














一、前言
关注用户体验,提高页面性能,是每位前端研发同学的日常工作之一。提高页面性能对业务的帮助,虽不易衡量,但肯定是利远大于弊。如何衡量页面性能优劣?如何帮助研发同学快速定位到页面性能瓶颈点?一直是前端的重点工作之一。本文分享汽车之家在页面性能监控建设方面的部分工作,主要包含三方面:
技术选型
- 该选择哪些页面性能监控技术方案?
- 在尽可能不影响页面性能的前提下,既能客观、全面衡量页面性能,又能帮助研发同学快速定位性能瓶颈点,该采集哪些指标?
- SPA 应用非首页性能该如何评估?
- 在尽可能不影响页面性能和保证采集数据精准性的前提下,尽量多地采集和上报数据,如何选择合适的指标采集时机和上报方式?
整体架构设计
整合选中技术方案,构建体系化性能监控架构,提供性能监控和性能分析工具链,支持产研同学在 DevOps 各阶段中发现和定位页面性能问题。
建立评判体系
有数据,我们才能度量;有评分,技术才好改进。
利用采集到的众多指标,根据应用特性,按各性能指标的重要程度,设置不同的基线和权重,以加权平均的方式,求得应用得分。通过分数,直观告诉研发同学应用页面快或慢?应用性能高或低?是否需要改进?
应用得分只能反映单个应用的性能情况,主要服务于产研同学。一家公司有多个部门,每个部门有多个团队,一个团队有多个应用,我们需要公司、部门和团队层级的性能得分,才能让各级领导直观了解其负责队伍的页面性能,也方便上级领导判断下级各队伍之间的性能高低,所以我们根据应用 PV 数和应用级别,仍以加权平均算法,获得团队、部门和公司性能得分。
二、技术选型
根据监控页面性能时的运行环境,我们将技术方案分为两种:合成监控(Synthetic Monitoring,SYN)和真实用户监控(Real User Monitoring,RUM)。
合成监控 (以下简称 SYN)
指在通过仿真环境运行页面,评估页面性能。早期代表工具有我们熟知的 YSlow 和 PageSpeed。随着技术进步,当前三个最成熟的 SYN 工具为:Lighthouse、WebPageTest 和 SiteSpeed。Lighthouse 虽然仅支持 Chrome 浏览器、实施成本较高,但是有谷歌支持、易扩展、指标丰富、有评分诸多优势,已逐步代替 WebPageTest,成为 SYN 首选工具。 如下以 Lighthouse 为例介绍 SYN 的运行过程、优缺点。
运行过程
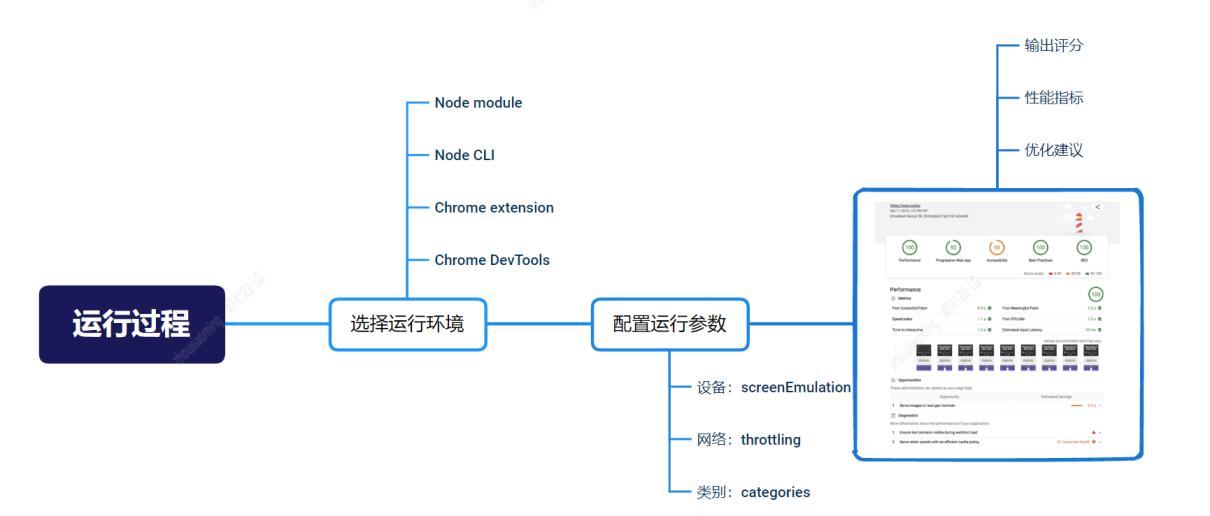
从运行结果页面来看,Lighthouse 除了输出关键性能指标值和评分外,还向我们提供优化建议和诊断结果。10.1.0 版 Lighthouse 分别内置 94、16 条性能和最佳实践方面的规范或建议,其中不乏日常研发比少留意且较有意义的规范,如:最大限度地减少主线程工作(mainthread-work-breakdown)、网页已阻止恢复往返缓存(bf-cache)、减少 js 文件中未使用的 JavaScript (unused-javascript)等。
推荐使用 Node Cli 或 Node Module 方式运行 Lighthouse,同时输出 html 和 json 格式的结果。json 中数据更全面,包含如:最大内容渲染时间元素(largest-contentful-paint-element)、应避免出现长时间运行的主线程任务(long-tasks)等明细信息。
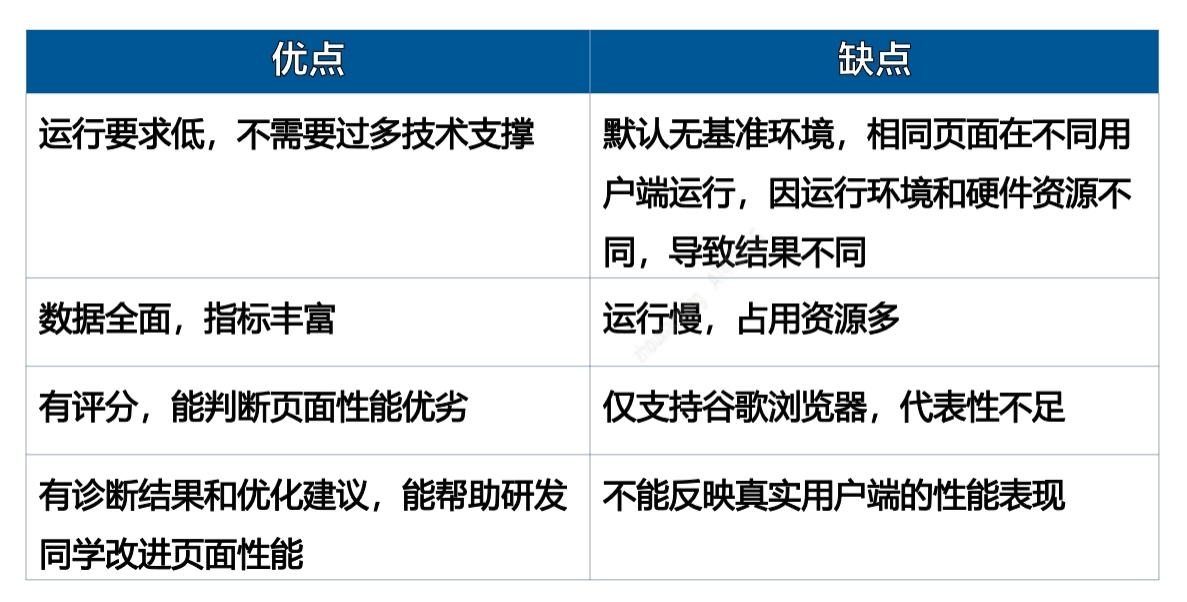
优缺点
根据我们实践,总结 Lighthouse 有如下优缺点:
改进
针对上述不足和产品需求,我们做了一些改进:
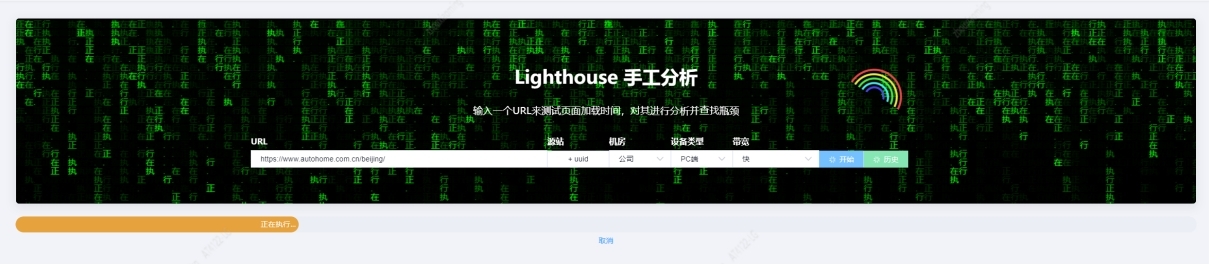
n 为解决 默认无基准环境,相同页面在不同用户端运行,因运行环 境和硬件资源不同,导致结果不同 的问题,我们做了两方面的改进:
首先,提供 SYN 基准运行环境。利用 Lighthouse Node Module 自研 Web 版 SYN 服务并部署在容器中。通过在 Node 服务端添加队列策略,保证单容器任意时间只允许运行一个 SYN 任务,且每个容器的硬件资源( 4 核 + 4G )和网速配置( M 端应用统一使用 10M 网速 )都一样,从而保证运行结果和最终得分是相对公平和可靠的。
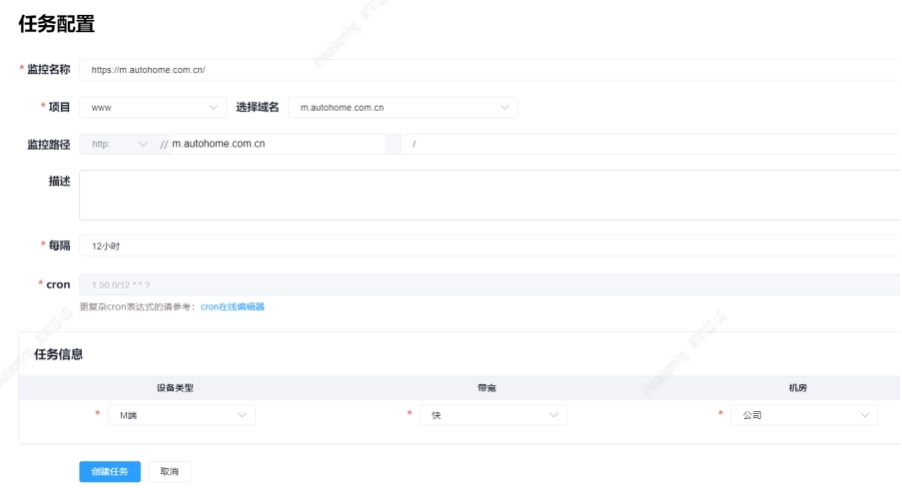
其次,支持以计划任务,间隔 6、12 或 24 小时 的方式运行 SYN 任务。 统计多次运行结果指标的 AVG、TP 值,排除少数异常运行的结果偏差。
- 针对 运行慢,占用资源多 的问题。我们认为相同页面,如果没有改版,没必要过于频繁的持续测试,建议 PV 量大或重要页面添加计划任务 12 小时及以上时间间隔运行一次,这样既能客观反映页面性能情况,也能节省资源。
- 将 SYN 集成到 CI 流水线中,将 SYN 作为上线前页面性能测试或竞品对比的实施工具。
适用场景
- 将 SYN 作为页面性能测试工具,集成到前端监控后台应用、QA 套件 和 CI 中。建议研发同学交付页面前,通过 SYN 评估页面性能并根据优化建议和诊断结果,改进页面质量缺陷,提高交付质量。
- 利用 SYN 做竞品对比。
- 将 SYN 作为分析 RUM 捕获到慢页面的首选工具,结合 Chrome DevTools , 从实践来看可以定位到多数问题。
使用方法

总结
SYN 实施成本低,便于统一标准,相比 RUM,受运行时环境的影响更小,结果更具有可比性和可复现性,是性能监控的重要一环。基于 Lighthouse,借助 K8S 等容器编排技术,快速搭建提供基准环境的 SYN Web 服务是建设页面性能监控体系的第一阶段。该阶段以提供评估页面性能、分析慢页面等关键功能为主。虽然 Lighthouse 还存在 仅支持谷歌浏览器,代表性不足,也不能真实反映真实用户端的性能情况 这两个问题,但瑕不掩瑜,可以作为 SYN 的首选方案。同时,这两个问题我们将通过添加另外一种技术方案:真实用户监控(RUM)来解决。
真实用户监控 ( 简称 RUM)
顾名思义,指监控运行在真实用户终端(浏览器),采集用户运行页面时候真实的性能指标。业内技术方案主要分为两种:
依托 W3C 组织且各浏览器厂商广泛支持技术方案:PerformanceTiming 和 PerformanceNavigationTiming。偏向从浏览器处理过程角度去衡量页面运行时各节点、各阶段的耗时。
各厂根据实际需求自研技术方案。谷歌 web-vitals 是其中最优秀的代表,它从用户体验角度,用更通俗易懂的指标展现页面性能。
除上述两种常见技术方案外,少数商业前端监控服务厂商,除了支持 W3C 和 web-vitals 外,还提供少数自定义性能指标,如:阿里 ARMS 中的 FMP 、字节 WebPro 里的 SPA_LOAD 。SPA_LOAD 用于评估 SPA 非首页的页面性能,有较大创新性,后面还会提及。
技术选型
技术选型主要解决两个问题:1)W3C 的 PerformanceTiming 和 PerformanceNavigationTiming 两规范,应该以哪个为主?2)W3C Timing 规范 和 web-vitals 应该如何协作?
W3C 的 PerformanceTiming 和 PerformanceNavigationTiming 两规范,应该以哪个为主?
PerformanceTiming:已被最新 W3C 标准废弃,不过当前主流浏览器仍支持,旧浏览器支持好,兼容度高。
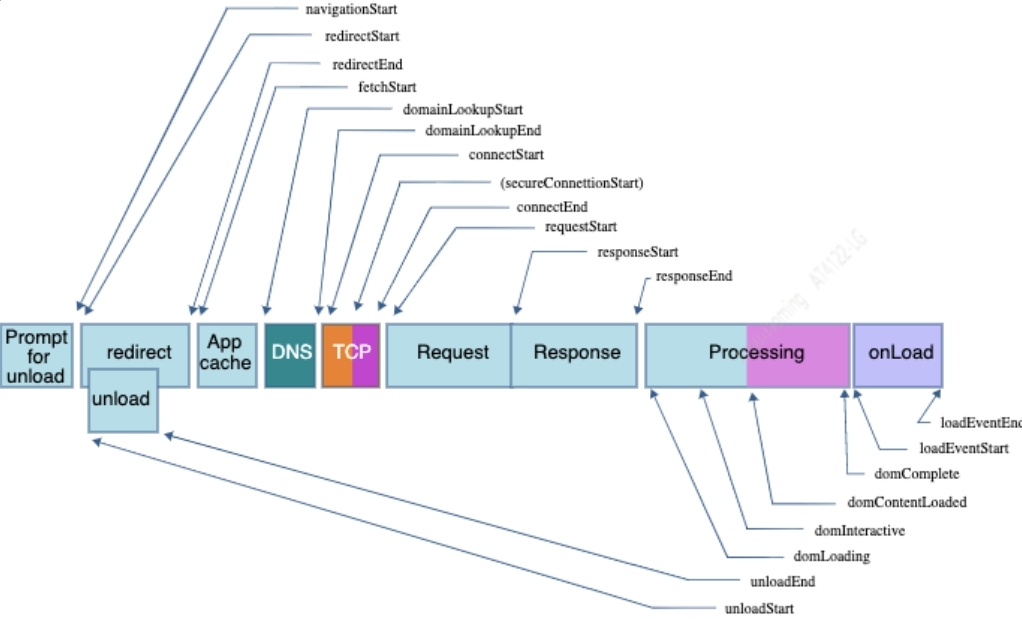
PerformanceNavigationTiming:最新标准随 Navigation Timing Level 2 于 2019 年推出,Navigation Timing Level 2 目的是代替涵盖 PerformaceTiming 的 Navigation Timing Level 1。
变更点:
- 整合 PerformanceTiming 和 PerformanceNavigation 功能。
- 废弃因各浏览器厂商实现不一,指导意义不足的 domLoading 节点。
- 添加 ServiceWorker 相关节点。
- 各属性节点时间使用高精度、以 startTime 为起点的相对时间。
优点:
- 使用高精度的相对时间,避免因用户端系统时间更改而导致后续节点值不准。
- 支持 ServiceWorker 相关统计。
缺点:
- 浏览器兼容性不足。
结论:
从 Can I Use 统计两者兼容度仅差 2.67%,但是从我们实际用户分布来看,使用 PerformanceNavigationTiming,用户兼容度下降 12%,难以接受。所以我们以 PerformanceNavigationTiming 为主,如浏览器不支持,则使用 PerformanceTiming。两者数据格式差异不大,忽略 PerformanceTiming 中 domLoading 节点,使用 PerformanceTiming 时认为浏览器不兼容 workStart 节点即可。
W3C Timing 规范 和 web-vitals 应该如何协作?
PerformanceNavigationTiming ( 以下简称 Timing ): 基于 W3C 规范,着重从浏览器处理过程角度衡量页面性能,以下简称 Timing。
优点:
- 浏览器兼容性好浏览器兼容性好。
- 数据丰富,指标全面。即包含各阶段耗时,如:Unload、Redirect、DNS、TCP、SSL、Response、DomContentLoadedEvent 和 LoadEvent;还支持显示页面运行到各节点时的耗时,如:workStart、fetchStart、requestStart、domInteractive 和 domComplate;也可以根据所给节点值,计算 DCL ( DomContentLoaded ) 、window.load 事件或者 PageLoad(页面加载)的耗时。
缺点:
- 缺乏关键指标。虽然指标多、全,但是不够直观,很难表达用户体验效果。
web-vitals: 目前含 6 个指标:TTFB、FCP、LCP、FID、INP 和 CLS,其中 FID 将被 INP 代替。TTFB、FCP 和 LCP 反映页面加载性能,FID 与 INP 代表页面交互体验,CLS 表示页面视觉稳定性。仅 6 个指标,就能支持对页面加载、交互和视觉稳定方面的评估。不过 web-vitals 部分指标源头还是来自于 W3C 制定的 LargestContentfulPaint、LayoutShift、PerformanceEventTiming 和 PerformancePaintTiming 等规范,不过兼容性更好、整体性更强。
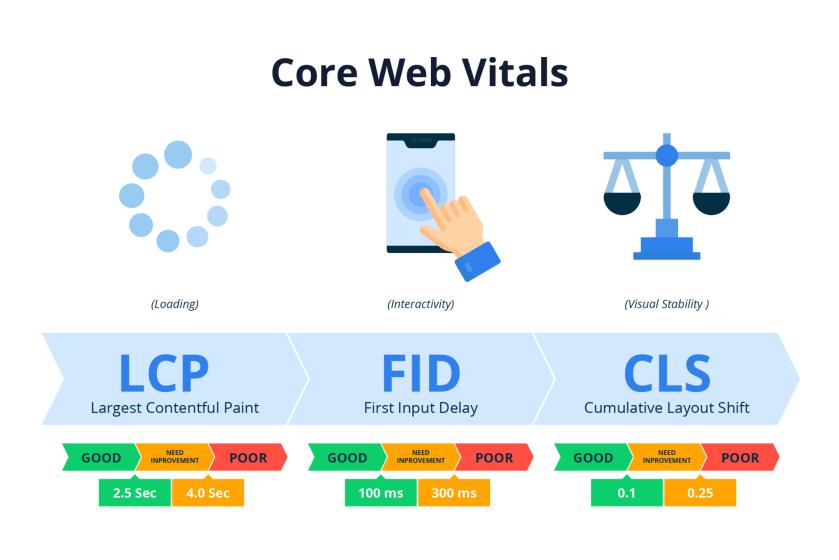
优点:
- 指标简明、精练、易懂。
- 自带基线,能根据指标,判断页面性能优劣。
缺点:
- 浏览器兼容不足,尤其在 IOS 端。
- LCP 可以伪造。做法:给页面添加大尺寸白底图,该图加载时间大概率就是 LCP 值,但是该 LCP 值并没有任何业务意义
- 受限于 LCP、CLS 原理,对采集指标时机有一定要求,后面会详细介绍。
述求
真实、客观、全面衡量页面性能。
结论
同时采集 Timing 和 web-vitals 数据,带来好处有:
- 指标丰富、数据全面,既能利用 Timing 站在浏览器角度反映各节点、各阶段处理耗时,也能通过 web-vitals 直观表达用户视觉体验。建议先通过 web-vitals 直观判断页面性能,再通过 Timing 再进一步分析,达到综合考虑、全面分析,减少因浏览器兼容不足、LCP 造假等情况下,误判页面性能。
- 结合 Timing 和 web-vitals 数据,更容易定位问题。如:web-vitals 采集到的 TTFB 慢,可以通过 Timing 定位到具体慢在 Unload、Redirect、DNS、TCP、SSL 哪个阶段。
- 解决 web-vitals 老浏览器兼容不足的问题。如果浏览器不支持 web-vitals, 可以通过 DCL、window.load 事件或者 PageLoad(页面加载)的耗时来判断页面性能。
小节:RUM 技术选型,同时采集 PerformanceNavigationTiming 和 web- vitals。如果浏览器不兼容 PerformanceNavigationTiming,则以 PerformanceTiming 代替。
采集哪些指标
我们的需求是:在尽可能不影响页面性能,既能客观、全面衡量页面性能,又能帮助研发同学快速定位性能瓶颈点。具体包含三方面需求:1) 指标要全面客观;2) 能发现慢页面的瓶颈点;3) 满足前面两需求前提下,尽可能不影响页面性能。
指标要全面客观
首先,我们采集了 web- vitals 六个指标,效果如下:
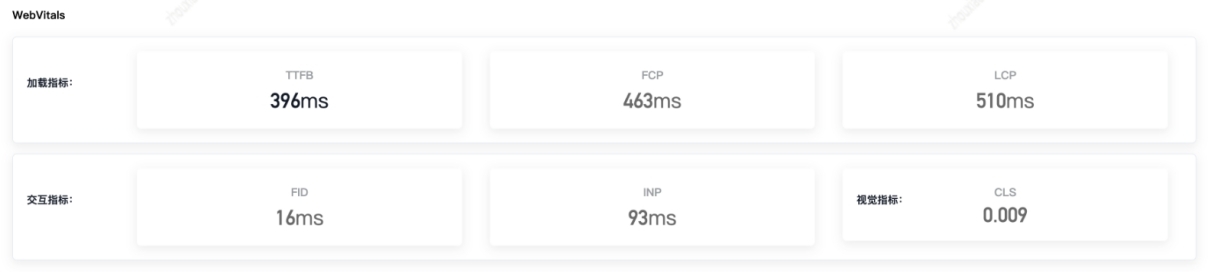
谷歌计划于 2024 年用 INP 替换 FID,FID 体现第一次交互的延迟时间,INP 表示所有交互中最长的延迟时间。我们认为 FID 和 INP 都有各自使用场景,同时保留并不矛盾。
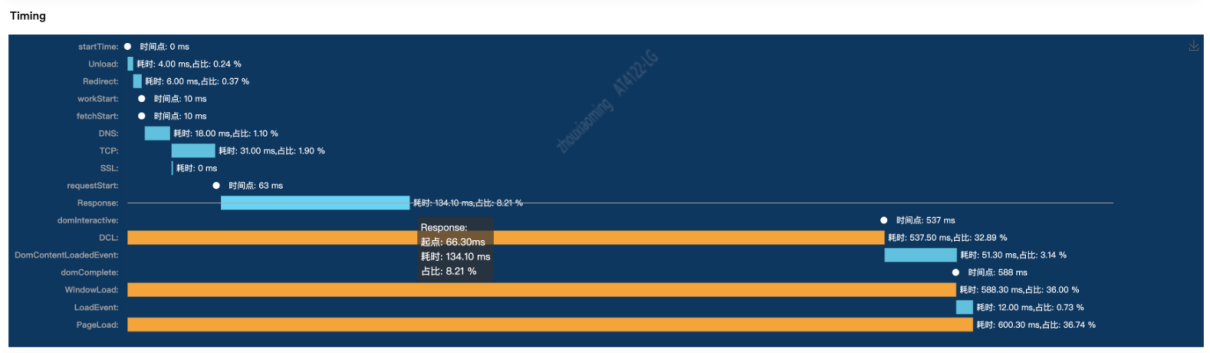
其次,我们对 PerformanceNavigationTiming 做了加工处理,效果如下:
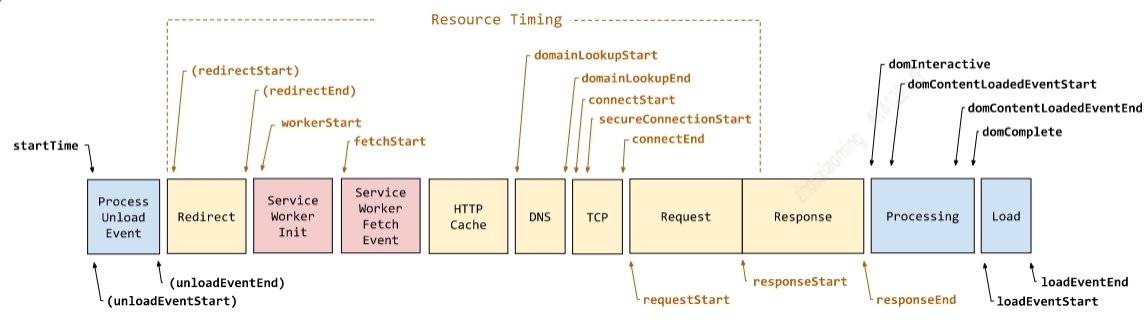
与下面的 W3C 示例图不同:
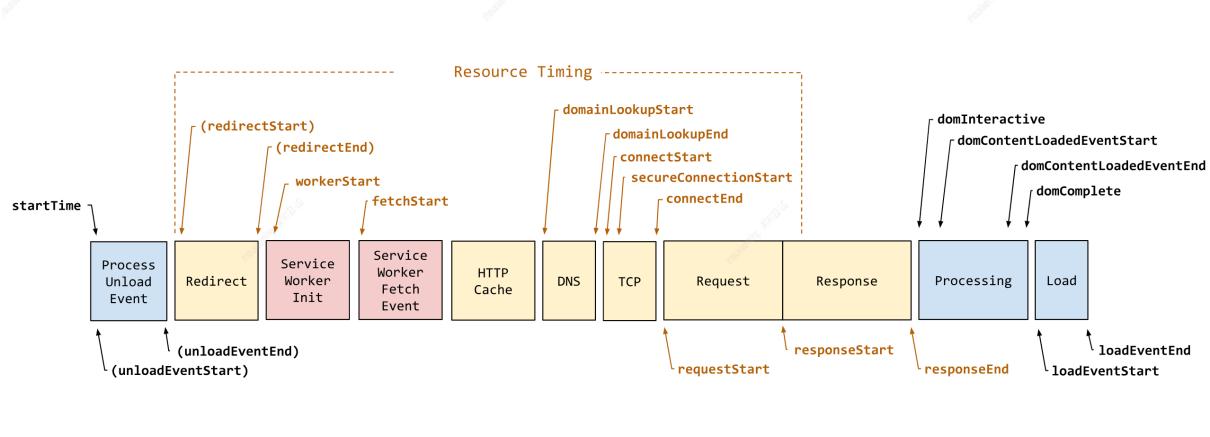
原因在于:
- 实际页面运行过程中,各阶段并不一定如上图那样串行运行。存在 responseEnd 耗时大于 domLoading 的情况。
- HTTP Cache 阶段并无起止时间节点,只能表明发生在 fetchStart 和 domainLookUpStart 节点之间。
- ServiceWorkerInit、ServiceWorkerFetchEvent 和 Request 阶段只有起始节点,没有终止节点,无法统计阶段耗时。对于 Request 阶段不能以 responseStart 作为终止节点,因为内容在网络中是分帧传送的,不一定可以一次传输整个页面内容。
- Processing 阶段以 domInteractive 为起点,不符合客观规律,页面执行到 domInteractive 时候 DOM is ready,所以 Processing 阶段无法代表页面处理过程。
所以我们结合 W3C 示例图,以点、段和线的方式,展示真实的页面运行过程:
- 点:指不存在终止节点的节点,含:workStart、fetchStart、requestStart、domInteractive 和 domComplete,用白色圆点表示。
- 段:指真实存在起始和终止节点的处理阶段,如 unload 阶段值为:unloadEnd - unloadStart。同理于 redirect、DNS、TCP、SSL、Response、domContentLoadedEvent 和 loadEvent,用蓝色柱状图表示。
- 线:含页面加载过程中触发的事件,如 DCL ( DomContentLoaded ) 、window.load。另外我们自定义 PageLoad 事件,表示整个页面加载耗时,值为:loadEventEnd-loadEventStart。用黄色柱状图表示。
段和线具体算法:
- UnloadEvent = unloadEventEnd - unloadEventStart
- Redirect = redirectEnd - redirectStart
- DNS = domainLookupEnd - domainLookupStart
- TCP = connectEnd - connectStart
- SSL = connectEnd - secureConnectionStart
- Response = responseEnd - responseStart
- loadEvent = loadEventEnd - loadEventStart
- DCL = domContentLoadedEventStart - startTime
- WindowLoad = loadEventStart - startTime
- PageLoad = loadEventEnd - startTime
此外,为了更全面体现页面性能,还采集和统计了如下输入:
- 小概率 (1%) 的采集完整 PerformanceEntry 数据。PerformanceEntry 包含 LargestContentfulPaint、LayoutShift、PerformanceEventTiming、PerformanceLongTaskTiming、PerformanceNavigationTiming、PerformancePaintTiming、PerformanceResourceTiming、PerformanceServerTiming 等方面数据,既包含页面本身性能指标,还涵盖资源、网络、缓存、JS 长阻塞任务、慢执行事件等多方面信息,对评估页面性能,判断慢页面瓶颈点很有帮助。考虑到大部分页面内容较多,导致 PerformanceEntry 集合条数太大,要是 100%采集上报,对带宽、存储、查询性能都有较大影响,所以只能小概率采集。
- 页面导航类型,取值于 PerformanceNavigationTiming.type,判断页面是首次加载还是刷新重载等。
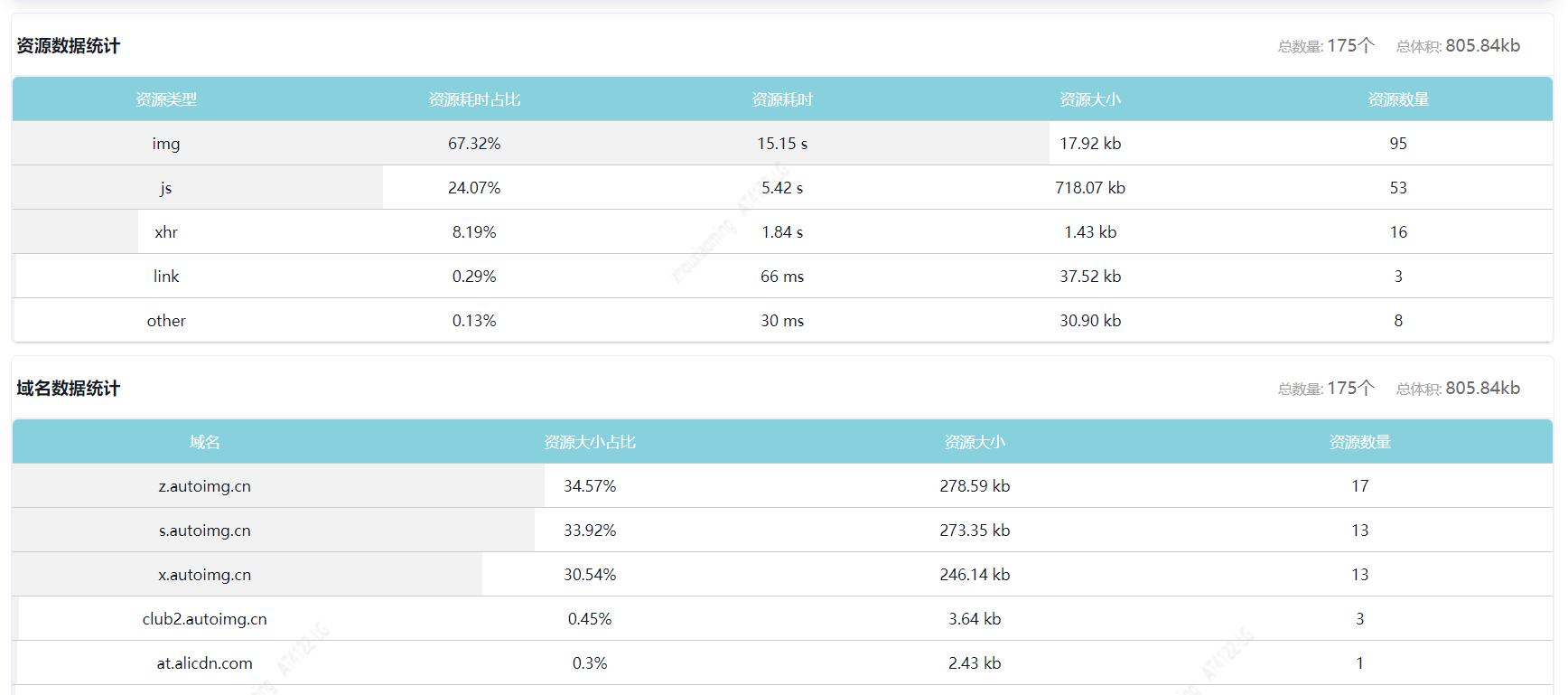
- 按资源类型,统计各类资源个数、总传输体积和总耗时。
- 按域名,统计各域名资源个数、总传输体积和总耗时。
能发现慢页面瓶颈点
我们参考Lighthouse 50 分线 和 HTTP Archive 站点统计数据,根据应用类型是 PC 或 M 来制定慢页面标准,具体阈值如下:
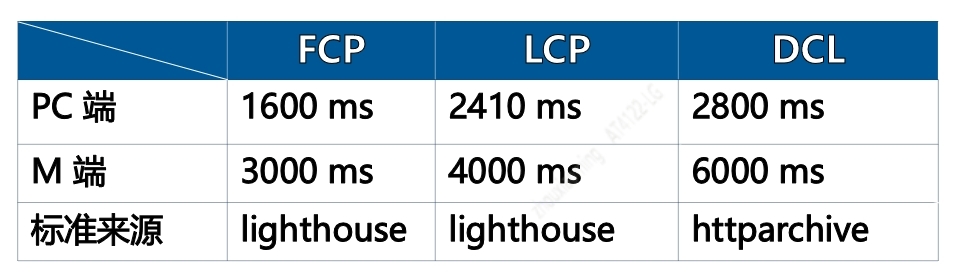
针对慢页面,我们除了采集上节提到的 PerformanceNavigationTiming、web- vitals、小概率的完整 PerformanceEntry 数据和统计数据外,我们还会采集:
- TOP N 慢资源,做法:取 duration 值最大的 N 个 PerformanceResourceTiming 类型的 PerformanceEntry。
- 长任务,指占用 UI 线程大于 50 毫秒的任务。做法:采集所有 PerformanceLongTaskTiming 类型的 PerformanceEntry。不过当前大部分浏览器无法提供长任务所在的脚本地址( containerSrc )和方法名称( containerName ),采集这部分数据,只能判断长任务是否发生?发生的次数。PerformanceLongTaskTiming 内容如下:

- 慢事件,指处理时间超过 104ms 的交互事件,做法:采集所有 PerformanceEventTiming 类型的 PerformanceEntry。
- 页面跳转次数,值为:PerformanceNavigationTiming.redirectCount,可以辅助分析 Redirect 阶段耗时多的原因。
- CLS 和 LCP 值大于慢页面阈值时,记录其关联的元素。
不影响页面性能
RUM 必须通过入侵页面,在页面引入 JS SDK 来实现,不可避免地影响页面性能。作为一个发现和分析页面性能的工具,不应该加重页面性能问题。为了将性能影响降到最低,我们做了两方面工作:
异步加载 JS SDK:页面只引入功能单一、体积小的 JS 头文件,待页面到达 DomContentLoaded 事件后,以动态 script 方式异步加载功能完整的 JS 主文件。
减少带宽占用:
- 抽样上报:慢页面必须上报,非慢页面抽样上报,默认抽烟比例为 30%,减少上报次数。
- 减少上报数据体积:全量的 PerformanceEntry 数据可以完整体现页面性能,不少页面动辄超过白条 PerformanceEntry 数据,体积过大,所以只能小概率采集全量 PerformanceEntry 数据,计算和采集 PerformanceEntry 的统计数据。
综上所述我们采集指标主要两大类:PerformanceEntry 和 web-vitals。
SPA 应用非首页性能该如何评估?
采集上述指标,已经可以较为客观全面评估常规页面和 SPA 应用首页的页面性能。但是 SPA 应用非首页不是浏览器标准,在 SPA 路由切换过程中:
- 浏览器仅会执行 History.replaceState()方法,不会也不该重新生成 PerformanceNavigationTiming 数据。
- 多数 PerformanceEntry 数据包含 SPA 首页以来所有路由切换页面的性能指标。以 PerformanceResourceTiming 为例,无法通过 History.replaceState()方法拿到真实路由切换的时机,排除 PerformanceResourceTiming 集合中的历史数据,从而获取当前路由的 PerformanceResourceTiming 数据。因为各前端框架在 SPA 路由切换过程中,大多数会先执行其框架内部逻辑,而后再触发 History.replaceState()方法,所以 History.replaceState()方法触发时间晚于路由切换的执行时间。
- web-vitals 暂时也不支持采集 SPA 非首页路由切换后的性能指标。
所以,对于上述指标 SPA 非首页无法或无法准确拿到,所以我们暂不评估 SPA 非首页性能。
针对业内 SPA 非首页性能难评估的情况,字节 WebPro 创造性地推出 SPA_LOAD 的概念,基本逻辑为:以触发 history.replaceState() 方法为起点,通过 MutationObserver 监听 dom 变更、资源加载、请求发送等变更事件来寻找一个页面达到稳定态的时间为终点,通过计算起终点之间的耗时,来衡量 SPA 非首页的页面性能。SPA_LOAD 类似于常规页面 onload 事件,但是起始时间比真实路由切换时间晚,到终止时间时页面可能已经加载完毕,略有不足,不过已是当前最佳的方案,后面我们可能引入。
采集指标时机
只有采集真实、准确的指标值,才能真实反映页面性能,反之,可能误导产研同学,错误评估真实的页面性能。所以选择采集指标时机有几大原则:
- 指标准,最关键是要保证指标是准的,不准不如不采。
- 样本多,上报可靠,部分指标,如 CLS、INP、PerformanceEventTiming 等,越晚采集值越准,但是越晚采集,留给上报的时间越少,数据上报失败的概率越大,为了尽量多采集数据样本,我们不能等到页面关闭时再采集指标、提交上报。
- 公平,部分指标,如 CLS、INP、LCP 等,随着页面打开时间边长,值可能也跟着变大。对于这类指标,我们只能保证数据”样本多“的前提下,选择一个相对合理、对“所有项目”都公平的采集时机。
- 一次上报,web-vitals 中部分指标如:LCP、CLS、INP,每次变更都会触发其回调函数,谷歌官方建议每次指标值变更都采集上报。这种处理逻辑,指标值是更准,但是占用太多前端的连接、带宽和 CPU 资源,也严重加大后端接收程序的处理难度,不是各合理均衡的选择。所以我们要找到一个合适的采集时机,一次采集并上报所有的性能指标。
那么如何确定采集时机?我们得先分析 PerformanceEntry 和 web-vitals 两类指标数据得准确生成时间:
对于 PerformanceEntry 数据,onload 事件触发时,页面已接近加载完毕,PerformanceEntry 中影响首屏加载的绝大部分指标数据已经生成。未生成的数据对评估页面性能影响不大,如:PerformanceNavigationTiming 中的 loadEventEnd 指标值。所以我们认为 onload 事件触发件时,可以采集 PerformanceEntry 指标。
web-vitals 中各指标生成原理不一,onload 事件触发时:
- TTFB、FCP 指标已生成且不会变,可以采集。
- LCP 对应的最大元素大概率已加载完毕,所以我们认为这时候 LCP 值大概率是准的,可以采集。
- CLS 值无法确定是否准确,其计算逻辑为:页面打开后每 5s 作为一个 session 窗口,累加该窗口内产生的偏移值即是 CLS 值,如果下一个 session 窗口的 CLS 值大于上一个 session 窗口,则替换。所以对于 CLS 指标来说,打开页面 5S 后、最好 5S 或其整数倍时采集,比较合适,对”所有项目“也比较公平。
- FID、INP 也无法确定是否准确,它们依赖用户交互操作后才生成,交互操作含:点击、输入、拖放、触摸等事件。FID 是第一次交互的延迟时间,INP 取多次交互操作中延迟时间最大的值。这两指标都依赖于用户操作,INP 可能会随着用户操作次数变多而值变大,所以任何时间都没法保证准确拿到这两指标值。
基于上述考虑,我们认为至少要满足:触发 onload 事件或打开页面 5s 之一条件时,才能保证 PerformanceEntry 或部分 web-vitals 指标值准确,采集才有意义。在追求”样本多“的原则下,结合 RUM SDK 是 onload 事件后异步加载的实际情况,我们针对页面是否被正常关闭前提下,总共设置了三种采集时机,其特点如下:
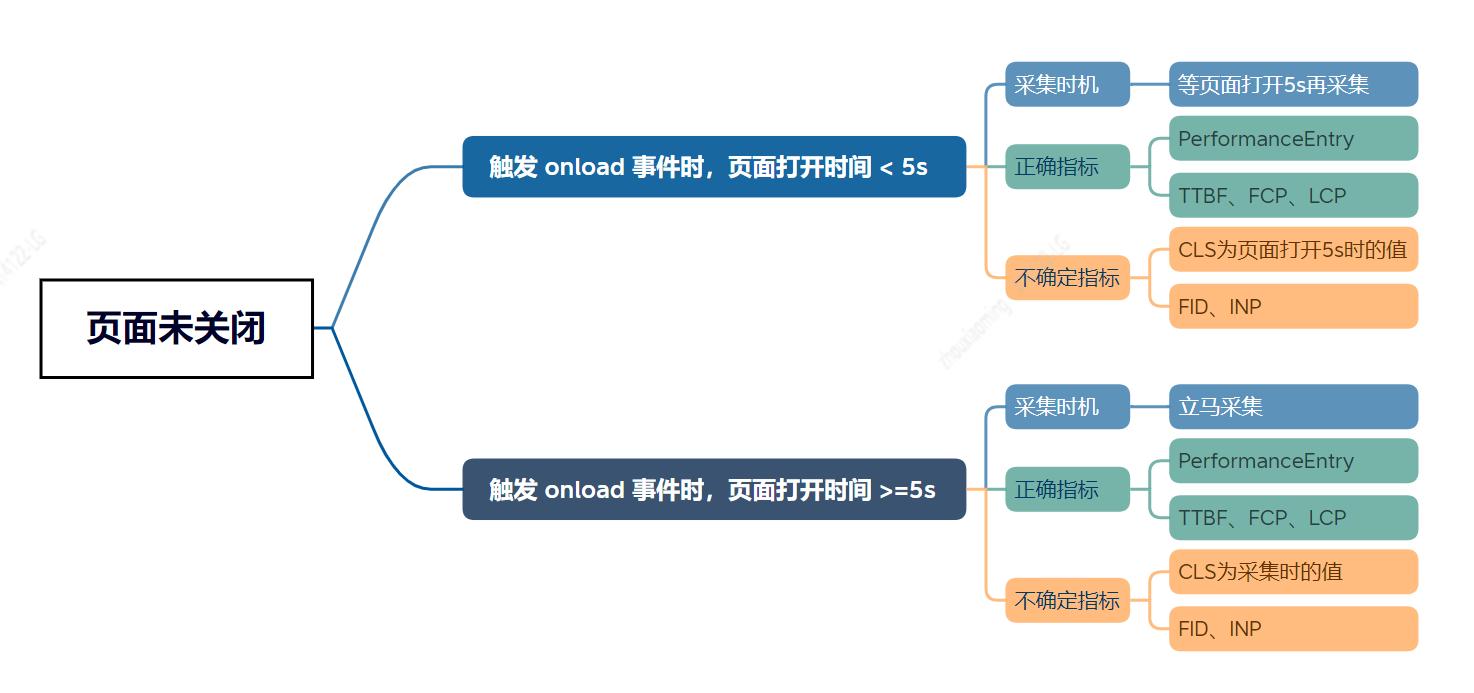
为了避免采集指标影响页面性能,我们异步加载 RUM JS SDK,web-vitals 中各指标默认仅支持异步回调,异步加载再异步回调,导致采集时机时仍可能无法拿到各指标值,所以我们对 web-vitals 源码做了改造,支持同步获取各指标值。
上报方式
采集到指标后,需要选择恰当上报方式,将指标可靠的发送到后端。上报方式包含两个部分:上报机制和上报时机。
选择合适的上报机制,首先,要满足功能需求,浏览器兼容度高,对数据大小最好没限制;其次,能感知上报请求异常,便于上报重试,进而提高上报可靠性;最后,客户端支持设置超时时间,避免长时间占用忘了连接,加大后端服务压力。常见上报机制有四种,分别是:Image、XMLHttpRequest、sendBeacon、Fetch API。其特点如下:
Image | XMLHttpRequest | sendBeacon | Fetch | |
基本原理 | 创建一个 1 像素、隐藏的 img DOM,将上报地址和上报内容包含在 img 的 src 中。上报成功则返回 200 状态码 | 利用浏览器内置对象 XMLHttpRequest 上报数据 | 使用专门设计用于发送分析数据的 navigator.sendBeacon()方法,以异步发送 HTTP POST 请求的方式将分析数据提交到后端 | fetch 是一个现代的、基于 Promise 的用于发送 HTTP 请求的 API |
浏览器兼容性 | 高 | 高 | 中,不支持 IE | 中偏低,不支持 IE |
数据大小限制 | 小于 8K 各浏览器大小限制不一,且受制于 CDN、后端代理和 web 服务器,默认值常为 8K。8K 指用 URI 编码后的长度 | 用 POST 请求,无限制 | 有,部分浏览器小于 64K | 用 POST 请求,无限制 |
感知上报异常 | 部分支持。 请求返回状态码为 404 或 204 时会触发 img onerror 事件。状态码大于等于 400,不会触发 onerror 事件,如 400、500、502 和 504 等。 | 支持 | 不支持。 sendBeacon()返回值,只能表示浏览器是否发出请求 | 支持 |
可设置超时 | 不可以,依赖服务端的设置 | 可以 | 不可以 | 可以 |
优点 | 使用简单、兼容度高 | 功能强大,灵活易扩展 无大小限制,兼容度高 | 使用简单,可靠性高 页面关闭时,仍可发送 | 相比于 XMLHttpRequest,使用更简介、功能更强大 |
缺点 | 数据大小有限制,难感知上报异常 | 代码编写略复杂 跨域处理要留意 | 无法感知上报异常,函数返回值 true、false 只能代表是否发送成功 | 同 XMLHttpRequest 浏览器兼容度最低 |
适用场景 | 上报数据小,可靠性要求不高 | 功能需求多 建议以 POST 方式用 text/plain 或 application/x-www-form-urlencoded 格式上报,CORS 预验证 | 需要在页面关闭时,上报数据 | 同 XMLHttpRequest,更适用于浏览器分布较新的终端 |
上述结论:依赖于 chrome114
相比于 Fetch,XMLHttpRequest 功能几乎一致,兼容性更高;与 Image 对比,XMLHttpRequest 具有兼容度高、数据大小没限制、能感知异常和可设置超时时间等优势;XMLHttpRequest 是页面正常(未关闭)情况下,发送指标数据的首选上报机制。至于 sendBeacon,虽然存在诸多不足,但是页面关闭时仍可以上报数据,成功率还较高,适合作为在页面关闭时,发送尚未发送的指标数据的上报机制。
既然选择了 sendBeacon 作为页面关闭时发送指标数据的上报机制,那该如何判断页面被关闭?传统方案是监听 unload 或 beforeunload 事件,该方案存在两个不足:
- 不能满足功能需求。手机端用户离开页面时,更习惯将浏览器隐藏,而不是关闭浏览器。隐藏页面时,不会触发 unload 和 beforeunload 事件。
- 性能有损耗。部分浏览器,监听到 unload 或 beforeunload 事件后,无法使用 bfcache,导致页面性能降低。
更合适、更现代的方案是监听 pagehide 或 visibilitychange===hiden 事件,该方案除了避免传统方案存在的两不足,兼容度也会更高。对于 SPA 项目我们不采集非首页性能指标,触发History.replaceState()方法也算离开页面。
综上所述,整体上报机制为:1)页面正常(未关闭),到采集时机时,SDK 采集性能指标数据,使用 XMLHttpRequest 机制上报;2)通过监听 pagehide 或 visibilitychange===hiden 事件,当页面被关闭时,如果满足任一采集时机条件,则立即采集指标,使用 sendBeacon 机制上报。
整体方案
综上所述,我们整理 RUM 实施大纲如下:
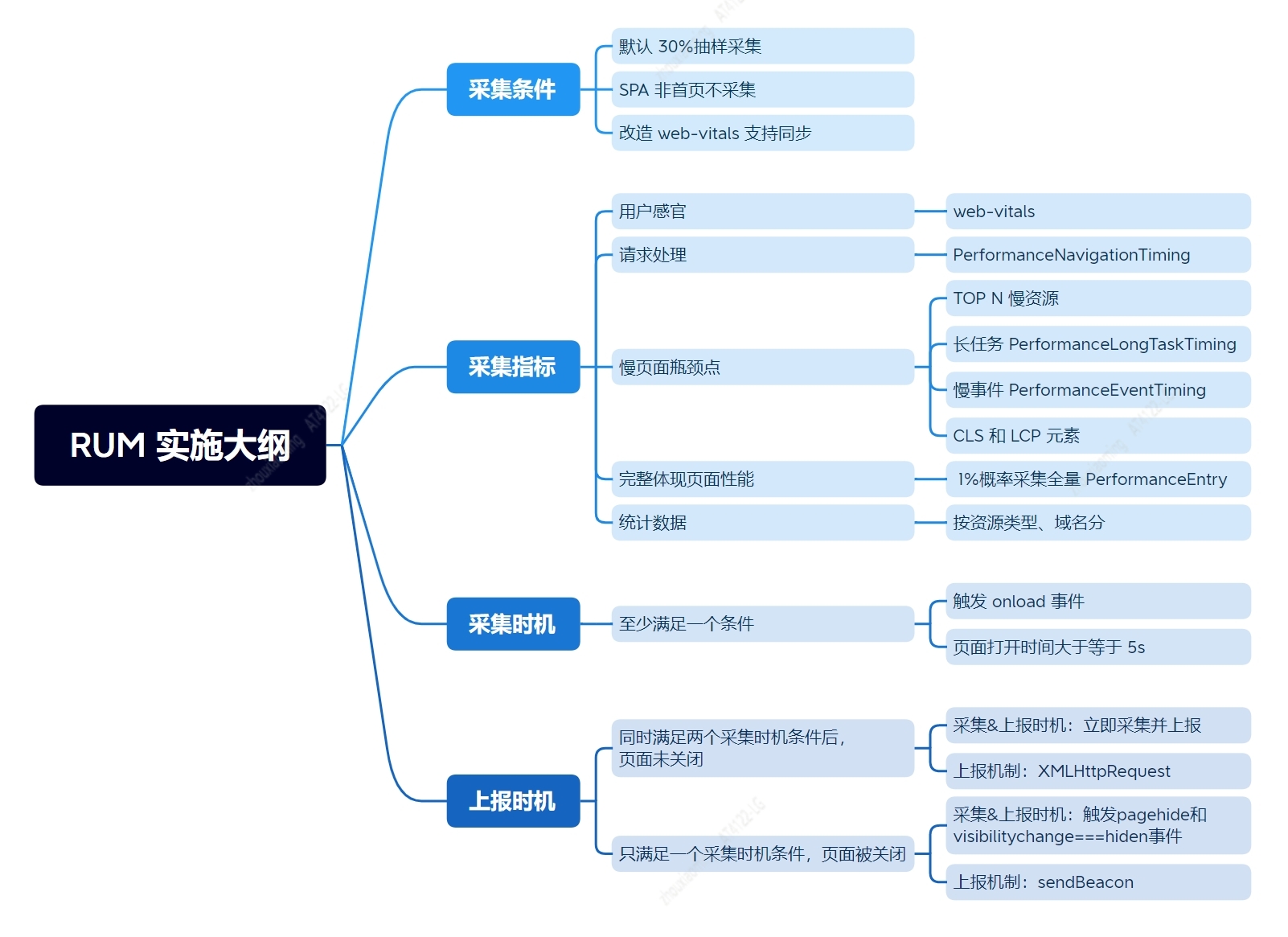
实际编码过程中,具体处理流程如下:
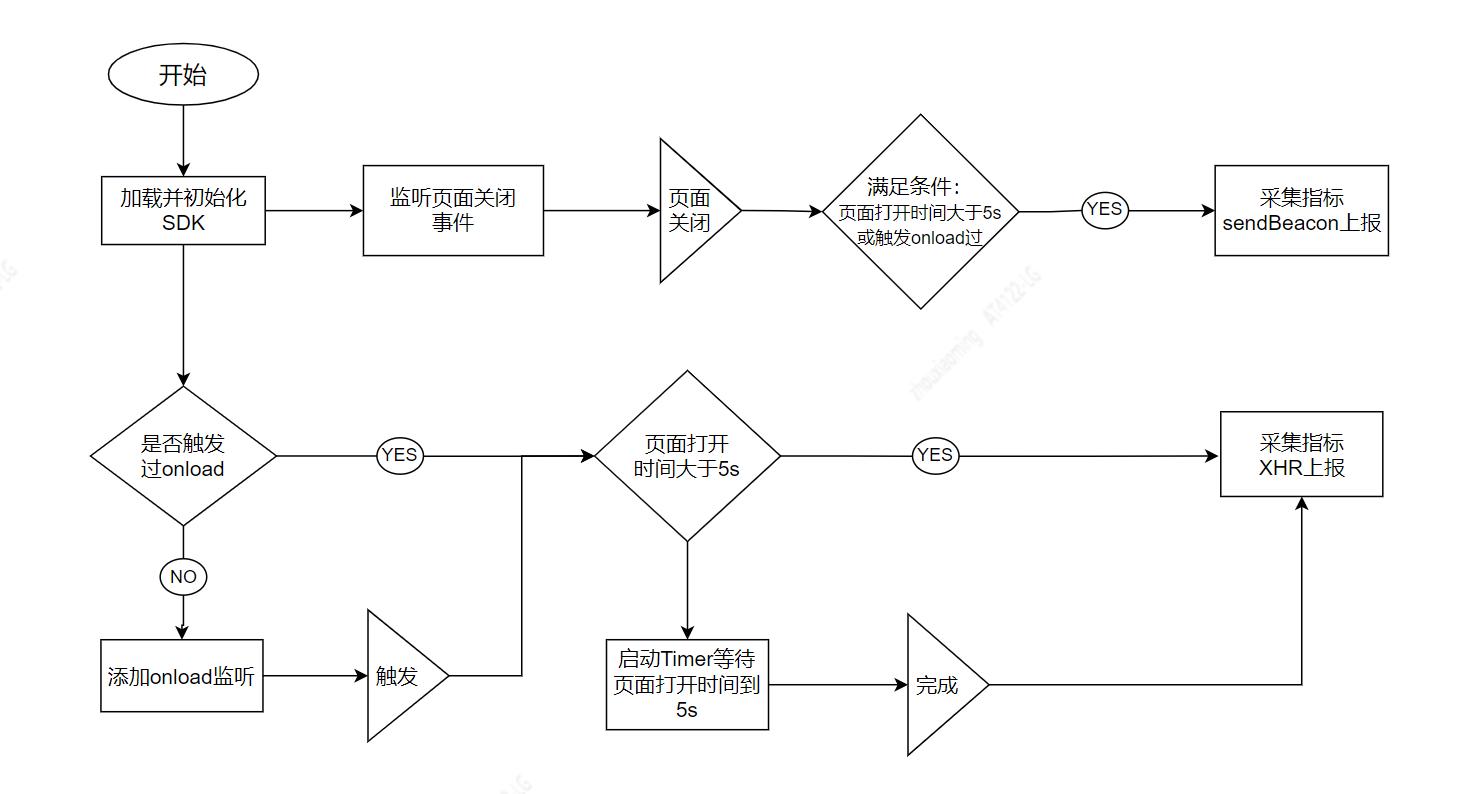
优缺点
在实施过程中,我们总结 RUM 优缺点如下:
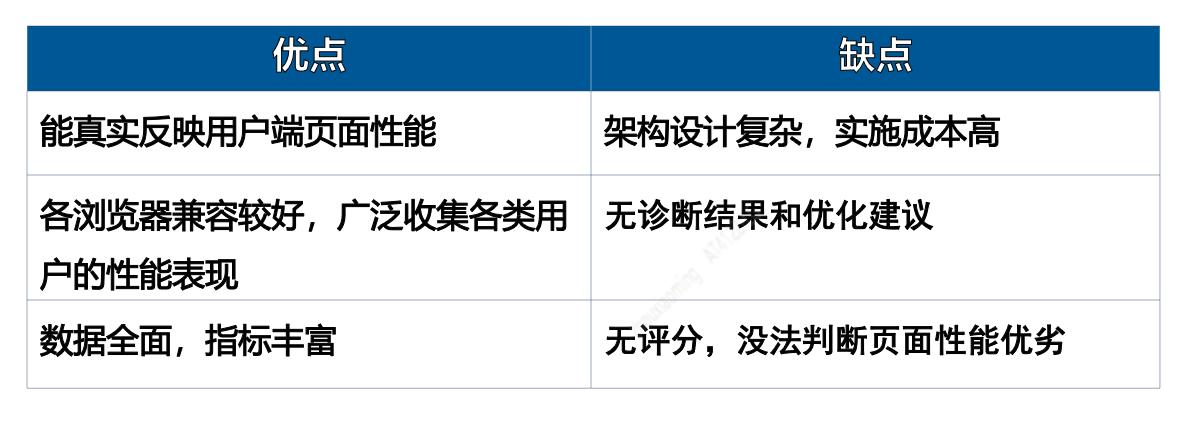
RUM 架构设计复杂,实施成本较高,由于是技术刚需,只能投入资源,努力做好。
针对 无诊断结果和优化建议 的缺点,可以结合 SYN,取长补短,利用 SYN 诊断慢页面性能瓶颈点分布。
对于 无评分,没法判断页面性能优劣 的问题,我们分三步走:首先,制定慢页面标准,判断单次页面是否快慢,标准值前文已有描述;其次,统计该页面各重要指标的 AVG、TP50、TP90、TP99 值,全面评估页面所有请求的性能分布;最后,我们会对页面所在的应用进行评分,直接告诉研发同学,该应用性能优劣,应用评分具体做法,会在下面《建立评分体系》章节细讲。
三、整体架构设计
前文深入分析了 SYN 和 RUM 各自特点、使用方法及优缺点等,我们发现 SYN 和 RUM 各有所长、无法替代,最好同时引用 SYN 和 RUM,构建体系化性能监控架构,提供性能监控和性能分析工具链,支持产研同学在 devpos 各阶段中发现和定位页面性能问题。
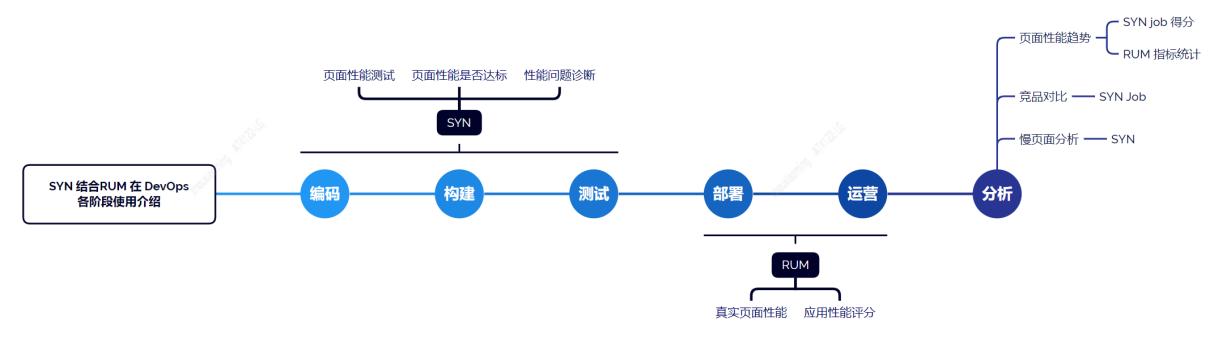
在编码、构建和测试阶段,研发同学可以利用 SYN 来做页面性能测试,判断页面性能是否达标?如果页面性能有问题,再利用 SYN 诊断性能问题,获得优化建议。此举解决前端页面长期以来,前端页面做性能测试难、交付页面质量无标准等痛点。应用部署后,再利用 RUM 采集真实用户页面性能,评估真实页面性能,如果还存在慢页面,仍可以使用 SYN 定位慢页面性能瓶颈点,并利用诊断结果和优化建议,提高优化效率。除此之外,SYN 还可以用来做竞品对比,达到知己知彼、快竞争对手一步的目的。
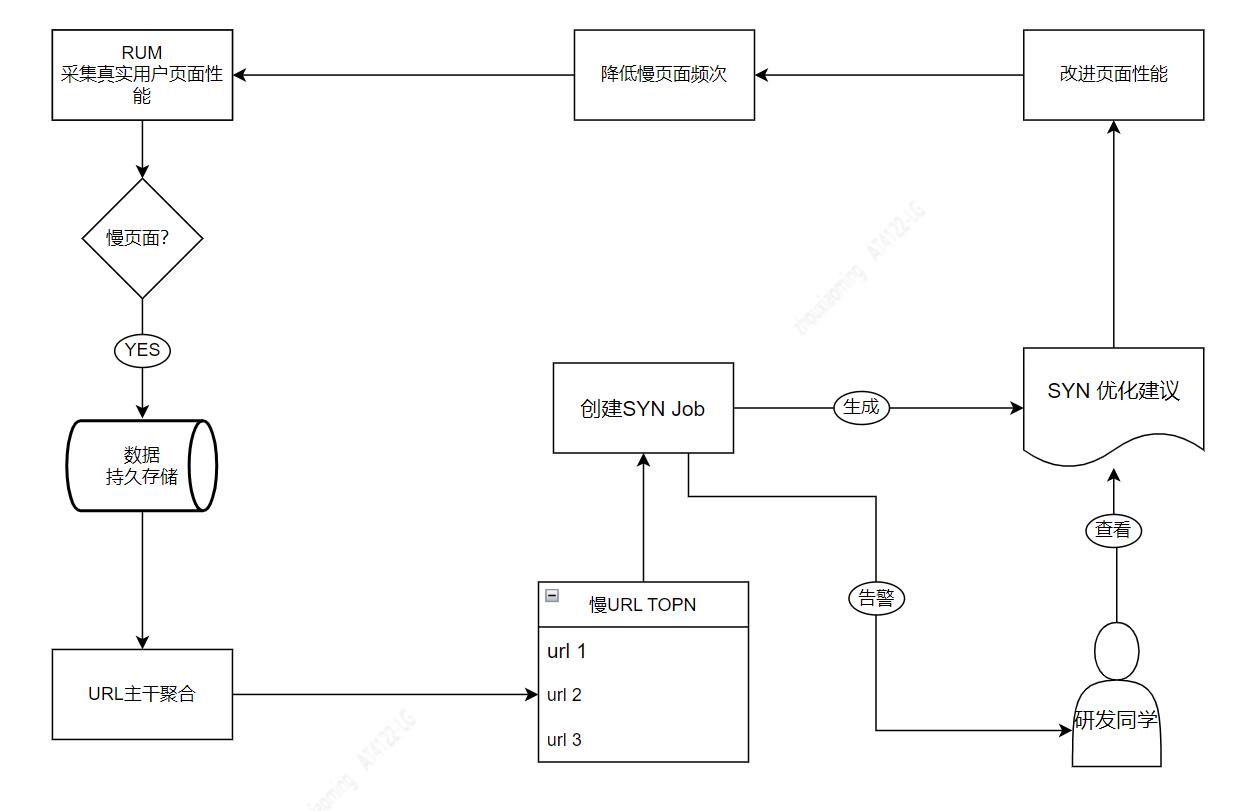
有了 SYN 和 RUM,我们可以构建在线持续优化慢页面的闭环,如上图。RUM 负责采集真实用户产生的慢页面,经后台存储、聚合,自动将 TOPN 的慢页面创建 SYN JOB,待 JOB 运行完毕,将诊断结果和优化建议以告警防止通知研发同学,研发同学利用 SYN 优化建议,再利用 devtools、webpack 等工具,改进页面,交付高质量页面,降低慢页面的频次。如此循环迭代,持续优化应用页面性能,最终应用能达到极致性能。
三、建立评判体系
引入 SYN,自研 RUM SDK,采集到众多 SYN 和 RUM 指标数据后,我们将着手建立评判体系,评估各应用、团队、部门,乃至整个公司的性能情况,输出少数几个关键指标和评分,直观告诉各层级、各角色员工其所在组织及同级组织的页面性能情况,通过得分和同级对比,评判是否要优化页面性能?
建立评判体系时我们秉持着:既要突出重点、关键指标,同时还能全面、综合、客观真实地反映页面性能 的原则。所以我们将评判体系分为两大块,其一,展示最关键的性能指标。其二,输出各指标、应用、团队、部门及公司层级的性能评分和层级。
展示最关键的性能指标
我们从 web-vitals 和 performanceNavigationTiming 中各选一个最能代表页面性能的指标,分别为:DCL 和 LCP。LCP 兼容度不高且可能被伪造,DCL 既能代替 LCP 部分反映首屏性能且兼容度高、难以伪造,和 LCP 相辅相成,最能体现页面性能。

TP90 代表 90%用户的体验下限,与 AVG、TP50、TP75 比,覆盖和统计更广的用户,还能屏蔽页面在手机端特殊网络环境下,产生的少数脏数据,更具有代表性。
输出各级评分
应用性能评分
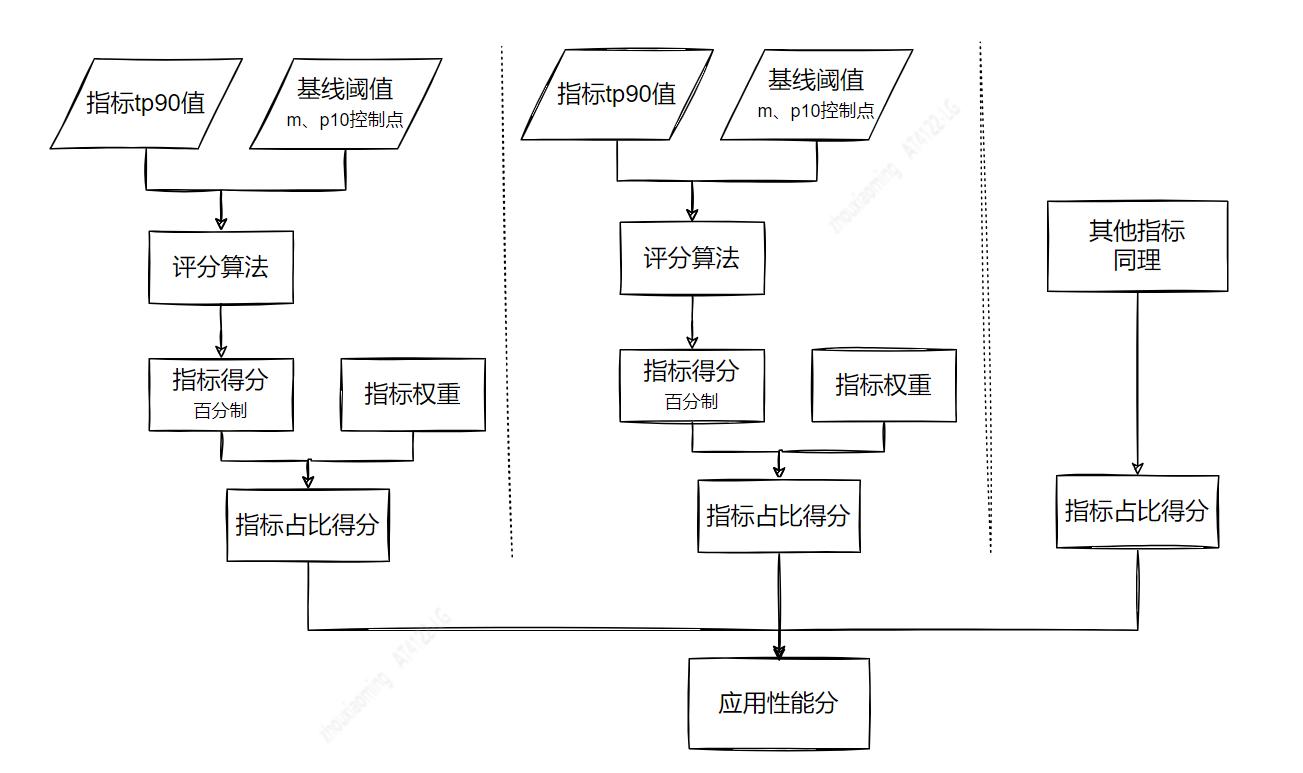
为了全面、综合和客观的评估应用页面性能。我们将选择各维度具有代表性指标,参考 HTTP Archive 给予的业内指标分布,根据应用特性,如应用类型( PC 或 M 端 )、终端用户( C 端用户、B 端客户和内部员工),设立不同的评分基线,算出各指标得分。再根据各指标重要程度设置权重,通过加权平均算法,求得应用性能评分。流程如下:
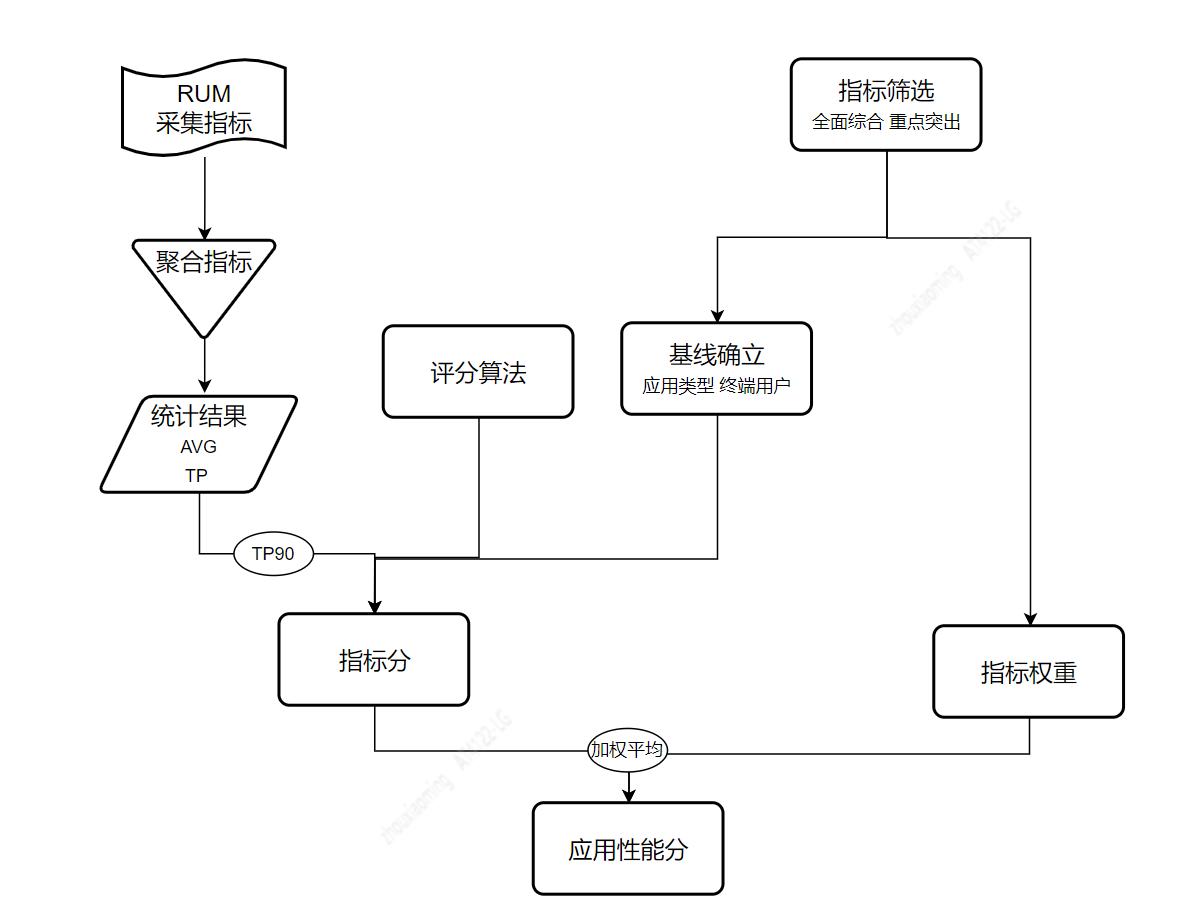
获取应用性能分过程中涉及几个重要流程:1) 指标筛选及权重设置;2) 选择评分算法;3) 确立指标基线;4) 使用加权平均算法计算应用性能分。下面逐一介绍。
指标筛选及权重设立
此过程中,我主要考虑两点:
全面综合考虑。页面性能涵盖多方面,传统上只用首字节、白屏、首屏时间等少数指标来衡量,较为片面,不够客观。我们认为评判页面性能应该涵盖各维度指标,如:页面加载、交互体验和视觉体验。此外我们还引入慢 API 比例的概念,API 请求比例指页面打开后 API 耗时超过 3s 的请求比例,慢 API,即可能影响首屏加载耗时,也会影响交互过程中的用户体验。为了让研发同学关注慢页面、将在线 SYN 作为日常开发性能评估工具,我们将 SYN 评分也作为权重指标,后台系统每天会统计访问次数 TOP10 的慢页面并自动创建 SYN 定时任务,待任务执行、分析完毕后,将优化建议和诊断结果通知研发同学。SYN 评分项,包含性能分和最佳实践分,两者都是百分制。
突出重点。提高重要指标的权重比。如:加载指标用于衡量页面能不能用,最为关键,所以赋予权重占比最大。LCP 是最重要的加载指标,权重占比也相应提高。由于 LCP 本身不一定完全合理且可能被伪造,所以评判页面加载性能时,还引入 DCL、FCP、TTFB、WindwLoad 和 PageLoad 等加载指标。该做法,优点:指标多,维度广、角度大、更全面和更客观准确;缺点:增加评判系统复杂度和难度。
基于上述两点考虑,我们指标筛选结果和权重占比设置,如下图:
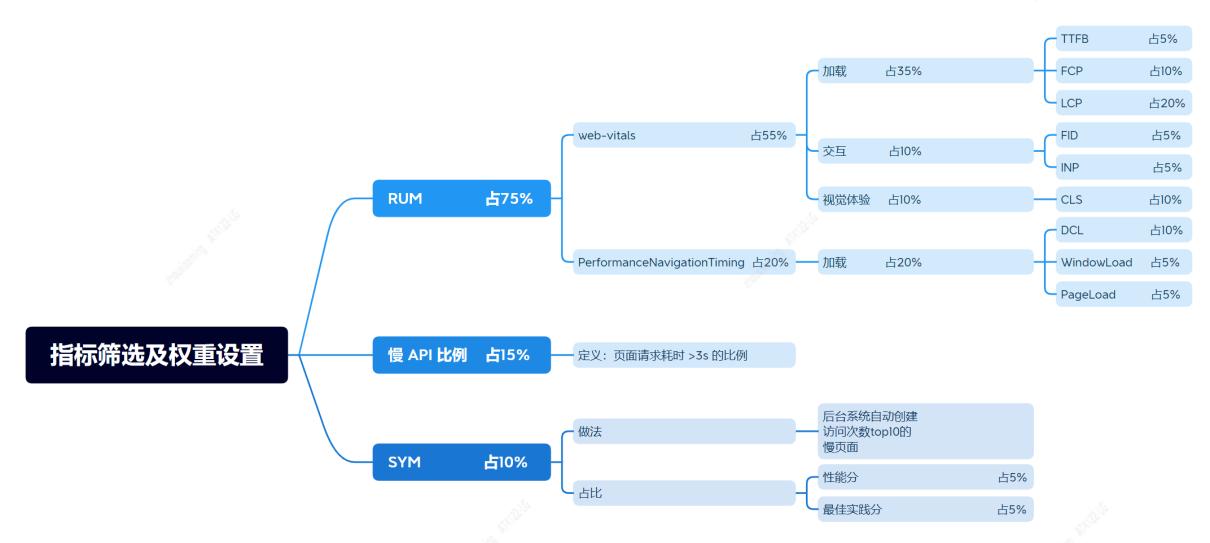
各指标以其 TP90 统计值,参与评分运算。
选择评分算法
评分算法主要参考 Lighthouse 评分曲线模型,基本原理是:设置两个控制点,通常是 TP50 和 TP90,即得 50 或 90 分时的指标值点,然后根据这两个控制点,生成对数正态曲线,通过该曲线可以获得任一指标值对应的得分。下图是 M 端 LCP 的评分曲线:
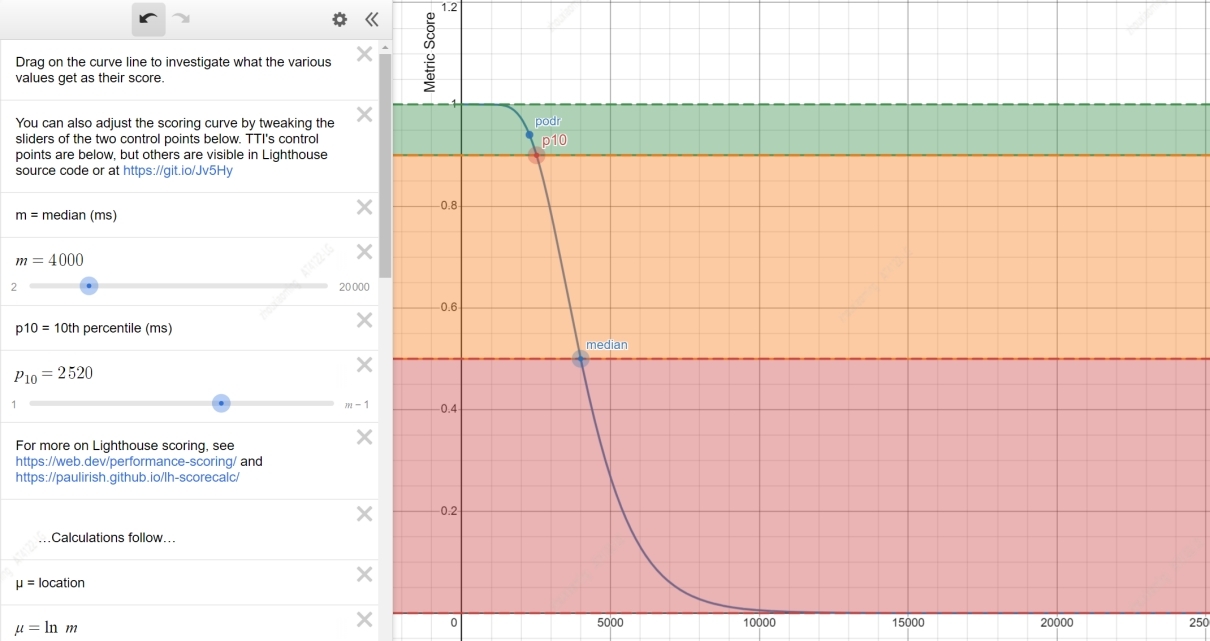
m 表示中位数,图中 m 值为 4000ms,表示当 LCP 值为 4000ms 时,得 50 分;同理 p10 为 2520ms,LCP 值为 2529ms 时,得 90 分。设置 m 和 p10 后,会生成右边的评分曲线模型,根据该模型可以获得 LCP 值从 0 到正无穷时的得分。
确立指标基线
确立指标基线是为了给评分算法提供两个控制点,即 m 和 p10 的值。确立方法有三种:
- 直接借用 Lighthouse 配置。以 Lighthouse 对应指标的 50 分和 90 分阈值为 m 和 p10 控制点值,如 web-vitals 中各指标。
- 参考 HTTP Archive 统计数据,以统计数据中的 p10、p75 值为 m 和 p10 控制点值。如 performanceNavigationTiming 各指标。
- 自建基线。少数指标基线无法从上述两种方法确立,只能自建基线。具体做法:以当前后台系统拿到的数据为样本,以样本的 tp75 和 tp95 值为 m 和 p10 控制点值。适用于慢 api 比例指标。
确立基线过程中,应考虑应用价值和研发要求的不同,根据应用特性,有针对性的设置。首先,PC 端和 M 端类型的应用,要设置不同的指标基线,所幸 Lighthouse 和 HTTP Archive 都提供 PC 端和 M 端的配置参考;其次,根据应用实际终端用户类型,有针对性的调整阈值。C 端和 B 端应用,直接产生业务价值,性能要求要比内部应用高,两控制点值应该更低。
使用加权平均算法计算应用性能分
根据指标 tp90 值、指标基线和评分算法,求得该指标的百分制得分。
使用加权平均算法求应用性能分,结果 = (Σ (指标tp90值 × 指标权重)) / (Σ 权重) ,其中:Σ 表示求和。
各级组织评分
至于求各级组织,含团队、部门及公司的性能分,则根据其管辖的应用个数、应用性能分及应用权重,仍使用加权平均算法获取组织分。流程如下:
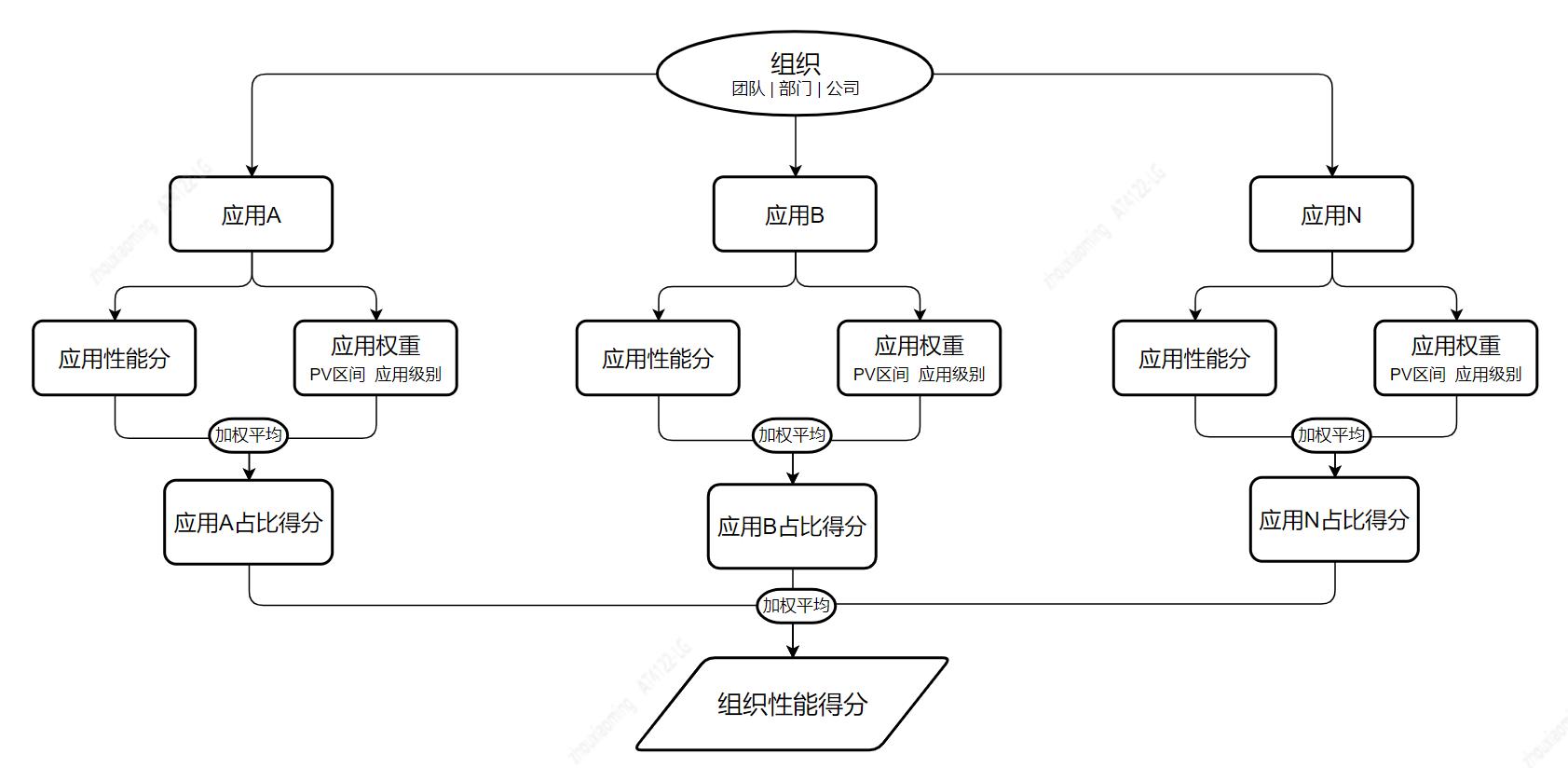
求组织性能分的难点是:如何设置应用权重?我们主要参考应用的 PV 区间和应用级别。PV 层级越大、应用级别越高,权重越大。具体配置参考如下:
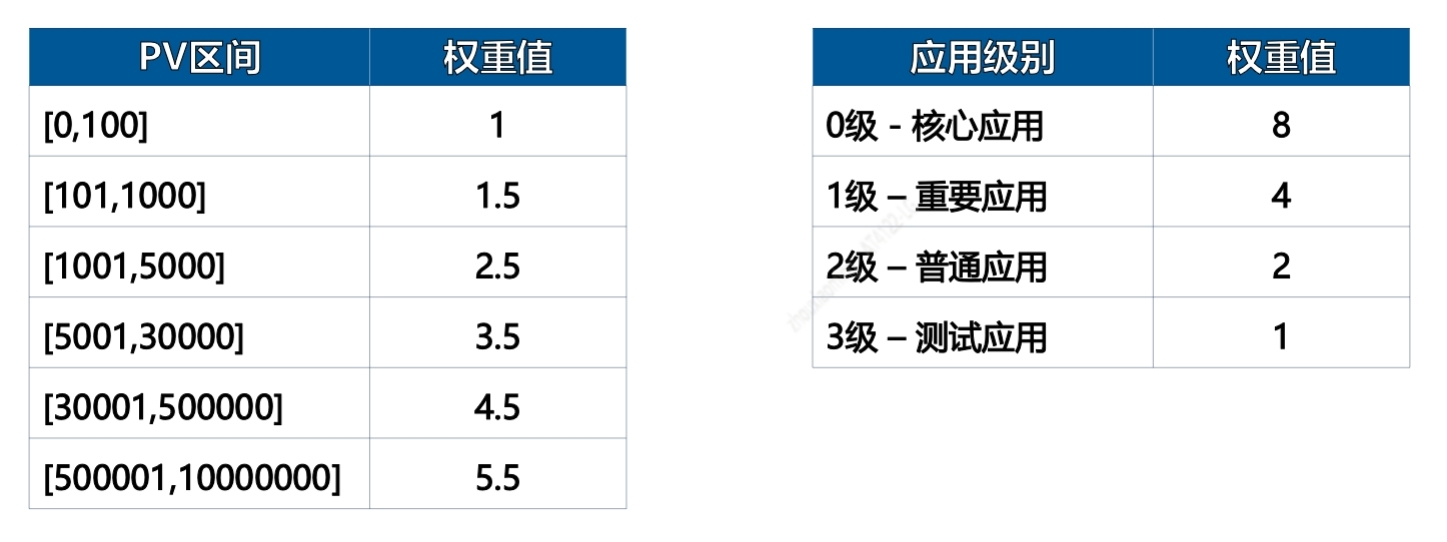
PV区间中的PV 值指采用 PV,而非真实 PV,采用 PV=采集到 RUM 数据量/抽样比例。
经过上述步骤,我们能获得应用性能分,以及各级组织的性能分,如团队性能分、部门性能分及之家性能分,展示效果如下:
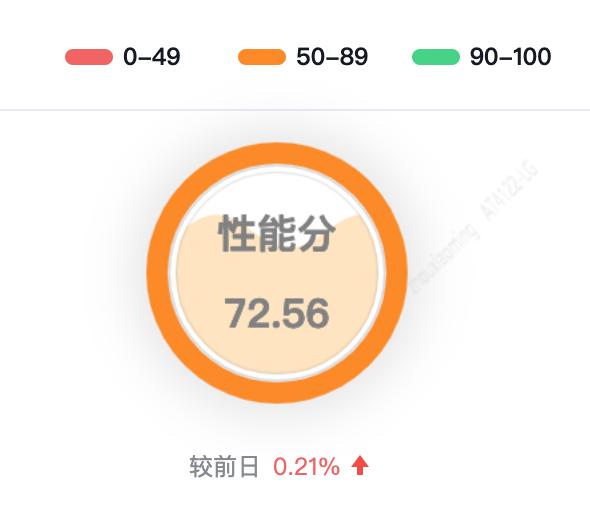
性能分参考lighthouse标准,50分以上算合格,90分以上才算优秀。
四、总结
通过页面性能监控和评判体系建设,我们既有原始页面性能数据,又有聚合统计值,还有最终评分。通过评分、统计和原始数据,打通了发现、定位和分析性能问题的链路。研发同学可以通过评分直观判断应用性能优劣是否需要优化?如果需要优化,再通过聚合统计数据,分析应用瓶颈点;定位具体瓶颈点时,可以查看明细数据,辅助分析产生瓶颈点的具体原因;改进后可以通过通过统计查看优化效果,最终反映到提高评分上。
受限于篇幅,本文仅能介绍页面性能监控和评判体系建设相关的实践。一个完整的页面性能监控系统,还应该包含:监控、报警、优化、治理等模块,不仅仅只是指标,能度量页面性能,发现其中性能瓶颈点,帮助研发同学提升优化效率,还要治本,通过构建一系列前端工具链,改进交付过程,通过规范、工具和流程,从源头上提高页面交付质量,避免将问题带到线上,先于用户发现性能问题。
五、参考文献
Web Vital Metrics for Single Page Applications
一个收集和分析网站性能数据的项目,旨在帮助 Web 开发者了解互联网的技术趋势以及性能优化的最佳实践。


























