现在,开发者都在悄悄使用AI生成的数据来训练AI模型。
原因就是——人类创造的数据,实在是太贵了!
在以往,大多数AI模型都是靠人类的数据训练的,但现在,越来越多的公司(包括OpenAI、微软,以及Cohere这样的初创公司)都开始使用这种AI生成的「合成数据」,或者在努力搞清如何使用AI生成的数据了。
虽然,这会让整个AI生态系统变成一种自己吃自己的「贪吃蛇」,但是,人类自己创造的数据,实在是负担不起了啊!
互联网上的人类数据快耗尽了
除了价格,另外还有一个原因,就是规模问题。
现在,互联网上很多可用的人类数据都被薅干净了,可是如果要构建更强大的模型,就需要更多数据。
去年11月,ChatGPT的推出引爆了大模型之战,谷歌、微软、Meta、Anthropic等大科技公司轮番下场,三不五时就更新一波新产品。
而像ChatGPT和Bard这样的聊天机器人背后的LLM,主要就是通过抓取互联网数据来训练的,包括所有数字化书籍、新闻文章、博客、搜索查询、Twitter和Reddit帖子、YouTube视频、Flickr图像等等。
但现在,生成式AI变得越来越复杂,即使是很多财力雄厚的大公司,也耗尽了易于访问的高质量数据,来训练AI模型。
与此同时,因为训练AI所消耗的个人数据数量庞大,来源广泛,他们也在不断承受着全世界各地的监管机构、艺术家和媒体的抨击。
大家早就在悄悄用了
开发者纷纷表示,来自网络的通用数据,已经不足以推动人工智能模型的性能。
Cohere首席执行官Aiden Gomez在接受《金融时报》采访时表示,如果能从网上获取需要的所有数据,就太完美了。
然而可惜的是,互联网上的信息如此嘈杂、混乱,以至于它们并不能代表开发者真正想要的数据。

其实,Cohere早就在悄悄用合成数据训练LLM了,虽然这个消息还未被广而告之。
而OpenAI之类的公司,也在做此打算。
在五月份于伦敦举行的一次活动中,OpenAI CEO Sam Altman被问及是否担心对ChatGPT隐私侵犯风险的监管调查。
Altman对此不以为意,云淡风轻地表示,很快所有的数据都会变成合成数据,他对此非常有信心。
合成数据潜力巨大
合成数据,似乎前途大好。
而微软已经发表了一项研究,来论证合成数据如何加强基本的LLM。

论文地址:https://arxiv.org/pdf/2306.11644.pdf
如今,像GPT-4这类最前沿的模型,在写作和编码等领域的表现已经在接近人类,还能通过美国律诗考试等基准测试。
为了显著提高性能,让它们能够应对科学、医学或商业方面的挑战,就需要使用独特而复杂的数据集来训练AI模型。
这些数据集要么需要由科学家、医生、作家、演员或工程师等专家创建,要么需要作为专有数据,从制药、银行和零售商等大公司获得。
然而,人类创造的数据集,价格太昂贵了。
如果使用合成数据,成本就会大大降低。
公司可以用AI模型来生成与医疗保健、金融欺诈等领域相关的文本、代码或更复杂的信息,然后用这些合成数据来训练高级LLM,让它们性能更强。
Gomez透露,Cohere及其几个竞争对手早就在使用合成数据,然后由人类进行微调和调整了。现在很多地方都在大量采用合成数据了,尽管这个消息还没有大量公开。
Gomez解释道,比如为了训练一个高等数学模型,Cohere就会让两个AI模型对话,一个充当导师,一个充当学生。
它俩会谈论三角学,所有对话都是合成的、靠模型想象出来的。
然后人类会检查这个对话,如果模型说错了,人类就去纠正。
微软最近的两项研究表明,合成数据可以用来训练比OpenAI的GPT-4或Google的PaLM-2这类先进模型更小、更简单的模型。
一篇论文描述了由GPT-4生成的短篇小说的合成数据集,它只包含了四岁孩子能理解的单词。

论文地址:https://arxiv.org/pdf/2305.07759.pdf
这个数据集被称为TinyStories,它被用来训练一个简单的LLM,它会讲出流利和语法正确的故事。
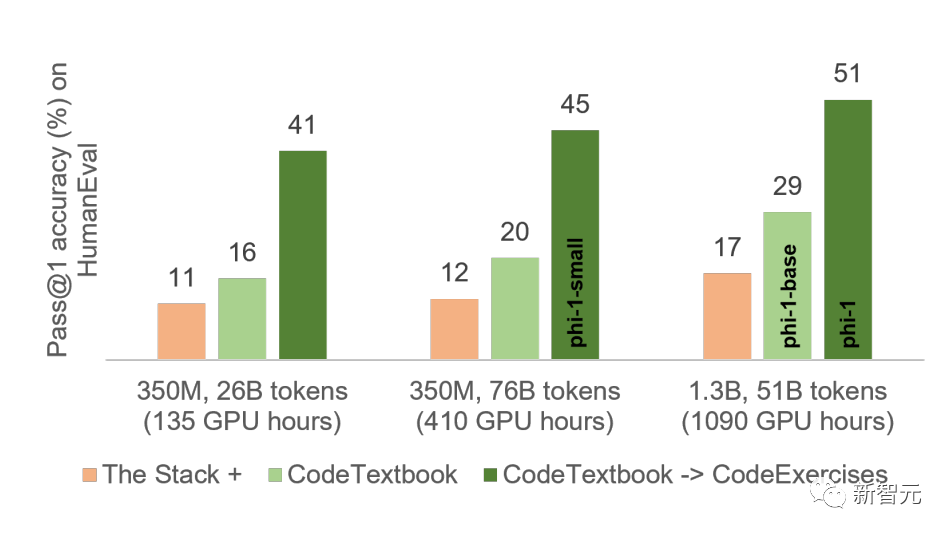
另一篇论文表明,人工智能可以以教科书和练习的形式进行合成Python代码的训练,这些代码在编码任务上表现得很好。
Scale AI和Gretel.ai等初创企业也如雨后春笋般涌现,它们提供的,就是合成数据即服务。
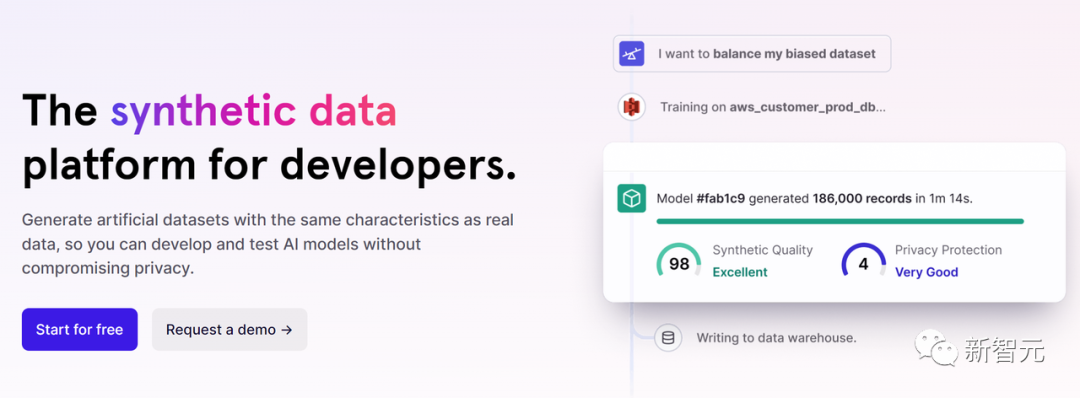
Gretel由来自NSA和CIA的前美国分析师成立,与谷歌、汇丰银行、Riot Games和Illumina等公司合作,用合成数据训练更好的AI模型。
根据Gretel CEO Ali Golshan的说法,合成数据关键就在于,它保留了数据集中的所有个人隐私,同时仍然保持了统计上的完整性。
并且,精心制作的合成数据还可以消除现有数据中的偏见和不平衡。
「对冲基金可以查看黑天鹅事件,还能创建一百种变体,看看我们的模型是否会失败。」
对于银行来说,欺诈通常占总数据的不到100%,而Gretel的软件可以生成「数千个关于欺诈的边缘案例场景,并用于训练AI模型。
AI贪吃蛇,可行吗?
当然,用AI「自产自销」的贪吃蛇式数据,也存在着巨大的问题。
就算是在人类数据上训练出来的AI,都会出现重大的事实性错误,更何况AI自己生成数据呢。
批评者指出,并非所有合成数据都会经过精心策划,以反映或改进现实世界的数据。
随着AI生成的文本和图像开始充斥互联网,人工智能公司很可能最终会使用由自己模型的原始版本产生的原始数据——这种现象被称为「狗粮」。
斯坦福大学和莱斯大学的科学家发现,将人工智能生成的内容提供给人工智能模型,似乎会导致它们的输出质量下降。

论文地址:https://arxiv.org/abs/2307.01850
这种类似贪吃蛇的自我消费,会打破模型的数字大脑。
莱斯大学和斯坦福团队发现,将AI生成的内容喂给模型,只会导致性能下降。研究人员对此给出一种解释,叫做「模型自噬障碍」(MAD)。
研究发现在使用AI数据,经过第5次迭代训练后,模型就会患上MAD。
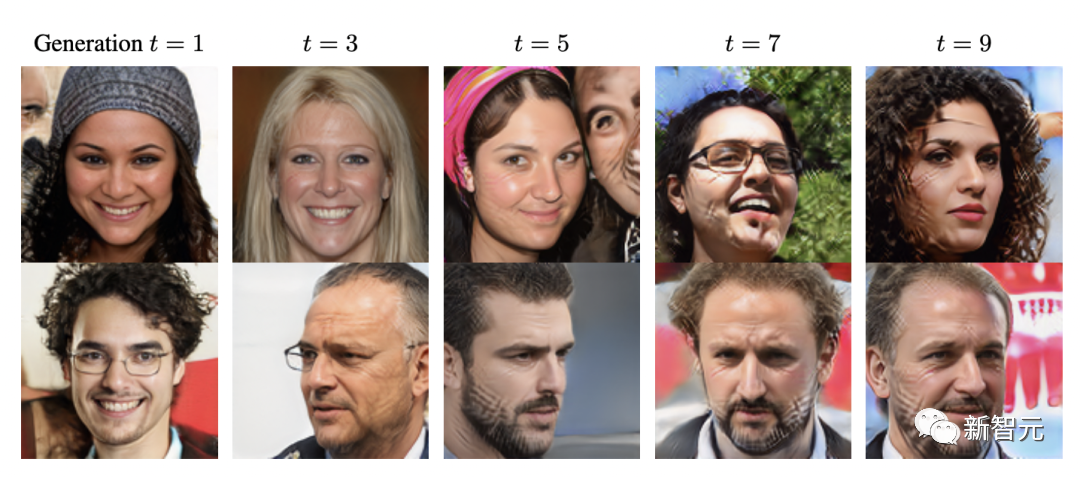
在合成数据上训练AI模型会逐渐放大伪影
换句话说,如果不能给模型提供「新鲜的数据」,即由人类标注的数据,其输出质量将会受到严重影响。
而牛津大学和剑桥大学的研究者也发表了论文,发出警告说,在自己的原始输出上训练人工智能模型,其中可能包含虚假或捏造,会随着时间的推移,这些数据或许会破坏模型,导致「不可逆转的缺陷」。

论文地址:https://arxiv.org/pdf/2305.17493v2.pdf
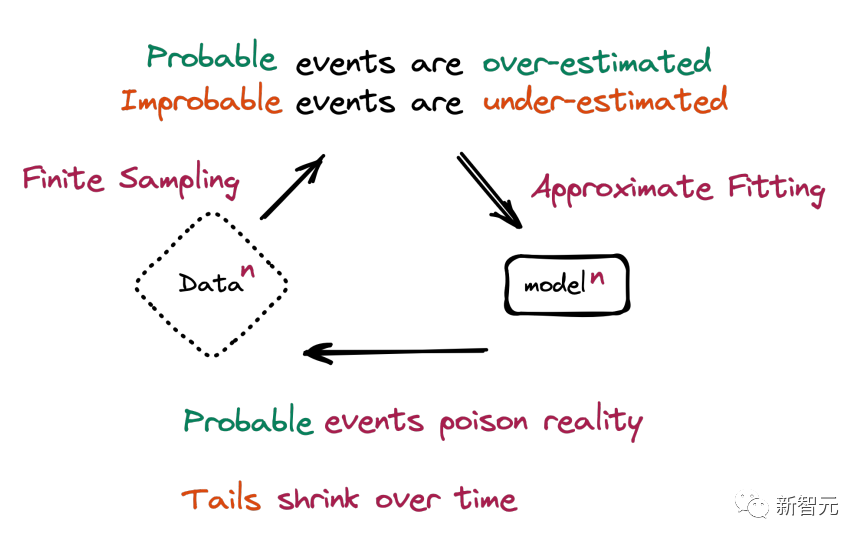
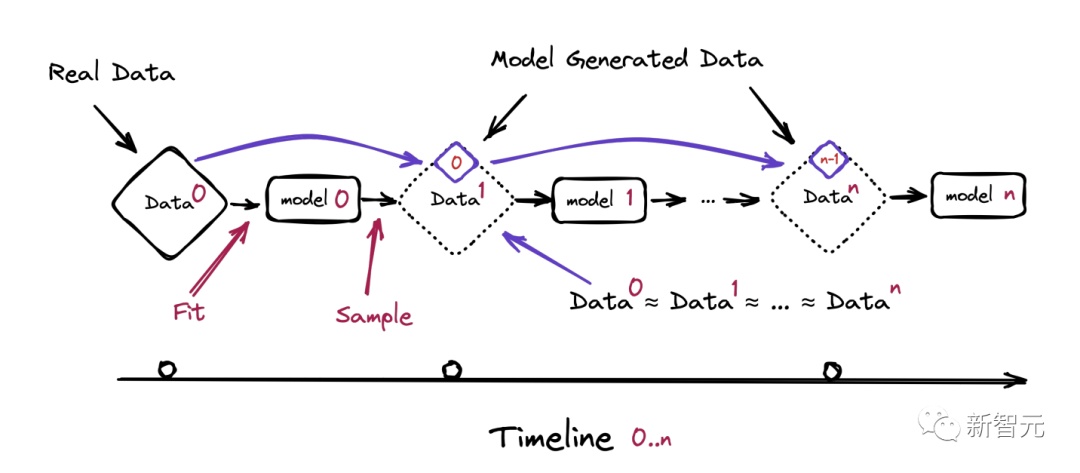
AI,你赶快学会自学吧
Golshan同意,如果用糟糕的合成数据进行训练模型,可能会阻碍它们的进步。
「随着互联网上充斥着越来越多AI生成的内容,确实会导致模型退化,因为它们在产生反刍的知识,没有产生任何新的见解。」
尽管存在这些风险,但Cohere的Gomez等AI研究人员仍然表示,合成数据有望加速通往超级智能AI系统的道路。
CEO Gomez这样说道:你真正需要的,就是能够自学的AI模型——自己提出问题,自己发现真理,自己创造知识,这就是人类的梦想。
网友展开激烈辩论
对此,多位网友发表了高见。
合成数据有以下好处——
👍 合成数据可以潜在地解决使用真实世界数据会产生的隐私问题。
👍 针对特定需求创建的合成数据,可能具有更高的质量,从而产生更准确的AI模型。
👍 训练高级AI模型对数据的需求正在飙升。合成数据几乎能无限供应,大大减少了数据赤字。

但是,AI训练AI背后的目的至关重要:
💡如果我们的目标是创建帮助人类的人工智能模型,那么对人类生成的数据进行训练可能更合适。这确保了人工智能的反应和行为与我们自己的反应和行为更加一致,并且与我们相关。
💡如果我们的目标是创建超级智能AI,那么合成数据可能是关键,它让模型能够从超出人类理解能力的模型中学习。
👎我们已经看到很多例子,人工智能从合成数据中自我学习导致结果质量下降。所以,现在的答案在于真实世界的合成数据和用于训练的专家数据的平衡组合。可解释性AI是解释如何确定模型结果的绝对关键。

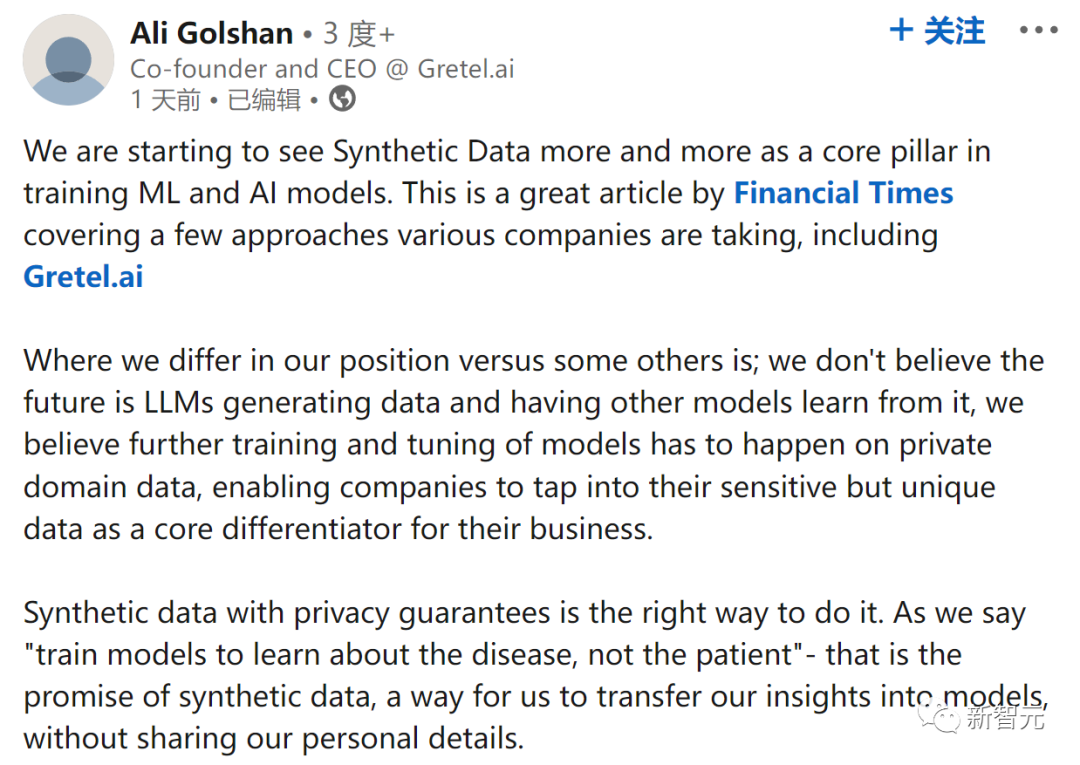
我的立场和其他人不同:我不认为在未来应该让LLM生成数据并让其他模型从中学习,我认为,必须在私有领域数据上进行进一步的模型训练和调整,使公司能够利用其敏感但独特的数据,作为业务的核心差异化因素。
正确的方法是,具有隐私保证的合成数据。
正如我们所说,「训练模型是为了了解疾病,而不是了解患者」——这就是合成数据的承诺,我们是将自己的见解转移到模型中,而无需分享我们的个人详细信息。
1. 有些领域需要好的数据,而不是完美的数据,在这些地方合成数据将产生最大的影响。
2. 与此相关的是,质量将基于平均水平的范围,而不是极端情况下的杰出结果。
3. 如果技术人员设计的计算机制造数据被用于训练AI,就会加剧系统中的偏见——其中大多数是认知偏见——即使只是无意中, 因此,与其考虑有风险的工作类别,更好的方法可能是考虑哪些工作是体面的、必要的,但它只需要达到一定的阈值标准,而不是100%。
最后一点,很多人在讨论人工智能与工业革命的相似之处。在股市场上,被动投资基金和ETF的兴起也有很多相似之处,即现在大多数交易都是基于算法,而不是实际的人为干预完成的。
但这样的系统本质上往往是被动的,并且很容易被操纵。