近年来深度学习,在图像与自然语言处理领域取得显著成效.而这其中像ResNet、Transformer等网络发挥着巨大作用。本系列以https://github.com/lukas-blecher/LaTeX-OCR为例,阐述下如何基于人工智能技术实现latex公式识别服务。本系列主要分为3篇,分别从系统构建(环境+训练)、系统原理(代码层面)、系统的增强三个部分展开论述。
环境构建
查看cuda版本
下面看到,cuda版本最高支持到12.1,我们下面选用的cu116。
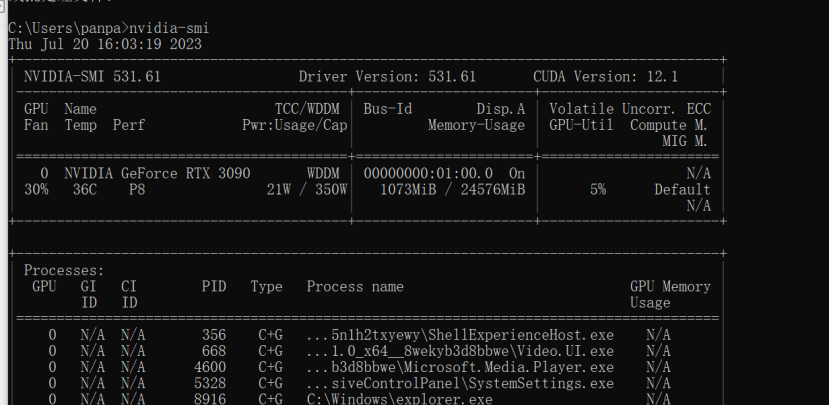
gpu版本查看
创建conda环境
conda env create -f 下述文件。
name: latex3.9
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- conda-forge
dependencies:
- python=3.9
- pip
- pip:
- tqdm>=4.47.0
- munch>=2.5.0
- torch==1.13.1+cu116
- opencv_python_headless>=4.1.1.26
- requests>=2.22.0
- einops>=0.3.0
- x_transformers==0.15.0
- transformers>=4.18.0
- tokenizers>=0.13.0
- numpy>=1.19.5
- Pillow>=9.1.0
- PyYAML>=5.4.1
- pandas>=1.0.0
- timm==0.5.4
- albumentations>=0.5.2
- pyreadline3>=3.4.1
- python-Levenshtein>=0.12.2
- torchtext>=0.6.0
- imagesize>=1.2.0
- wandb>=0.15.5
- --extra-index-url https://download.pytorch.org/whl/cu116检查pytorch与gpu是否兼容
import torch
if torch.cuda.is_available():
cuda_version = torch.version.cuda
print(f"PyTorch CUDA版本为: {cuda_version}")
# 检查CUDA版本是否与PyTorch兼容
if torch.backends.cudnn.version() is None:
print("PyTorch不支持当前CUDA版本")
else:
print("PyTorch支持当前CUDA版本")
else:
print("PyTorch不支持GPU加速")数据准备
准备数据(包括训练集+验证集+测试集)
现在训练测试数据集,然后放的位置很讲究!
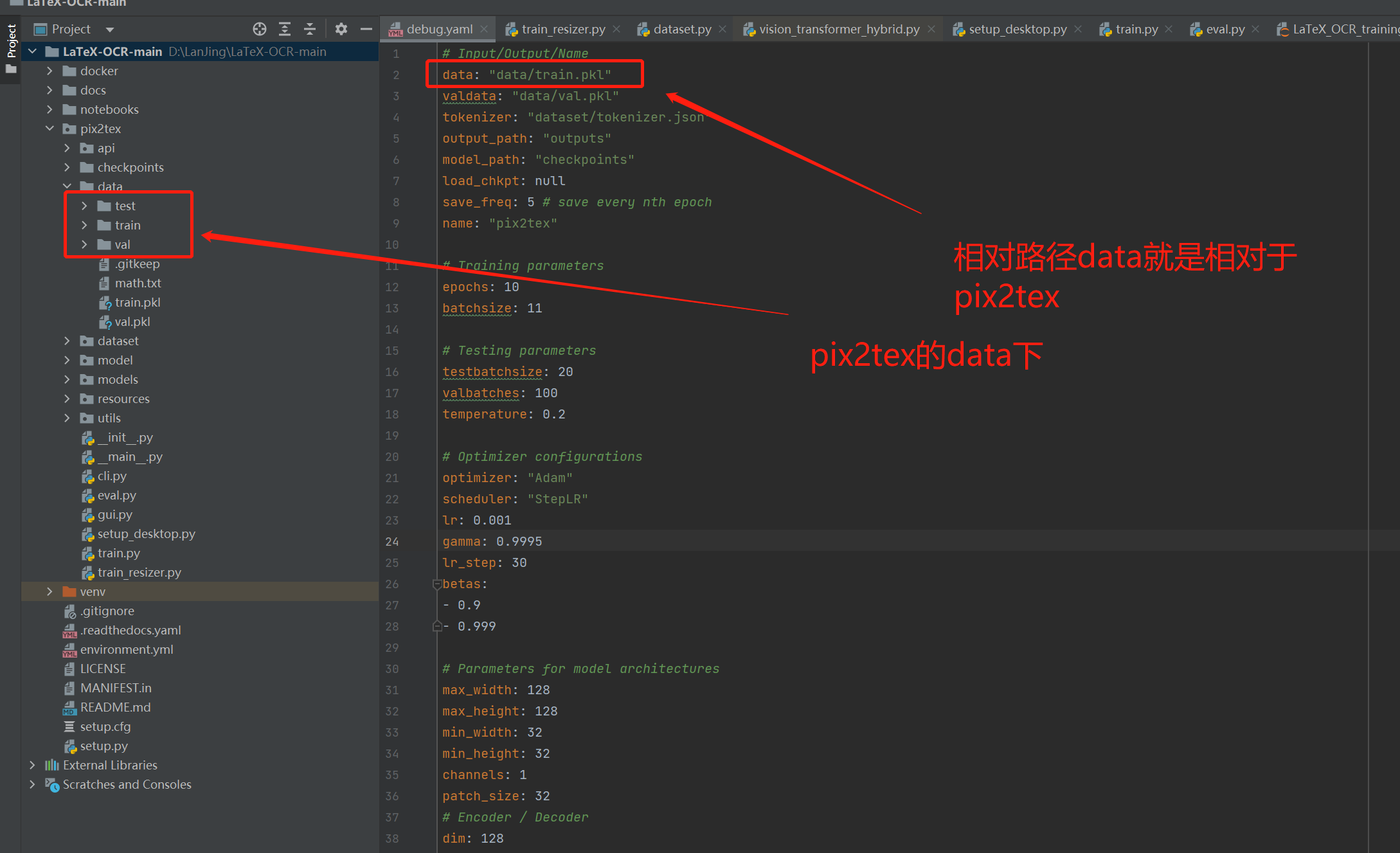
数据存放位置
- activate latex3.9 (这个在windows上执行,linux上 conda activate latex3.9)
- python -m pix2tex.dataset.dataset --equations data/math.txt --images data/train --out data/train.pkl
- python -m pix2tex.dataset.dataset --equations data/math.txt --images data/val--out data/val.pkl
- python -m pix2tex.dataset.dataset --equations data/math.txt --images data/test--out data/test.pkl
训练调试
Pycharm上debug训练代码
注:参数--config D:\LanJing\LaTeX-OCR-main\pix2tex\model\settings\debug.yaml --debug。
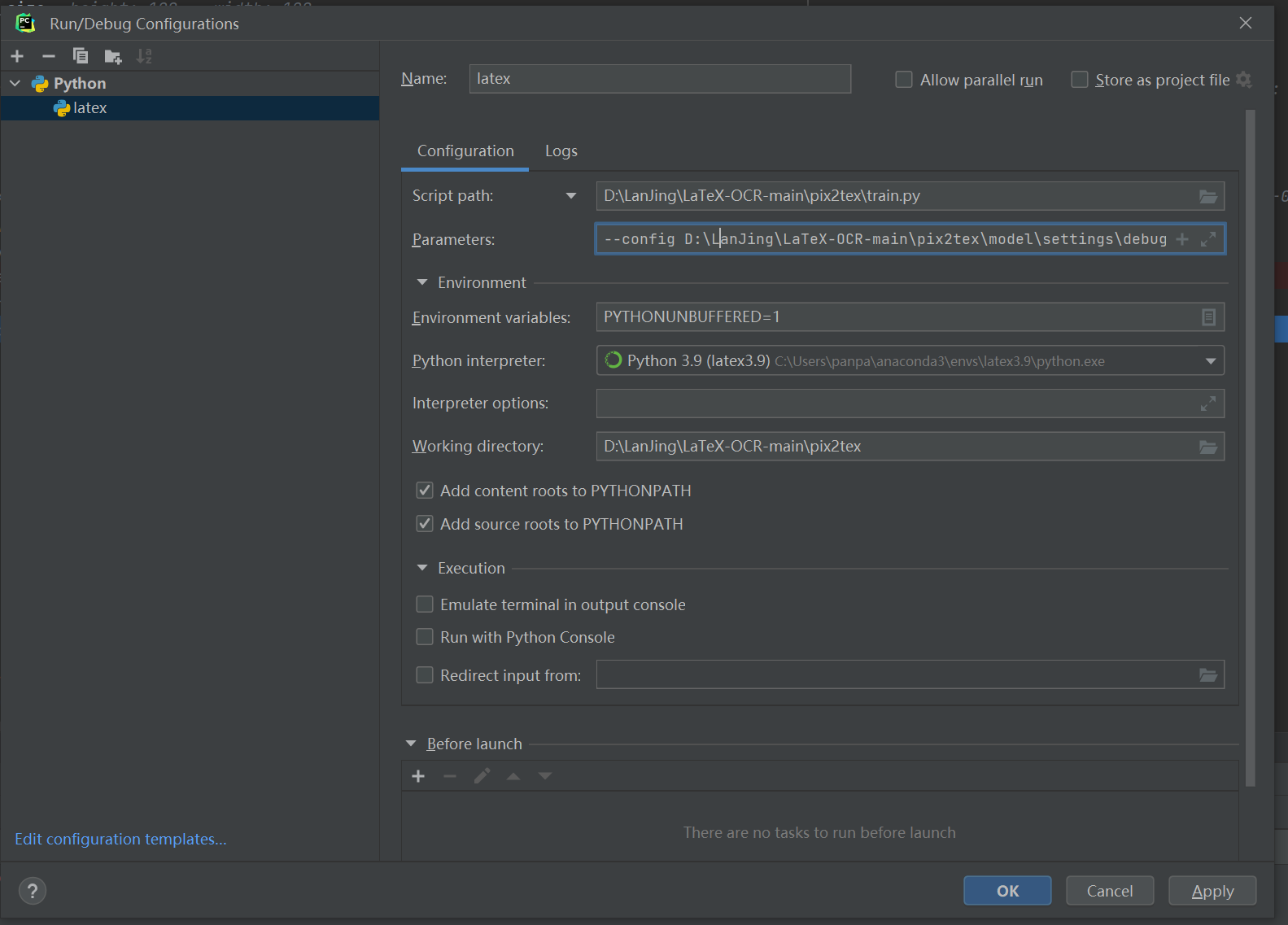
pycharm配置
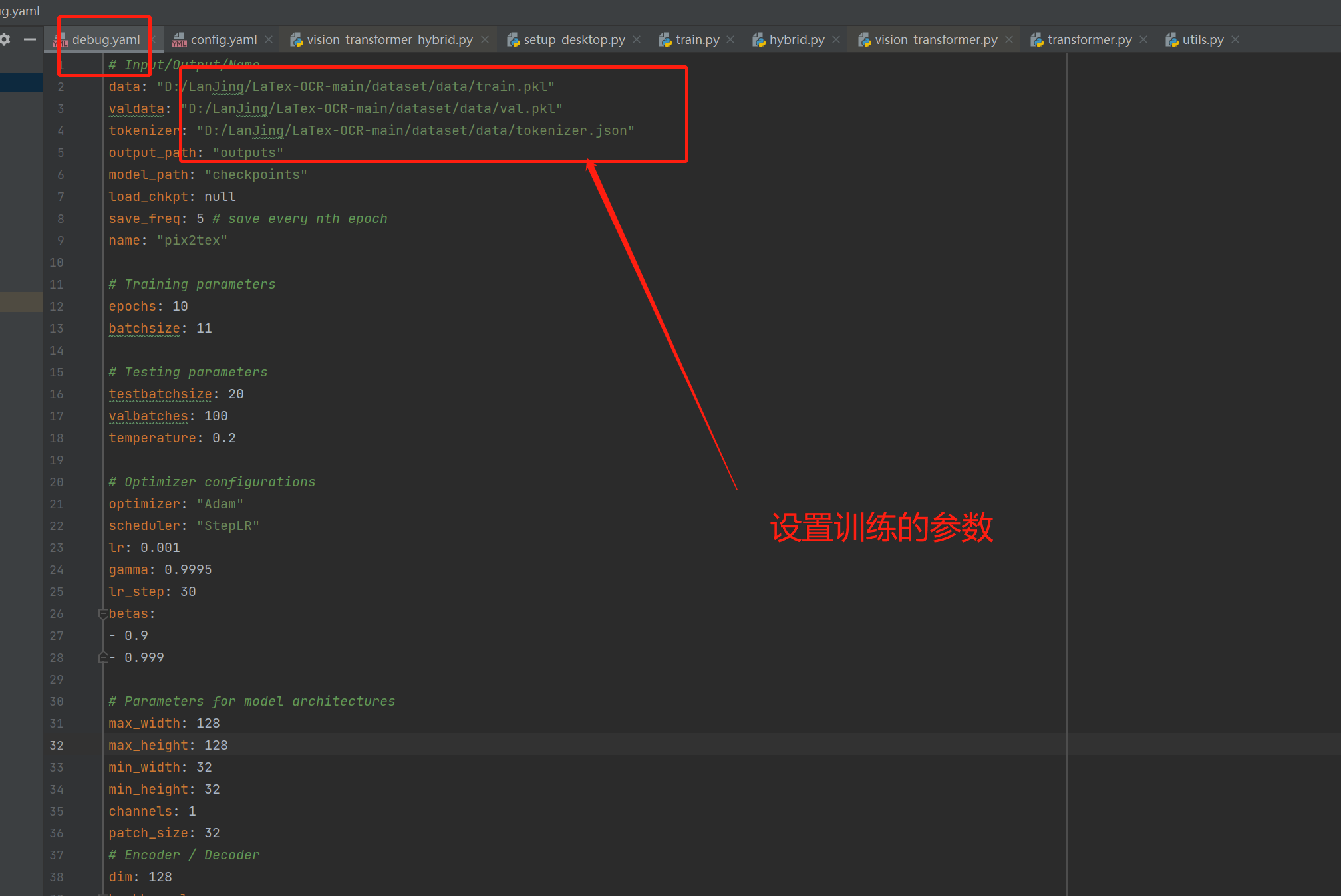
debug.yaml配置修改
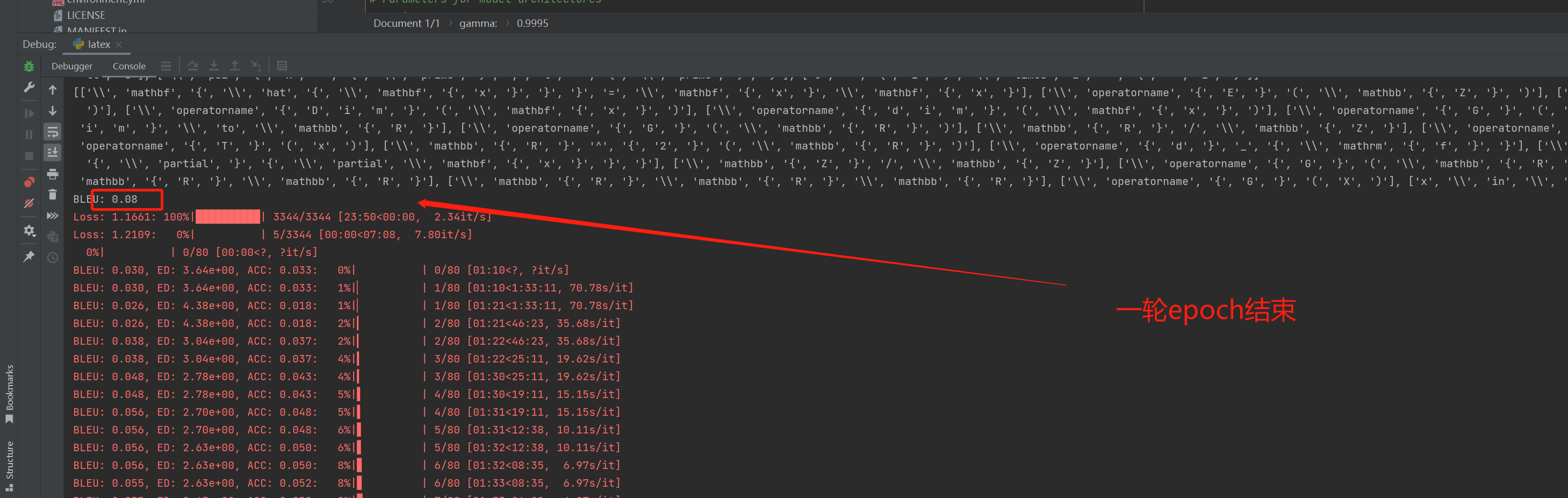
一轮epoch结束
加速训练
为了加速训练过程,可以使用提供的权重,并更新配置文件使用权重。该步骤也叫做fine tune。
下载 https://github.com/lukas-blecher/LaTeX-OCR/releases/download/v0.0.1/weights.pth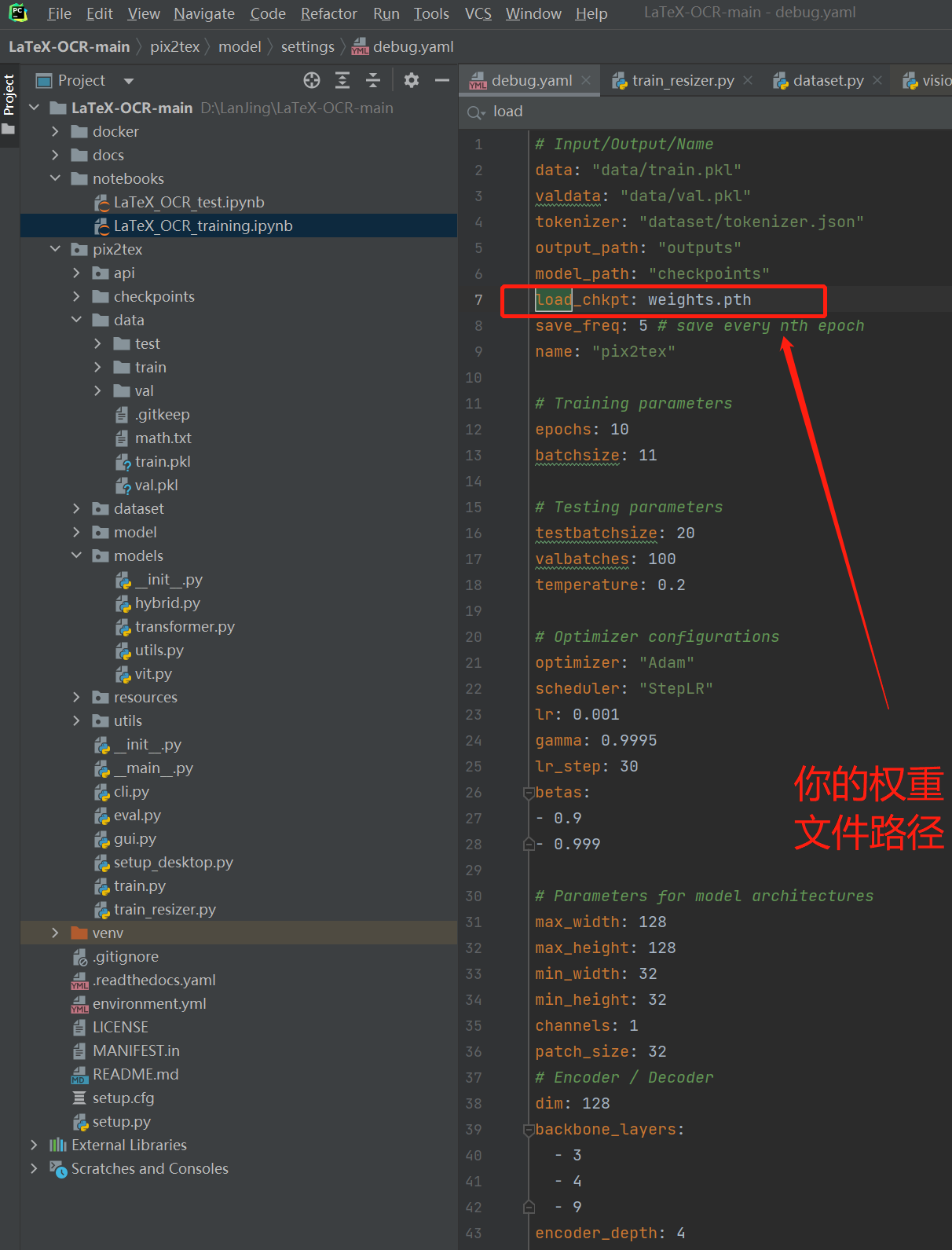
访问权重路径
训练测试数据
https://drive.google.com/drive/folders/13CA4vAmOmD_I_dSbvLp-Lf0s6KiaNfuO。

数据集解释
接下来在第二篇中我会重点介绍下,代码的实现,如何构建这样一个训练网络,以及它的关键代码,尤其是数据shape是如何变化的。