












大型语言模型(LLM)和视觉语言模型(VLM)在各种评测基准中都展现出了强大的性能,比如可以看图说话、进行常识推理。
但这些模型的训练过程并没有引入3D物理世界,也就无法理解更丰富的现实概念,包括空间关系、布局、物体反馈等。
最近,加州大学洛杉矶分校、上海交大、华南理工大学、麻省理工学院等机构的研究人员联合提出了一个全新的3D-LLM任务,把3D世界的知识注入到大型语言模型中,以3D点云及其特征作为输入,从而可以执行各种3D相关的任务,包括描述生成、3D问题回答、任务分解、3D辅助对话、导航等。

论文链接:https://arxiv.org/pdf/2307.12981.pdf
基于这个思路,研究人员设计了三种类型的提示机制,收集了超过30万的3D语言数据来支持上述任务。
为了有效地训练3D-LLM,首先使用从渲染的多视图图像获得3D特征的3D特征提取器,再用2D VLMs作为模型的骨干来训练3D-LLM网络;通过引入3D定位机制,3D-LLM可以更好地捕获3D空间信息。
在ScanQA上的实验结果表明,该模型显著优于最先进的基线模型,例如,BLEU-1指标上的性能提升达到9%

此外,在3D描述生成、3D辅助对话等数据集上的实验表明,该模型优于2D VLMs
定性结果也表明,该模型可以执行超出现有的LLM和VLM能力范围的一些任务。
三维语言数据生成
从互联网上可以轻松获取海量的二维图像和相应文本的数据对,不过三维多模态数据的获取却非常困难,网络上的三维资产非常稀缺,而且提供文本标注也更有挑战。
现有的三维语言数据,如ScanQA、ScanRefer等在数量和多样性方面都很有限,而且每个数据集都仅限于一项任务,如何自动生成一个可用于各种三维相关任务的三维语言数据集非常值得深入研究。
受GPT等大型语言模型的启发,研究人员提出利用此类模型来收集3D语言数据。

具体来说,主要有三种方法来提示纯文本GPT模型来生成数据:
1. 基于boxes-demonstration-instruction的提示。
输入三维场景中房间和物体的轴对齐包围框(AABB),提供场景的语义和空间位置信息,然后向GPT模型提供具体指令,以生成多样化的数据。
研究人员给GPT模型提供0-3个少样本演示示例,用来指示生成的数据类型。
2. 基于ChatCaptioner的提示。
使用ChatGPT输入提示询问一系列关于图像的有信息量的问题(informative questions),然后用BLIP-2模型回答这些问题。
为了收集三维相关数据,研究人员将不同视角的图像输入 BLIP-2,然后要求ChatGPT提问并收集不同区域的信息,从而形成整个场景的全局三维描述。
3. 基于revision的提示,可用于将一种三维数据迁移到到另一种类型的三维数据。
经过上述流程,GPT能够生成各种类型的三维语言数据,主要基于下列三维资产:
1. Objaverse,包含80万个三维物体,不过由于语言描述是从在线资源中提取的,未经人工检查,因此大多数对象的描述都包括大量噪声,比如网址等,或是无法生成描述。研究人员利用基于 ChatCaptioner 的提示功能为场景生成高质量的 3D 相关描述。
2. Scannet,包含约1000个3D室内场景的富标注数据集,提供了场景中物体的语义和边界框。-
3. Habitat-Matterport (HM3D) ,具身人工智能(embodied AI)的三维环境数据集。HM3DSem为HM3D的200多个场景进一步添加了语义注释和边界框。
3D-LLM
3D特征抽取器
训练3D-LLM的第一步是建立有意义的3D特征,使之可以与语言特征相匹配,但由于缺乏大规模三维资产数据集,所以无法采用预训练的方式学习表征。
受到从二维多视角图像中提取三维特征的方法启发,研究人员提出通过渲染多个不同视角的三维场景来提取三维点的特征,并从渲染的图像特征中构建三维特征。
首先提取渲染图像的像素对齐密集特征,然后针对不同类型的三维数据,设计了三种方法从渲染图像特征中构建三维特征:
1. 直接重建(direct reconstruction)
基于3D数据,使用真实相机矩阵,直接从三维数据渲染的rgbd图像中重建点云,将特征直接映射到重建的三维点。
这种方法适用于具有完美相机姿势和内在特征的 rgbd 渲染数据。
2. 特征融合(feature fusion)
使用gradslam将二维特征融合到三维映射中,与稠密映射方法不同的是,除了深度和颜色之外,模型还融合了其他特征。
这种方法适用于具有噪声深度图渲染或噪声相机姿势和内在特征的三维数据。
3. 神经场(neural field)
利用神经voxel场构建三维紧凑表征,具体来说,除了密度和颜色外,神经场中的每个voxel都有一个特征,可以利用 MSE 损失对射线中的三维特征和像素中的二维特征进行对齐。
这种方法适用于有 RGB 渲染但无深度数据的三维数据,以及有噪声的相机姿态和本征。
训练3D-LLMs
考虑到使用三维特征提取器可以将三维特征映射到与二维图像相同的特征空间,因此使用这些二维视觉语言模型作为3D-LLM的骨干是合理的。
鉴于三维特征与三维特征抽取器提取的二维特征处于相同的特征空间,而且感知器能够处理相同特征维度的任意输入大小,因此任意大小的点云特征也可以输入到感知机中。
因此,研究人员使用三维特征提取器在与冻结图像编码器特征相同的特征空间中提取三维特征,然后使用预训练二维视觉语言模型作为骨干网络,输入对齐的三维特征和收集的3D语言数据集来训练3D语言模型。
3D定位机制
除了建立与语言语义相匹配的三维特征外,捕捉三维空间信息也至关重要。
研究人员提出了一种三维定位机制,以提高三维LLMs吸收空间信息的能力。
该机制由两部分组成:
1. 用位置嵌入增强三维特征,将所有嵌入串联起来作为最终特征
2. 将三维位置放入嵌入词汇表,用AABB的形式表示边界框,连续角坐标被统一离散为voxel整数,在语言模型的输入和输出嵌入中解冻这些token的权重。
实验部分
从ScanQA验证集和测试集的实验结果中可以看到,几乎所有的评估指标都得到了明显提升。
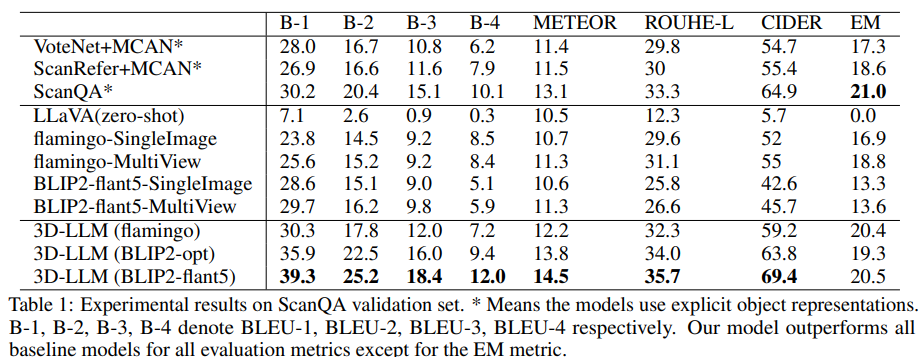
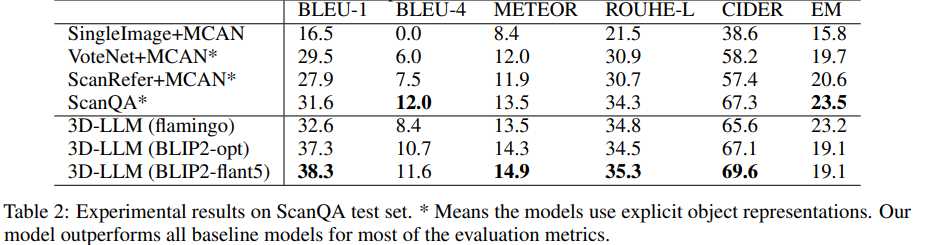
例如,对于BLEU-1指标,该模型在验证集上比最先进的ScanQA模型高出约9%,在测试集上高出约7%。
这些结果表明,通过将3D注入LLM,模型生成的答案与真实答案更为相似。
此外,基于3D的基线使用对象检测器(如 VoteNet)来分割对象,然后将每个对象的特征发送到它们的模型中,而文中提出的模型输入是整体3D特征,没有显式的对象表征。
结果表明,即使没有明确的对象表征,该模型也能对物体及其关系进行视觉推理。
还可以发现,以单视角图像或多视角图像作为输入,二维VLM的性能会比三维VLM下降很多,也就是说多视角图像也包含整个场景的信息,但与3D-LLM相比,3D VLM的性能仍然要低得多,可能是因为多视角图像的特征是无序的,从而丢失了与3D有关的信息。























