













马老板前几天刚刚官宣了他的AI公司xAI,要利用AI探索宇宙的本质。
好巧不巧,就在马老板到处摇人攒xAI的时候,科学界好像也和他心有灵犀,在Nature上发了一篇堪称「xAI目标的可行性报告」的论文。

论文地址:https://www.nature.com/articles/s41562-023-01648-z#auth-Jamshid-Sourati
这篇名为「用人类意识加持的AI加速科学发展」的论文,用科学严谨的方法让所有质疑马老板在画大饼的人暂时闭了嘴。
马老板看过之后,估计心里就十个字,打钱*5!
论文作者芝加哥大学的James Evans教授用一句话总结了这篇论文:
如果人类(用AI)增强了对自己在做什么的认知,就可以改进预测,并超越自身,从而加速科学的发展!

AI批评家马库斯也转发了这篇论文,希望人们能从对大模型的狂热中匀出点关注度给其他的AI相关进展。
就像马斯克在xAI的誓师大会上提到的。
如果未来出现的AGI不能帮助人类对一些困扰人类的本源问题做出解答,那它就不配被称为AGI。
同样,AI技术如果只是帮大学生糊弄下期末作业,不能帮助人类拓宽认知边界,那和英伟达的显卡只用来打游戏,却不用来训练AI一样,暴殄天物!
论文内容概述
具体来说,研究人员想要探索如何将人类意识与人工智能模型相结合来加速科学发展。
通过实验和数据集对比后,发现人工智能模型可以模拟人类科学家的推论,从而预测未来的发现,也能产生有价值的补充假设,还能帮助科学家避开那些没有前景的研究。
根据已发表的科学发现进行训练的AI模型,已经在材料科学领域帮助发明了有价值的材料,或者是在医学领域发现了靶向疗法。
但这样的AI只针对已有的科学发现进行了训练,没有结合更加专业的科学家认知。
研究人员在论文中表明,通过在人类专家可认知的推理上训练无监督模型来整合人类专业知识的分布,可以显著提高(高达400%)AI对未来科学发现的预测能力。

这样的方法大大超越了仅针对具体研究内容进行训练的AI预测。
尤其是在相关文献和成果比较稀少的领域,这个方法的效果尤为明显。
这类模型成功地预测了科学家将会做出的预测。
而且研究人员通过这个方式对「外星人」假设进行了科学的预测。
而如果没有AI的帮助,人类在短期之内是不可能解决这类假设的。
研究人员相信,具有人类意识的人工智能能够加速人类的发现或探索人类的盲点,使人类能够快速地大幅拓展科学的边界。
具体来说,研究人员首先将科学发现定义为:
首次报告现有材料与明确定义的属性之间的关系。
例如,「万古霉素可用于治疗肺炎」,其中万古霉素是材料,有效治疗肺炎是属性。
然后,研究人员的方法利用了对候选发现中涉及的每个主题集结的人类科学家分布的确定量,利用无监督流形学习(unsupervised manifold learning)的技术,结合可以获取到的出版物原始数据进行分析。
研究人员扩展了这种研究方法,用来识别更广泛的材料及其功能属性的矩阵,预测了治疗一百多种不同人类疾病的数千种药物的发现,其中包括针对COVID-19的疫苗和疗法。
研究方法
每个发科学现的预测实验包括一个目标属性和一组材料,其中材料由一个预测器进行评分,并选择得分最高的50种材料作为预测结果。
每个预测器通过计算材料与属性之间的相似度来对个别材料进行评分。
基于研究人员的超图(Hepergraph)的预测器使用的相似性度量包括材料节点和属性节点之间具有一个和两个中间作者节点的转移概率(因此是两步和三步的转移,即s=2和s=3),以及在deepwalk嵌入空间中的余弦相似度。
前者可以通过贝叶斯规则计算,无需生成随机游走(randam walk),但后者需要在研究人员的超图上显式生成一组随机行走序列。
基于内容的复制基线中的相似性度量是在在预测年份之前产生的出文献语料库上训练的Word2Vec模型的嵌入空间中的余弦相似度。
每个属性和潜在材料集合的出版物语料库和真实发现结果的准备方式各不相同。
用超图来将人类专家进行整合
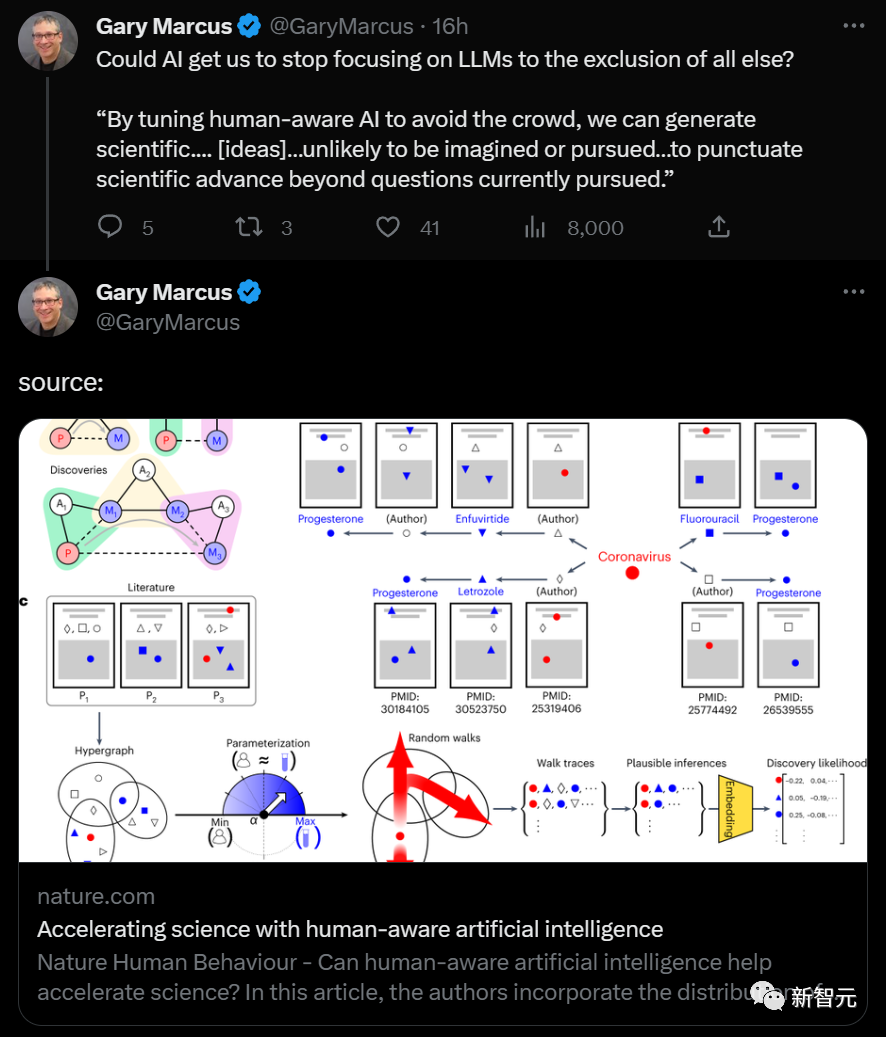
研究人员通过构建一个基于研究出版物的超图(Hypergraph)来对科学家集体和认知上可访问的推论分布进行共同建模。
超图是一个广义的图,其中一条边连接的是一组节点而不是节点对。
研究人员的研究超图是混合的,其中的节点不仅对应于标题或摘要中提到的材料和属性,还包括研究它们的科学家(如下图)。
 图片
图片
在构建研究超图之后,研究人员通过在其上生成随机游走序列来识别认知上可访问的推断。
这些游走为人类科学家提供了推理路径,并追踪发现了足以为前沿研究提供的各种专业知识的混合路径。
如果一个科学家在先前的研究中使用过铅钛酸铅(PbTiO3)这种铁电材料(可逆的电极化现象,用于传感器中),那么在研究具有价值的材料性质(例如铁电性)时,这个科学家更有可能考虑铅钛酸铅是否具有铁电性,而没有研究经验的科学家则不太可能这样做。
如果这个科学家后来与之前曾经研究过亚硝酸钠(NaNO2)这种铁电材料的另一个科学家合作发表论文,那么通过对话,这个科学家更有可能想象亚硝酸钠是否具有这种属性,而没有这种个人联系的科学家则不太可能这样做。
通过这种方式,研究人员的研究超图上的随机游走密度与认知上的合理性和通过对话获得的推论密度成比例。
如果两个文献没有共著的科学家,那么在研究超图中,随机游走就很少会将其桥接。
就像一位科学家很少会考虑将一个只有一个领域重视的属性,但与另一个完全不相干的领域所了解的材料联系起来一样(如下图)。

研究人员假设,识别周围具有高人类专家密度的主题将会为研究人员提供近期发现的有价值的信息信号。
就超图中在它们之间移动所需的步数而言,这些主题在超图中相隔甚远,需要许多步才能在它们之间游走。但是如果中间步骤在社会中交叉足够密集,且便于谈话和协作,那么随机游走和科学思维可以轻松地在它们之间旅行(上图)。
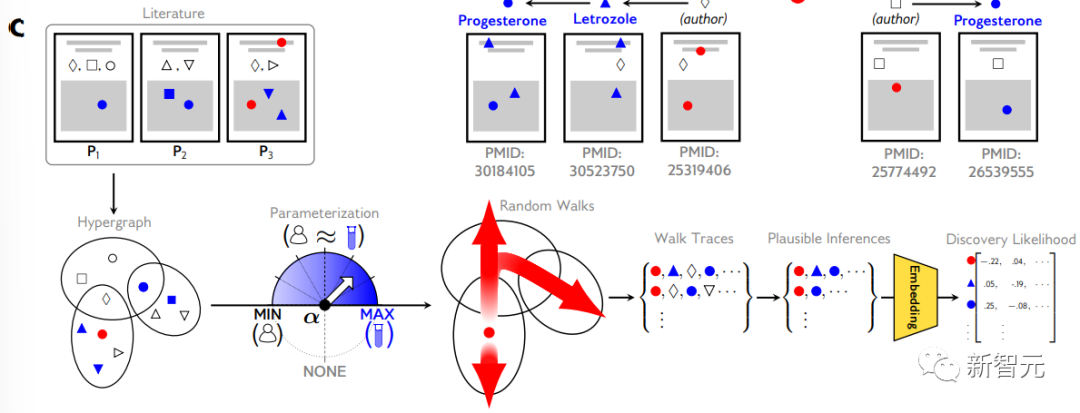
为了生成每个随机游走序列,模型 (i) 以一个有价值的属性(例如铁电性)作为序列中的第一个节点开始游走,(ii) 随机选择提到该属性的一篇文章(超边),(iii) 从那篇文章中随机选择一个材料或作者作为下一个节点,然后通过随机选择与新选择的材料或作者有关的另一篇文章开始第二步,并重复这个马尔可夫过程 (Markov process)预定次数(如下图)。
 图片
图片
每一步随机游走都可以看作是对人类行为的模拟:
作者-作者步模拟了两个专家合作者之间的网络或谈话;
作者-材料或作者-属性步表示作者对他们研究和发表过的所选材料/属性非常熟悉;
材料/属性-材料/属性步抓住了这种转变可能通过读取一系列科学文章而为人类科学家实现的可能性。
但由于某些学科间的协作特性,研究超图中的作者节点远远多于材料。为了补偿这种不平衡,研究人员设计了一个非均匀采样分布,其参数化由α决定。
α粗略地确定了结果序列中的材料与作者节点的比例。具体地,当从一篇论文中采样一个节点时(例如上述(iii)中),定义α以使选择材料的概率是选择作者的α倍(如下图)。
 图片
图片
较大的α值会导致更频繁地对材料进行采样,模拟研究人员将主要通过研究和阅读来发现新的科学可能性;
α值越小,作者选择的频率越高,这意味着研究主要通过社会网络、交流对话和与该领域的其他人协作进行发现。
在混合超图上进行的随机游走会在节点之间诱导有意义的邻近关系:
两个作者之间的邻近关系暗示着他们具有相似的研究兴趣和经历;
一个材料与一个属性之间的邻近关系反映了该材料可能具有该属性的可能性,也反映了一位科学家可能会通过研究经验、相关阅读或社会互动而熟悉该材料的可能性;
一个材料与一位科学家之间的邻近关系评估了其是否已经或将要熟悉那种材料的可能性;
两个材料之间的邻近关系暗示着它们可能是替代品、互补品,或者共享另一种更微妙的关系,如相互作用或比较。
最后,一个材料与一个属性之间的邻近关系会揭示该科学家可能会发现和发表该材料(如下图)。

通过这种方式,超图诱导的邻近关系结合了文献中潜在的物理和材料属性,也结合了人类科学家的分布。
这使研究人员能预测那些科学家的推断并预测即将到来的发现。
人类科学家的分布能从科学家们出席会议和调查他们的领域中,寻找到有前途的新方向。
为了预测具有重要属性材料的潜在发现,研究人员利用随机游走诱导的节点相似性指标来捕获目标属性与候选材料之间的相关性。
这些指标在属性/材料节点对之间进行评估,反映了相应节点的人类可推断相关性,并对候选材料进行排序,报告那些推断拥有该属性排名最高的材料。
这种简单的度量利用局部超图结构来估计随机步行者在固定步数(用s表示)内通过中间作者节点从属性节点移动到材料的过渡概率。
研究人员使用贝叶斯规则来计算这些概率,而无需实际运行随机游走采样器(如下图)。

在这里,只需要考虑两步和三步转移(s=2和s=3)。然而,研究的主要指标选择基于一个流行的无监督神经网络嵌入算法(deepwalk),它是在研究生成的随机游走上进行估计的。
虽然基于文本嵌入,主要捕获的是词之间的语义相关性,但此研究方法能够保留所有节点之间的超图邻近关系,同时还能获得词向量。
因此结果可以用来测量每个材料相对于目标属性的人类认知可及性。
因为推断出发现涉及的相关材料,研究人员在从随机游走序列中排除了作者,并将训练后的deepwalk嵌入模型(下图)。
结果嵌入空间中的余弦相似度可以用作相关性指标。
研究人员使用这两个相关性指标:转移概率和deepwalk相似度,作为选择最有可能出现为下一个发现的材料的双重标准。
另外,研究还训练了更深的图卷积神经网络。这确认了从deepwalk获得的结果模式。
总的来说,研究通过构建包含多类节点的超图,在上面模拟科学家行为,来捕捉科学认知和协作的特点,从而预测科学发现。
这项研究不仅考虑节点内容,也考虑科学家分布,能使模型结果更符合人类思维。
参与人类发现的成果
为了证明人类专家的计算能力,研究人员使用转移概率和deepwalk指标来构建两个替代的发现预测器。
这些算法通过嵌入人类感知的超图,根据给定预测年份(例如2001年)之前发表的文献来评估焦点属性与每个候选材料的相关性。
研究人员将他们的预测与随机基线和精确复制的先前工作生成的预测进行对比,这些预测使用基于科学文献文本内容的词嵌入,而不考虑人类科学家的分布。
这项准备工作通过Word2Vec模型的余弦相似性来衡量属性/材料的相关性,该模型是根据预测年之前发表的科学文章的内容进行训练的。
研究人员的实验和评估框架与本研究的设置相同,以便于精确复制。
每个评估的算法都会根据超图或Word2Vec相似性度量选择与焦点属性最相似的50种材料,并将它们报告为发现预测。
研究人员根据预测年份与发现和发布的材料的重叠来评估预测质量。
能源相关材料预测
在研究人员的第一组实验中,他们针对10万种候选无机化合物考虑了热电、铁电和光伏容量的宝贵电化学特性。
在同一数据集(有关无机材料的150万篇科学文章)上,研究团队针对2001 年所有三个属性的预测进行了预测实验,预测未来的发现作为当代科学家公开研究的函数。
他们计算了预测年份之后的年度精度,直到2018年底(下图1)并以累积方式将其可视化(下图2)。结果表明,考虑到人类科学家分布的预测对所有属性和材料的预测平均优于基线100%。
 图1
图1

药物重新利用的预测
研究人员使用相同的方法来探索约4K种FDA批准的现有药物的重新利用,以治疗100种重要的人类疾病。
他们使用生物医学研究的MEDLINE数据库文献并将预测年份设置为2001年(下图)。

事实真相的发现是基于比较毒理学数据库(CTD)的专家管理者建立的药物与疾病的关联,该数据库记录了化学品影响人类健康的能力。
下图报告了预测年份18年后的预测精度,揭示了在研究人员的无监督超图(unsupervized hypergraph)嵌入中考虑生物医学专家的分布如何产生,比仅考虑研究内容的相同模型高43%的预测精度。

研究人员发现他们的人类感知预测精度与文献中的药物出现频率之间存在很强的相关性(r=0.74,p<0.001),这意味着研究人员的方法最适合先前研究中经常提到相关药物的疾病。
COVID-19治疗和疫苗预测
研究人员还考虑了治疗或预防SARS-CoV-2感染的疗法和疫苗。
这里,预测年定为2020年(下图),全球范围内开始认真寻找相关药物和疫苗。

继先前研究之后,如果一种疗法能够汇集和COVID-19临床案例相关的实质性证据,那么研究人员考虑认为这种疗法与COVID-19相关。
如下图所示的结果表明,通过转移概率和基于深度游走(deepwalk)的指标做出的预测,分别有36%和38%的预测,被专家在预测日期后12个月内进行了大规模的临床试验来进行评估(即到2020年12月为止),到2021年7月底,这一比例进一步增加到42%。

这比仅由科学内容加持的AI模型生成的候选发现的精确度高出350至400%(第一次发现后的精确度为10%,到2021年7月精确度为12%)。
这些COVID-19预测的成功表明,对COVID疗法和疫苗的快节奏研究如何提高了科学家先前研究经验和网络的重要性。
针对人类的预测
研究人员的预测模型利用发现的专家分布,成功改进了发现预测。
为了证明这一点,研究人员考虑了从预测年份开始科学家做出发现所需的时间。
认知上接近研究特定属性的研究人员社区的材料会受到更多关注,并且它们与该属性的关系可能比远离社区的材料更早被调查、发现和发布。
换句话说,发现的「等待时间」应该与认识到某个属性和候选材料的专家群体的规模成反比。
研究者通过将属性/材料对之间的人类专家密度定义为两组人类专家的杰卡德(Jaccard)指数来衡量这一群体的规模:在最近的文献中提到该属性的人和提到每种候选材料的人(下图),这个图衡量了社区研究属性和质量之间的重叠百分比。

对于前面提到的所有三种电化学特性、COVID-19疗法和疫苗,以及上面考虑的100种疾病中的大多数,研究发现日期和专家密度之间的相关性是负的、显著的和实质性的(如下图)。

这一结果证实了研究人员的假设,即受到更大量专家关注的材料会更早被发现。
研究人员的预测模型有效地利用过去文献的超图来合并展示了这些人类专家密度(下图)。

基于嵌入邻近度可以得出类似的结果如:
下图说明了研究人员的预测如何聚集在人类专家及其研究的材料的联合嵌入空间中的密度峰值上。
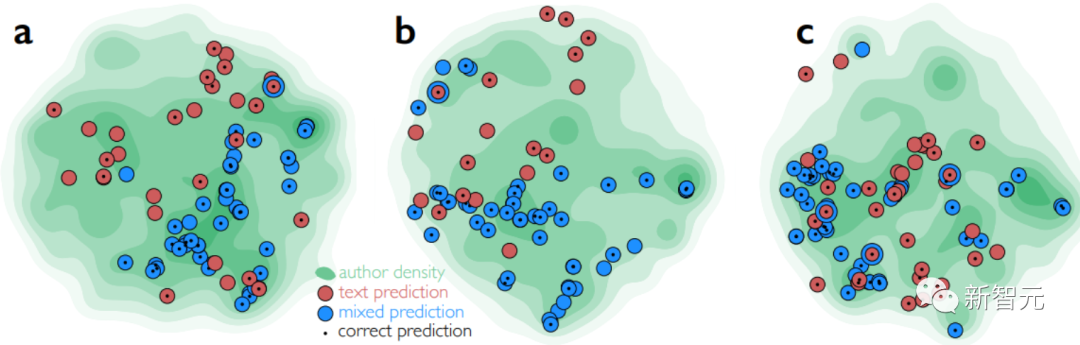
这进一步证明,研究人员的关注人类专家的方法可能会选中更容易被该领域的专家接触到的科学发现。
对于补充人类发现的成果
研究人员可以利用人类认知可用性模型不仅可以接近和模仿,还可以回避没有前景的研究和补充人类专家的分布。
人类的概念联系是由先前的发现及其发现者引导的(如下图)。
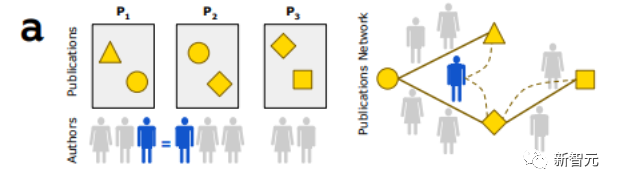
为了构建具有人类意识的AI,提出科学家不可能想象的概念联系,研究人员使用混合超图中作者互连的概念节点对之间的最短路径距离(SPD),来反转了测量人类认知可认识性的方法。
为了排除缺乏科学前景的候选假设,研究人员将认知不可用性与科学合理性信号结合起来。
该信号可以由已发表的研究文献的内容提供,并通过无监督的知识嵌入模型进行量化。
或者说,科学合理性的信号可以从理论驱动的材料特性模型中得出。
在这里,研究中的算法使用无监督的知识嵌入,保留理论驱动的属性模拟来评估预测结果的价值和人类互补性。
具体来说,研究人员使用该假设中涉及的材料和属性节点的嵌入向量之间的余弦相似性来预测任何给定假设的科学价值。
下图概述了研究人员的算法方法,以此识别科学上合理且人类无法认知或互补的发现。
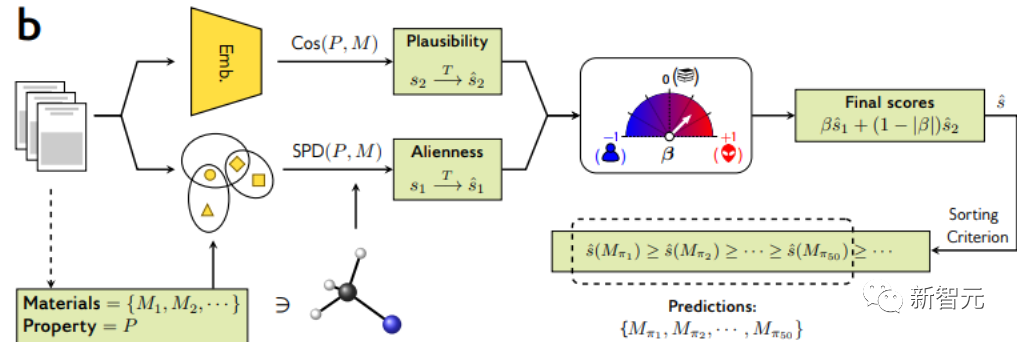
以从文献中提取出一个候选材料池为开头,研究人员在先前的分析基础上以集成的方式计算人类可访问性和科学合理性信号,以生成类似人类的预测。
在之前的文献中使用无监督词嵌入模型,以嵌入内的余弦距离来衡量科学相关性。
评估发现的预测
研究人员的人类感知模型旨在让他们能够调整预测与近期人类发现的相似程度。
随着增加𝛽,算法会避免人类可访问的位于高专家密度区域内的推论,并专注于跨越学科鸿沟并逃避人类注意力的候选材料和属性。
结果强烈证实了研究预期,即以较高𝛽值推断的材料不太容易被人类科学家发现(下图)。

此外,距离超图中给定属性较远的材料预计在较长时间内对于该属性附近的科学家来说仍然无法认知(如下图)。

该领域的研究人员需要更多的时间来弥合将不熟悉的材料与有价值的属性分开的知识差距。
在最终发现的推论中,研究人员测量了发现等待时间,并期望随着预测从负(人类竞争)𝛽值转向正(人类互补)𝛽值,观察到等待时间的增加趋势。
每个𝛽值生成50个假设并评估结果预测表明,对于大多数目标属性,当增加𝛽时,平均发现等待时间显着增加(如下图)。

评估没有发现的预测
为了评估研究人员的算法预测的科学价值,包括那些在研究期间尚未发现的预测,还需要现有文献之外的数据。
对于较大的𝛽值,此类假设必然会涵盖绝大多数情况。
如果科学是一个有效的市场,并且专家以最佳方式追求科学质量,那么在人类回避的高𝛽假设中,将观察到科学承诺和功效成比例下降。
另一方面,如果科学家们沿着科学可能性的前沿聚集在一起,并且其持续努力产生的边际回报递减,那么在超越这些前沿时,可能会观察到希望的增加。
为了验证这一点,研究人员将平均理论得分的变化与各种𝛽值生成的假设的可发现性进行了对比。
如下图(第一行)所示,可发现性在𝛽从负值到正值转变附近下降,但其衰减比平均理论分数急剧得多,直到接近𝛽 = 0.4时才会崩溃。

这适用于电化学特性和大多数疾病。某些个别疾病的结果可以在上图的第二行中看到。
如下图所示,本节中考虑的绝大多数属性都会产生大量且显著的正期望差距。

在此基础上,研究人员使用概率模型来评估他们的算法与科学界对𝛽的任何值的预测的互补性。
这是通过显式计算联合概率来完成的,即随机选择的预测在所需属性方面是合理的,并且超出了当前科学家的研究范围。
这些概率指定了在增强人类集体预测方面平衡利用和探索的最佳𝛽。
下图的结果表明最佳点因不同属性而异,但可以将范围0.2-0.3区分为最一致有希望的区间。

在此期间,尽管假设不太可能来自科学界,但很可能产生成功的科学结果。
结论和讨论
这项研究证明了在人工智能系统中结合人类意识,能够加速实现对未来的发现。
研究中的人工智能模型通过直接预测人类发现和将要做出这些发现的人类专家,使预测精度提高了400%。
这些发现支持了超图中所描绘的人类经验和社会之间的联系在推动科学进步中的影响。
此外,通过调整研究中的算法来避免群体性思维,得到了前景广阔但在未来数年内如果没有机器的帮助则不太可能被想象、追求或发表的假设。
通过识别和纠正由领域界限和制度化教育形成的人类注意力的集体模式,这些模型补充了当代科学界的研究。
这表明研究人员专家意识超图中的连接性不仅对预测和加速人类在近期的发现有用,而且对推断只能在遥远的未来才能被科学家想象的颠覆性发现也有用。
研究人员还成功揭示了人类科学机构对科学发现的影响,这些机构将使科学家聚集在可能发现的前沿共同体中。
而研究中提出的「外星人」或人类与人工智能互补假设的成功,表明科学部门和学科的设置实质上限制了富有成效的探索。并指出人类能够通过重塑科学教育以实现和发现改善人类预测的机会。
在这个研究分析过程中,强调了人工智能结合人类个体和社会因素来补充而不是取代人类专业知识的力量。
人工智能可以设计为与科学界共同发展的系统和工具,而不是与之对抗的威胁。事实上,人工智能的加入能够帮助扩大人类想象力和科学探索的边界。

























