一、简介
分库分表的设计和实现方式,在之前的内容中总结过很多,本文基于SpringBoot3和ShardingSphere5框架实现数据分库分表的能力;
不得不提ShardingSphere5文档中描述的两个基本概念:
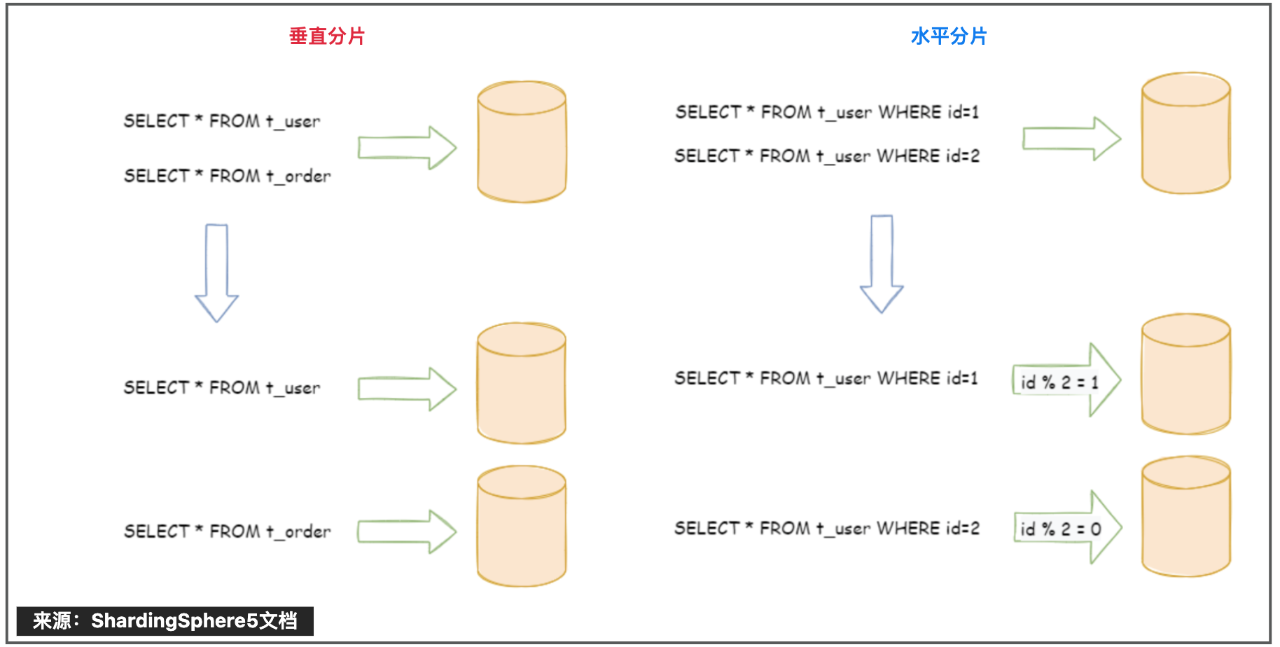
垂直分片
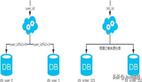
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。
水平分片
水平分片又称为横向拆分。相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。
下面从案例实践中,看看ShardingSphere5框架是如何实现分库分表的原理;
二、工程搭建
1、工程结构
2、依赖管理
这里只看两个核心组件的依赖:shardingsphere-jdbc组件是5.2.1版本,mybatis组件是3.5.13版本,在依赖管理中还涉及MySQL和分页等,并且需要添加很多排除配置,具体见源码;
三、配置详解
1、配置文件
此处只展示分库分表的相关配值,默认数据源使用db_master库,注意tb_order库表路由的策略和分片算法的关联关系,其他工程配置详见源码仓库;
2、配置原理
在配置中需要管理三个数据源,shard_db默认库,在操作不涉及需要路由的表时默认使用该数据源,shard_db_0和shard_db_1是tb_order逻辑表的路由库;
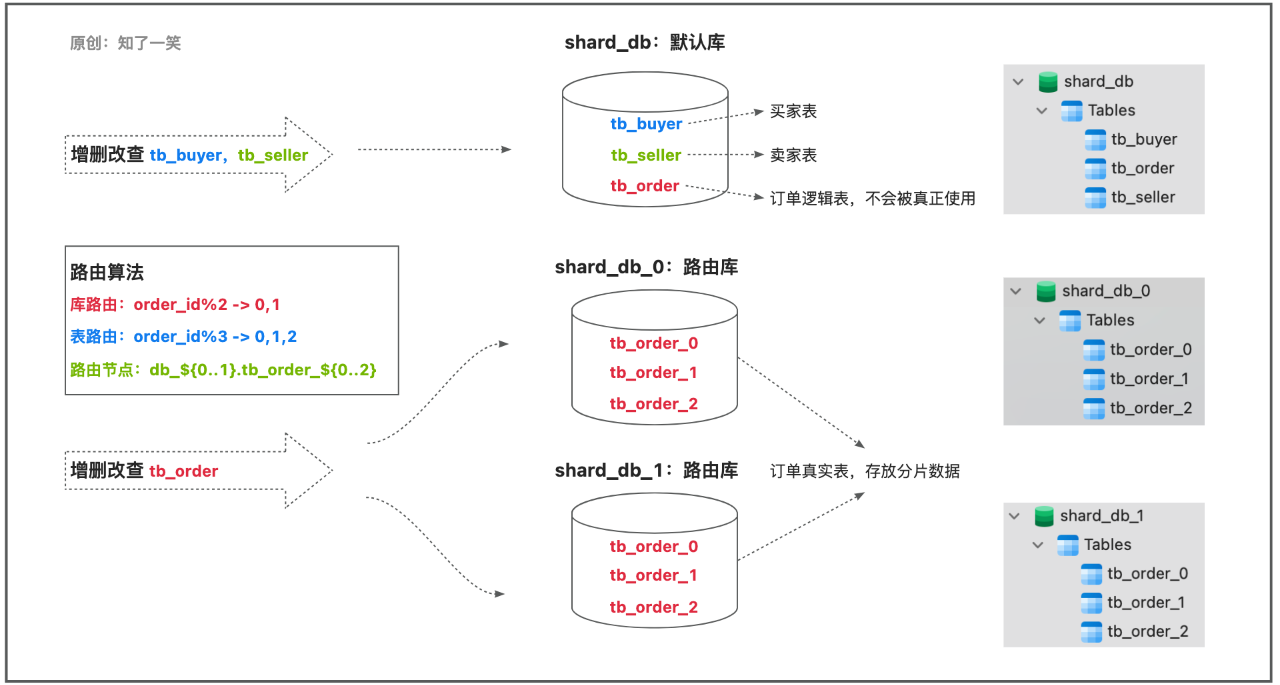
逻辑表tb_order整体使用两个数据库,每个库建3张结构相同相同的表,在操作tb_order数据时,会根据order_id字段值定位数据所属的分片节点;
- 库路由db_${0..1}采用db_${order_id%2}的算法;
- 表路由tb_order_${0..2}采用tb_order_${order_id%3}的算法;
四、测试案例
1、主库操作
基于Mybatis持久层框架,实现对shard_db默认库的数据操作,注意控制台的日志打印,可以看到一系列解析逻辑以及库表节点的定位,分页查询使用PageHelper组件即可;
2、分库操作
在对tb_order表执行增删改查时,会根据order_id的字段值计算库表的路由节点,注意分页时会查询所有的分库和分表,然后汇总查询的结果;
3、综合查询
编写一个订单详情查询接口,同时使用三个库构建数据结构;如果是基于列表数据的检索,比较常规做法的是构建ES索引结构,如果没有搜索的需求,可以在订单表分页查询后去拼接其他结构;
查看SQL语句