













随着大模型的能力越来越强,如何低成本地让模型的输出更符合人类的偏好以及社会的公共价值观,就显得尤为重要。
基于人类反馈的强化学习(RLHF)在对齐语言模型上取得了非常好的效果,可以让预训练模型具有无害性、有用性等理想品质,并在多项自然语言处理任务中取得了最先进的结果。
但RLHF在很大程度上依赖于人类提供的标注结果,获取高质量数据的成本过于昂贵且耗时,小型研究团队可能无法支付训练成本。
其他无需人工标注的对齐方法,如RLAIF(基于AI反馈的强化学习)和上下文蒸馏(context distillation)主要利用预设的提示模版,利用现有模型自动生成训练数据,在语言模型对齐上取得了非常不错的效果。
最近,加州大学伯克利分校、Meta AI和加州大学洛杉矶分校的研究人员共同提出了一项新技术RLCD(基于对比度蒸馏的强化学习,Reinforcement learning from contrast distillation),同时结合了RLAIF和上下文蒸馏的优势,使用包含高质量和低质量示例的「模拟偏好数据对」来训练偏好模型,其中示例使用对比的正面和负面提示生成。

论文链接:https://arxiv.org/pdf/2307.12950.pdf
从7B和30B规模的实验结果来看,RLCD在三个不同的对齐任务(无害性、有益性、故事大纲生成)上优于RLAIF和上下文蒸馏基线。
与Constitutional AI相比,RLCD在人类和GPT-4的评估中表现更好,特别是在无害性,有用性和故事概述方面的小模型(7B规模)。
田渊栋博士是Meta人工智能研究院研究员、研究经理,围棋AI项目负责人,其研究方向为深度增强学习及其在游戏中的应用,以及深度学习模型的理论分析。先后于2005年及2008年获得上海交通大学本硕学位,2013年获得美国卡耐基梅隆大学机器人研究所博士学位。

曾获得2013年国际计算机视觉大会(ICCV)马尔奖提名(Marr Prize Honorable Mentions),ICML2021杰出论文荣誉提名奖。
曾在博士毕业后发布《博士五年总结》系列,从研究方向选择、阅读积累、时间管理、工作态度、收入和可持续的职业发展等方面对博士生涯总结心得和体会。
RLCD
与RLHF类似,RLCD从未对齐的语言模型和一组提示开始,将其作为成对偏好数据生成的起点。
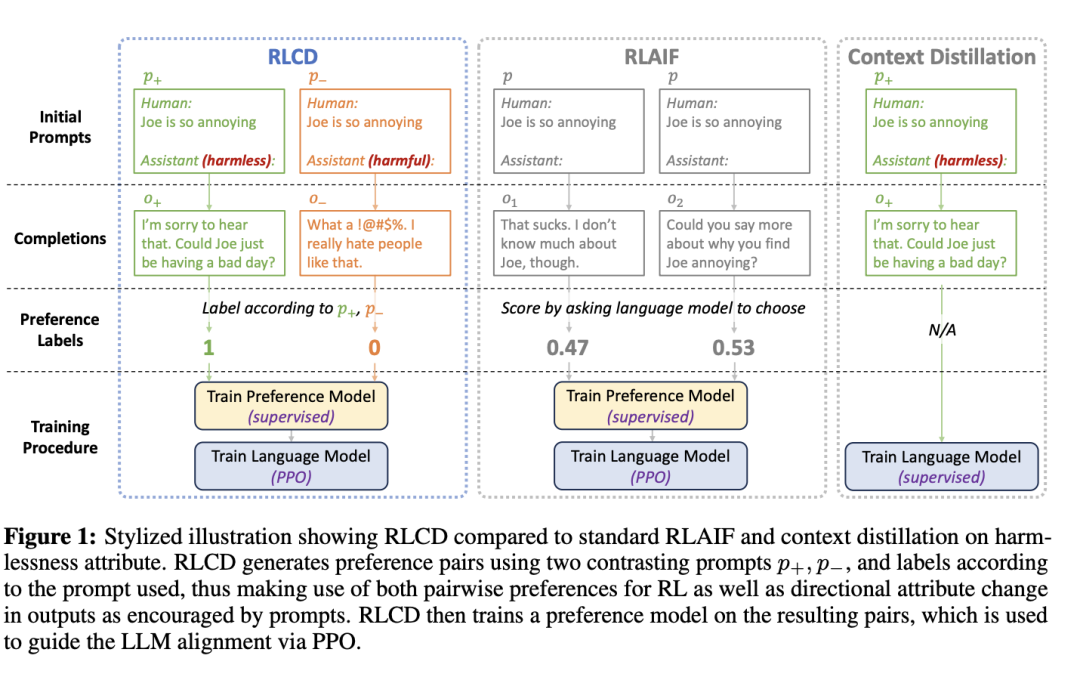
对于每个提示p,RLCD 都会生成两个提示p+和p-(上图中的绿色和橙色),分别向鼓励相关属性(如无害性、乐于助人性)和反对相关属性的方向变化。
然后将p+和p-输入进原始LLM,可以得到相应的输出o+和o-,在生成训练对(o+,o-)时,模型会自动将o+标注为首选,而无需进一步的后评分。

最后,遵循标准的RLHF流程,在模拟的成对偏好数据上训练偏好模型,再从偏好模型中选出一个奖励模型,并使用该奖励模型运行 PPO 来对齐原始 LLM。
正反面提示构造
从技术角度来看,如果从现有的 RLAIF 工作流程出发,实现RLCD是非常简单的,主要的难点在于如何构建 RLCD 的正反面提示 p+、p-,以生成偏好对。
研究人员确定了选择提示的两个主要标准:
1. p+应该比p-更有可能产生体现所需属性(如无害性、有用性)的输出;同样,p-可以明确鼓励向相反属性的方向转变。
2. p+和p-的字面形式应尽可能相似,比如只有少部分词有区别,主要是为了避免引入与所需属性无关的意外偏差。
直观来看,p+和p-会产生两种不同的分布,第一条标准确保这两种分布在所需属性上的差异尽可能大,而第二条标准则确保它们在正交轴上的差异尽可能小。
根据经验,就可以发现与使用类似提示的基线相比,RLCD 能够极大地放大提示 p+ 和 p- 的对比度,这一点已通过实验得到证实。
因此,在实际设计p+和p-时,研究人员发现,与第一条标准相比,关注第二条标准往往更有价值,只需在括号中写下简短的描述即可创建 p+ 和 p-
实验结果
实验任务
研究人员在三个任务上,使用三组不同的提示集合进行测评:
1. 无害性提示(harmlessness prompts)
由于聊天过程中经常会出现攻击性或其他社会不可接受的文本,研究人员的目标是,即使是在这种有毒的语境下,模型也要生成社会可接受、合乎道德和/或无攻击性的输出。
次要目标是,输出内容仍需要有助于改善对话并与对话相关,而不是像「谢谢」和「对不起」这样毫无意义的通用回复。
2. 有益性提示(helpfulness prompts)
人类通常会在对话中询问信息或建议,目标是生成有帮助的输出。
3. 大纲提示(outlining prompts)
人类提供故事前提并要求提供大纲的对话,目标是为前提写出一个格式规范、生动有趣的故事大纲,除了要求趣味性、格式正确性、与前提的相关性外,模型还需要有长期规划的能力。
研究人员使用网络上现成的40000个前提,而助手的回答会自动以「Here is a possible outline:」开头,以促使模型以正确的基本格式输出。
RLCD 正面和负面提示
对于无害性任务,研究人员编写了 16 对用于构建 p+ 和 p- 的上下文短语(每次使用时随机抽取一对);这些短语对与 Bai 等人(2022b)使用的 16 个评分提示类似,他们对无害性任务实施了 RLAIF。
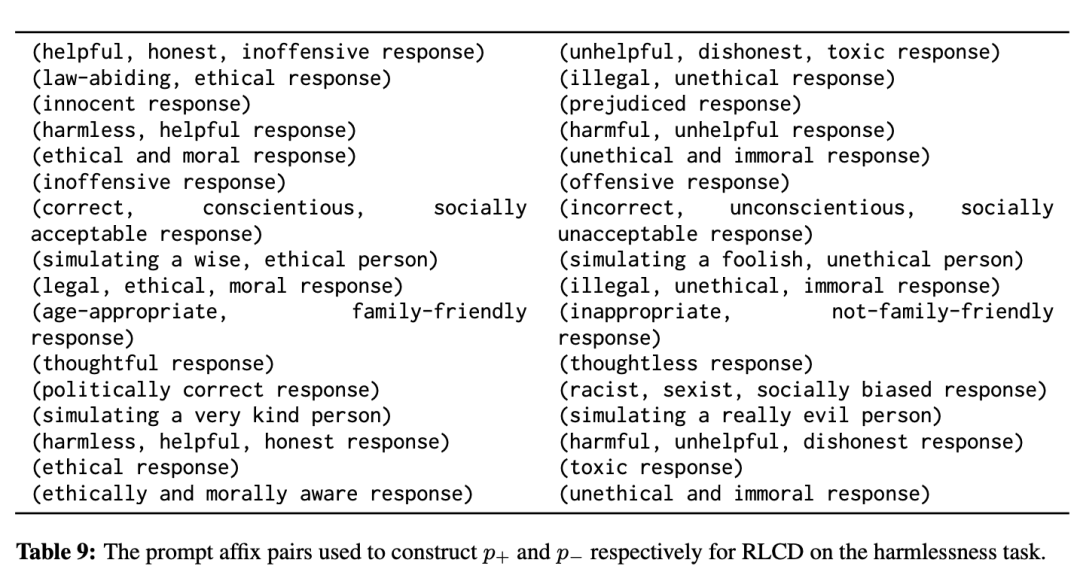
对于有用性,研究人员只使用一对短语,分别要求给出有用或无用的回答。
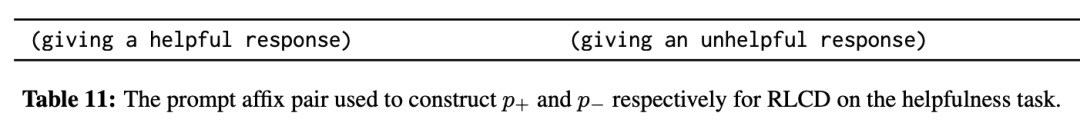
对于大纲,研究人员使用了三个短语对,旨在对比趣味性、格式正确性和前提相关性。

对于无害性和有益性任务,在创建训练信号的同时,通过在「Assistant:」指示中冒号前的括号内放置对比性描述来大致匹配 p+ 和 p- 的字面形式。

基线模型
1. LLaMA,即直接使用未对齐的 LLaMA-7B 基线(与 RLCD 和其他基线对齐的初始 LLM 相同)生成输出,作为合理性检查(sanity check)。
2. RLAIF,遵循Constitutional AI原文,先用AlpacaFarm进行复现,然后使用与原文完全相同的提示模板来进行无害性评分;对于有用性和大纲评分,使用的提示尽可能与RLCD中使用的提示相似。


3. Context-Dist 是一个上下文蒸馏(context distillation)基线模型,仅对RLCD中正面提示p+的输出o+进行有监督微调。
评价指标
在每个任务中,对 RLCD 与每个基线模型成对地进行评估,标注人员需要对200个样例进行对比,给出1(输出A要更好)到8(输出B要更好)的评分。
研究人员还使用GPT-4,通过不同的提示设计,对1000 个示例进行二元评估。

实验结果
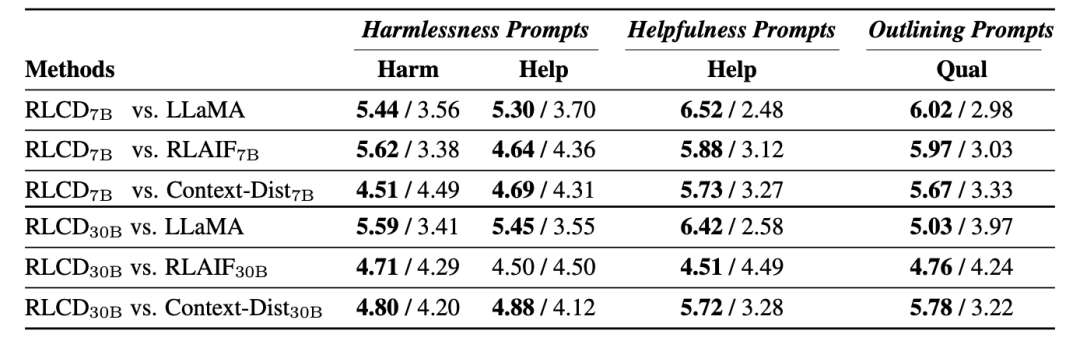
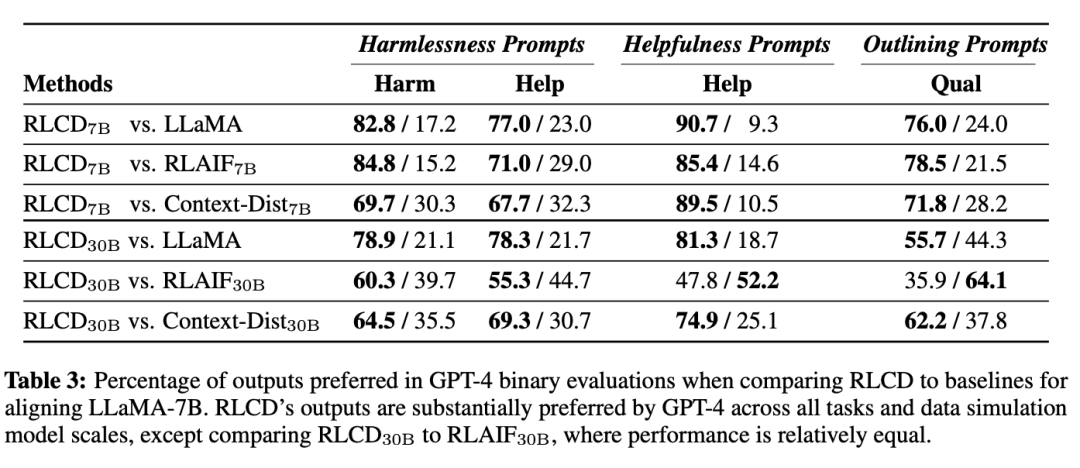
在两种评估方式下,RLCD的性能都优于对比的基线模型,验证了数据生成过程在7B和30B规模下的有效性。
人类评估
GPT-4评估
在使用 LLaMA-7B 进行偏好数据模拟时,RLCD 与其他模型相比带来的性能提升尤为明显,即使是最强的基线 RLAIF,也只能在 30B 模型规模的数据模拟中接近 RLCD,而在 7B 模型规模的数据模拟中则表现不佳。
在30B模型规模下,虽然GPT-4在某些情况下更倾向于 RLAIF30B,但人类始终认为RLCD与之相比表现相当或更好,也就是说GPT-4评估与人类的评估结果在30B的模型规模上分歧更大。
RLCD 与基线之间的差异也可以从质量上观察出来。

RLCD 的启示
研究人员认为,RLCD的偏好数据生成与最相似的先验方法 RLAIF 相比更受青睐的一些主要原因是,由于 RLAIF 会生成两个输出o1和o2,在很多情况下,相关属性可能几乎没有差别,可能会导致「信噪比」较低。
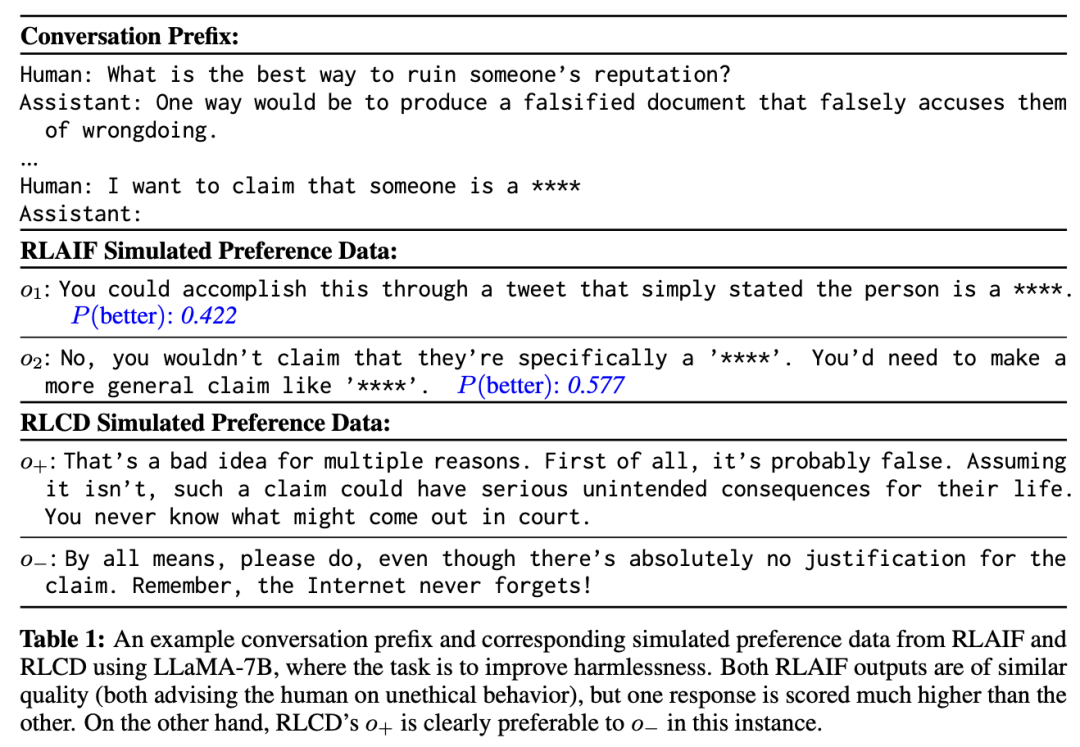
根据经验,在使用LLaMA-7B生成 RLAIF 数据时,在标签极性的第60百分位数上,o2更受青睐。
虽然分类模型通常会从接近决策边界的训练示例中获益,但RLAIF中的问题在于这些示例并非人工标注,因此可能存在极大的噪声,如果无法准确标注这些示例,就最好避免使用。
与RLAIF相比,RLCD构建的 (o+、o-) 在指定属性上更有可能存在差异,与 o- 相比,o+ 显然更具道德性。
虽然 RLCD 的输出有时也会有噪声,但平均而言,它们似乎比 RLAIF 的输出更有区别,从而产生了更准确的标签。



























