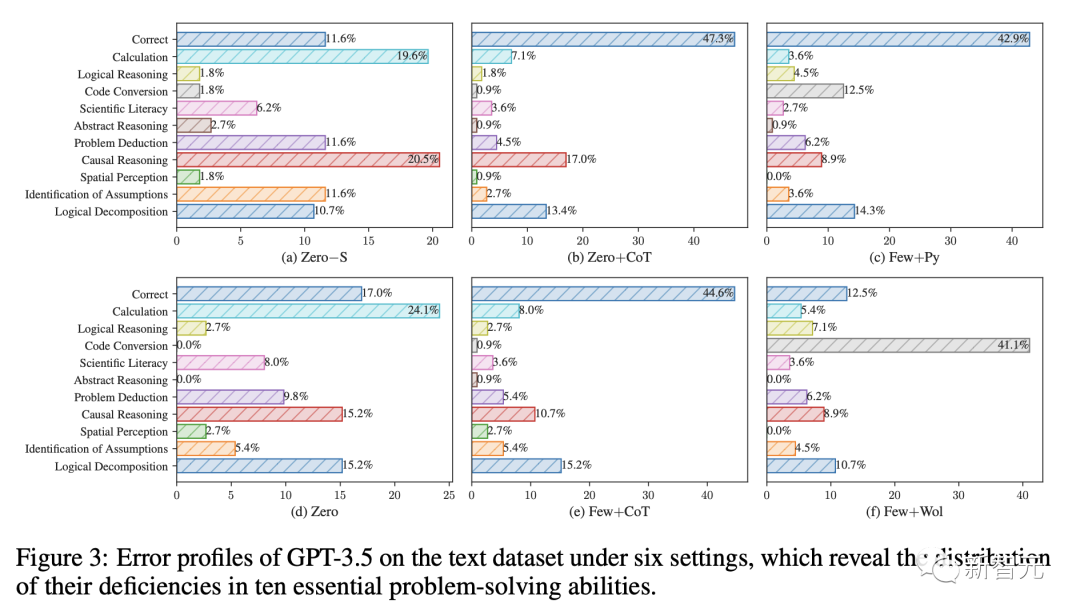
6种设置下GPT-3.5在文本数据集上的错误概况,揭示了其10种基本解决问题能力的缺陷分布
最后,通过分析发现:
(1) 虽然CoT显著提高了计算能力,但在其他方面的效果较差;
(2) 使用外部工具的提示可能会损害其他基本技能;
(3) 少样本学习并不能普遍提高科学问题解决能力。
总之,研究结果表明,当前大型语言模型在解决问题能力方面依旧很弱,并且在各种工具帮助下,依旧存在局限性。




























