当我们提到对话机器人,你是否也会像我一样立刻想起与Siri或者Alexa的一次次对话,虽然它们有时候可能会让你啼笑皆非,但也无可否认它们确实为我们的生活带来了很大便利。然而,训练这样的对话AI,其难点在于如何获取高质量的对话数据。过去我们通常需要收集大量的人类对话作为训练数据,这既费时又费力。那么,有没有更好的方法呢?
偶然想起去年阅读的一篇论文,介绍了一种对话补全的方案,非常有趣。今天就向大家介绍一种全新的方法——对话补全,它能帮我们把普通的文档转变成聊天记录。让我们一起探索这个颠覆传统的技术,看看它如何打破界限,让任何一篇文档都能“说话”。
首先,让我们看一下“对话补全”(inpainting)这个词。它其实是从图像处理那块借用过来的,原意是指用周围的像素信息来补全图片中缺失或者损坏的部分。而在这篇论文里,我们可以理解为用已有的对话内容来推测和补全对话中缺失的部分。就好像我们在看一幅画时,如果画中有一部分缺失,我们就会想象这部分应该是什么样的,以使画看上去更完整。在对话补全中,我们也是这样,利用已有的对话内容来猜测缺失的部分,让整个对话听起来更流畅、更完整。
下面我们来看看这个论文是怎么讲的。
简介
对话机器人需要大量的优质对话来进行训练,但这种数据往往不太好找。因此,论文作者想出了一种新的方法,叫做"对话补全",就是把普通的文章改编成像我们日常聊天一样的对话。这样一来,我们就能从各种各样的文章中获取大量的对话内容了。具体来说,就是把文章的每一句话看作一个人的发言,然后机器人就要猜测另一个人可能的回答或者提问。
训练的部分
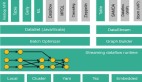
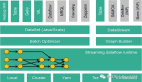
对话补全器(inpainting)使用的是一种叫做T5的生成模型,这是一种编码器-解码器的模型。这个模型的训练方法跟我们之前见过的BERT模型有点类似,只不过有一个关键的不同:BERT是在句子中遮蔽单个的词语来训练模型,而在这里,我们是遮蔽掉整个发言来训练模型。
举个例子,考虑以下对话:
讲话者1:“你好,你怎么样?”
讲话者2:“我很好,谢谢你。你呢?”
讲话者1:“我也很好,谢谢你的关心。”在对话补全任务中,可能会遮蔽一个完整的发言,像这样:
讲话者1:“你好,你怎么样?”
讲话者2:?
讲话者1:“我也很好,谢谢你的关心。”模型的任务就是预测缺失的发言(在这个例子中,“我很好,谢谢你。你呢?”)。用于训练的损失函数是标准的交叉熵损失,它的目标是最小化原始发言在部分对话给出的情况下的负对数概率。
推理阶段
在推理阶段,训练好的补全模型被用来将一篇文章转化为对话。假设我们有一篇这样的文章:
“猫是小型的食肉哺乳动物。”
“它们经常被当作宠物。”
“猫有强壮的柔韧体骼,反应快,爪子锐利且可以伸缩。”这篇文章被视作在一个假设的对话中,作者的一系列发言。这个对话最初看起来像这样:
作者:“猫是小型的食肉哺乳动物。”
读者:?
作者:“它们经常被当作宠物。”
读者:?
作者:“猫有强壮的柔韧体骼,反应快,爪子锐利且可以伸缩。”
读者:?问号代表对话中缺失的部分,这就是对话补全模型设计的目的,去填补这些缺失的部分。用了对话补全模型后,对话可能会变成这样:
作者:“猫是小型的食肉哺乳动物。”
读者:“猫一般常在哪些地方出没呢?”
作者:“它们经常被当作宠物。”
读者:“猫有哪些特殊的身体特征呢?”
作者:“猫有强壮的柔韧体骼,反应快,爪子锐利且可以伸缩。”
读者:“真有意思,你能再多介绍一些关于猫的行为习性吗?”文章和对话的例子
再让我们看另一篇文章:
“大象是大型哺乳动物。”
“它们有长长的鼻子。”
“大象是食草动物。”用了对话补全模型后,对话可能会变成这样:
作者:“大象是大型哺乳动物。”
读者:“大象有哪些独特的特征呢?”
作者:“它们有长长的鼻子。”
读者:“大象平时都吃些什么?”
作者:“大象是食草动物。”
读者:“真有趣,你能告诉我更多关于大象的栖息地信息吗?”总结
"对话补全"就像是给聊天记录中的空白部分填充内容。它可以帮我们把普通的文章变成像人们日常对话一样的聊天记录。这对于训练聊天机器人来说是个好方法,因为它能提供大量丰富、真实的对话内容。所以,这个技术可能会给聊天机器人的发展带来很大的帮助。