













一、问题系统介绍
1. 监听商品变更MQ消息,查询商品最新的信息,调用BulkProcessor批量更新ES集群中的商品字段信息;
2. 由于商品数据非常多,所以将商品数据存储到ES集群上,整个ES集群共划分了256个分片,并根据商品的三级类目ID进行分片路由。
比如一个SKU的商品名称发生变化,我们就会收到这个SKU的变更MQ消息,然后再去查询商品接口,将商品的最新名称查询回来,再根据这个SKU的三级分类ID进行路由,找到对应的ES集群分片,然后更新商品名称字段信息。
由于商品变更MQ消息量巨大,为了提升更新ES的性能,防止出现MQ消息积压问题,所以本系统使用了BulkProcessor进行批量异步更新。
ES客户端版本如下:
BulkProcessor配置伪代码如下:
二、问题怎么发现的
1. 618大促开始后,由于商品变更MQ消息非常频繁,MQ消息每天的消息量更是达到了日常的数倍,而且好多商品还变更了三级类目ID;
2. 系统在更新这些三级类目ID发生变化的SKU商品信息时,根据修改后的三级类目ID路由后的分片更新商品信息时发生了错误,并且重试了5次,依然没有成功;
3. 因为在新路由的分片上没有这个商品的索引信息,这些更新请求永远也不会执行成功,系统的日志文件中也记录了大量的异常重试日志。
4. 商品变更MQ消息也开始出现了积压报警,MQ消息的消费速度明显赶不上生产速度。
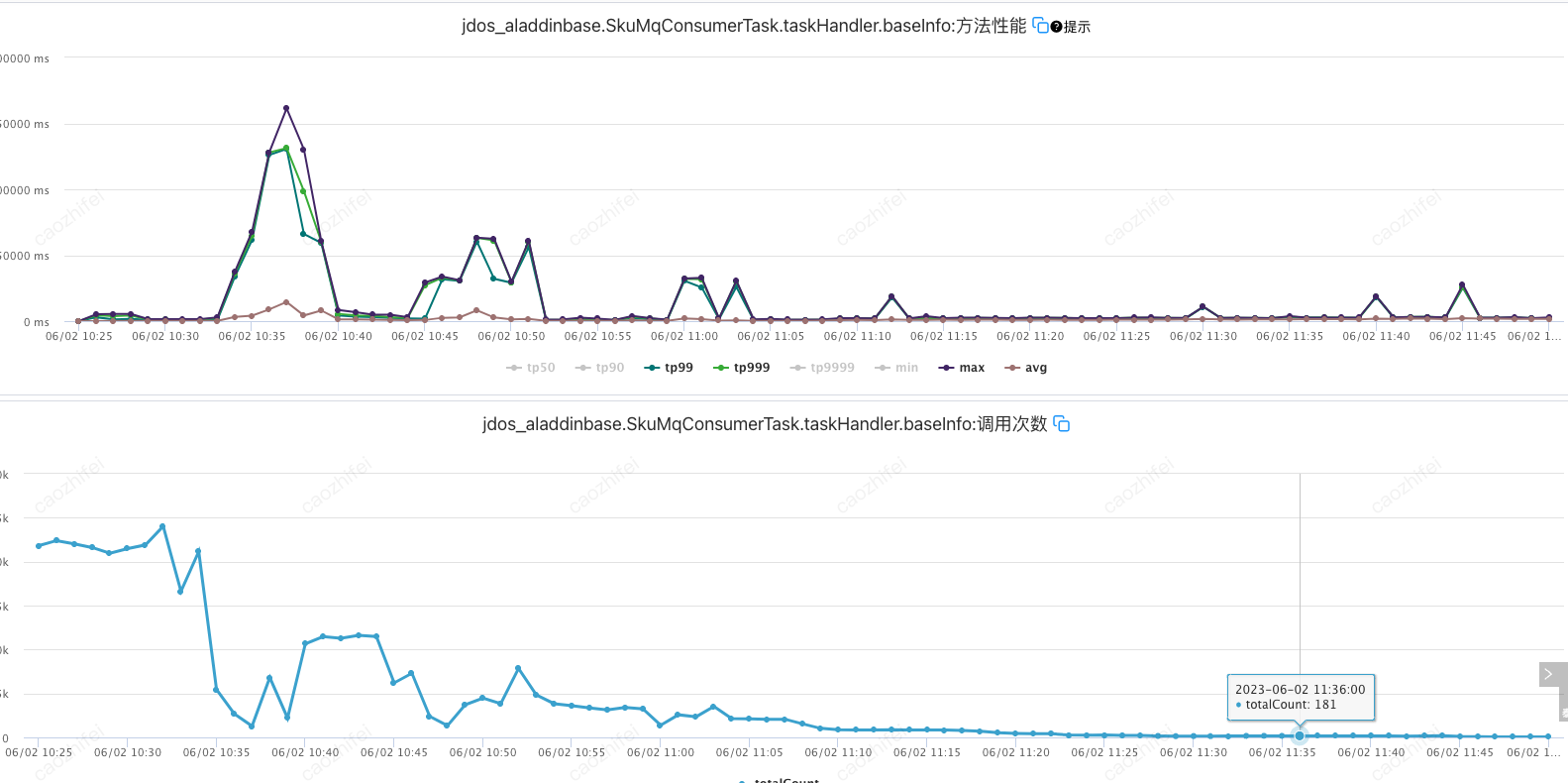
5. 观察MQ消息消费者的UMP监控数据,发现消费性能很平稳,没有明显波动,但是调用次数会在系统消费MQ一段时间后出现断崖式下降,由原来的每分钟几万调用量逐渐下降到个位数。
6. 在重启应用后,系统又开始消费,UMP监控调用次数恢复到正常水平,但是系统运行一段时间后,还是会出现消费暂停问题,仿佛所有消费线程都被暂停了一样。
三、排查问题的详细过程
首先找一台暂停消费MQ消息的容器,查看应用进程ID,使用jstack命令dump应用进程的整个线程堆栈信息,将导出的线程堆栈信息打包上传到 https://fastthread.io/ 进行线程状态分析。分析报告如下:
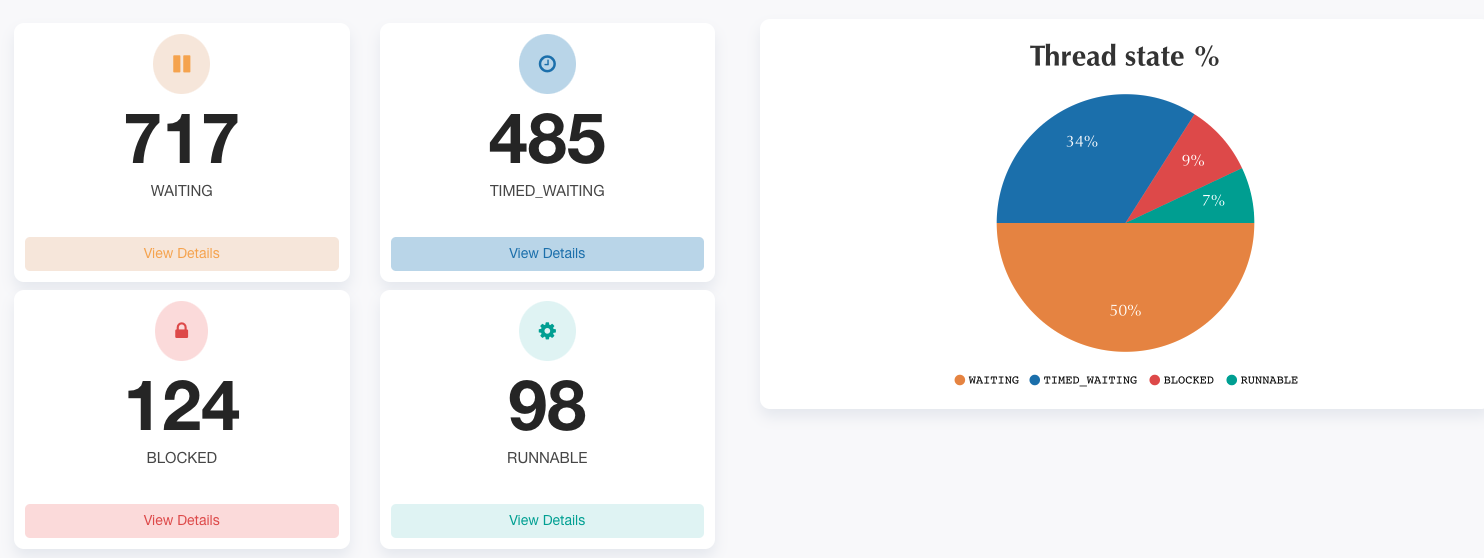
通过分析报告发现有124个处于BLOCKED状态的线程,然后可以点击查看各线程的详细堆栈信息,堆栈信息如下:

连续查看多个线程的详细堆栈信息,MQ消费线程都是在waiting to lock <0x00000005eb781b10> (a
org.elasticsearch.action.bulk.BulkProcessor),然后根据0x00000005eb781b10去搜索发现,这个对象锁正在被另外一个线程占用,占用线程堆栈信息如下:

这个线程状态此时正处于WAITING状态,通过线程名称发现,该线程应该是ES客户端内部线程。正是该线程抢占了业务线程的锁,然后又在等待其他条件触发该线程执行,所以导致了所有的MQ消费业务线程一直无法获取BulkProcessor内部的锁,导致出现了消费暂停问题。
但是这个线程elasticsearch[scheduler][T#1]为啥不能执行? 它是什么时候启动的? 又有什么作用?
就需要我们对BulkProcessor进行深入分析,由于BulkProcessor是通过builder模块进行创建的,所以深入builder源码,了解一下BulkProcessor的创建过程。
内部创建了一个时间调度执行线程池,线程命名规则和上述持有锁的线程名称相似,具体代码如下:
最后在build方法内部执行了BulkProcessor的内部有参构造方法,在构造方法内部启动了一个周期性执行的flushing任务,代码如下
通过源代码发现,该flush任务就是在创建BulkProcessor对象时设置的固定时间flush逻辑,当setFlushInterval方法参数生效,就会启动一个后台定时flush任务。flush间隔,由setFlushInterval方法参数定义。该flush任务在运行期间,也会抢占BulkProcessor对象锁,抢到锁后,才会执行execute方法。具体的方法调用关系源代码如下:
而上述代码中的add方法,则是由MQ消费业务线程去调用,在该方法上同样有一个synchronized关键字,所以消费MQ业务线程会和flush任务执行线程直接会存在锁竞争关系。具体MQ消费业务线程调用伪代码如下:
通过以上对线程堆栈分析,发现所有的业务线程都在等待elasticsearch[scheduler][T#1]线程释放BulkProcessor对象锁,但是该线程确一直没有释放该对象锁,从而出现了业务线程的死锁问题。
结合应用日志文件中出现的大量异常重试日志,可能与BulkProcessor的异常重试策略有关,然后进一步了解BulkProcessor的异常重试代码逻辑。由于业务线程中提交BulkRequest请求都统一提交到了BulkRequestHandler对象中的execute方法内部进行处理,代码如下:
BulkRequestHandler通过构造方法初始化了一个Retry任务对象,该对象中也传入了一个Scheduler,且该对象和flush任务中传入的是同一个线程池,该线程池内部只维护了一个固定线程。而execute方法首先会先根据Semaphore来控制并发执行数量,该并发数量在构建BulkProcessor时通过参数指定,通过上述配置发现该值配置为1。所以每次只允许一个线程执行该方法。即MQ消费业务线程和flush任务线程,同一时间只能有一个线程可以执行。然后下面在了解一下重试任务是如何执行的,具体看如下代码:
RetryHandler内部会执行提交bulkRequest请求,同时也会监听bulkRequest执行异常状态,然后执行任务重试逻辑,重试代码如下:
RetryHandler将执行失败的bulk请求重新交给了内部scheduler线程池去执行,通过以上代码了解,该线程池内部只维护了一个固定线程,同时该线程池可能还会被另一个flush任务去占用执行。所以如果重试逻辑正在执行的时候,此时线程池内的唯一线程正在执行flush任务,则会阻塞重试逻辑执行,重试逻辑不能执行完成,则不会释放Semaphore,但是由于并发数量配置的是1,所以flush任务线程需要等待其他线程释放一个Semaphore许可后才能继续执行。所以此处形成了循环等待,导致Semaphore和BulkProcessor对象锁都无法释放,从而使得所有的MQ消费业务线程都阻塞在获取BulkProcessor锁之前。
同时,在GitHub的ES客户端源码客户端上也能搜索到类似问题,例如:
https://github.com/elastic/elasticsearch/issues/47599 ,所以更加印证了之前的猜想,就是因为bulk的不断重试从而引发了BulkProcessor内部的死锁问题。
四、如何解决问题
既然前边已经了解到了问题产生的原因,所以就有了如下几种解决方案:
1.升级ES客户端版本到7.6正式版,后续版本通过将异常重试任务线程池和flush任务线程池进行了物理隔离,从而避免了线程池的竞争,但是需要考虑版本兼容性。
2.由于该死锁问题是由大量异常重试逻辑引起的,可以在不影响业务逻辑的情况取消重试逻辑,该方案可以不需要升级客户端版本,但是需要评估业务影响,执行失败的请求可以通过其他其他方式进行业务重试。
作者:京东零售 曹志飞
来源:京东云开发者社区
























