可视化是以图形形式表示数据或信息的过程。在本文中,将介绍Seaborn的最常用15个可视化图表。
Seaborn是一个非常好用的数据可视化库,它基于Matplotlib,并且提供了一个高级接口,使用非常见简单,生成图表也非常的漂亮。

安装
安装非常简单:
在使用时只要导入就可以了。
Seaborn提供了一些内置的数据集,这里我们使用Seaborn的Iris数据集。
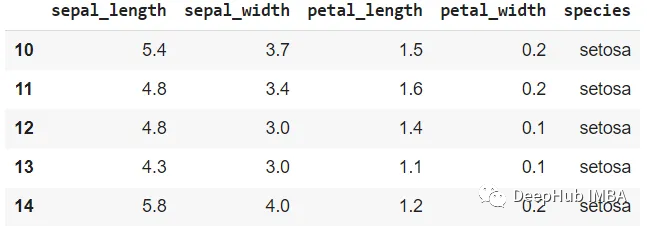
我们看看数据量

1、条形图
条形图用于表示分类变量,它只显示平均值(或其他估计值)。我们为x轴选择一个分类列,为y轴(花瓣长度)选择一个数值列,我们看到它创建了一个为每个分类列取平均值的图。

2、散点图
散点图是由几个数据点组成的图。x轴表示花瓣长度,y轴表示数据集的萼片长度。

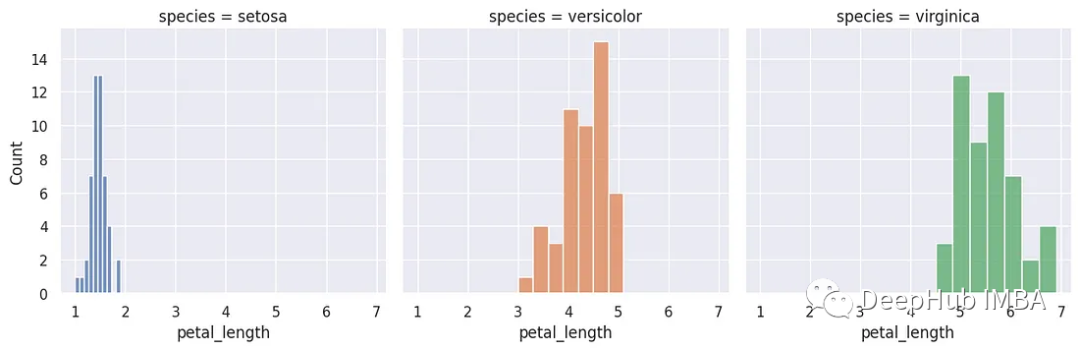
3、直方图
直方图通常用于可视化单个变量的分布,但它们也可用于比较两个或更多变量的分布。除了直方图之外,KDE参数还可以用来显示核密度估计(KDE)。这里,我们使用萼片长度。
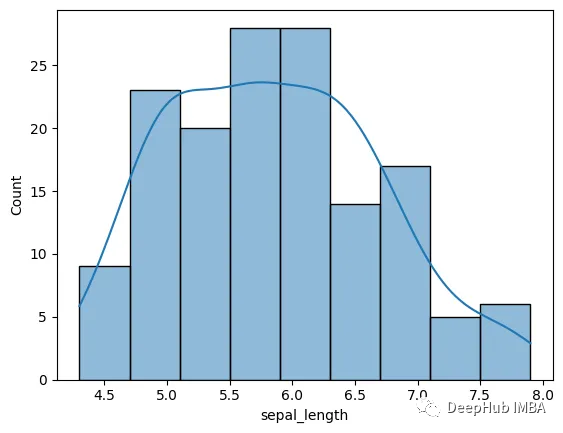
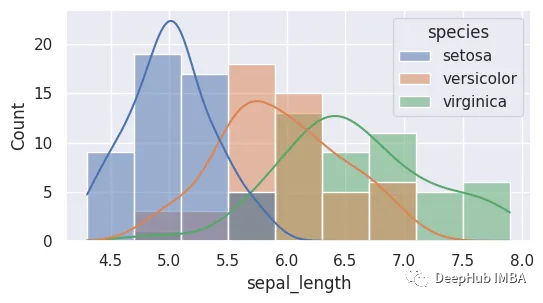
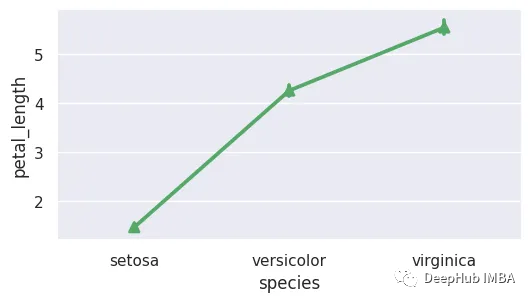
4、线形图
线形图可以用来可视化各种不同的关系。它们易于创建和分析,在线形图中每个数据点由直线连接。

5、小提琴图
小提琴图可以表示数据的密度,数据的密度越大的区域越胖。“小提琴”形状表示数据的核密度估计,每个点的形状宽度表示该点的数据密度。
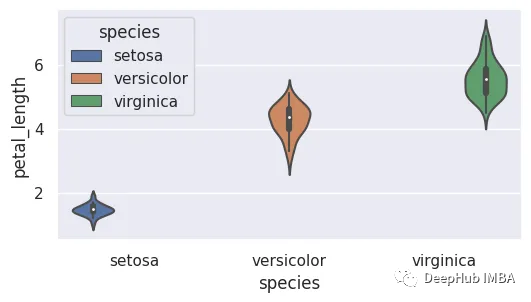
6、箱线图
箱形图由一个箱形图和两个须状图组成。它表示四分位数范围(IQR),即第一和第三四分位数之间的范围。中位数由框内的直线表示。须状图从盒边缘延伸到最小值和最大值的1.5倍IQR。异常值是落在此范围之外的任何数据点,并会单独显示出来。
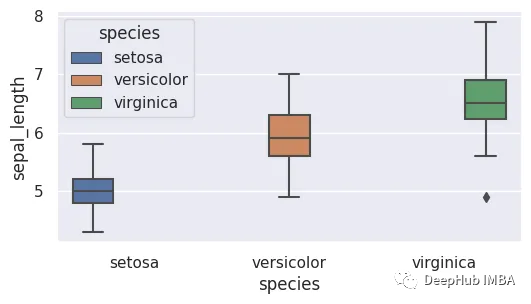
7、热图
热图是数据的二维可视化表示,它使用颜色来显示变量的值。热图经常用于显示数据集中的各种因素如何相互关联,比如相关系数。

8、点图
点图是一种统计图表,用于显示一组数据及其变异性的平均值或集中趋势。点图通常用于探索性数据分析,可以快速可视化数据集的分布或比较多个数据集。
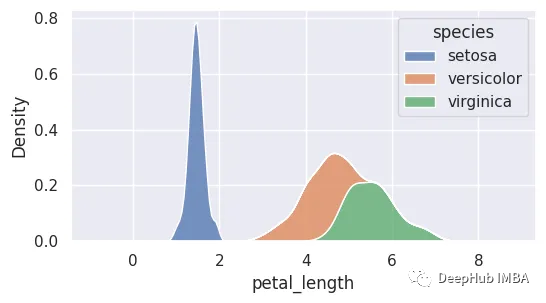
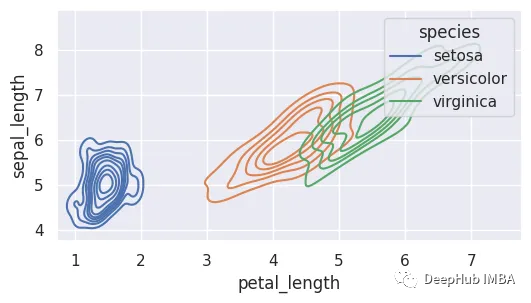
9、密度图
密度图通过估计连续随机变量的概率函数来表示数据集的分布,也称为核密度估计(KDE)图。
10、计数图
计数图是一种分类图,它显示了分类变量的每个类别中观测值的计数。它本质上是一个柱状图,其中每个柱的高度代表特定类别的观测值的数量。

11、分簇散点图
分簇散点图与条形图相似,但是它会修改一些点以防止重叠,这有助于更好地表示值的分布。在该图中,每个数据点表示为一个点,并且这些点的排列使得它们在分类轴上不会相互重叠。

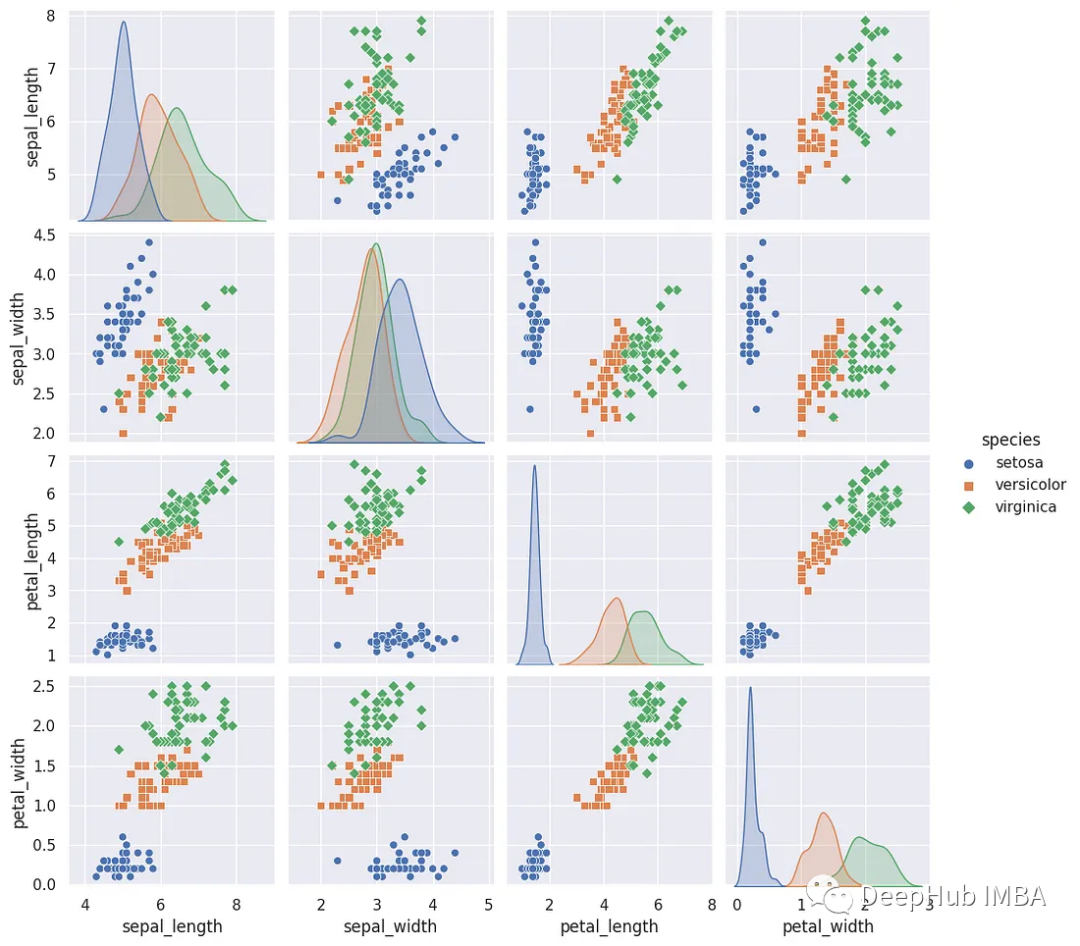
12、配对图
配对图可视化了数据集中几个变量之间的成对关系。它创建了一个坐标轴网格,这样所有数值数据点将在彼此之间创建一个图,在x轴上具有单列,y轴上具有单行。对角线图是单变量分布图,它绘制了每列数据的边际分布。
13、Facet Grid
Seaborn中的FacetGrid函数将数据集和一个或多个分类变量作为输入,并创建一个图表网格,每种类别变量的组合都有一个图表。网格中的每个图都可以定制为不同类型的图,例如散点图、直方图或箱形图。
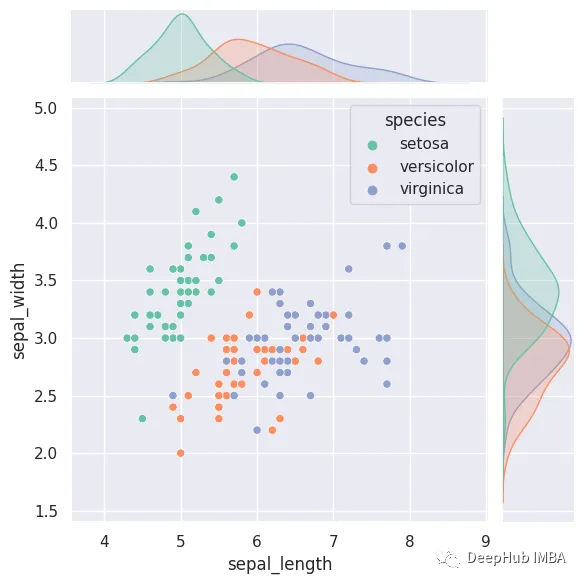
14、联合分布图
联合分布图将两个不同的图组合在一个表示中,可以展示两个变量之间的关系(二元关系)。
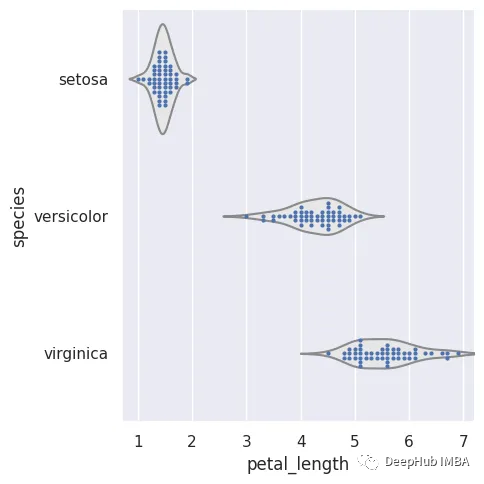
15、分类图
cat图(分类图的缩写)是Seaborn中的定制的一种图,它可以可视化数据集中一个或多个分类变量与连续变量之间的关系。它可用于显示分布、比较组或显示不同变量之间的关系。
总结
Seaborn对于任何使用Python处理数据的人来说都是一个非常好用的工具,它易于使用,并且提供更美观的图形使其成为探索和交流数据最佳选择。它与其他Python数据分析库(如Pandas)的集成使其成为数据探索和可视化的强大工具。