













OpenObserve 是一个 Rust 开发的开源的高性能云原生可观测平台(日志、指标、追踪),比起 Elasticsearch 它大约可以节省 140 倍的存储成本,OpenObserve 能够处理 PB 级的数据,如果你正在寻找一个用于日志、指标、追踪的可观测工具,那么 OpenObserve 是非常值得尝试的。OpenObserve 虽然目前处于 alpha 阶段,但其实也进行了广泛的测试。
OpenObserve 与 Elasticsearch 的比较
Elasticsearch 是一个通用搜索引擎,可以使用应用程序搜索或日志搜索。OpenObserve 是专门为日志搜索而构建的,如果你正在寻找 Elasticsearch 的轻量级替代品,那么您应该看看 ZincSearch,如果只是想要一个日志搜索引擎,那么 OpenObserve 是一个非常好的选择。
OpenObserve 不依赖于数据索引,它将未索引的数据以压缩格式存储在本地磁盘或以 parquet 列格式的对象存储中。这使得数据摄取期间的计算要求大大降低,并且压缩率非常高,从而使存储成本降低约 140 倍。没有数据索引意味着全扫描搜索可能比 Elasticsearch 慢,但由于分区和缓存等多种其他技术,仍然应该很快。Uber 发现其生产环境中 80% 的查询是聚合查询,而 OpenObserve 的列式数据存储意味着聚合查询通常比 Elasticsearch 快得多。
下面是我们使用 Fluentbit 将真实日志数据从 Kubernetes 集群发送到 Elasticsearch 和 OpenObserve 时的结果,这只与存储有关。EBS 卷的成本为 8 美分/GB/月 (GP3),s3 的成本为 2.3 美分/GB/月。在 Elasticsearch 的 HA 模式下,通常有 1 个主节点和 2 个副本。无需复制 s3 来实现数据持久性/可用性,因为 AWS 会将你的对象冗余存储在 Amazon S3 区域中至少三个可用区 (AZ) 的多个设备上。
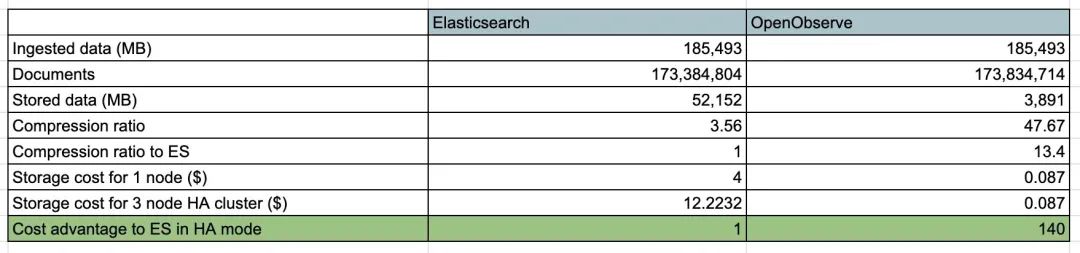
OpenObserve VS Elasticsearch
在上述场景中,OpenObserve 具有比 Elasticsearch 低 140 倍的存储成本的显著优势,这甚至没有考虑额外未使用的 EBS 卷容量(为了不耗尽磁盘空间而需要提供这些容量)以及持续监控磁盘使用情况以使其不被填满所需的工作。
无状态节点架构允许 OpenObserve 水平扩展,而无需担心数据复制或损坏。与 Elasticsearch 相比,您通常会发现管理 OpenObserve 集群的运维工作量和成本要低得多。
OpenObserve 内置的图形用户界面消除了对 Kibana 等其他组件的需求,而且由于 Rust 的优势,性能出色,而无需面对 JVM 所带来的问题。
与 Elasticsearch 相比,Elasticsearch 是一个通用性的搜索引擎,同时也兼具观测工具的功能。而 OpenObserve 是从头开始构建的观测工具,非常注重提供优秀的可观测性能。
架构
OpenObserve 可以在单节点下运行,也可以在集群中以 HA 模式运行。
单节点模式
单节点模式也分几种架构,主要是数据存储的方式不同,主要有如下几种:
Sled 和本地磁盘模式
如果你只需要进行简单使用和测试,或者对高可用性没有要求,可以使用此模式。当然你仍然可以在一台机器上每天处理超过 2 TB 的数据。在我们的测试中,使用默认配置,Mac M2 的处理速度为约 31 MB/秒,即每分钟处理 1.8 GB,每天处理 2.6 TB。该模式也是运行 OpenObserve 的默认模式。
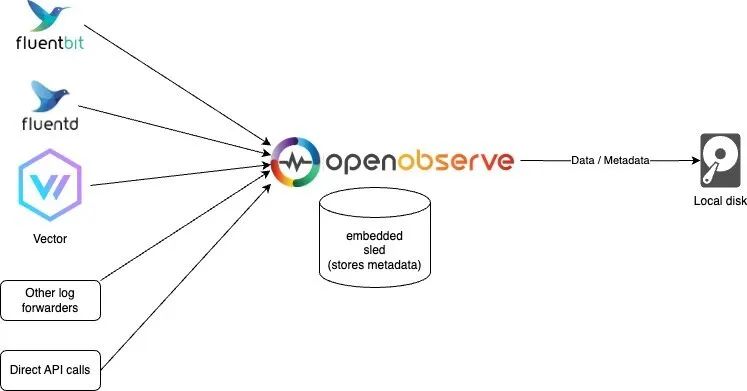
Sled本地模式
Sled 和对象存储模式
该模式和 OpenObserve 的默认模式基本上一致,只是数据存在了对象存储中,这样可以更好的支持高可用性,因为数据不会丢失。
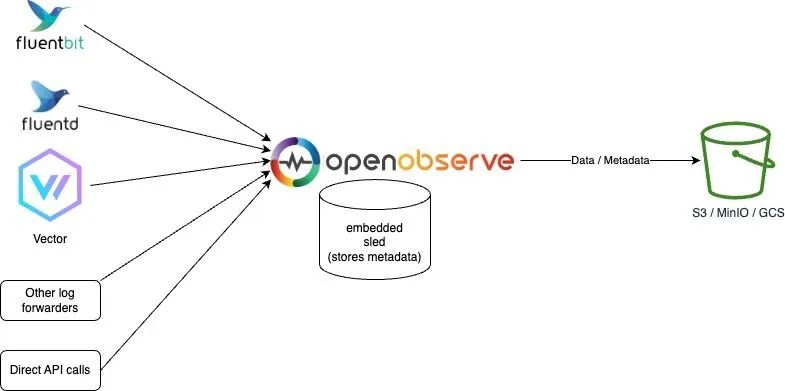
Sled对象存储模式
Etcd 和对象存储模式
该模式是使用 Etcd 来存储元数据,数据仍然存储在对象存储中。
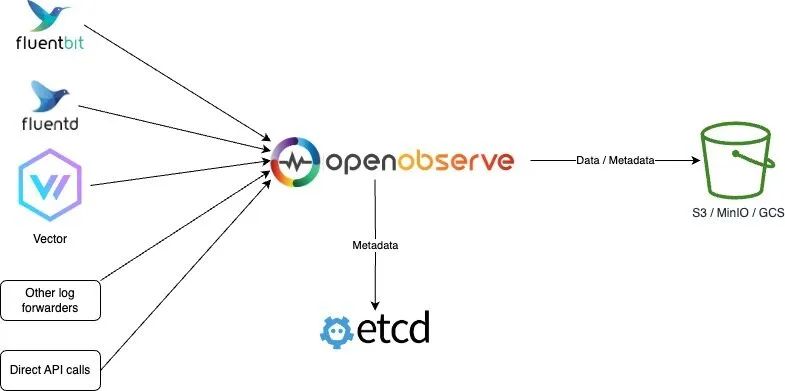
Etcd对象存储模式
HA 模式
HA 模式不支持本地磁盘存储,集群模式下 OpenObserve 会运行多个节点,每个节点都是无状态的,数据存储在对象存储中,元数据存储在 Etcd 中,这样可以更好的支持高可用性,因为数据不会丢失。
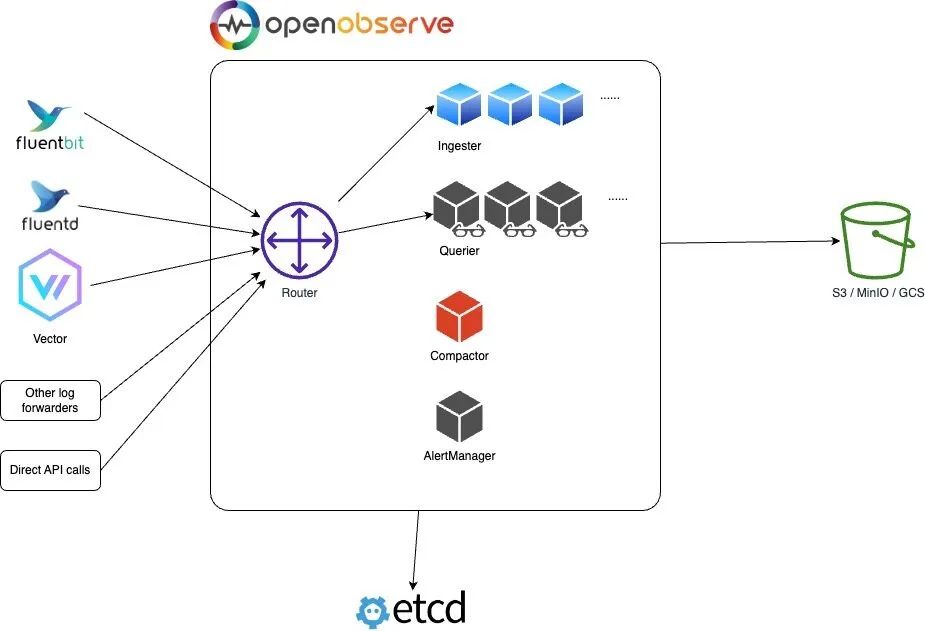
Etcd对象存储
在该模式下 OpenObserve 主要包括 Router、Querier、Ingester 和 Compactor 四个组件,这些组件都可以水平扩展;Etcd 用于存储用户、函数、报警规则和集群节点信息等元数据;对象存储(例如 s3、minio、gcs 等等)存储 parquet 文件和文件列表索引的所有数据。
- Router:Router 路由器将请求分发给 ingester 或 querier,它还通过浏览器提供 UI 界面。Router 实际上就是一个非常简单的代理,用于在数据摄入程序和查询程序之间发送适当的请求并进行响应。
- Ingester:Ingester 用于接收摄取请求并将数据转换为 parquet 格式然后存储在对象存储中,它们在将数据传输到对象存储之前将数据临时存储在 WAL 中。
- Querier:Querier 用于查询数据,查询器节点是完全无状态的。
- Compactor:Compactor 会将小文件合并成大文件,使搜索更加高效。Compactor 还处理数据保留策略、full stream 删除和文件列表索引更新。
安装
OpenObserve 的安装非常简单,只需要下载二进制文件即可,它支持 Linux、Windows 和 MacOS,也支持 Docker 镜像。我们这里当然还是将其安装到 Kubernetes 集群中,为简单这里我们直接使用默认的 Sled 和本地磁盘模式。
首先创建一个命名空间:
$ kubectl create ns openobserve然后创建如下所示的资源清单文件:
# openobserve.yaml
apiVersion: v1
kind: Service
metadata:
name: openobserve
namespace: openobserve
spec:
clusterIP: None
selector:
app: openobserve
ports:
- name: http
port: 5080
targetPort: 5080
---
# create statefulset
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: openobserve
namespace: openobserve
labels:
app: openobserve
spec:
serviceName: openobserve
replicas: 1
selector:
matchLabels:
app: openobserve
template:
metadata:
labels:
app: openobserve
spec:
securityContext:
fsGroup: 2000
runAsUser: 10000
runAsGroup: 3000
runAsNonRoot: true
containers:
- name: openobserve
image: public.ecr.aws/zinclabs/openobserve:latest
env:
- name: ZO_ROOT_USER_EMAIL # 指定管理员邮箱
value: root@example.com
- name: ZO_ROOT_USER_PASSWORD # 指定管理员密码
value: root321
- name: ZO_DATA_DIR
value: /data
imagePullPolicy: Always
resources:
limits:
cpu: 4096m
memory: 2048Mi
requests:
cpu: 256m
memory: 50Mi
ports:
- containerPort: 5080
name: http
volumeMounts:
- name: data
mountPath: /data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
storageClassName: cfsauto # 指定一个可用的存储类
resources:
requests:
storage: 10Gi上面的资源清单中,我们使用了一个 StatefulSet 来创建 OpenObserve,需要注意的是需要配置 ZO_ROOT_USER_EMAIL 和 ZO_ROOT_USER_PASSWORD 两个环境变量用来指定管理员邮箱和密码。然后在 PVC 模板中指定一个可用的 StorageClass,用于持久化存储数据。
然后直接应用上面的资源清单文件即可:
$ kubectl apply -f openobserve.yaml
$ kubectl get pods -n openobserve
NAME READY STATUS RESTARTS AGE
openobserve-0 1/1 Running 0 2m31s
$ kubectl get svc -n openobserve
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
openobserve ClusterIP None <none> 5080/TCP 2m52s快速使用
创建后我们可以查看一下 OpenObserve 的日志来验证是否启动成功:
$ kubectl logs -f openobserve-0 -n openobserve
[2023-08-04T10:18:06Z INFO openobserve] Starting OpenObserve v0.5.1
[2023-08-04T10:18:06Z INFO openobserve::service::db::user] get; org_id=Some("default") name="root@example.com"
[2023-08-04T10:18:06Z INFO tracing::span] set;
[2023-08-04T10:18:06Z INFO openobserve::service::db::user] Users Cached
# ......
[2023-08-04T10:18:06Z INFO openobserve::common::meta::telemetry] sending event OpenObserve - Starting server
[2023-08-04T10:18:07Z INFO actix_server::builder] starting 4 workers
[2023-08-04T10:18:07Z INFO actix_server::server] Tokio runtime found; starting in existing Tokio runtime
[2023-08-04T10:18:07Z INFO openobserve] starting HTTP server at: 0.0.0.0:5080, thread_id: 0
[2023-08-04T10:18:07Z INFO openobserve] starting HTTP server at: 0.0.0.0:5080, thread_id: 0
[2023-08-04T10:18:07Z INFO openobserve] starting HTTP server at: 0.0.0.0:5080, thread_id: 0启动后我们可以通过 kubectl port-forward 命令将 OpenObserve 的 5080 端口映射到本地,然后在浏览器中访问 http://localhost:5080 即可看到 OpenObserve 的 UI 界面。
$ kubectl port-forward svc/openobserve 5080:5080 -n openobserve
Forwarding from 127.0.0.1:5080 -> 5080
Forwarding from [::1]:5080 -> 5080
OpenObserve Login
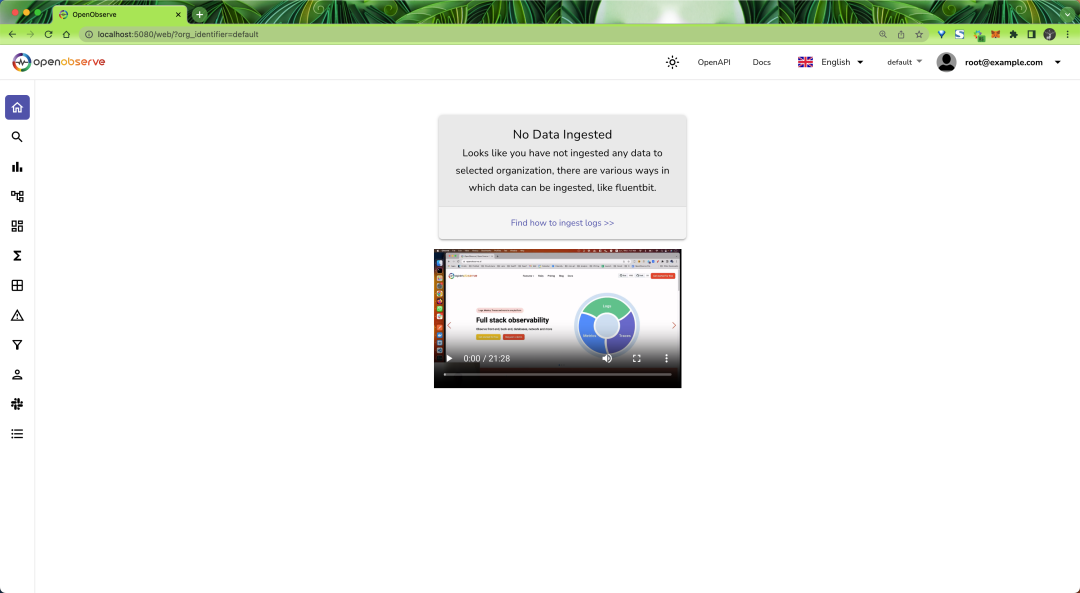
使用上面指定的管理员邮箱和密码即可登录,然后就可以看到 OpenObserve 的主界面:
OpenObserve Web
因为现在还没有数据,所以页面中没有任何内容,在 ingestion 页面提供了 Logs、Metrics、Traces 数据的各种摄取方法:
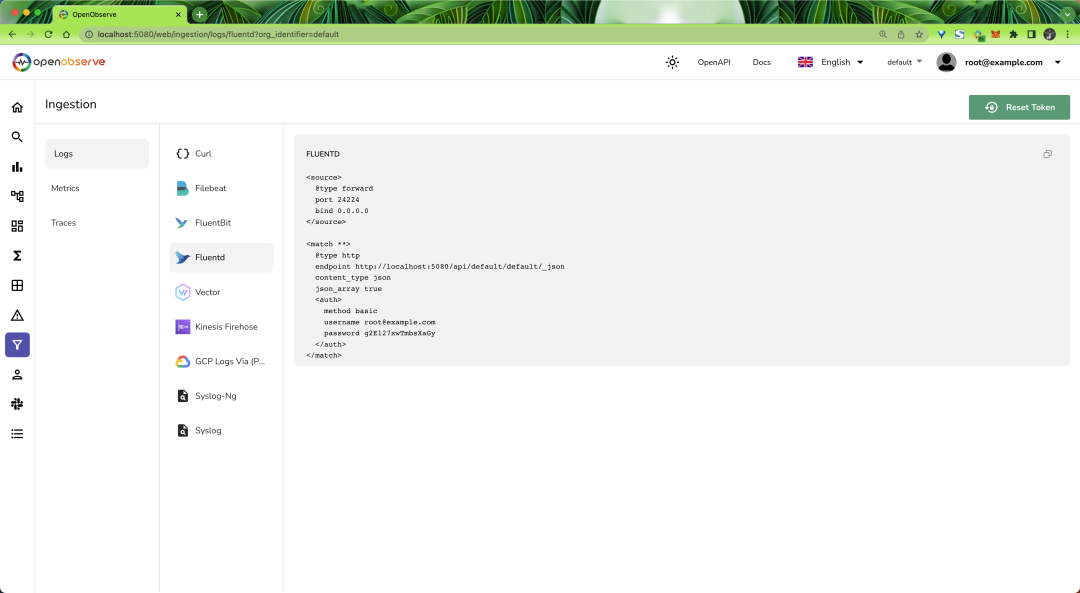
Ingestion
这里我们可以先使用 JSON API 来加载一些示例日志数据来了解一下 OpenObserve 的使用方法。先使用下面命令下载示例日志数据:
$ curl -L https://zinc-public-data.s3.us-west-2.amazonaws.com/zinc-enl/sample-k8s-logs/k8slog_json.json.zip -o k8slog_json.json.zip
$ unzip k8slog_json.json.zip然后使用下面命令将示例日志数据导入到 OpenObserve 中:
$ curl http://localhost:5080/api/default/default/_json -i -u "root@example.com:root321" -d "@k8slog_json.json"
HTTP/1.1 100 Continue
HTTP/1.1 200 OK
content-length: 71
vary: Origin, Access-Control-Request-Method, Access-Control-Request-Headers
content-type: application/json
date: Fri, 04 Aug 2023 10:46:46 GMT
{"code":200,"status":[{"name":"default","successful":3846,"failed":0}]}%收据导入成功后,刷新页面即可看到有数据了:
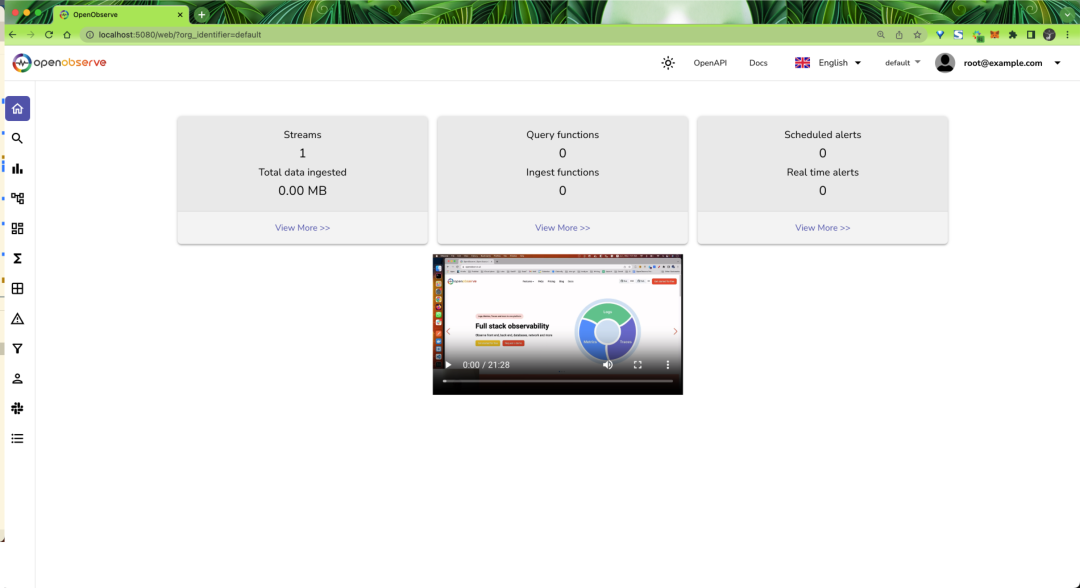
OpenObserve Web
在 Stream 页面可以看到我们导入的数据元信息:
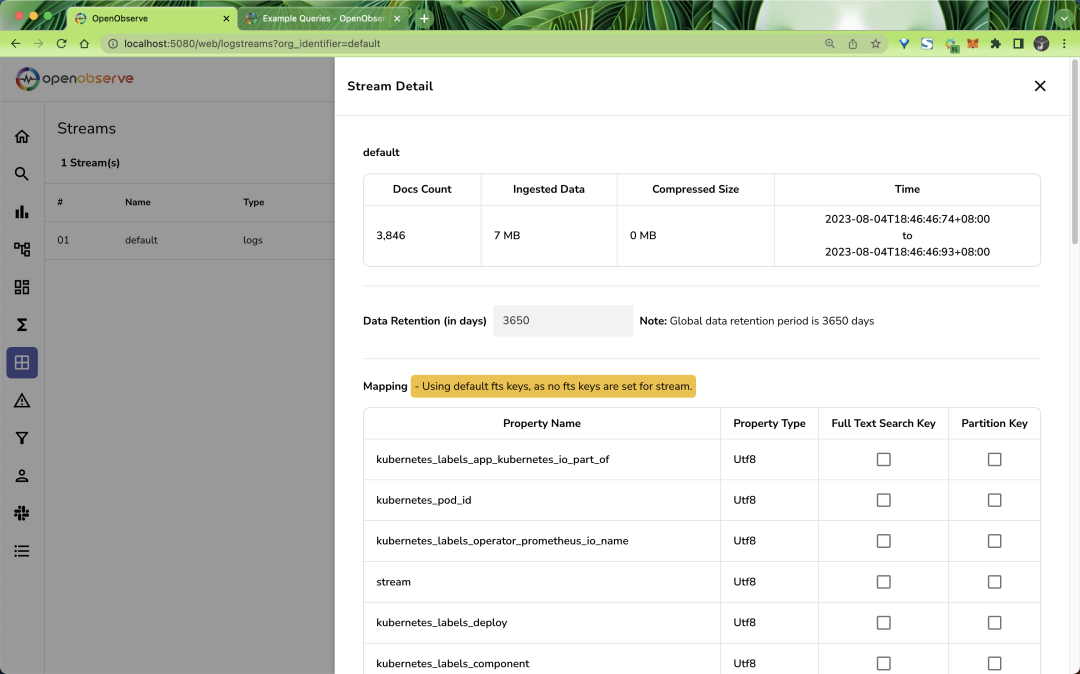
Stream流
然后可以切换到 Logs 页面就可以看到日志数据了:

OpenObserve Logs
现在我们就可以去根据直接的需求去查询日志了,常用的一些查询语法如所示:
- 对于值 error 的全文搜索,在查询编辑器中使用 match_all('error')
- 对于值 error 的不区分大小写的全文搜索,使用 match_all_ignore_case('error')
- 对于值 error 的列搜索,使用 str_match(fieldname, 'error'),这比 match_all 更有效,因为它在单个字段中搜索。
- 要搜索 code 列的值 200,使用 code=200
- 要搜索列 stream 列的值为 stderr,使用stream='stderr'
- 要在日志 log 列上搜索和使用查询函数extract_ip,使用 extract_ip(log) | code=200
当然除了日志之外,OpenObserve 还支持指标和追踪数据,这里就不再演示了,有兴趣的可以自己去尝试一下。
这里我们只是简单的演示了一下 OpenObserve 的日志方面的使用方法,后续我们可以使用 Fluentbit、Vector 之类的工具来将 Kubernetes 集群中的日志数据发送到 OpenObserve 中,敬请期待!
参考文档:https://openobserve.ai/docs




















