前段时间,抓取平台用户数据风波,Reddit网友吵翻了天。
今天,OpenAI推出了一个网络爬虫工具GPTBot,能够自动抓取网站的数据。

如何使用?
OpenAI在发布的文档中表示,网络爬虫将过滤删除需要付费强访问的来源,同时也会删除个人身份信息(PII)或违反其政策的文本。
GPTBot抓取的数据,被用来训练GPT-4或GPT-5,能够提升未来人工智能系统的准确性和能力。
可通过以下代码识别该工具:
User agent token: GPTBot
Full user-agent string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0; +https://openai.com/gptbot)禁止GPTBot访问
另一方面,你也可以通过将GPTBot添加到站点robots. txt,来禁止其访问网站。
这意味着,网站所有者必须自愿采取措施,禁止OpenAI对自己的网站访问,不将自己的数据用来训练。
User-agent: GPTBot
Disallow: /自定义GPTBot访问
你还可以通过以下代码,来控制GPTBot对网站部分内容的访问。
User-agent: GPTBot
Allow: /directory-1/
Disallow: /directory-2/IP出口
对于OpenAI的爬虫,将从OpenAI网站上记录的IP地址块调用网站。

网友热议
OpenAI此举引发了网友对用于训练AI模型的网络爬虫的道德问题的讨论。
「OpenAI甚至没有适度引用。它是在制作衍生作品,却没有引用,从而掩盖了它的事实。」

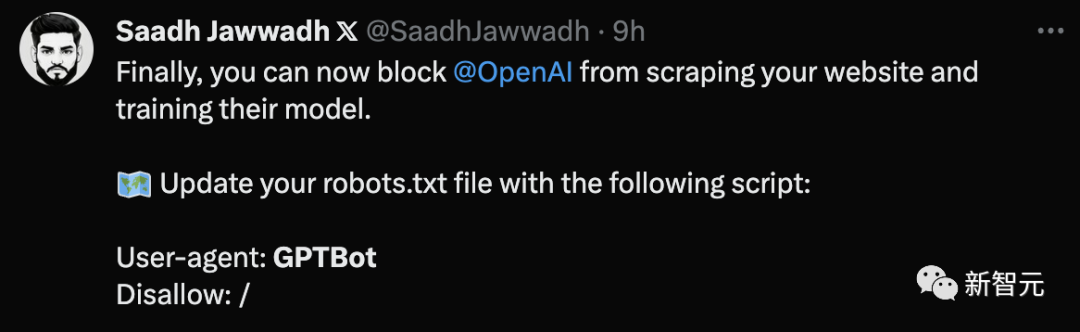
网友表示,终于有机会阻止OpenAI抓取你的网络数据,来训练模型。
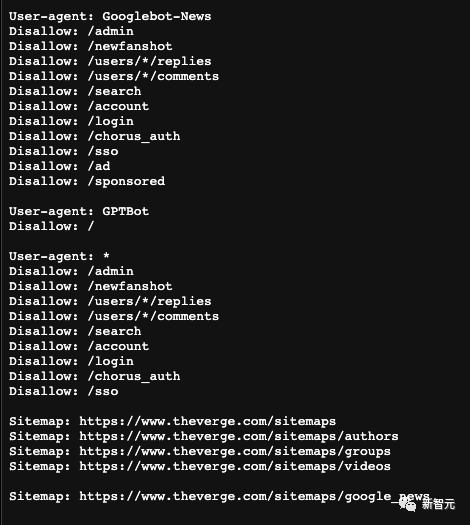
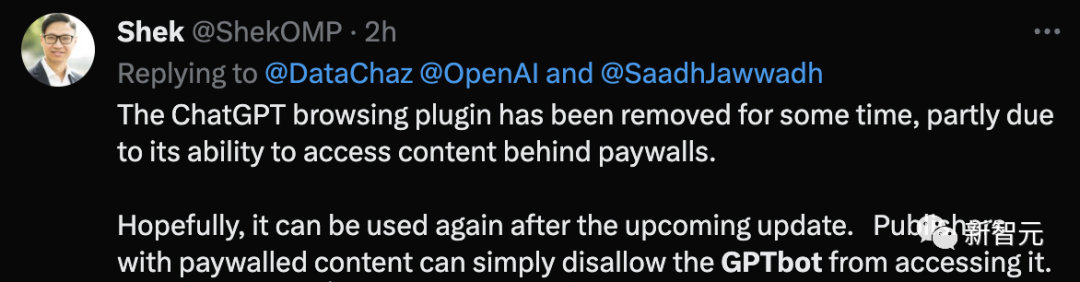
还有人表示,ChatGPT浏览器插件已被移除一段时间,部分原因是它可以访问付费墙后面的内容。
前段时间,OpenAI于7月18日向美国专利局提交了GPT-5的商标申请,暗示着公司正在训练更高级的AI系统。

GPTBot显然将帮助该OpenAI从互联网上收集更多数据来训练这个模型。