一、导言
1、2022年末火出圈的OpenAI与AIGC
2022年是AI历史上具有里程碑意义的一年,AI发展为作家、画家、音乐家、导演等,特别是ChatGPT让AI彻底出圈,不断有非计算机专业的人谈论AI是否能够颠覆已有的模式。ChatGPT也成为继抖音以后,最快的月活过亿的产品。

2、回顾GAN以来的最重要AIGC的工作
先回顾一下过去十年来 AIGC 领域中比较重要的工作。2013年至2017年主要处于基础理论逐渐完善的阶段,在这个阶段VAE、GAN、Transformer等深度神经网络横空出世,处于基础组件逐渐诞生和完善的阶段;2018年至2021年,超大规模的模型逐渐流行,多模态逐渐融合,并且大语言模型的预训练的学习方式成为可能, Few Shot Learning和Incontext Learning等学习范式被提出;从2022年到现在处于第三个阶段,AIGC集中爆发,模型效果的真实性、计算效率全面提升。最近,微软发表文章说明大模型能力涌现,强人工智能已经开始出现。

二、商品文案生成
1、为什么需要AI生成产品文案
产品文案对于电商导购过程是非常重要的,因为很多购物者可能首先会被产品的标题所吸引,很多的售后问题可能源于产品的描述错误(产品与描述不符)。但是,编写产品的文案是一件令人头疼的事情,因为好的文案需要首先了解人群的画像,还需要很多SEO的技巧,想要持续产出高质量的文案需要投入大量的人力。
随着AI技术的发展,自动生成高质量的产品文案,不但可以满足客户的需求,还可以持续追踪热门事件,不断提升文案的质量和稳定性。
下图右侧是两个例子,一个是传统的服饰电商,另一个是酒旅行业。客户只需给出产品的特点,大语言模型技术直接生成相应的文案。

2、问题定义
那么该如何定义该问题?以民宿文案设计为例,在实际的应用中,原始数据可能是一些结构化或非结构化的数据,客户可能也不清楚产品的卖点是什么。如何做卖点提取,卖点提取以后如何生成标题。这些都需要其它技术介入。
由于今天分享的是AIGC的方向,所以主要聚焦于卖点已知的情况下,如何生成较好的文案。如客户只需要简单地输入房型、风格等特征的描述,模型就能够识别出其中比较重要的信息,并以比较好的文采对产品的标题或描述进行润色或生成。

3、阶段一:基于模板的技术方案
几年前,我们也尝试过使用基于模板的方式做类似的任务。做法是首先提取产品的知识,对知识进行结构化处理,形成知识图谱。在知识图谱的基础上,做核心卖点的选择、模板的选择和卖点的填充。这种做法主要基于模板实现,受限于模板数量和人为的总结,相对来说比较死板。

4、模板填充—>大规模语言模型
结合近期技术的进步,我们考虑结合纯粹的生成式语言模型的方案是否可行。特别是在ChatGPT出来之后, GPT系列的模型已经可以帮助人们实现一些评论、邮件的写作,因此考虑使用类似的生成模型完成上述的任务。在初步的实验后,取得的效果比基于模板的结果更好。在这之后,我们又进行算法上的迭代。在深入这部分内容前,我们先来回顾一下 GPT 系列模型的基本原理。

5、GPT原理解读1:语义模型的思想
在正式介绍具体的技术方案前,先介绍一下GPT的原理。GPT的核心思想比较简单,即人类的知识蕴含于人类的语言中,如果能完美地预测下一个词,那么模型也可以模拟人类的思维,也就具有了智能。假设当n=t时,可知,当n=t+1时,也可以预测。任何与语言相关的任务,可以抽象为这类生成任务,都可以用语言模型的方式求解。
但和数十年前的语言模型不同的是,现在的语言模型通过大规模Transformer的深度神经网络进行建模。好处是:
- 可以更准确地建模下一个词的概率;
- 可以进行高效的模型训练和推理;
- 可以解决基于长距离的语义依赖。

6、GPT原理解读2:模型的演进过程
由OpenAI的技术迭代过程可以发现,不仅模型的规模越来越大,数据的规模也在增加。在大规模语料数据、大规模模型的基础上,模型的能力也越来越强,发展到GPT-4不仅可以处理文本语言,也可以处理多模态的数据。由于 GPT-4从公开的资料中能获取的信息非常有限,这里仅列举一下 GPT-3.5 之前OpenAI推出的模型相关参数(GPT-3.5是OpenAI推出的一列模型,ChatGPT 又称 GPT-3.5-Turbo,但不在此表中)。

7、GPT原理解读3:ChatGPT & RLHF
去年年末,OpenAI又提出了ChatGPT(GPT-3.5-Turbo)及人工强化学习反馈的技术,对整个社会造成了巨大的影响。通过该技术,实现AI对齐人类偏好的能力。ChatGPT之前的模型已经具备了很好的文本生成的能力,但是生成的文本和人类的偏好没有对齐,ChatGPT主要针对人类的偏好进行对齐。
这个训练过程主要分为三个阶段:
- SFT阶段: 使用人工续写数据对text-davinci-003模型进行有监督微调;
- RM阶段: 人工标注排序数据,使用pairwaise ranking 模型训练奖励模型;
- RLHF阶段:使用强化学习PPO微调大语言模型。
需要说明的是,斯坦福大学在羊驼的基础上,使用Self-Instruct技术进行训练,并没有使用RLHF的训练方式,取得的效果也不错。

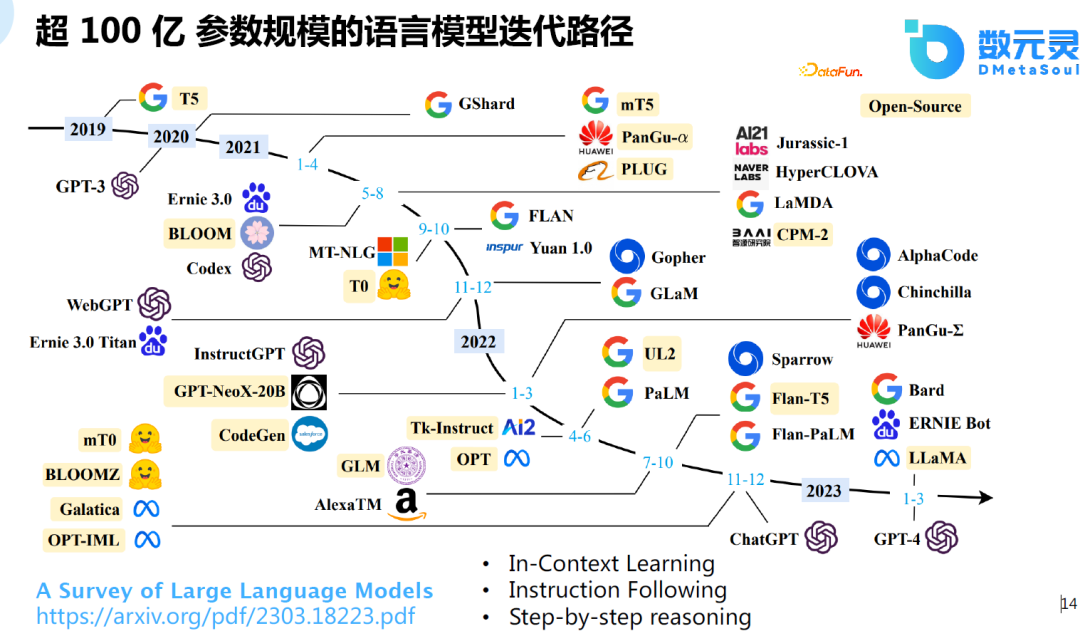
8、超100亿参数规模的语言模型迭代路径
近期的一篇综述文章,调研了超100亿参数规模的语言模型迭代路径。为什么是100亿?模型在100亿参数时会出现涌现的能力,而这在以前的小模型中是不存在的。实验发现,模型在60-70亿参数量时,模型的能力会显著提升,这也是ChatGPT或类似模型有如此强大的功能的基础。
这里主要包含了以下几个方面,首先是In-Context learning,即上下文学习,是OpenAI提出的一种模式,不需要梯度更新,只需给出一些例子,模型能够知道该例子的含义,对于新的任务,模型能够给出不错的预测结果。第二是Instruction Following,模型能够听懂指令,例如,给出指令:帮我写代码,模型能够给出较好的response。最后就是Step-by-step reasoning,之前的语言模型在解数学题时表现不好,谷歌提出了train of source的工作,使模型可以一步步地学习,在常识推理、逻辑推理及数学题中表现较好,这也是大模型在100亿参数量的基础上可能会涌现出来的能力。
9、阶段二:基于语言模型的技术方案
由于算力的限制,我们首先在GPT2的基础上进行微调,发现效果比基于模板的结果更好。但在其中也发现了一些问题,生成的信息虽然多样、丰富,但只能产生较高频的内容,对于低频的内容效果较差。因为对于民宿来说,这是一个非标品,如果所有的文案都讲述相同的内容,并不能有效地吸引客户。因此,在这基础上,希望模型能够对齐人类的偏好。因此,在GPT2的基础上,做了第二阶段的优化,将其应用于生成任务。

10、阶段三:基于语言模型的改进方案
受限于当时的解决方案及算力的影响,效果不太理想。因此,参考了ChatGPT的训练方式,采用三阶段进行训练。首先,收集质量较好的数据,对模型进行微调。其次,使用模型生成数据样本,并对这些数据进行排序。最后,利用排序完的数据对模型进行第二次的微调。在训练两轮后,发现模型收敛的效果还比较好。

11、Case分析
以下是一些结果的Case分析,对比于GPT2的微调模型来说,改进后的方案能够识别特色卖点,并且在排序上能够更加突出这种卖点。这相当于模型对齐了人类的评估标准。

12、商品文案生成总结
我们的方法首先是基于GPT2的模型进行微调,模型规模较小。其次,我们的任务更加简单,只限于文案的生成。在第一阶段,ChatGPT采用人工标注的方式,我们的方案选用的是精选数据集,因为我们的场景,可以更高效的获取监督数据,因此该阶段无需人工标注。在第二阶段,也基于pair-wise损失训练了ranking的模型。在第三阶段,基于大规模的数据标签进行两轮微调。

三、商品图像生成
1、为什么需要AI生成产品图片
在电商领域,图片是非常重要的,但是实际的拍摄过程是非常复杂的,成本也比较高,但产品的迭代时间却比较短,对图片有大量的优化的需求。基于AI,以相对简单的文本约束的方式,生成产品图片,特别是对于服饰产业,可以大量缩短图片生成的时间,降低原流程的时间、成本。因此,我们在这个方向上进行探索。

2、Text2Image里程碑
首先介绍部分关于文本生成图像的一些具有里程碑意义的工作。2021年,DALL-E 1的出现具有划时代的意义,使得从文到图的生成模型具有商业落地的潜力。之后,不断有人在这一领域进行研究,包括DALL-E 2,不但实现了效果的提升,还降低了参数量。Stable Diffusion的出现也是石破天惊的一项工作,不但生成的效果好,而且可以在消费级的显卡上工作,降低了AIGC的门槛。最近非常火爆的LoRA技术,不但可以在消费级的显卡上使用,还可以对模型进行微调,更加降低了参与的门槛,促使大量的人和资本涌入这一领域。

3、技术的快速演进:如何画好一个人像?
这里以人像等自动生成为例,我们可以看到:从21年的VQGAN-CLIP到Stable Diffusion的快速演进,技术正在快速进步。而近期的ControlNet可以根据人的姿势或线光图直接生成结果,这更是具备了商业落地的可能性。

4、Stable Diffusion原理解读1:扩散模型
Stable Diffusion的思路比较简单,相当于使用U-Net预测噪音,即不断在原图的基础上增加噪声,将带噪音的数据作为输入,使用U-Net预测原始图像及加噪声的过程。通过这种模式,使通过噪音生成图像称为可能。

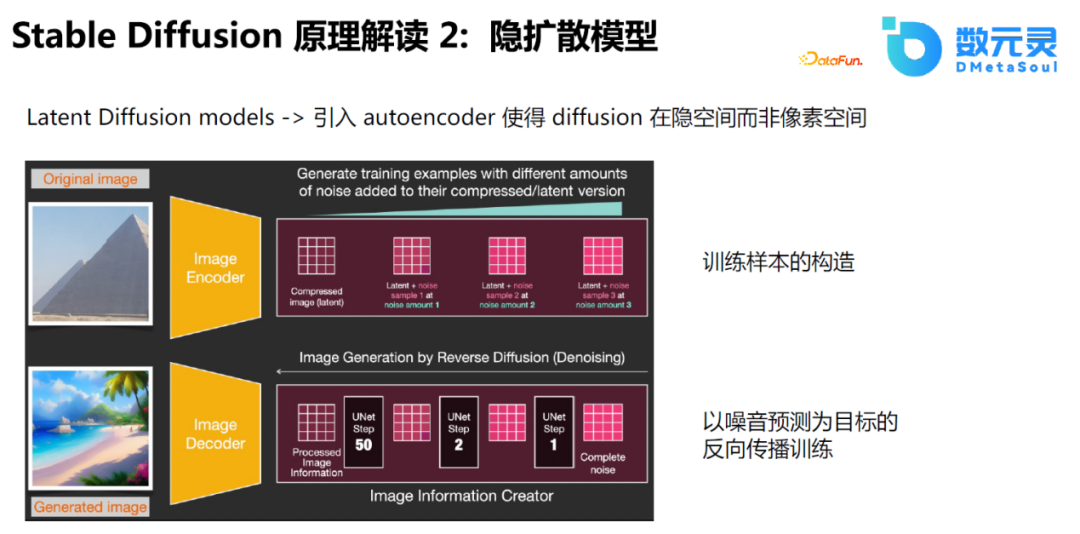
5、Stable Diffusion原理解读2:隐扩散模型
在Stable Diffusion的基础上,还提出使用隐向量的训练方式。原先的Diffusion加噪音的过程作用于图片,即中间过程和原始过程接近。而隐扩散模型使用Auto Encoder将中间过程映射到隐空间中,这有利于将中间过程进行降维计算,在高维空间进行解码,这也是它能够支持大分辨率图像,降低显存计算资源的主要原因。
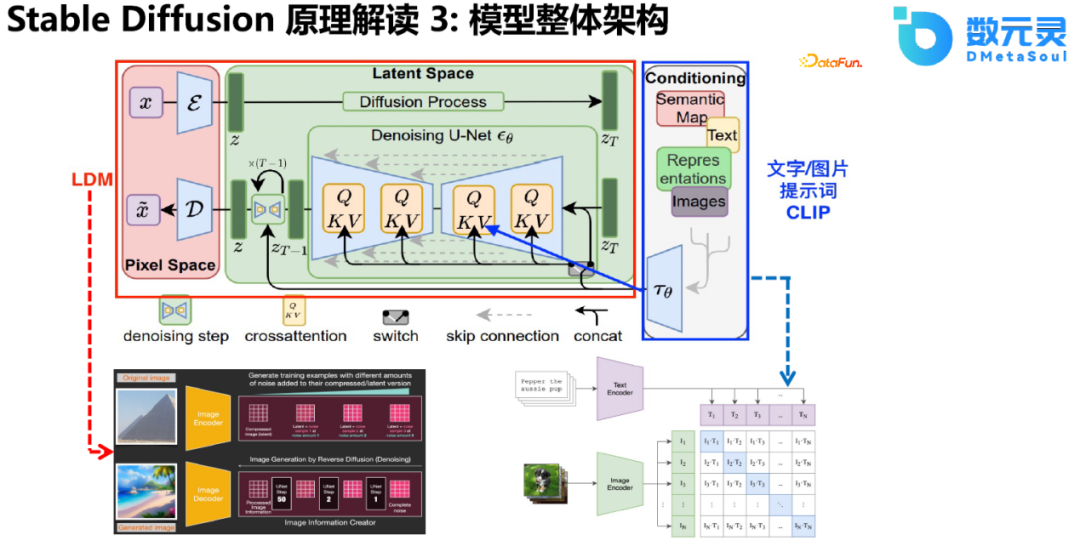
6、Stable Diffusion原理解读3:模型整体结构
对于文字部分的编码,Stable Diffusion引入了CLIP,并通过cross attention的方式融入模型中。使用CLIP对Prompt进行编码,通过U-Net、cross attention作为控制条件引导图像的生成过程。总的来说,Stable Diffusion通过构建LDM,解决了直接在高维空间进行计算带来的资源消耗和精度控制的限制,并且取得了非常好的效果。最关键的是,整个结构可以在消费级的显卡上进行使用,极大地促进了AIGC行业的发展。
7、Stable Diffusion的后续迭代技术
在Stable Diffusion之后,最近也有许多相关工作的迭代,包括Textual Inversion、DreamBooth、ControlNet和LoRA,这些模型使得生成的图像更加逼真,并且用户可以提供更多的控制条件,微调训练的速度更快,微调的参数量更少,需要的显存更少。

8、AI Writer图片生成展示
我们在这方面的工作主要集中在电商的图片生成,如提供一些商品的买点关键词,然后由模型自动生成相应的图片。

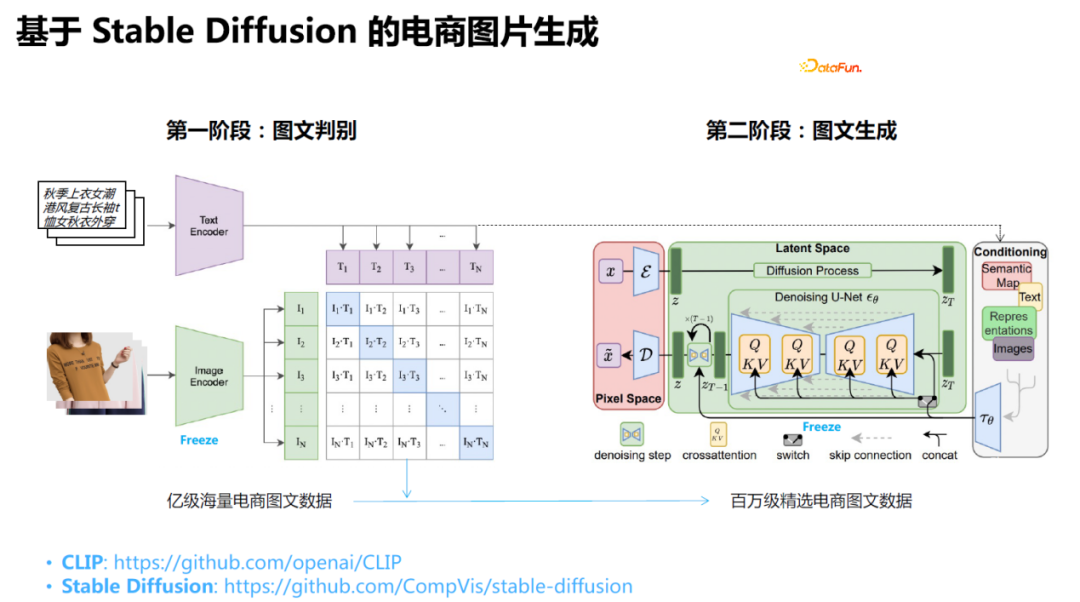
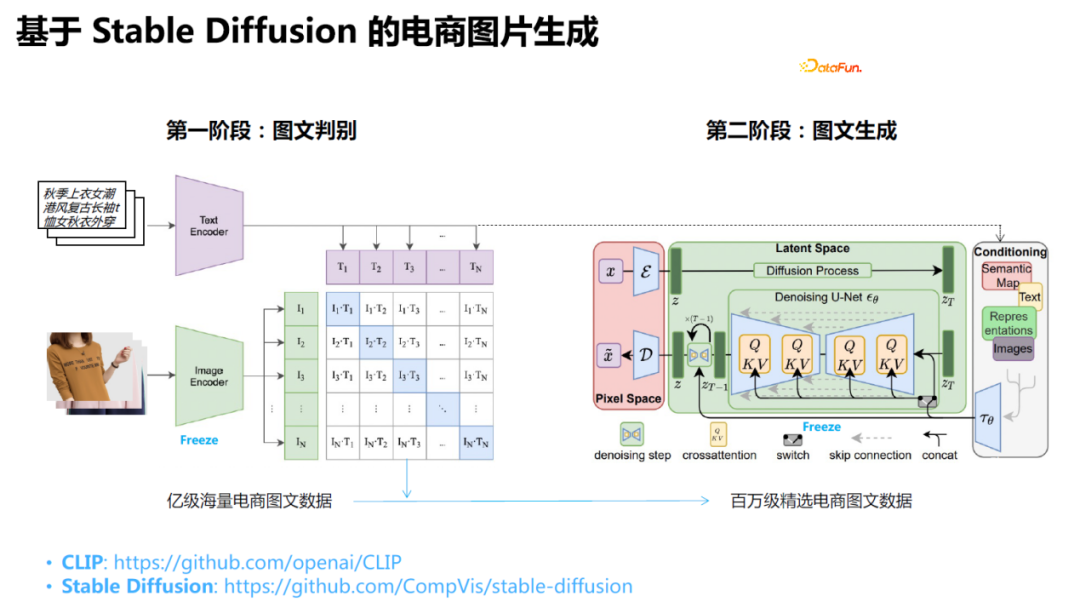
9、基于Stable Diffusion的电商图片生成
具体做法是:采样Stable Diffusion模型进行微调,主要微调CLIP部分。首先爬取电商数据,在此基础上,通过用户的评论数量、收藏数量、成交等信息进行筛选,然后,使用CLIP对这些内容进行打分,保留标题和图片相关度较高的数据作为训练集进行训练。
 10、电商服饰产品图片制作流程
10、电商服饰产品图片制作流程
原始的电商服饰产品图片制作流程包括:摄影师拍照,模特摆拍,美工后期处理、交付等,使用模型进行图片生成,可以免去模特、摄影师成本,可以根据运营需求及时调整。
经过我们对市场的调研,发现电商行业内对图片素材的自动生成需求很大。但从技术上来说,目前整个图片生成的工作还处于探索阶段,虽然流程已经打通,但是对质量要求较高的图片的生成还有一定的局限性。这个领域的进展非常快,我们也在不断的吸取经验,不断迭代优化,就目前而言,小图、概念图、缩略图的生成结果较好,高清大图还很难一次成片。

四、结语
文章开头回顾了近期文本、图像等相关领域的重要工作,讨论了大模型在电商领域带来新的机遇与挑战;随后,我们介绍了数元灵在电商文案生成基于GPT 模型的实践,对比不同版本的模型的迭代效果并进行了分析;最后,介绍了数元灵在电商图像生成基于Stable Diffusion 的实践。
AIGC目前的发展速度很快,未来我们也可能基于最新的技术进展进一步迭代模型。新技术得出现,让以前可能需要非常大计算资源才能做的产品,现在可能不需要那么多资源也能启动。

下面谈一下针对电商领域,AIGC可能会带来以下变革:
- 导购链路:比如和OpenAI合作的Shop,以对话的形式进行交互,客户提出想法、需求,模型推荐不同的产品,新的技术出现让这种产品交互模式成为可能。
- 制造和供应链:虽然对于质量较高的图片生成,目前的技术还不能实现。但对于制造方向,如CALA可以生成设计图,这能够降低服装设计的门槛,降低设计的成本。
- 运营效率:如AI Writer可以自动生成多条运营文案,运营同学可以调整生成的因子,挑选合适的文案。这种方式能够降低运营成本,提高运营效率。毕竟选择题要比主观题做起来容易得多。

下图中的网站给出了许多的大模型应用场景,不仅仅局限于ChatGPT,还有Bard等。

目前,在国内做通用大模型或国产的ChatGPT可能并不是一个最优的选择,因为这需要大量的积累,对于我们普通创业者和开发工程来说,可能会有以下机会:
- 解决大模型并不擅长的事情,如处理长文本,更及时地知识的更新等;
- 基于大模型改造既有业务,包括电商行业或其他行业,可能每个行业在这个时代都会重新做一遍;
- 大模型时代的Linux社区,目前开源社区已经是遍地开花的状态,大语言模型的iPhone时刻已过,相信Android时刻未远也!


五、Q&A
Q1:有没有可能做小型的通用模型,如果可以,有什么技术方案?
A: 这需要根据模型的大小来确定,就目前来看,如果模型的参数小于100亿,不太可能出现通用的能力,对于世界知识或指令的理解、推理能力比较差,至少可能需要60-70亿参数的模型才会逐渐出现这种通用的能力。
Q2:商品文案生成时,有什么方法能够加入风格化的元素,比如说抖音、小红书等描述风格?
A:这也是我们正在做的事情,目前是通过Prompt引导模型生成不同风格的文案。另外,可能需要一些抖音、小红书风格的标注数据,再生成时通过Prompt引导模型。
Q3:有没有可能出现幻觉问题,如果产生错误的信息应该如何控制?
A:文案中出现幻觉或虚假信息都是可能的。目前的解决方案是生成多个候选,然后进行后处理。
Q4:文案生成有哪些需要特别注意的点?
A:最重要的应该是收集高质量的数据。其次可能是如何对模型进行微调。
Q5:在一个细分领域可以做AIGC吗?
A:这是可以的,也是我们目前正在做的事情,而且参数的规模可能不需要那么大。
Q6:ChatGPT和Internet结合是不是可以解决数据延迟的问题?
A:这是可以的。
Q7:100亿及以上的模型需要多大的算力?
A:如果是微调模型,8块A100肯定是可以的。如果没有A100,V100也是可以的。具体的设备要求和模型参数量、数据量、训练时长都有关系,需要具体情况具体分析。
Q8:有没有比较好的支持中文的预训练大模型?
A:hugging face上应该有很多中文的大模型可以使用。
Q9:生成结果如果存在许多不合常识、不合逻辑的问题该如何解决?
A:这也是我们开始尝试时遇到的问题。在根据商品属性生成图片时,效果不理想。我们的解决方案是首先将商品数据进行归一化处理,其次,将比较稀疏的属性过滤,如使用TF-IDF挑选出重要的属性等。这个问题主要来源于数据质量。
Q10:在AI创作领域,AIGC不能解决的问题和局限性有哪些?
A:目前比较难的应该是视频生成的领域。Meta提出的Make-A-Video也只能生成一些短视频,而且质量也不理想。高分辨图片中细节的部位生成的效果也是一个难题。
Q11:在电商领域,还有哪些痛点可以通过AIGC解决?
A:理论上说,会话的模式可以解决所有和商家、客户沟通的事情,这都是ChatGPT能够解决的事情。比如,目前大多数的客服机器人都是通过规则来实现的,在ChatGPT后可以通过ChatGPT和知识相结合的方式来完善。
Q12:BERT可以做哪些任务?
A:BERT通常用于分类、实体识别等识别类任务。GPT可能更擅长生成类的任务。可以在BERT最后一层接上不同的任务层,做识别类的任务,如亮点识别等。
Q13:AIGC在自动化运营层面有什么可以结合的思路?
A:这需要根据需求来确定。如海外电商通常使用邮件进行交流,这也是一个行业痛点。产品设计图、概念图的生成也是比较好的方向。
Q14:有没有可以展示的案例?
A:有的,链接:http://nlg-demo.dmetasoul.com/ecommerce。但是因为算力的限制,部署用的模型只是一个小模型。