












现如今已有大量提供深度学习服务的供应商,在使用这些服务时,用户需要将自己的信息包含在 prompt 中发送给这些服务商,这会导致隐私泄漏等问题。另一方面,服务商基本不愿意公开自己辛苦训练得到的模型参数。
针对这一问题,蚂蚁集团的一个研究团队提出了 PUMA 框架,可以在不影响模型性能的前提下实现安全的推理。不仅如此,他们也开源了相关代码。

- 论文:https://arxiv.org/abs/2307.12533
- 代码:https://github.com/secretflow/spu/blob/main/examples/python/ml/flax_llama7b/flax_llama7b.py
预训练 Transformer 模型在许多实际任务上都表现优良,也因此受到了很大关注,并且现在已经出现了不少基于这类技术的工具,它们常以「深度学习即服务(DLaaS)」范式提供服务。但是,这些服务常会有隐私问题,比如假如用户要使用 ChatGPT, 要么就需要用户向服务提供商提供自己的私人 prompt,要么就需要服务提供商将自己专有的训练得到的权重配置交给用户。
为了解决 Transformer 模型服务的隐私问题,一种解决方案是安全多方计算(Secure Multi-Party Computation),这可以在推理过程中保证数据和模型权重的安全。但是,多方计算(MPC)中简单基础的 Transformer 推理的时间成本和通信成本都很高,难以用于实际应用。为了取得更好的效率,已经有一些研究成果提出了多种加速 Transformer 模型安全推理的方法,但这些方法仍然存在以下一个或多个缺点:
- 替换很困难。近期一些工作提出,为了降低成本,可使用二次函数和 ReLU 函数等快速近似方法来替代高成本的 GeLU 和 softmax 等函数。但是,如果只是简单替换这些函数,可能会导致 Transformer 模型性能大幅下降(这可能就会需要额外再对模型进行训练,即微调)以及出现部署问题。
- 推理成本高。有研究提出使用更准确的多项式函数来近似高成本的非线性函数,但其近似方法并未考虑 GeLU 和 Softmax 的特殊性质。因此,使用近似之后,这种方法的成本依然很高。
- 不容易部署。最近也有些研究提出通过修改 Transformer 的模型架构来加速安全推理,例如分解嵌入过程并重新组织线性层。更糟糕的是,由于 Crypten 框架不支持安全 LayerNorm,因此如果仅使用 BatchNorm 模拟成本,就会导致安全推理得到不正确的结果。这些修改方式与现有的明文 Transformer 系统存在冲突。
综上所述,在 MPC Transformer 推理领域,模型性能和效率难以兼得,而人们可能会有如下问题:
能否安全又高效地评估预训练大型 transformer 模型,同时无需进一步再训练也能达到与明文模型相近的准确度。
蚂蚁集团提出的 PUMA 框架正是为了解决这一难题而生,该框架能够安全又准确地执行端到端的安全的 Transformer 推理。这篇论文的主要贡献包括:
- 用于近似非线性函数的新方法。文中提出了更加准确和快速的近似方法,可用于近似 Transformer 模型中高成本的非线性函数(如 GeLU 和 Softmax)。不同于之前的方法,新提出的近似方法基于这些非线性函数的特殊性质,可以兼顾准确度和效率。
- 更快更准确的安全推理。研究者使用 6 个 transformer 模型和 4 个数据集进行了广泛的实验,结果表明,相比于 MPCFORMER,当使用 PUMA 框架时,准确度在接近明文模型的同时,速度和通信效率都提高了 2 倍左右(并且注意 MPCFORMER 的准确度不及 PUMA)。PUMA 甚至可以在 5 分钟内完成对 LLaMA-7B 的评估,生成一个词。作者表示这是首次采用 MPC 评估如此大的语言模型。
- 开源的端到端框架。蚂蚁集团的这些研究者成功以 MPC 形式设计并实现了安全的 Embedding 和 LayerNorm 程序。得到的结果是:PUMA 的工作流程遵照明文 Transformer 模型,并未改变任何模型架构,能够轻松地加载和评估预训练的明文 Transformer 模型(比如从 Huggingface 下载的模型)。作者表示这是首个支持预训练 Transformer 模型的准确推理的开源 MPC 解决方案,同时还无需再训练等进一步修改。
PUMA 的安全设计
PUMA 概况
PUMA 的设计目标是让基于 Transformer 的模型能安全地执行计算。为了做到这一点,该系统定义了三个实体:模型所有者、客户端和计算方。模型所有者提供经过训练的 Transformer 模型,客户端负责向系统提供数据和收取推理结果,而计算方(即 P_0、P_1 和 P_2)执行安全计算协议。注意模型所有者和客户端也可以作为计算方,但为了说明方便,这里会将它们区分开。
在安全推理过程中需要保持一个关键的不变量:计算方开始时总是有客户端输入中三分之二的复制的机密份额以及模型的层权重中三分之二的权重,最终计算方也有这些层的输出中三分之二的复制的机密份额。由于这些份额不会向各方泄漏信息,这就能确保这些协议模块能以任意深度按顺序组合起来,从而为任意基于 Transformer 的模型提供安全计算。PUMA 关注的主要问题是降低各计算方之间的运行时间成本和通信成本,同时维持所需的安全级别。通过利用复制的机密份额和新提出的 3PC 协议,PUMA 能在三方设置下让基于 Transformer 的模型实现安全推理。
安全嵌入协议
当前的安全嵌入(secure embedding)流程需要客户端使用 token id 创建一个 one-hot 向量,这偏离了明文工作流程并会破坏 Transformer 结构。因此,该方法并不容易部署到真实的 Transformer 模型服务应用中。
为了解决这个问题,这里研究者提出了一种新的安全嵌入设计。令 token id ∈ [n] 且所有嵌入向量均表示为  ,则嵌入可以表示为
,则嵌入可以表示为 。由于 (id, E) 共享秘密,则新提出的安全嵌入协议的
。由于 (id, E) 共享秘密,则新提出的安全嵌入协议的 的工作方式如下:
的工作方式如下:
- 计算方在接受到来自客户端的 id 向量后,安全地计算 one-hot 向量
 。具体来说,
。具体来说, 其中 i ∈ [n].
其中 i ∈ [n]. - 各计算方可以通过
 计算嵌入向量,其中
计算嵌入向量,其中 不需要安全截断(secure truncation)。
不需要安全截断(secure truncation)。
如此一来,这里的 Π_Embed 就不需要显式地修改 Transformer 模型的工作流程。
安全 GeLU 协议
目前大多数方法都将 GeLU 函数看作是由更小的函数组成的,并会尝试优化其中每一部分,这就让它们错失了从整体上优化私密 GeLU 的机会。给定 GeLU 函数:
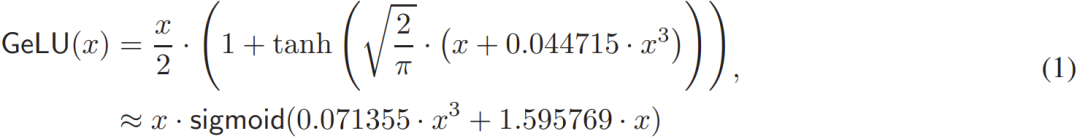
过去的一些方法关注的重心要么是 tanh 函数设计高效的协议,要么是将现有的求幂和倒数的 MPC 协议用于 Sigmoid。
但是,这些方法都没有用到这一事实:GeLU 函数两边基本都是线性的,即当 x<−4 时 GeLU (x) ≈ 0,当 x>3 时 GeLU (x) ≈ x。研究者提出在 GeLU 的 [−4,3] 的短区间内,低次多项式的分段近似是一种更高效且更容易实现的安全协议选择。具体来说,这个分段式低次多项式如下 (2) 式所示:

其中多项式 F_0 和 F_1 的计算是通过软件库 numpy.ployfit 实现,如 (3) 式所示。研究者发现,这种多项式拟合虽然简单,但表现却出人意料地好;实验结果的最大误差 < 0.01403,中值误差 < 4.41e−05,平均误差 < 0.00168。

从数学形式上讲,给定机密输入 ,新提出的安全 GeLU 协议
,新提出的安全 GeLU 协议 的构建方式见如下算法 1。
的构建方式见如下算法 1。

安全 Softmax 协议
在函数 中,关键的挑战是计算 Softmax 函数(其中 M 可被视为一个偏置矩阵)。为了数值稳定性,可以这样计算 Softmax:
中,关键的挑战是计算 Softmax 函数(其中 M 可被视为一个偏置矩阵)。为了数值稳定性,可以这样计算 Softmax:
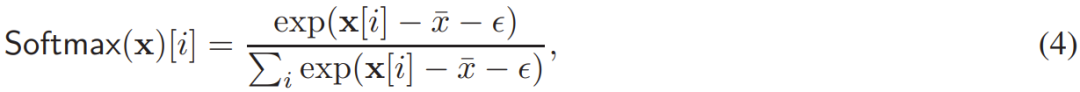
其中  是输入向量 x 的最大元素。对于普通的明文 softmax,ε = 0。对于二维矩阵,则是将 (4) 式用于其每个行向量。
是输入向量 x 的最大元素。对于普通的明文 softmax,ε = 0。对于二维矩阵,则是将 (4) 式用于其每个行向量。
算法 2 给出了新提出的安全协议 Π_Softmax 的详细数学描述,其中提出了两种优化方法:

- 第一种优化是将 (4) 式中的 ε 设置成一个非常小的正值,比如 ε=10^-6,这样一来 (4) 式中求幂运算的输入就都是负值。研究者利用了这些负操作数来提升速度。他们具体通过简单的裁剪使用泰勒级数来计算其中的幂。
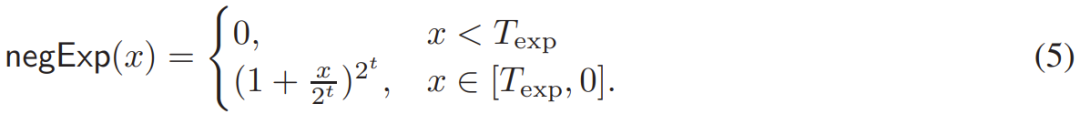
- 研究者提出的第二种优化是降低除法量,这最终能降低计算和通信成本。为此,对于大小为 n 的向量 x,研究者将 Div (x, Broadcast (y)) 运算替换成了 x・Broadcast (1/y),其中
 。这种替换可以有效地将 n 次除法约简至 1 次倒数运算和 n 次乘法运算。这种优化对于 Softmax 运算尤其有益。在定点值设置下,Softmax 运算中 1/y 依然足够大,难以维持足够的准确度。由此,这样的优化可以在保证准确度的同时显著降低计算和通信成本。
。这种替换可以有效地将 n 次除法约简至 1 次倒数运算和 n 次乘法运算。这种优化对于 Softmax 运算尤其有益。在定点值设置下,Softmax 运算中 1/y 依然足够大,难以维持足够的准确度。由此,这样的优化可以在保证准确度的同时显著降低计算和通信成本。
安全 LayerNorm 协议
回想一下,给定大小为 n 的向量 x, ,其中 (γ, β) 是已训练的参数,
,其中 (γ, β) 是已训练的参数, 且
且  。在 MPC 中,关键挑战是评估除以平方根公式
。在 MPC 中,关键挑战是评估除以平方根公式  。为了安全地评估这一公式,CrypTen 的做法是按这个顺序执行这个 MPC 协议:平方根、倒数和乘法。但蚂蚁集团的研究者观察到
。为了安全地评估这一公式,CrypTen 的做法是按这个顺序执行这个 MPC 协议:平方根、倒数和乘法。但蚂蚁集团的研究者观察到  。而在 MPC 方面,计算平方根倒数 σ^{-1/2} 的成本接近平方根运算的成本。此外,受前一小节中第二种优化的启发,他们还提出首先计算 σ^{-1/2},然后广播 Broadcast (σ^{-1/2}) 以支持快速和安全的 LayerNorm (x)。算法 3 给出了 Π_LayerNorm 协议的数学形式。
。而在 MPC 方面,计算平方根倒数 σ^{-1/2} 的成本接近平方根运算的成本。此外,受前一小节中第二种优化的启发,他们还提出首先计算 σ^{-1/2},然后广播 Broadcast (σ^{-1/2}) 以支持快速和安全的 LayerNorm (x)。算法 3 给出了 Π_LayerNorm 协议的数学形式。

实验评估

图 1:在 GLUE 和 Wikitext-103 V1 基准上的性能表现,模型方面,a 是 Bert-Base,b 是 Roberta-Base,c 是 Bert-Large,d 包括 GPT2-Base、GPT2-Medium、GPT2-Large。

表 1:对于一个长度为 128 的输入句,Bert-Base、Roberta-Base 和 Bert-Large 的成本。时间成本以秒计算,通信成本以 GB 计算。

表 2:GPT2-Base、GPT2-Medium 和 GPT2-Large 的成本。输入句的长度为 32,这些是生成 1 个 token 的成本。

表 3:对于 {2, 4, 8, 16} 句子的批次,Bert-Base 和 GPT2-Base 的成本。Bert-Base 和 GPT2-Base 的输入长度分别设定为 128 和 32,GPT2 的数据是生成 1 个 token 的成本。

表 4:不同输入长度(#Input)下 Bert-Base 和 GPT2-Base 的成本。Bert-Base 和 GPT2-Base 的输入长度分别设定为 {64, 128, 256, 512} 和 {16, 32, 64, 128}.GPT2 的数据是生成 1 个 token 的成本。

图 2:GPT2-Base 生成不同输出 token 的成本,输入长度为 32。a 是运行时间成本,b 是通信成本。

表 5:用 LLaMA-7B 执行安全推理的成本,#Input 表示输入句的长度,#Output 表示所生成的 token 的数量。
只需五分钟就能扩展用于 LLaMA-7B。研究者在 3 个阿里云 ecs.r7.32xlarge 服务器上使用 PUMA 评估了大型语言模型 LLaMA-7B,其中每个服务器都有 128 线程和 1 TB RAM,带宽为 20 GB,往返时间为 0.06 ms。如表 5 所示,只需合理的成本,PUMA 就能支持大型语言模型 LLaMA-7B 实现安全推理。举个例子,给定 8 个 token 构成的输入句,PUMA 可以在大约 346.126 秒内以 1.865 GB 的通信成本输出一个 token。研究者表示,这是首次使用 MPC 方案对 LLaMA-7B 实施评估。
PUMA虽然取得了一系列突破,但是它依然是一个学术成果,其推理耗时依然离落地存在一些距离。研究者相信未来与机器学习领域最新的量化技术、硬件领域量新的硬件加速技术相结合之后,真正保护隐私的大模型服务将离我们不再遥远。

















