














概述
由MySQL5.0 版本开始支持存储过程。
如果在实现用户的某些需求时,需要编写一组复杂的SQL语句才能实现的时候,那么我们就可以将这组复杂的SQL语句集提前编写在数据库中,由JDBC调用来执行这组SQL语句。把编写在数据库中的SQL语句集称为存储过程。
存储过程:(PROCEDURE)是事先经过编译并存储在数据库中的一段SQL语句的集合。调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是很有好处的。
就是数据库 SQL 语言层面的代码封装与重用。
存储过程就类似于Java中的方法,需要先定义,使用时需要调用。存储过程可以定义参数,参数分为IN、OUT、INOUT类型三种类型。
- IN类型的参数表示接受调用者传入的数据;
- OUT类型的参数表示向调用者返回数据;
- INOUT类型的参数即可以接受调用者传入的参数,也可以向调用者返回数据。
优点
- 存储过程是通过处理封装在容易使用的单元中,简化了复杂的操作。
- 简化对变动的管理。如果表名、列名、或业务逻辑有了变化。只需要更改存储过程的代码。使用它的人不用更改自己的代码。
- 通常存储过程都是有助于提高应用程序的性能。当创建的存储过程被编译之后,就存储在数据库中。
- 但是,MySQL实现的存储过程略有所不同。
- MySQL存储过程是按需编译。在编译存储过程之后,MySQL将其放入缓存中。
- MySQL为每个连接维护自己的存储过程高速缓存。如果应用程序在单个连接中多次使用存储过程,则使用编译版本,否则存储过程的工作方式类似于查询。
- 存储过程有助于减少应用程序和数据库服务器之间的流量。
- 因为
- 应运
- 程序不必发送多个冗长的SQL语句,只用发送存储过程中的名称和参数即可。
- 存储过程度任何应用程序都是可重用的和透明的。存储过程将数据库接口暴露给所有的应用程序,以方便开发人员不必开发存储过程中已支持的功能。
- 存储的程序是安全的。数据库管理员是可以向访问数据库中存储过程的应用程序授予适当的权限,而不是向基础数据库表提供任何权限。
缺点
- 如果使用大量的存储过程,那么使用这些存储过程的每个连接的内存使用量将大大增加。
- 此外,如果在存储过程中过度使用大量的逻辑操作,那么CPU的使用率也在增加,因为MySQL数据库最初的设计就侧重于高效的查询,而不是逻辑运算。
- 存储过程的构造使得开发具有了复杂的业务逻辑的存储过程变得困难。
- 很难调试存储过程。只有少数数据库管理系统允许调试存储过程。不幸的是,MySQL不提供调试存储过程的功能。
- 开发和维护存储过程都不容易。
- 开发和维护存储过程通常需要一个不是所有应用程序开发人员拥有的专业技能。这可能导致应用程序开发和维护阶段的问题。
- 对数据库依赖程度较高,移值性差。
MySQL存储过程的定义
存储过程的基本语句格式
存储过程中的参数分别是 in,out,inout三种类型;
- in代表输入参数(默认情况下为in参数),表示该参数的值必须由调用程序指定。
- ou代表输出参数,表示该参数的值经存储过程计算后,将out参数的计算结果返回给调用程序。
- inout代表即时输入参数,又是输出参数,表示该参数的值即可有调用程序制定,又可以将inout参数的计算结果返回给调用程序
存储过程中的语句必须包含在BEGIN和END之间。
DECLARE中用来声明变量,变量默认赋值使用的DEFAULT,语句块中改变变量值,使用SET 变量=值;
存储过程的使用
定义一个存储过程

调用存储过程
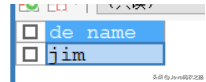
定义一个有参数的存储过程
先定义一个student数据库表:
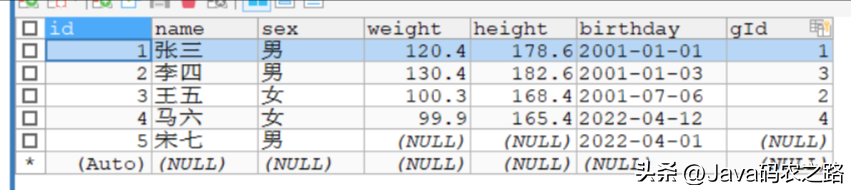
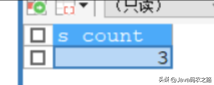
现在要查询这个student表中的sex为男的有多少个人。
调用这个存储过程
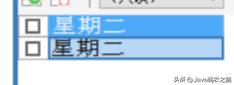
定义一个流程控制语句 IF ELSE
IF 语句包含多个条件判断,根据结果为 TRUE、FALSE执行语句,与编程语言中的 if、else if、else 语法类似。
调用这个存储过程
定义一个条件控制语句 CASE
case是另一个条件判断的语句,类似于编程语言中的 choose、when语法。MySQL 中的 case语句有两种语法格式。
- 第一种
调用这个存储过程
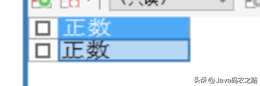
2.第二种
调用此函数
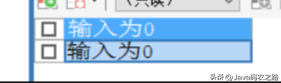
定义一个循环语句 WHILE
调用此函数
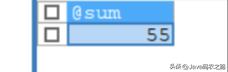
定义一个循环语句 REPEAT UNTLL
REPEATE…UNTLL 语句的用法和 Java中的 do…while 语句类似,都是先执行循环操作,再判断条件,区别是REPEATE 表达式值为 false时才执行循环操作,直到表达式值为 true停止。
调用此函数
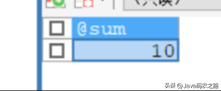
定义一个循环语句 LOOP
循环语句,用来重复执行某些语句。
执行过程中可使用 LEAVE语句或者ITEREATE来跳出循环,也可以嵌套IF等判断语句。
- LEAVE 语句效果对于Java中的break,用来终止循环;
- ITERATE语句效果相当于Java中的continue,用来跳过此次循环。进入下一次循环。且ITERATE之下的语句将不在进行。
调用此函数
使用存储过程插入信息
调用此函数
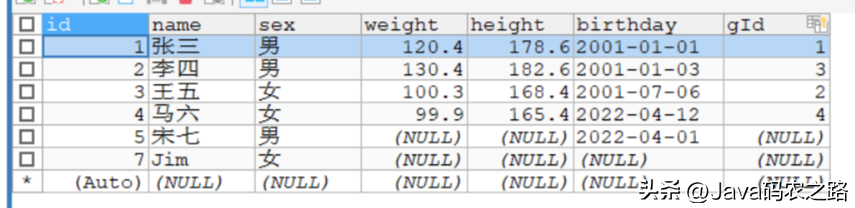
再次调用次函数

存储过程的管理
显示存储过程

显示特定数据库的存储过程
显示特定模式的存储过程

显示存储过程的源码

删除存储过程
后端调用存储过程的实现
在mybatis当中,调用存储过程
调用数据库管理
通过这样就可以调用数据库中的存储过程的结果。












