译者 | 朱先忠
审校 | 重楼
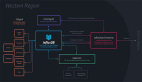
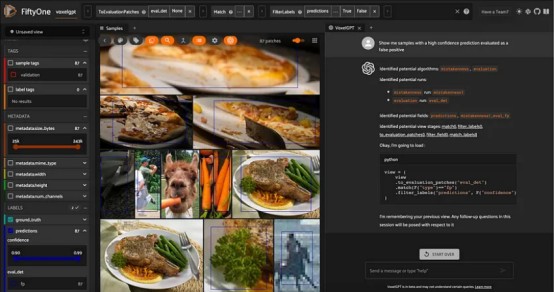 VoxelGPT使用自然语言查询图像数据集(图片由作者提供)
VoxelGPT使用自然语言查询图像数据集(图片由作者提供)
简介
与表格数据不同,计算机视觉任务的数据集是非结构化的——如像素块、标签堆、标签袋,有时还存在一些结构化的元数据。尽管如此,我们这些从事计算机视觉工作的人仍然需要能够有效地筛选这些数据,以了解数据集,准备训练和测试集,找到模式,识别边缘案例,并评估模型性能等。
当我需要理解视觉数据时(基本上一直都是这样),我会使用开源库FiftyOne,这个库定义了一个强大的Python语法来查询计算机视觉数据。它有点像计算机视觉数据的非结构化世界的SQL,它允许我以编程方式过滤、排序和语义切片由图像、视频甚至3D点云组成的数据集。
几个月前,随着ChatGPT热潮的全面展开,我在OpenAI的网站上看到了一个将自然语言输入转换为SQL查询的示例应用程序。虽然这个应用程序是非常基础性的,而且计算机视觉数据要复杂得多,但它让我思考这样一个问题:可以对图像和视频数据集做类似的事情吗?换句话说:
我们能否利用大型语言模型(LLM)的多功能性,将自然语言查询转换为非结构化计算机视觉数据集的过滤视图?
答案是:是的,我们可以!
最近,我们Voxel51的团队将LLM的一般语言和推理能力与FiftyOne的查询语言相结合,构建了VoxelGPT:一款开源人工智能助手,让您无需编写一行代码即可全面查询计算机视觉数据集!
我们使用langchain、tiktoken和fiftyone开发成功这个工具。你可以在https://gpt.fiftyone.ai/这个网站上免费试用此工具!
这篇文章将向你介绍如何构建一个特定领域LLM应用程序,其中涉及提示工程、软件工程以及大量的尝试和错误调试等完整过程。
的确,在整个过程中,我们多次碰壁,担心这项任务不可行。如果你正在尝试并努力构建一个LLM驱动的应用程序,我希望这篇文章能给你带来突破自我设定障碍所需的灵感!
本文的目录结构如下:
- 类似SQL的图像和视频查询
- 定义总体任务
- 给出模型上下文
- 生成和利用示例
- 分解问题
- 投入实际应用
查询语言
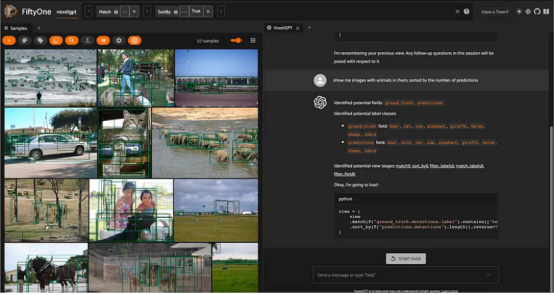 VoxelGPT使用自然语言查询图像数据集(图片由作者提供)
VoxelGPT使用自然语言查询图像数据集(图片由作者提供)
在我们深入研究如何使用LLM生成查询之前,有必要花点时间先来描述一下我们希望负责模型翻译任务的查询语言。以下仅是您需要的一些基本信息。有关这方面内容更全面的概述,请参阅《FiftyOne用户指南》。如果您已经熟悉该语言,请随时跳到下一节。
- 数据集(Dataset):是SQL中的表或Panda中的DataFrame的计算机视觉模拟。它包含与媒体文件集合相关的所有信息。
- 样本(Sample):类似于数据表中的一行,样本是数据集的原子元素。每个样本都有一个文件路径,指向一个媒体文件,并存储与该数据段相关的所有其他信息。
- 字段(Field):字段类似于数据表中的列,因为它定义了样本的属性(例如,图像宽度、高度和文件路径)。但是,字段是灵活的,因为它们可以包含其他字段(请参见下面的标签)。
- 标签(Label):标签是一个存储语义基础真相或预测信息的字段。例如,对象检测存储在检测标签字段中,分类存储在分类标签字段中。
与SQL或Pandas一样,您可以使用查询操作过滤数据。例如,您可能希望在数据表中查询以下内容:
列“A”中条目大于0.5的所有行。
然而,尽管数据表本身适用于数字切片和过滤,但非结构化计算机视觉数据本身适用于语义切片,例如:
在至少3次非“狗”地面实况检测的图像中检索具有大边界框的高置信度“狗”预测。
简言之,对非结构化数据进行语义切片需要更大的灵活性。
为了实现这一级别的灵活性,FiftyOne定义了一组ViewStage方法,这些方法封装了允许的查询操作,如过滤、匹配、选择、排序和排除。这些方法大致类似于SQL中的SELECT、WHERE和ORDER BY,但由于查询的空间要大得多,所以方法要多得多,而且这些方法中的每一种都有许多用例。有兴趣的读者请参阅此视图备忘单进行全面讨论。
通过按顺序组合多个ViewStage操作,可以获得数据集的任意子集,称为DatasetView。
以下是查询语言在操作中的样子:给定一个名为my_dataset的数据集,如果我们想在包含“cat”的10个随机图像的“predictions”标签字段中(在其“ground_truth”标签字段)获得所有“dog”检测,那么我们可以使用以下查询:
view = my_dataset.match(
F("ground_truth.detections.label").contains(["cat"])
).filter_labels(
"predictions",
F("label") == "dog"
).take(10)其中,match()仅限于“ground_truth”检测字段中有“cat”的图像,然后filter_labels()筛选“predictions”字段,仅检索“dog”检测,最后take()随机选择一个子集。
定义任务
当我们开始这段旅程时,我们不知道LLM有什么可能。早在2022年12月,我就玩过ChatGPT,甚至写了一篇文章《计算机视觉中的隧道视觉:ChatGPT能看到吗?》探讨过聊天机器人对计算机视觉概念的理解。当时,令人印象深刻的是,通用语言模型可以为基本的图像处理任务编写基本正确的Python代码,但在计算机视觉应用程序中使用GPT生成的代码(无需人工验证)的想法似乎有些牵强。
在看到了文本转换成SQL的例子,并阅读了据报道GPT-4以优异的成绩通过了BAR(以及其他考试)后,我决定再次尝试GPT for CV。我要求GPT-4为几个简单的查询生成Python代码;最终,我对它的响应感到惊喜。尽管GPT-4开箱即用结果的准确性还有很多不足之处,但是,考虑到我没有输入任何关于FiftyOne库的信息;因此,这样的结果还是可以理解的。尽管如此,这项工作的前景十分诱人。
要求一致性
当我们尝试提示技术时(我们稍后会讨论),如果我们想将其纳入更大的工程管道中,我们首先需要明确地进行任务定义。
由于问题场景的复杂性,GPT模型的响应在不同提示的格式上有很大差异。
以下只是两个简单的例子,我们将很快对此进行分析:
提示1:
英文提示:Your task is to convert input natural language queries into Python code to generate ViewStages for the computer vision library FiftyOne. Here is your first natural language query: “Images that only contain dogs”.Give me the FiftyOne code.
中文含义:您的任务是将输入的自然语言查询转换为Python代码,为计算机视觉库FiftyOne生成ViewStages。这是你的第一个自然语言查询:“只包含狗的图像”。请给我使用FiftyOne库相关编程代码。
回复1:
英文回复:Sure, here’s the FiftyOne code that generates a ViewStage for images that only contain dogs:
中文含义:当然,下面是FiftyOne代码,它为只包含狗的图像生成ViewStage:
import fiftyone as fo
import fiftyone.zoo as foz
# Load the dataset
dataset = foz.load_zoo_dataset(
"open-images-v6",
split="validation",
label_types=["detections"],
classes=["Dog"],
)
# Create a view stage that filters out images without any dog detections
view_stage = fo.ViewStage("detections", fo.FilterField("detections", "label", "Dog"))
# Apply the view stage to the dataset
dataset = dataset.add_stage(view_stage)
# View the dataset
session = fo.launch_app(dataset)此代码加载Open Images v6验证数据集,其中仅包含狗的“detections”标签类型。然后,它创建了一个视图,过滤掉任何没有检测到狗的图像。最后,将视图应用于数据集,并在FiftyOne应用程序中启动。
提示2:
英文提示如下:
Your task is to convert input natural language queries into Python code to generate ViewStages for the machine learning library FiftyOne. Here is your first natural language query: “most unique images with a false positive detection”. Give me the FiftyOne code.
中文含义:您的任务是将输入的自然语言查询转换为Python代码,为机器学习库FiftyOne生成ViewStages。这是你的第一个自然语言查询:“大多数具有假阳性检测的独特图像”。请给我使用FiftyOne库相关编程代码。
回复2:
英文回复:Sure, here’s the FiftyOne code to generate ViewStages for the natural language query “most unique images with a false positive detection” using the FiftyOne library in Python:
中文含义:当然,以下是使用Python中的FiftyOne库为自然语言查询“具有假阳性检测的最独特图像”生成ViewStages的FiftyOne代码:
import fiftyone as fo
import fiftyone.zoo as foz
# Load your dataset
dataset = fo.load_dataset("your_dataset_name")
# Define your false positive detection model
model = foz.load_zoo_model("your_model_name")
# Define your pipeline
pipeline = [
{"$set": {"predictions": {"$predict": model}}},
{"$match": {"predictions.mistakes.false_positive": True}},
{"$group": {"_id": "$filepath"}},
{"$count": "num_images"},
{"$sort": {"num_images": -1}},
]
# Run your pipeline and display the results in a view stage
view = dataset.aggregate(pipeline).limit(10).display()在这段代码中,我们首先加载FiftyOne库和任何必要的依赖项。然后,我们使用fo.load_dataset()加载您的数据集。
接下来,我们使用foz.load_zoo_mode()定义您的假阳性检测模型。此函数从FiftyOne 动物园模型Zoo加载一个预先训练的模型,其中包括一系列最先进的计算机视觉模型。
之后,我们使用$set、$match、$group、$count和$sort等聚合命令来定义我们的管道。管道首先使用$set向数据集中包含模型预测的每个样本添加一个字段。然后,我们使用$match对样本进行过滤,以便仅包括那些检测为假阳性的样本。
接下来,我们使用$group根据样本的文件路径对其进行分组,并使用$count计算每组中的图像数量。最后,我们使用$sort按照图像数量的降序对组进行排序。
最后,我们在您的数据集上运行管道,并使用limit()将结果限制为假阳性检测最多的前10张图像。然后,我们使用display()在视图中显示结果。
尽管这两个例子的提示结构相同,但有关的回答在几个关键方面有所不同。例如,响应1试图通过将ViewStage添加到数据集中来创建DatasetView。响应2定义并应用了一个MongoDB聚合管道,然后是limit()方法(应用limit这一步),将视图限制为10个样本,以及一个不存在的display()方法。此外,当响应1加载到实际数据集(Open Images V6)中时,响应2实际上是模板代码,因为需要填写“your_dataset_name”和“your_model_name”。
归纳来看,这些例子还突出了以下问题:
- 模块代码:一些响应包含用于导入模块、实例化数据集(和模型)和可视化视图(sessinotallow=fo.lonch_app(dataset))的代码。
- 解释性文本:在许多情况下,包括教育背景下,该模型解释其“推理”的事实是积极的。然而,如果我们想代表用户执行查询,那么这段解释性文本就成了障碍。有些查询甚至会产生多个按文本划分的代码块。
我们真正想要的是LLM用可以复制并粘贴到Python进程中的代码来响应,而不需要所有额外的负担。作为提示模型的第一次尝试,我开始将以下文本作为我希望它翻译的任何自然语言查询的前缀:
Your task is to convert input natural language queries into Python code to generate ViewStages for the computer vision library FiftyOne.
Here are some rules:
- Avoid all header code like importing packages, and all footer code like saving the dataset or launching the FiftyOne App.
- Just give me the final Python code, no intermediate code snippets or explanation.
- always assume the dataset is stored in the Python variable `dataset`
- you can use the following ViewStages to generate your response, in any combination: exclude, exclude_by, exclude_fields, exclude_frames, …
至关重要的是,我定义了一个任务,并制定了规则,指导模型允许和不允许做什么。
注意:随着回复的格式更加统一,我正是从ChatGPT聊天界面通过OpenAI的API使用GPT-4。
限制范围
我们的团队还决定,至少在一开始,我们会限制我们要求LLM做的事情的范围。虽然FiftyOne查询语言本身就很丰富,但要求预先训练的模型在没有任何微调的情况下完成任意复杂的任务会让人失望。从简单开始,不断增加复杂性。
对于这个实验,我们施加了以下界限:
- 只是图像和视频:不要期望LLM查询3D点云或分组数据集。
- 忽略变化无常的ViewStages:大多数ViewStages都遵循相同的基本规则,但也有少数操作例外。Concat是唯一接收第二个DatasetView的ViewStages;Mongo使用MongoDB聚合语法;GeoNear有一个查询参数,它接受一个fiftyne.utils.geojson.geo_within()对象;GeoWithin需要一个2D阵列来定义“内部”所适用的区域。我们决定忽略Concat、Mongo和GeoWithin,并支持除查询参数之外的所有GeoNear用法。
- 坚持两个阶段:虽然模型可以组成任意数量的阶段,但在我见过的大多数工作流中,一个或两个ViewStage足以创建所需的DatasetView。本文中我们这个项目的目标不是使读者“陷入困境”,而是为计算机视觉从业者打造一些有用的产品。
提供上下文
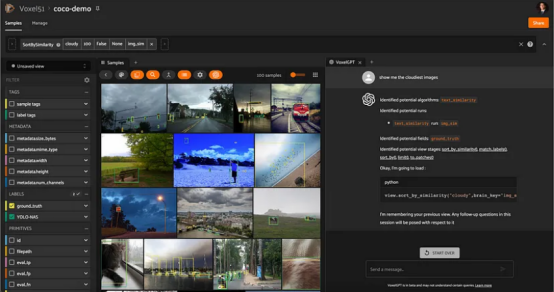 VoxelGPT使用自然语言查询图像数据集(图片由作者提供)
VoxelGPT使用自然语言查询图像数据集(图片由作者提供)
除了给模型一个明确的“任务”并提供明确的指令外,我们发现还可以通过向模型提供更多关于FiftyOne的查询语言如何工作的信息来提高性能。如果没有这些信息,LLM只能是盲目操作,胡乱在黑暗的大数据世界中抓取。
例如,在提示2中,当我要求提供假阳性预测时,响应试图用predictions.mistakes.false_ppositive引用这些假阳性。就ChatGPT而言,这似乎是存储和访问假阳性信息的合理方式。
该模型不知道在FiftyOne中,检测预测的真实性/虚假性是用dataset.evalate_detections()来评估的,在运行所述评估后,您可以通过匹配eval_fp>0来检索所有具有假阳性的图像,其中:
images_with_fp = dataset.match(F("eval_fp")>0)我试图通过提供其他规则来澄清这项任务,例如:
- When a user asks for the most "unique" images, they are referring to the "uniqueness" field stored on samples.
- When a user asks for the most "wrong" or "mistaken" images, they are referring to the "mistakenness" field stored on samples.
- If a user doesn't specify a label field, e.g. "predictions" or "ground_truth" to which to apply certain operations, assume they mean "ground_truth" if a ground_truth field exists on the data.
我还提供了有关标签类型的信息:
- Object detection bounding boxes are in [top-left-x, top-left-y, width, height] format, all relative to the image width and height, in the range [0, 1]
- possible label types include Classification, Classifications, Detection, Detections, Segmentation, Keypoint, Regression, and Polylines
此外,虽然通过向模型提供允许的视图阶段列表,我能够促使它使用它们,但它并不知道:
- 当给定的阶段(stage)相关时,或
- 如何以正确的语法来使用阶段
为了填补这一空白,我想向LLM提供有关每个视图阶段的信息。为此,我编写了代码来循环浏览视图阶段(可以使用fiftyone.list_view_stages()列出),存储文档字符串,然后将文档字符串的文本拆分为描述和输入/参数。
然而,我很快就遇到了一个问题:上下文长度。
通过OpenAI API使用基本的GPT-4模型,我已经遇到了8192令牌上下文长度的问题。这是在添加示例或任何关于数据集本身的信息之前!
OpenAI确实提供了一个带有32768个令牌上下文的GPT-4模型,理论上我本可以使用它,但粗略的计算让我相信这可能会变得十分昂贵。如果我们填写整个32k代币上下文,考虑到OpenAI的定价,每个查询大约需要2美元!
相反,我们的团队重新考察了我们使用的方法,并采取了以下措施:
- 切换到GPT-3.5
- 最小化令牌计数
- 对输入信息更加挑剔
切换到GPT-3.5
没有免费午餐这回事——这确实导致了性能的略微下降,至少在最初是这样。在项目的过程中,我们能够通过及时的工程恢复并远远超过这一点!在我们的案例中,付出的努力值得节省成本。在其他情况下,可能不会。
最小化令牌计数
随着上下文长度成为限制因素,我采用了以下简单技巧:使用ChatGPT优化提示!
一次一个ViewStage,我获取原始描述和输入列表,并将这些信息输入ChatGPT,同时提示LLM在保留所有语义信息的同时尽量减少该文本的令牌计数。使用tiktoken计算原始版本和压缩版本中的代币,我能够将代币数量减少约30%。
更具选择性
虽然为模型提供上下文很好,但根据手头的任务,某些信息比其他信息更有帮助。如果模型只需要生成一个涉及两个ViewStage的Python查询,那么它可能不会从其他ViewStage所接受的输入信息中受益匪浅。
我们知道我们需要一种根据输入的自然语言查询来选择相关信息的方法。然而,这并不像对描述和输入参数进行相似性搜索那么简单,因为前者的语言通常与后者截然不同。我们需要一种将输入和信息选择联系起来的方法。
事实证明,这种联系就是一个例子。
示例
生成示例
如果您曾经使用过ChatGPT或另一个LLM,您可能已经亲身体验过如何为模型提供哪怕只是一个相关的示例也能显著提高性能。
作为开始,我提供了10个完全合成的示例,并通过在任务规则和输入提示中的ViewStage描述下面添加这些示例,最后将这些示例传递给GPT-3.5:
以下是A、B形式的输入输出对的几个示例:
A) "Filepath starts with '/Users'"
B) `dataset.match(F("filepath").starts_with("/Users"))`
A) "Predictions with confidence > 0.95"
B) `dataset.filter_labels("predictions", F("confidence") > 0.95)`
…………
仅通过这10个例子,模型的响应质量就有了显著的提高,因此我们的团队决定对此进行系统化处理。
- 首先,我们梳理了我们的文档,找到了通过ViewStages组合创建的视图的任何和所有的示例。
- 然后,我们浏览了ViewStages列表并添加了示例,以便尽可能全面地涵盖用法语法。为此,我们确保每个参数或关键字至少有一个示例,为模型提供一个可遵循的模式。
- 在介绍了用法语法的情况下,我们改变了示例中字段和类的名称,这样模型就不会对与阶段相关的名称产生任何错误的假设。例如,我们不希望模型仅仅因为match_labels()的所有示例碰巧都包含一个“person”类,就将person类与match_labels()方法强关联。
选择类似示例
在这个示例生成过程的最后,我们已经有了数百个示例,远远超出了上下文长度。幸运的是,这些示例包含(作为输入的)自然语言查询,我们可以直接将其与用户输入的自然语言查询进行比较。
为了进行比较,我们使用OpenAI的text-embedding-ada–002模型预先计算了这些示例查询的嵌入。在运行时,用户的查询嵌入了相同的模型,并选择了具有最相似的自然语言查询(按余弦距离)的示例。最初,我们使用ChromaDB来构建内存中的向量数据库。然而,考虑到我们处理的是数百或数千个向量,而不是数十万或数百万个向量,实际上切换到精确的向量搜索更有意义(加上我们的依赖性有限)。
管理提示相关的这些示例和组件变得越来越困难,所以正是在这一点上,我们开始使用LangChain的提示模块。最初,我们可以使用他们的相似性ExampleSelector来选择最相关的示例,但最终我们不得不编写一个自定义的ExampleSelecter,这样我们就可以更好地控制预过滤。
筛选合适的示例
在计算机视觉查询语言中,查询的适当语法可能取决于数据集中样本的媒体类型:例如,有时需要将视频与图像区别对待。我们决定只给出给定数据集语法正确的例子,而不是通过给出看似冲突的例子来混淆模型,或者通过强迫模型根据媒体类型进行推断来使任务复杂化。在向量搜索的上下文中,这被称为预过滤。
这个想法非常有效,以至于我们最终将同样的考虑应用于数据集的其他功能。在某些情况下,差异仅仅是语法上的——在查询标签时,访问Detections标签的语法与Classification标签的语法不同。其他过滤器更具策略性:有时我们不想让模型知道查询语言的某个特性。
例如,我们不想给出使用它无法访问的计算的有关LLM示例。如果没有为特定数据集构建文本相似性索引,那么将搜索最佳视觉匹配的模型示例提供给自然语言查询是没有意义的。同样,如果数据集没有任何评估运行,那么查询真阳性和假阳性将产生错误或无效结果。
您可以在GitHub存储库的view_stage_example_selector.py文件中看到完整的示例预过滤管道。
基于示例选择上下文信息
对于给定的自然语言查询,我们使用ExampleSelector选择的示例来决定在上下文中提供哪些附加信息。
特别是,我们统计这些选定示例中每个ViewStage的出现次数,确定五个最频繁的“ViewStage”,并在提示中添加关于这些ViewStage输入参数的描述和信息作为上下文。这样做的理由是,如果一个阶段经常出现在类似的查询中,那么它很可能(但不能保证)与该查询相关。
如果它不相关,那么描述将帮助模型确定它不相关。如果相关,那么有关输入参数的信息将帮助模型生成语法正确的ViewStage操作。
分而治之
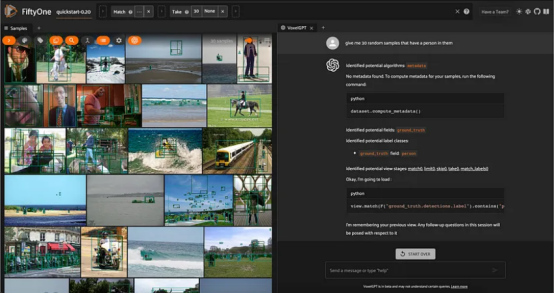 VoxelGPT使用自然语言查询图像数据集(图片由作者提供)
VoxelGPT使用自然语言查询图像数据集(图片由作者提供)
到目前为止,我们一直专注于将尽可能多的相关信息——而且只是相关信息——压缩到一个提示中。但这种方法已经到了极限。
即使没有考虑到每个数据集都有自己的字段和类名称这一事实,可能的Python查询空间也太大了。
为了取得进展,我们需要把问题分解成更小的部分。从最近开发的方法中获得灵感,包括思想链提示和选择推理提示,我们将生成数据集视图的问题分为四个不同的选择子问题:
- 算法
- 算法的运行
- 相关字段
- 相关类名
然后,我们将这些选择“链接”链接在一起,并在DatasetView推断的最后提示中将它们的输出传递给模型。
对于这些子任务中的每一个,都适用相同的一致性和简单性原则。我们试图尽可能地从现有示例中回收利用自然语言查询,但强调要简化每个选择任务的所有输入和输出的格式。对一个链接来说,最简单的表达对另一个链接可能不是最简单的!
算法
在FiftyOne中,数据集上的计算产生的信息被存储为“运行”(run)。这包括计算,如唯一性(uniqueness),它测量每个图像相对于数据集中其他图像的唯一性,以及硬度(hardness),它量化模型在尝试学习该样本时将经历的困难。它还包括相似性(similarity)的计算,包括为与每个样本相关的嵌入生成向量索引,甚至包括我们之前谈到的评估计算。
每个计算都会生成不同类型的结果对象,该对象具有自己的API。此外,ViewStages和这些计算之间没有任何一一对应的关系。
让我们以唯一性(uniqueness)为例作简单讨论。唯一性计算结果存储在每张图像的浮点值字段(默认为“uniqueness”)中。这意味着根据情况,您可能需要按唯一性排序:
view = dataset.sort_by("uniqueness")检索唯一性高于特定阈值的样本:
from fiftyone import ViewField as F
view = dataset.match(F("uniqueness") > 0.8)甚至只是显示唯一性字段:
view = dataset.select_fields("uniqueness")在这个选择步骤中,我们让LLM预测哪些可能的计算可能与用户的自然语言查询相关。此任务的示例如下:
Query: "most unique images with a false positive"
Algorithms used: ["uniqueness", "evaluation"]算法的运行
一旦确定了潜在的相关计算算法,我们就要求LLM选择每次计算的最合适运行。这一点至关重要,因为某些计算可以在具有不同配置的同一数据集上多次运行,而ViewStage可能只有在正确的“运行”下才有意义。
相似性运行就是一个很好的例子。假设您在数据上测试两个模型(InceptionV3和CLIP),并在数据集上为每个模型生成了向量相似性索引。当使用SortBySimilarity视图阶段时,哪些图像被确定为与哪些其他图像最相似,这在很大程度上取决于嵌入模型,因此以下两个查询需要生成不同的结果:
## query A:
"show me the 10 most similar images to image 1 with CLIP"
## query B:
"show me the 10 most similar images to image 1 with InceptionV3"这种运行选择过程是为每种类型的计算单独处理的,因为每种计算都需要一组修改后的任务规则和示例。
相关字段
链中的这个链接涉及识别与自然语言查询相关的、与计算运行无关的所有字段名。例如,并非所有具有预测的数据集都以“predictions”的名称存储这些标签。根据个人、数据集和应用程序的不同,预测可能存储在名为“pred”、“resnet”、“fine-tuned”、“predictions_05_16_2023”或完全其他的字段中。
此任务的示例包括查询、数据集中所有字段的名称和类型以及相关字段的名称:
Query: "Exclude model2 predictions from all samples"
Available fields: "[id: string, filepath: string, tags: list, ground_truth: Detections, model1_predictions: Detections, model2_predictions: Detections, model3_predictions: Detections]"
Required fields: "[model2_predictions]"相关类名
对于分类和检测等标签字段,将自然语言查询转换为Python代码需要使用数据集中实际类的名称。为了实现这一点,我让GPT-3.5为输入查询中的标签类执行命名实体识别。
在查询“samples with at least one cow prediction and no horses”(至少有一个奶牛预测而没有马的样本)中,模型的工作是识别“马”(horse)和“牛”(cow)。然后将这些识别的名称与前一步中选择的标签字段的类名进行比较——首先区分大小写,然后不区分大小写。
如果在数据集中的命名实体和类名之间没有找到匹配,我们就回到语义匹配:“"people" → "person", "table" → "dining table", and "animal" → [“cat”, “dog", “horse", …]。
每当匹配不相同时,我们使用匹配类的名称来更新传递到最后推理步骤的查询:
query: "20 random images with a table"
## becomes:
query: "20 random images with a dining table"ViewStage推理
一旦做出了所有这些选择,类似的示例、相关描述和相关数据集信息(选定的算法运行、字段和类)将与(可能修改的)查询一起传递到模型中。
我们没有像最初那样指示模型以dataset.view1().view2()…viewn()等的形式向我返回代码,而是不再搜索数据集部分,要求模型以列表的形式返回ViewStages。当时,我很惊讶地看到这样的操作居然提高了性能。事后看来,这样安排符合这样一种观点,即你把任务分解得越多,LLM就能做得越好。
实际应用
创建一个基于LLM技术的程序是一件很酷的事情,但将相同的内核变成LLM技术支持的应用程序更酷得多。以下是我们开发此应用程序的简要概述。
单元测试
当我们将其从原理验证转变为稳健的工程系统时,我们使用单元测试来对管道进行压力测试并确定薄弱环节。链中链接的模块化特征意味着,每个步骤都可以单独进行单元测试、验证和迭代,而无需运行整个链。
这样的技术会导致更快的改进,因为一个提示工程团队中的不同个人或团队可以并行处理链中的不同环节。此外,它还降低了成本,因为理论上,您只需要运行LLM推理的单个步骤即可优化链中的单个环节。
评估LLM生成的代码
我们使用Python的eval()函数将GPT-3.5的响应转换为DatasetView。然后,我们设置FiftyOne应用程序会话的状态以显示视图。
输入验证
垃圾输入→垃圾输出。为了避免这种情况,我们运行验证以确保用户的自然语言查询是合理的。
首先,我们使用OpenAI的审核端点。然后,我们将任何提示分类为以下四种情况之一:
1.明智而完整:提示可以合理地翻译成用于查询数据集的Python代码。
All images with dog detections(检测到狗的所有图像)。
2.明智但不完整:提示是合理的,但如果没有其他信息,就无法转换为DatasetView。例如,如果我们有两个模型对我们的数据进行了预测,那么以下仅引用“my model(我的模型)”的提示是不够的:
Retrieve my model’s incorrect predictions(检索我的模型中的错误预测)。
3.超出范围:我们正在构建一个应用程序,将查询的视图生成为计算机视觉数据集。虽然底层GPT-3.5模型是通用LLM,但我们的应用程序不应变成一个数据集附近断开连接的ChatGPT会话。以下提示应该被取消:
Explain quantum computing like I’m five(像我是五岁孩子一样解释量子计算)。
4.不明智:给定一个随机字符串,尝试生成数据集的视图是没有意义的——从哪里开始?!
Azlsakjdbiayervbg。
在尝试将用户的输入查询转换为一系列视图阶段之前,我们将输入与验证说明和示例一起传递到模型中。根据响应,我们要么提示用户提供更多信息或更合理的查询,要么继续数据集视图生成管道。
总结
 VoxelGPT正在运行(视频由作者提供)
VoxelGPT正在运行(视频由作者提供)
一个简单的想法导致产生了一个疯狂的想法,而这段旅程将这个疯狂的想法带到了生活中。凭借提示工程、一些真正的软件工程技术和一系列的技术黑魔法,我们的小团队创建了一个LLM驱动的应用程序,将自然语言查询转换为计算机视觉数据集的过滤视图。
要点很简单:定义任务,用规则指导,限制范围,简化,选择统一性,分解问题,并保持相关性。
当我们把所有的部分放在一起时,它看起来是这样的:
- 验证查询
- 查找类似的示例
- 检索相关文档
- 识别潜在的算法/计算
- 选择最有可能运行的算法
- 确定在查询中访问/使用哪些字段(属性)
- 推断每个标签字段的类名
- 生成用于查询的视图阶段列表
- 组合视图阶段并将筛选后的视图返回到数据集中
- 成功
需要说明的是,VoxelGPT远非一款完美的应用程序,但这从来都不是目标。每一步都有改进的空间,更不用说更多的例子了!您还可以将此作为构建计算机视觉任务的AutoGPT风格委托器的基础来使用。
最后,欢迎对VoxelGPT提供您的任何贡献。它是免费和开源的!
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:How I Turned ChatGPT into an SQL-Like Translator for Image and Video Datasets,作者:Jacob Marks