近期,指令微调(IFT)已经被作为预训练大语言模型(LLMs)获得指令遵循能力的关键训练阶段。
然而,广泛使用的IFT数据集(例如,Alpaca的52k数据)却包含许多质量低下的实例,这些实例带有错误或无关的回应,对IFT产生了误导和不利影响。
先前的处理方法主要依靠人工筛选这些低质量数据,但这既费时费力,又难以扩展。
因此,如何以高效、自动化的方式过滤出这些低质量数据,成为提升LLM微调效果的关键所在。
现在,来自马里兰大学,三星和南加大的研究人员提出了一种有效的数据过滤策略,使用强大的LLM(例如,ChatGPT)自动识别和移除低质量数据,以改善指令微调(IFT)的效果。
 图片
图片
论文地址:https://arxiv.org/abs/2307.08701
项目地址:https://lichang-chen.github.io/AlpaGasus/
在这项工作中,研究者提出的模型AlpaGasus,使用从52k Alpaca数据中过滤出来的9k高质量数据进行微调。
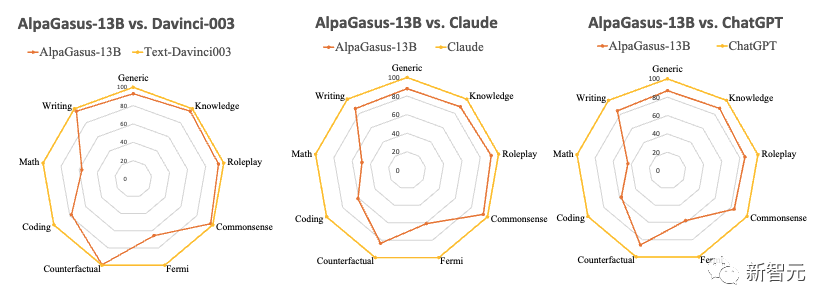
AlpaGasus在多个测试集上显著优于原始的Alpaca,其13B版本甚至在测试任务上的表现超过了90%的教师模型(即,Text-Davinci-003)。
并且,AlpaGasus在训练时间上也实现了5.7倍的提升,将7B版本的训练时间从80分钟缩短到了14分钟。
更少数据,训练更强「羊驼」
具体来说,研究者利用强大的LLM(如ChatGPT)自动评估每个(指令,输入,回应)元组的质量,对输入的各个维度如Accurac、Helpfulness进行打分,并过滤掉分数低于阈值的数据。
打分的prompt如下:
 图片
图片
方法的pipeline如下:

实验部分
在实验部分,作者使用了一组全面且多样化的测试集对他们提出的语言模型AlpaGasus进行了评估。
这个全面的评估集包含了来自Self-instruct、Vicuna、WizardLM和Koala的测试集。每一个测试集都提供了不同的指令,减少了评估偏差,提供了对AlpaGasus性能的全面概述。
作者们将AlpaGasus与四种最近的LLMs进行了比较:Alpaca、Text-Davinci-003、ChatGPT和Claude。
性能评估
对于性能的评估,作者们采用了GPT-4作为裁判来评估和比较不同模型对一组指令的回复。
为了解决GPT-4裁判的位置偏差,作者们对两种顺序(即,将AlpaGasus的回复置于基线模型的回复之前/之后)都进行了尝试,最终得分基于两次得分的「胜-平-负」准则。
结果分析
在结果部分,作者强调——数据的质量比数量更重要。
这一点通过AlpaGasus-9k与AlpaGasus-52k在所有测试集上的优异表现得到了证明,尽管前者使用的训练数据明显少于后者。

作者还将AlpaGasus-9k和使用从Alpaca数据集中随机挑选出9k数据训练的模型进行了对比。
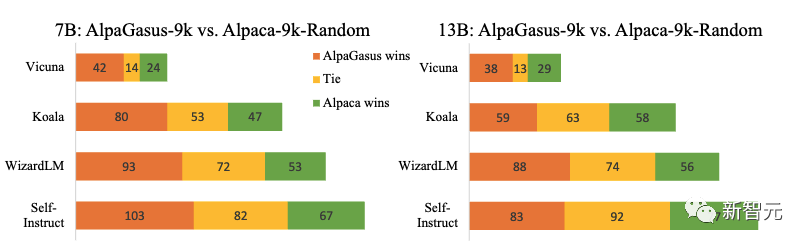
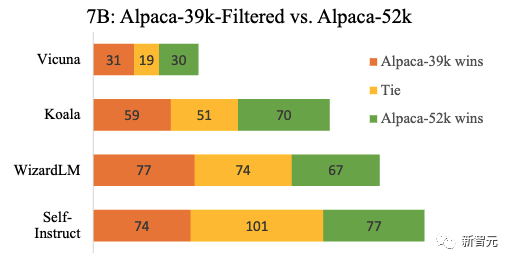
为了研究阈值对IFT的影响,作者比较了AlpaGasus和在应用较低阈值(4.0)选出的39k数据上微调的LLaMA。
结果显示,只用9k高质量数据训练的模型会显著好于用39k质量一般数据训练的模型。
消融实验部分,作者从选出训练AlpaGasus的9k数据中随机抽取3k和6k数据,并使用相同的训练脚本从LLaMA微调两个AlpaGasus的变体。
在所有四个测试集上,AlpaGasus在9k数据上的训练表现最好,这表明更多的高质量数据会导致更好的IFT模型。

细节评估
此外,作者还对AlpaGasus模型在WizardLM和Vicuna测试集的各项技能/类别进行了细致的评估。
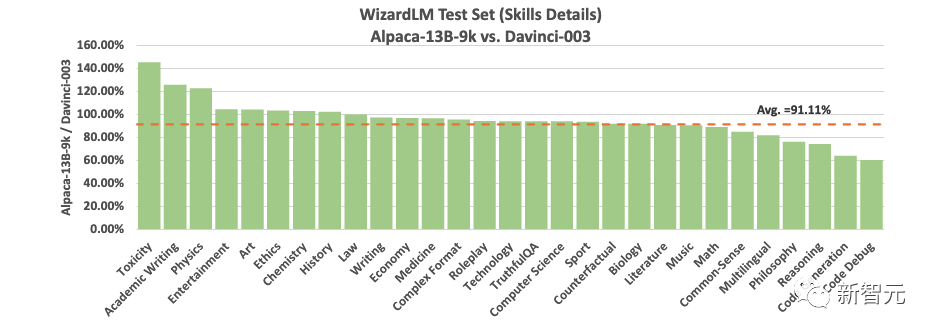
首先,作者比较了AlpaGasus-7B(9k)和Alpaca-7B(52k)在WizardLM测试集上的表现。
结果显示,AlpaGasus在29项技能中的22项上表现得比Alpaca好或相同,但在剩余的7项技能,例如编程(如代码生成)方面,AlpaGasus并未表现出优势。
作者发现,这可能是由于在数据选择和过滤过程中,没有指定技能类别的比例,导致与编程相关的数据被过滤的比例(88.16%)比平均过滤比例(82.25%)高很多。因此,这导致编程技能比其他技能弱。
也就是说,在IFT中,保持训练数据在不同类别之间的多样性和平衡性非常重要。
接下来,作者进一步比较了AlpaGasus-13B(9k)和Alpaga-13B(52k)在WizardLM测试集上的表现。
其中,结果与7B模型的观察结果一致,AlpaGasus在大多数技能上仍然优于Alpaca。
这表明,即使模型大小增加,数据质量仍然优于数据量。
在对Vicuna测试集的分析中,AlpaGasus-7B在大多数类别上,包括反事实、角色扮演、知识和通用等方面,都优于Alpaca-7B。而且,当基模型规模扩大时,这一结论仍然成立。
然后,作者比较了AlpaGasus、text-Davinci-003、ChatGPT和Claude。结果显示,AlpaGasus-13B可以达到其教师模型text-Davinci-003 (text-Davinci-003被用来生成Alpaca-52k指令数据) 的90%的能力.
成本节约
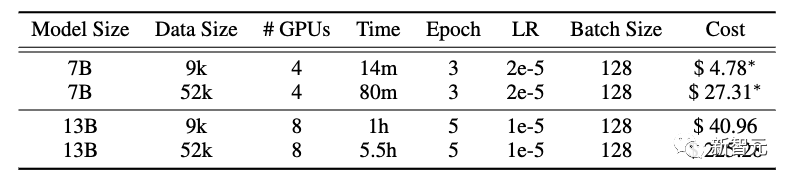
在成本节约部分,作者比较了AlpaGasus和Alpaca的训练成本,考虑到在AWS上所需的计算费用。
对于7B模型,使用9k数据的AlpaGasus的训练成本为4.78美元,使用52k数据的Alpaca的训练成本为27.31美元。
对于13B模型,使用9k数据的AlpaGasus的训练成本为40.96美元,而使用52k数据的Alpaca的训练成本为225.28美元。
这显示出,作者的数据选择策略在模型规模扩大时,可以带来更显著的训练成本节约。
总结
本文提出的数据过滤方法在可扩展性和自动化方面表现出显著的优势,证明了精心管理训练数据质量可以带来IFT性能的显著提升以及计算成本的大幅节省。
数据选择和评估策略也可以广泛应用于其他的指令微调数据集和LLMs,为大语言模型的实际部署开辟了新的研究方向。