所谓系统设计,就是给一个场景,让你给出对应的架构设计,需要考虑哪些问题,采用什么方案解决。很多面试官喜欢出这么一道题来考验你的知识广度和逻辑思考能力。
虽然各个系统千差万别,但是设计思想基本一致,学会一些经典的架构设计,掌握基本的设计方法和常见需要考虑的问题,用这一套方法论去应对面试,应该就没啥问题了。
目前专栏已经包含以下几个经典系统设计题:
- 高性能短链系统
- 高性能计数器
- 高性能未读数计数器
- 高性能 Feed 流
- 高性能限流器
- ...... 后续会不断增加
今天来分享下如何设计一个高性能的短链系统,字节三面的真实面试题。
什么是短链?为什么要用短链?
比如将 https://flowus.cn/veal/share/3306b991-e1e3-4c92-9105-95abf086ae4e 缩短为 https://sourl.cn/aY95qu,点击后面的短链接将会重定向到前面的长链接。
短链的好处如下:
- 链接变短,在对内容长度有限制的平台发文,可编辑的文字就变多了。比如微博限定了只能发 140 个字,如果一串长链直接复制上去就没地方再写其他文字了
- 大家接受各种短信的时候,能发现大部分链接都是短链形式,因为一般短信发文有长度限度,如果用长链,一条短信很可能要拆分成两三条发,相应的成本也就增加了
- 使用短链在排版上更加美观
短链跳转的基本原理
点击短链后,看下控制台:
 图片
图片
可以看到返回了状态码 302(重定向)与 location 值为长链的响应,然后浏览器会再请求这个长链以得到最终的响应,整个交互流程图如下:
 图片
图片
那么问题来了,301 和 302 都是重定向,到底该用哪个,这里需要注意一下 301 和 302 的区别:
- 301,代表 永久重定向:第一次请求拿到长链接后,下次浏览器再去请求短链的话,不会向短链服务器请求了,而是直接从浏览器的缓存里拿,这样的话短链服务器就无法获取到短链的点击数了,不利于数据分析,所以我们一般不采用 301
- 302,代表 临时重定向:每次去请求短链都会去请求短链服务器(除非响应中用 Cache-Control 或 Expired 暗示浏览器缓存),这样便于短链服务器统计点击数
生成短链的两种方法
方法 1:哈希算法
哈希算法可以将一个不管多长的字符串,转化成一个长度固定的哈希值。我们可以利用哈希算法,来生成短链。
常见的哈希算法就是 MD5、SHA 等,但实际上并不需要这些复杂的哈希算法。因为在生成短链这个问题上不需要考虑反向解密的难度,只需要关心哈希算法的计算速度和冲突概率就可以了。
能够满足这样要求的简单的哈希算法有很多,其中比较著名并且应用广泛的一个哈希算法,那就是 MurmurHash 算法。尽管这个哈希算法在 2008 年才被发明出来,但现在它已经广泛应用到 Redis、MemCache、Cassandra、HBase、Lucene 等众多著名的软件中。
MurmurHash 算法提供了两种长度的哈希值,一种是 32bits,一种是 128bits。为了让最终生成的短链尽可能短,我们可以选择 32bits 的哈希值。比如假设某个长链接经过 MurmurHash 计算后得到的哈希值是 181338494,再拼上短链服务的域名就变成了最终的短链 http://sourl.cn/181338494(其中,http://sourl.cn 是短链服务的域名)。
如何让短链更短
不过,通过 MurmurHash 算法得到的短链还是很长啊。别着急,我们只需要稍微改变一个哈希值的表示方法,就可以轻松把短链变得更短些。
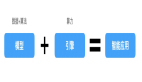
将 10 进制的哈希值,转化成更高进制的哈希值,这样哈希值就变短了。
16 进制中,用 A~F,来表示 10~15。在网址 URL 中,常用的合法字符有 0~9、a~z、A~Z 这样 62 个字符。为了让哈希值表示起来尽可能短,我们可以将 10 进制的哈希值转化成 62 进制。具体的计算过程如下图。最终用 62 进制表示的=短链就是 http://sourl.cn/cgSqq。
 图片
图片
如何解决哈希冲突
哈希算法无法避免的一个问题,就是哈希冲突。尽管 MurmurHash 算法,冲突的概率非常低。但是,一旦冲突,就会导致两个原始网址被转化成同一个短链。当用户访问短链的时候,我们就无从判断,用户想要访问的是哪一个原始网址了。这个问题该如何解决呢?
一般情况下,我们会保存短链跟原始网址之间的对应关系,以便后续用户在访问短链的时候,可以根据对应关系,查找到原始网址。存储这种对应关系的方式有很多,比如我们自己设计存储系统或者利用现成的数据库比如 MySQL、Redis。
以 MySQL 为例,当有一个新的原始网址需要生成短链的时候,我们先利用 MurmurHash 算法,生成短链。然后将这个新生成的短链,在 MySQL 数据库中查找:
- 如果没有找到相同的短链,这就表明这个新生成的短链没有冲突。于是我们就将这个短链返回给用户,然后将这个短链与原始网址之间的对应关系,存储到 MySQL 数据库中
- 如果在数据库中找到了相同的短链,那也并不一定说明就冲突了。我们先从数据库中将这个短链对应的原始网址取出来:
- 如果数据库中的原始网址,跟我们现在正在处理的原始网址是一样的,这就说明已经有人请求过这个原始网址的短链了。我们就可以拿这个短链直接用。
- 如果数据库中记录的原始网址,跟我们正在处理的原始网址不一样,那就说明哈希算法发生了冲突。不同的原始网址,经过计算,得到的短链重复了。这个时候,我们可以给原始网址拼接一串特殊字符,比如
DUPLICATED,然后再重新计算哈希值,两次哈希计算都冲突的概率,显然是非常低的。假设出现非常极端的情况,又发生冲突了,我们可以再换一个拼接字符串,比如OHMYGOD,再计算哈希值。然后把计算得到的哈希值,跟原始网址拼接了特殊字符串之后的文本,一并存储在 MySQL 数据库中。
当用户访问短链的时候,短链服务先通过短链,在数据库中查找到对应的原始网址。如果原始网址有拼接特殊字符(这个很容易通过字符串匹配算法找到),就先将特殊字符去掉,然后再将不包含特殊字符的原始网址返回给浏览器。
如何优化性能
在短链生成的过程中,服务器会执行两条 SQL 语句:
- 第一个 SQL 语句是通过短链查询短链与原始网址的对应关系
- 第二个 SQL 语句是将新生成的短链和原始网址之间的对应关系存储到数据库
很显然,第二步是无法避免的,而第一步可以通过给短链字段建立唯一索引来优化
这样,当有新的原始网址需要生成短链的时候,并不会拿生成的短链在数据库中查找判重,而是直接将生成的短链与对应的原始网址尝试存储到数据库中。如果数据库能够将数据正常写入,那说明并没有违反唯一索引,也就是说,这个新生成的短链并没有冲突。
当然,如果数据库反馈违反唯一性索引异常,那我们还得重新执行上述的“查询、写入”过程,SQL 语句执行的次数不减反增。但是,MurmurHash 的冲突概率还是比较低的,所以,从整体上看,总的 SQL 语句执行次数会大大减少。
那如果数据量非常大,冲突概率大幅上升,这种情况下该怎么办?
可以使用布隆过滤器。
把已经生成的短链,构建成布隆过滤器。当有新的短链生成的时候,我们先拿这个新生成的短链,在布隆过滤器中查找。如果查找的结果是不存在,那就说明这个新生成的短链并没有冲突。这个时候,我们只需要再执行写入短链和对应原始网页的 SQL 语句就可以了。
方法二:ID 生成器
我们可以维护一个 ID 自增生成器。它可以生成 1、2、3…这样自增的整数 ID。当短链服务接收到一个原始网址转化成短链的请求之后,它先从 ID 生成器中取一个号码,然后将其转化成 62 进制表示法,拼接到短链服务的域名(比如http://sourl.cn/)后面,就形成了最终的短链。最后,我们还是会把生成的短链和对应的原始网址存储到数据库中。
理论非常简单好理解。不过,这里有几个细节问题需要处理。
相同的原始网址可能会对应不同的短链
每次新来一个原始网址,我们就生成一个新的短链,这种做法就会导致两个相同的原始网址生成了不同的短链。这个该如何处理呢?实际上,我们有两种处理思路。
- 第一种处理思路是不做处理。听起来有点匪夷所依,但实际上,相同的原始网址对应不同的短链,这个用户是完全可以接受的。在大部分短链的应用场景里,用户只关心短链能否正确地跳转到原始网址。至于短链长什么样子,他其实根本就不关心。
- 第二种处理思路是拿原始网址在数据库中查找,看数据库中是否已经存在相同的原始网址了。如果数据库中存在,那我们就取出对应的短链,直接返回给用户。
不过,这种处理思路有个问题,我们需要给数据库中的短链和原始网址这两个字段,都添加索引。短链上加索引是为了提高用户查询短链对应的原始网页的速度,原始网址上加索引是为了加快刚刚讲的通过原始网址查询短链的速度。这种解决思路虽然能满足 “相同原始网址对应相同短链” 这样一个需求,但是是有代价的:一方面两个索引会占用更多的存储空间,另一方面索引还会导致插入、删除等操作性能的下降。
如何实现高性能的 ID 生成器
实现 ID 生成器的方法有很多,比如利用数据库自增。当然我们也可以自己维护一个计数器,不停地加一加一。但是,一个计数器来应对频繁的短链生成请求,显然是有点吃力的(因为计数器必须保证生成的 ID 不重复,笼统概念上讲,就是需要加锁)。如何提高 ID 生成器的性能呢?关于这个问题,实际上,有很多解决思路。我这里给出两种思路。
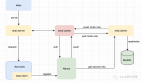
第一种思路是给 ID 生成器装多个前置发号器。我们批量地给每个前置发号器发送 ID 号码段(这一段的 ID 归属于这个发号器,不用担心ID 重复)。当我们接受到短链生成请求的时候,只需要选择一个前置发号器来取号码就行了。这样通过多个前置发号器,明显提高了并发发号的能力。
可能不是很好理解,这里类比下 “无锁的并发生产者 - 消费者模型”:
对于生产者来说,它往队列中添加数据之前,先申请可用空闲存储单元,并且是批量地申请连续的 n 个(n≥1)存储单元。当申请到这组连续的存储单元之后,后续往队列中添加元素,就可以不用加锁了,因为这组存储单元是这个线程独享的。不过,申请存储单元的过程还是需要加锁的。
对于消费者来说,处理的过程跟生产者是类似的。它先去申请一批连续可读的存储单元(这个申请的过程也是需要加锁的),当申请到这批存储单元之后,后续的读取操作就可以不用加锁了。
 图片
图片
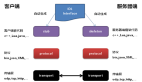
第二种思路跟第一种差不多。不过,我们不再使用一个 ID 生成器和多个前置发号器这样的架构,而是直接实现多个 ID 生成器同时服务。每个 ID 生成器按照不同的规则来生成 ID 号码,从而保证每个 ID 生成器生成的 ID 不重复。比如,第一个 ID 生成器只能生成尾号为 0 的,第二个只能生成尾号为 1 的,以此类推。这样通过多个 ID 生成器同时工作,也提高了 ID 生成的效率。
 图片
图片