Hello,大家好,我是阳哥。失踪人口回归,最近太忙,好久没有更文啦。
本文先分享2段面经,文末总结了关键问题的复盘笔记。一定要看到最后!
求职者情况
分享一下好友的最新面经。
简单说下这位好友的情况:坐标成都,游戏行业,3年开发经验,最近2年做Go语言开发,1年Java/PHP工作经验。
手撕CSAPP选手,半年前坚持打卡手写的学习笔记。(最近半年被公司摧残,没时间了....)
面经分享
第一家
Golang后端,3年+经验,游戏行业,成都,15~25K
下面以对话的方式大概描述问题:
A--->面试官
B--->我
A:自我介绍
B:巴拉巴拉
A:Actor 模型你是怎么理解的?
B:无锁的并发计算模型,Actor 有自己的状态,只能通过 mailBox 去收发消息、异步消息传递~
A:你不是百度了吧?
B:没有。因为我觉得它的一部分思想和 Go 的 GMP 挺像的,好记(这里我就给自己挖坑了,擦嘞~)
A:你能说说它们哪里像吗?
B:Go 的调度器全局队列和它的 MailBox 挺像的
A:那你的意思是,实现 MailBox,你会使用队列吗?
B:是的,用 chan 关键字,元素类型为 Interface
A:这样是可以,那么我给你一个场景,在同一时刻,有 1 万个消息打进来呢?
B:增加缓冲区大小、无锁队列、批量处理消息、背压机制
A:能从数据结构的角度说说吗?
B:chan 底层是数组,线性结构,我想用非线性结构红黑树接收消息
A:为什么?
B:因为 epoll 模型就是这么做的
A:优势是什么
B:忘了...
A:你再想想,比如动态调整缓冲区,可是是一瞬间打进来的,你怎么知道调整的多大,预留也不好做,巴拉巴拉
B:额,不知道
A:用环形队列
B:啊?我没想到,因为我的印象里,它的特定是固定大小,消息太多了,不是会覆盖吗,会导致消息丢失。(我提出这个疑问的时候,他没有继续给我聊了,如果只用环形队列肯定有这个问题)我确实没有想到,很少用到它...
A:你能聊聊分布式吗?
B:巴拉巴拉,有扩展性、容错、很多节点,不同地域、数据共享,巴拉巴拉
A:你提到了数据共享,那你说说一致性你怎么做?
B:我会先想到用 etcd 吧,因为它的 raft 可以保证一致性
A:继续...
B:etcd Leader选举、数据复制、心跳、然后读取,保证一致性,巴拉巴拉它们的细节
A:etcd 是键值数据库呀,主要场景是配置之类的吧,那我现在有一个场景,就是 10w qps 如何承载 50w qps 的场景,同时保证它们的数据一致性
B:啥?(我有点没听懂这个问题,硬来)首先是能够承载这个量级吧,考虑主从复制,然后用分片技术水平扩展、异步处理、加缓存巴拉巴拉
A:主从同步你能说说典型的应用吗?
B:(我已经被前面那个问题问蒙蔽了,想说 Redis 的,有点开不了口)额...
A:Redis 就是主从吧!
B:是....是的
然后就下来就是 Redis 拷打小皮鞭了,不多说了,谢谢大家。
第二家
Golang后端,坐标成都,游戏行业,15~20k
先说感受,总体不是很难。下面听我慢慢聊:
A -> 面试官
B -> 我
A:自我介绍
B:巴拉巴拉
A:我看你简历上提到力扣做了挺多题的。
B:是的,但是已经有段时间没做了,做过的题我都有基本思路。
A:你能说说你知道哪些排序吗?
B:冒泡、选择、插入、快速、归并、堆、桶
A:快排你能说一下它的思路吗?
B:通过选择一个基准元素,将数组分割成左右两个子数组,再对子数组进行递归排序,直到整个数组有序。
A:稳定排序和不稳定排序的概念能换说一下吗?
B:假如排序前后两个元素的相对顺序在排序后仍然不变,那么这种算法就是稳定排序。不稳定排序反之。(这里答的其实不太好,可以结合前面提到的排序算法说一下,哪些具体的算法是稳定的)
A:你对二叉树了解吗?
B:了解的,树形结构,有根节点、父节点、子节点、叶子节点、度、高度、深度这些概念。
A:常见的二叉树有哪些?
B:平衡二叉树、二叉搜索树,巴拉巴拉。
A:能说一下前序遍历和后序遍历吗?
B:前序遍历,遍历顺序是根节点、左子树、右子树。后序遍历是左子树、右子树、根节点。
A:前序遍历和后续遍历能够构建一颗二叉树吗?
B:额,这个问题我不太理解。。。
A:没事,换一个问题。Go 语言中的 Map 是如何实现的,你能聊一聊吗?
B:Map 是使用哈希表、链表来实现的。然后我从散列函数、解决哈希冲突、动态扩容、并发安全性聊
A:Go 的并发模式你了解吗?
B:请问是指的扇入扇出模式、for select 循环模式这种吗?(后来回忆一下,面试官想让我聊的应该是CSP并发模型)
A:不是,你可以说一说你了解的 Go 的并发原语
B:好的,我从两个部分简单说一下,一个就是关键字,另一个是包。像关键字有 go,创建协程。channel,进行通信。select,处理 channel 的收发。mutex,锁。context,上下文。包的话 atomic。
A:你知道 csp 吗,能简单说一下嘛?
B:(我脑子里第一时间和 cap 搞混了,但还是拉回来了)csp 是一种通信协作模型。在 Go 里面有一句很经典的话,不要用共享内存来通信,要用通信来共享内存。
A:(露出了满意的笑容,扭头看向旁边的同事)我没什么问的了,你有什么问的吗?
B:你之前用过 mongodb,存储在 mongodb 中的索引你是怎么设计的?
A:不好意思,我之前没有关注过这个部分,因为之前的整体架构都是将需要落盘的数据放在内存,然后标记脏位,通过一些策略来异步落盘,而需要查询数据时,也是直接从内存查询,因为项目启动时,会把所有的玩家数据加载到内存中。
B:没事,那我们聊一下 redis 吧,你知道 redis 的落盘方案吗?
A:知道,AOF、RDB(然后开始介绍它们的特点)巴拉巴拉
B:你会如何评估 redis 的落盘方案?
A:我会从数据安全性、可恢复性、性能、硬盘空间成本、使用场景来评估。
B:硬盘空间成本?你能具体说说吗?
A:AOF占用空间大等....巴拉巴拉。
B:redis 的 Key 过长会影响性能吗?
A:额,我觉得应该会影响性能,因为你问了这个问题,但是这个我没太关注过,对于 Key 我更在意的是可读性。
最后聊了一些 Redis 的数据结构,又继续聊了一下一些特定二叉树的概念,还问了我对于矩阵、向量的理解,我就围绕以前做过的天赋系统聊了一下矩阵。
复盘!复盘!
为了对大家更有帮助,我把面试中回答的关键问题,做了复盘和调研,总结如下:
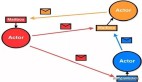
Actor模型
Actor模型是一种并发计算模型,用于描述并发系统中的实体和它们之间的通信。在Actor模型中,系统中的每个实体被称为一个Actor,每个Actor都有自己的状态和行为,并且可以通过消息传递与其他Actor进行通信。
在Actor模型中,每个Actor都是独立的,它们之间没有共享的内存。Actor之间通过异步消息传递进行通信,一个Actor可以向其他Actor发送消息,也可以接收其他Actor发送的消息。当一个Actor接收到消息时,它可以根据消息内容和自身的状态来决定如何处理消息,并可能改变自身的状态或向其他Actor发送消息。
Actor模型的特点包括:
1. 并发性: 每个Actor都可以独立地执行,不受其他Actor的影响,从而实现并发执行。
2. 无共享状态: 每个Actor都有自己的状态,不与其他Actor共享内存,避免了共享状态带来的并发问题。
3. 异步消息传递: Actor之间通过异步消息传递进行通信,消息的发送和接收是非阻塞的,提高了系统的响应性能。
4. 面向对象: 每个Actor都可以看作是一个对象,具有自己的状态和行为,可以封装数据和方法。
总结一下:通过使用Actor模型,可以简化并发系统的设计和实现,提高系统的可扩展性和可维护性。同时,Actor模型也能够有效地处理并发问题,避免了传统并发编程中常见的共享状态和锁竞争的问题。
对比Go的GMP模型和Actor模型
Go的GMP(Goroutine, M, P)模型和Actor模型都是用于并发编程的模型,但在一些方面有所不同。
Go的GMP模型是Go语言并发编程的基础,它通过goroutine(轻量级线程)和调度器(scheduler)来实现并发。GMP模型中的goroutine是Go语言中的并发执行单元,它可以独立地执行函数或方法。调度器负责将goroutine分配给线程(P),以便并行执行。线程(P)是操作系统线程的抽象,它负责执行goroutine。M(Machine)是Go语言运行时系统的一部分,它管理线程的创建和销毁,并提供与操作系统的交互。GMP模型的优点是轻量级的goroutine和高效的调度器,使得并发编程变得简单且高效。
Actor模型是一种并发编程模型,它通过将并发执行的单元(称为actor)之间的通信和状态封装在一起来实现并发。在Actor模型中,每个actor都是独立的实体,它们通过消息传递进行通信。每个actor都有自己的状态和行为,并且只能通过接收和发送消息来与其他actor进行通信。Actor模型的优点是提供了一种结构化的方式来处理并发,避免了共享状态和锁的问题。
虽然GMP模型和Actor模型都是用于并发编程,但它们在实现方式和语义上有所不同。GMP模型更加底层,直接操作线程和goroutine,适用于需要更细粒度控制的场景。而Actor模型更加高级,通过消息传递来实现并发,适用于需要更结构化和可扩展的场景。
总结起来,GMP模型适用于Go语言中的并发编程,提供了轻量级的goroutine和高效的调度器;而Actor模型适用于一般的并发编程,通过消息传递来实现并发。
epoll模型
epoll是一种在Linux系统中用于高效处理大量并发连接的I/O事件通知机制。它具有以下特点:
- 支持高并发:epoll使用事件驱动的方式,能够同时处理大量的并发连接,适用于高并发的网络应用场景。
- 高效的事件通知机制:epoll采用了基于事件驱动的方式,当有事件发生时,内核会将事件通知给应用程序,而不需要应用程序轮询检查事件是否发生,从而减少了系统资源的消耗。
- 支持边缘触发和水平触发:epoll提供了两种工作模式,边缘触发(EPOLLET)和水平触发(EPOLLIN/EPOLLOUT)。边缘触发模式只在状态发生变化时通知应用程序,而水平触发模式则在状态可读或可写时都会通知应用程序。
- 支持多种I/O事件类型:epoll可以同时监控多种I/O事件类型,包括读事件、写事件、错误事件等。
- 高效的内核数据结构:epoll使用红黑树和双向链表等高效的数据结构来管理大量的文件描述符,提高了事件的处理效率。
总之,epoll模型具有高并发、高效的事件通知机制和多种I/O事件类型的支持,适用于处理大量并发连接的网络应用场景。
etcd保证数据一致性
etcd通过使用Raft一致性算法来保证数据的一致性。 Raft是一种分布式一致性算法,它将集群中的节点分为Leader、Follower和Candidate三种角色,通过选举机制选出Leader节点来处理客户端的请求。
当客户端向etcd发送写请求时,Leader节点会将该请求复制到其他节点的日志中,并等待大多数节点确认接收到该日志条目。一旦大多数节点确认接收到该日志条目,Leader节点会将该请求应用到自己的状态机中,并将结果返回给客户端。同时,Leader节点会通知其他节点将该请求应用到自己的状态机中。
如果Leader节点失去连接或崩溃,剩余的节点会通过选举机制选出新的Leader节点。新的Leader节点会根据自己的日志和其他节点的日志进行比较,保证自己的日志是最新的,并将缺失的日志条目复制给其他节点,以保持数据的一致性。
通过Raft算法,etcd能够保证数据在集群中的一致性,并且在Leader节点失效时能够快速选举出新的Leader节点,保证系统的可用性和数据的一致性。
redis的落盘方案
Redis的落盘方案主要有两种:RDB(Redis Database)和AOF(Append Only File)。
- RDB(Redis Database):RDB是Redis默认的持久化方式。它通过将Redis的内存数据快照保存到磁盘上的二进制文件中来实现持久化。RDB的优点是快速和紧凑,适合用于备份和恢复数据。RDB的缺点是在发生故障时可能会丢失一部分数据,因为RDB是定期进行持久化的,而不是实时的。
- AOF(Append Only File):AOF是另一种持久化方式,它通过将Redis的写操作追加到文件末尾来记录数据的变化。AOF的优点是可以提供更好的数据安全性,因为它记录了每个写操作,可以在发生故障时进行恢复。AOF的缺点是相对于RDB来说,文件体积较大,恢复数据的速度较慢。
在实际应用中,可以根据需求选择适合的落盘方案。如果对数据的安全性要求较高,可以选择AOF方式;如果对数据的实时性要求较高,可以选择RDB方式。另外,也可以同时使用RDB和AOF两种方式,以提供更好的数据保护和恢复能力。
本文转载自微信公众号「 程序员升级打怪之旅」,作者「王中阳Go」,可以通过以下二维码关注。

转载本文请联系「 程序员升级打怪之旅」公众号。