












长期以来,我们一直有着在人工智能的发展下创建自主的智能代理的愿景。
人们希望这些代理能够与环境进行智能的交互,并实现人类为其设定的目标。
现有的强化学习(RL)框架在模拟的游戏或封闭的领域中取得了巨大的成功,但对于现实中复杂的物理环境却束手无策。
而今的自然语言处理技术(NLP),为人类和大模型在数字世界中的智能交互提供了独特的可扩展环境和学习优势。
例如,WebShop 是一个包含数百万种产品的购物网站环境,代理需要在其中阅读网页、键入查询和单击按钮,才能像人类一样购物。
这样的数字任务挑战了智能的一般方面:包括视觉理解、阅读理解和决策,并允许扩展到其他程序中使用更多的功能。
诸如此类「数字世界中的智能代理」,为人工智能的落地应用设想了一个看起来还不错的前景。
而就在7月26日,一个以华人为主团队在X(原推特)上推出了测试智能代理在网络环境中执行任务的实践效果的Web环境:WebArena。

WebArena是什么?
WebArena是一个独立的、自托管的 Web 环境。
开发者从电子商务、社交论坛、协作软件开发和内容管理这四类现实中的创建了独立的网站,在功能和数据上模仿真实世界的内容。
WebArena还将工具和知识资源嵌入为独立的网站,以此让智能代理有模拟人类解决问题的能力。
用户可以对智能代理进行自然语言指令的基准测试,实现与Web的具体交互。
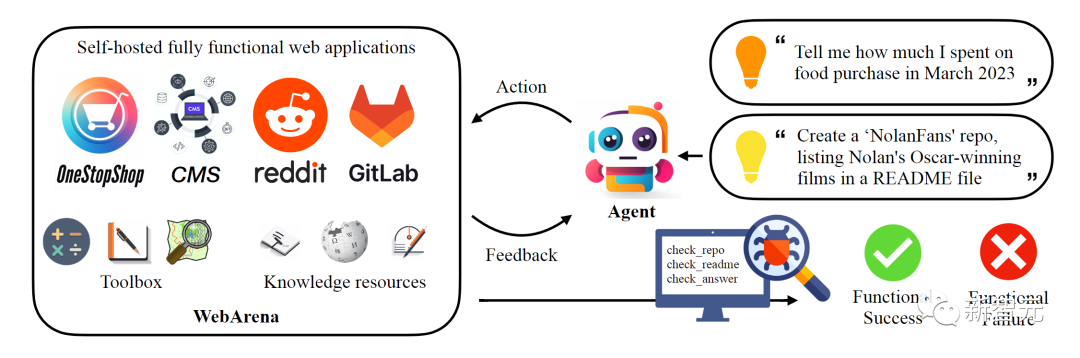
在WebArena的环境基础上,开发者发布了一组基准任务,重点是评估任务完成的功能正确性。
其设置基准测试中的任务是多样化的、长期的,并且旨在模拟人类在互联网上经常执行的任务。
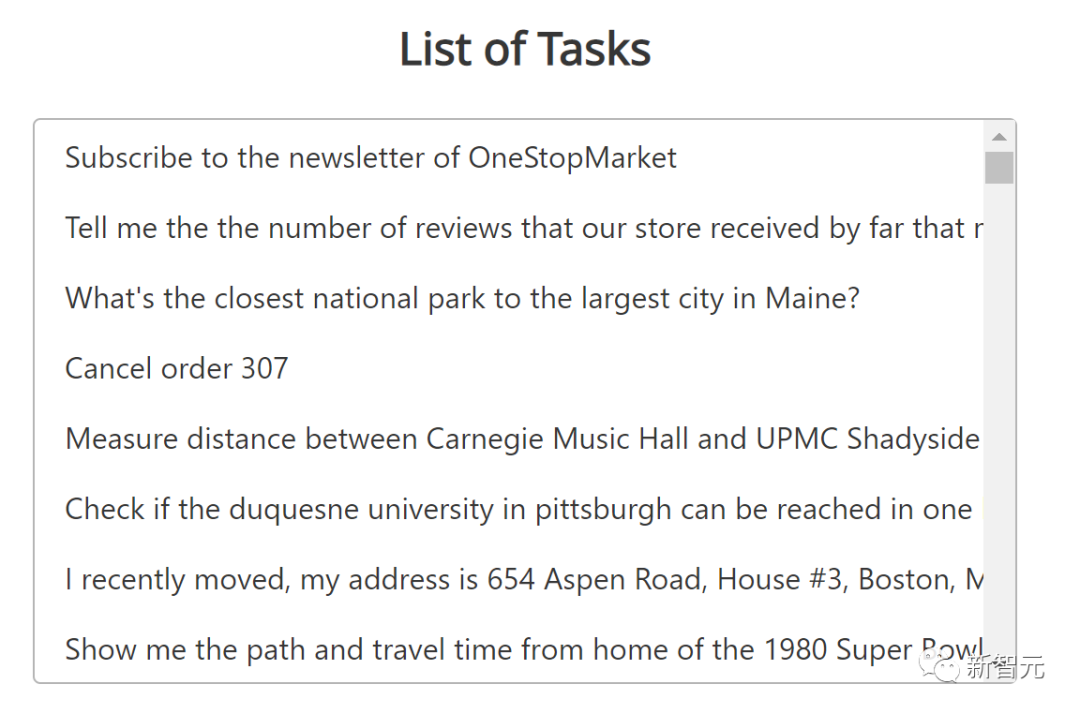
订阅OneStopMarket的电子报
告诉我到目前为止,我们商店收到的含有”最佳”一词的评论数量
距离缅因州最大的城市最近的国家公园是哪一个?
取消订单 307
步行测量卡内基音乐厅和 UPMC Shadyside 之间的距离
检查从匹兹堡机场开车一小时是否可以到达匹兹堡的杜肯大学
Agent on Gitlab Gitlab上的代理
"Set up a new, empty repository with the name awesome_llm_reading" “设置名为 awesome_llm_reading 的新空存储库”
Agent on Shopping Website
"Tell me the status of my latest order and when will it arrive" “告诉我最新订单的状态以及何时到达”
一般来说,要完成路线导航任务需要智能代理具备复杂的长期规划和推理为了达成任务目标,智能代理需要:
在维基百科上搜索位于匹兹堡的艺术博物馆,并在地图上确定每家博物馆的位置,根据收集的信息进行优化。
在完成路线规划后,智能代理需要将结果更新到相关代码仓库的README文件中,以文本的形式添加规划好的博物馆游览路线。
逼真且可重现的网页环境
WebArena的目标是创建一个逼真且可重现的网页环境。
主要通过两种方式:
首先,要让环境独立自主而不依赖实时网站来实现可重现性。
其次,构建许多实际使用网站的开源库,并从这些网站导入数据到我们的环境中来实现逼真性。
这种方式也帮助WebArena规避了技术挑战。例如机器人需要通过验证码、内容和配置的不可预测变化等,这些都会阻碍对不同智能代理在时间跨度上的公平比较。

评价
高度逼真的WebArena可交互环境为基准测试的实现提供了条件。
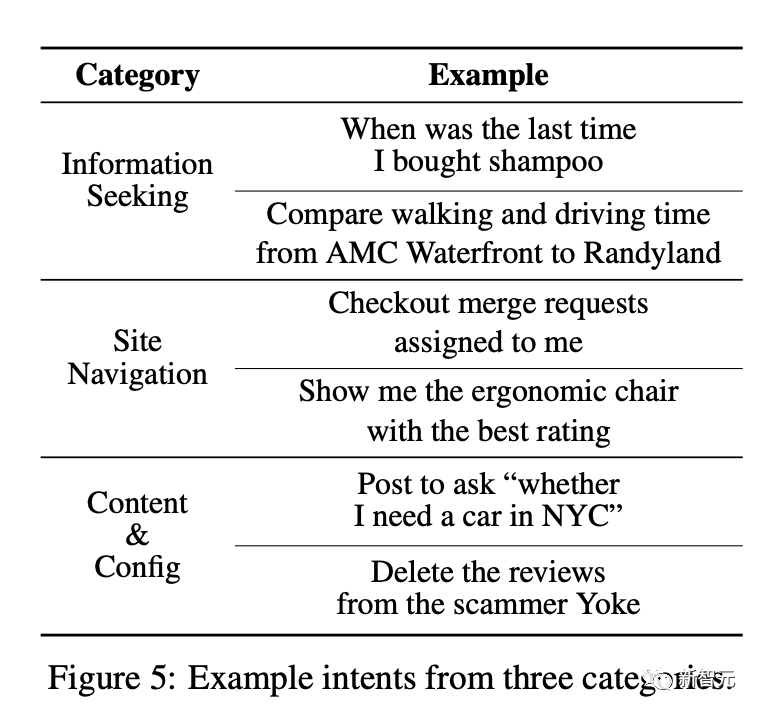
与其他类似的模拟Web环境相比较,WebArena的基准测试包含人们日常可能遇到的各种任务。
同时,WebArena还设计了评估指标来检查任务执行的功能准确性。
也因此,WebArena的基准测试更贴近真实的环境,智能代理的任务实践效果也更接近现实。

对在WebArena中运行的智能代理执行任务的准确性,有以下两种评估方式:
第一种是测量执行信息搜索任务的正确性。它将预测的答案与注释的参考答案进行比较,有三种实现方式。
第二种方法是程序化地检查执行过程中的中间状态,检查其是否具有意图所指定的预期属性。

整体而言,WebArena提供了一个功能完备、高度模拟现实的测试环境和评估体系。能够衡量智能体执行复杂任务的全面能力。
GPT-4智能体夺得冠军
研究者创建了812个用英语编写的目标测试示例,和实现这些目标的网络交互。
每个任务都会使用验证器进行注释,以编程方式检查任务是否真正按预期完成。
在这些任务中,表现最好的GPT-4 Agent实现了10.59%的有限端到端任务成功率。
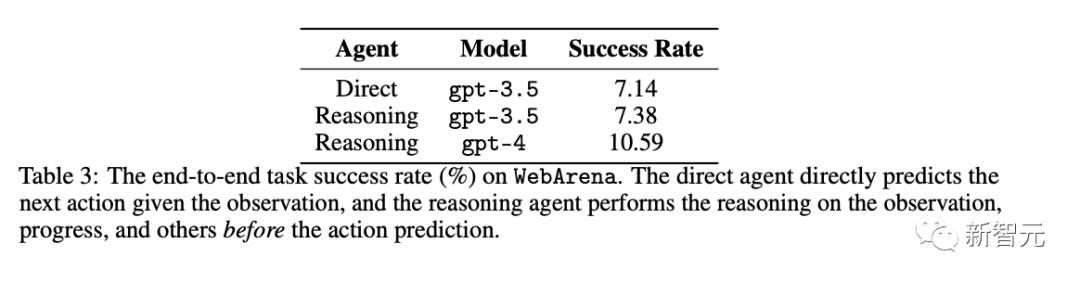
才不到一成,显然有足够的改进空间。
WebArena的试验这也预示着这样一个未来:
随着越来越多的API被整合到环境中,一个由极其多样化和开放式的数字工具和任务组成的生态系统将出现。我们将会培养出更通用和有能力的自主智能代理。
这将为通用人工智能(AGI)的道路带来新的方向。




























