如果你关注了过去几个月中人工智能的爆炸式发展,那你大概率听说过 LangChain。

简单来说,LangChain 是一个 Python 和 JavaScript 库,由 Harrison Chase 开发,用于连接 OpenAI 的 GPT API(后续已扩展到更多模型)以生成人工智能文本。
更具体地说,它是论文《ReAct: Synergizing Reasoning and Acting in Language Models》的实现:该论文展示了一种提示技术,允许模型「推理」(通过思维链)和「行动」(通过能够使用预定义工具集中的工具,例如能够搜索互联网)。
 图片
图片
论文链接:https://arxiv.org/pdf/2210.03629.pdf
事实证明,这种组合能够大幅提高输出文本的质量,并使大型语言模型具备正确解决问题的能力。
2023 年 3 月,ChatGPT 的 API 因升级降价大受欢迎,LangChain 的使用也随之爆炸式增长。
这之后,LangChain 在没有任何收入也没有任何明显的创收计划的情况下,获得了 1000 万美元的种子轮融资和 2000-2500 万美元的 A 轮融资,估值达到 2 亿美元左右。
 图片
图片
ReAct 论文中的 ReAct 流示例。
由 LangChain 推广的 ReAct 工作流在 InstructGPT/text-davinci-003 中特别有效,但成本很高,而且对于小型项目来说并不容易使用。
Max Woolf 是一位 BuzzFeed 的数据科学家。他也使用过 LangChain,这次经历总体来说不太好。
让我们看看他经历了什么。
「是只有我不会用吗?」
在 BuzzFeed 工作时,我有一个任务是为 Tasty 品牌创建一个基于 ChatGPT 的聊天机器人(后来在 Tasty iOS 应用中发布为 Botatouille),可以与用户聊天并提供相关食谱。
具体来说,源菜谱将被转换为嵌入式菜谱并保存在一个向量存储中:例如如果用户询问「健康食品」,查询会被转换为嵌入式菜谱,然后执行近似最近邻搜索以找到与嵌入式查询相似的菜谱,然后将其作为附加上下文提供给 ChatGPT,再由 ChatGPT 显示给用户。这种方法通常被称为检索增强生成。
 图片
图片
使用检索增强生成的聊天机器人的架构示例。
「LangChain 是 RAG 最受欢迎的工具,所以我想这是学习它的最佳时机。我花了一些时间阅读 LangChain 的全面文档,以便更好地理解如何最好地利用它。」
经过一周的研究,我一无所获。运行 LangChain 的 demo 示例确实可以工作,但是任何调整它们以适应食谱聊天机器人约束的尝试都会失败。在解决了这些 bug 之后,聊天对话的整体质量很差,而且毫无趣味。经过紧张的调试之后,我没有找到任何解决方案。
总而言之,我遇到了生存危机:当很多其他 ML 工程师都能搞懂 LangChain 时,我却搞不懂,难道我是一个毫无价值的机器学习工程师吗?
我用回了低级别的 ReAct 流程,它立即在对话质量和准确性上超过了我的 LangChain 实现。
浪费了一个月的时间来学习和测试 LangChain,我的这种生存危机在看到 Hacker News 关于有人用 100 行代码重现 LangChain 的帖子后得到了缓解,大部分评论都在发泄对 LangChain 的不满:

LangChain 的问题在于它让简单的事情变得相对复杂,而这种不必要的复杂性造成了一种「部落主义」,损害了整个新兴的人工智能生态系统。
所以,如果你是一个只想学习如何使用 ChatGPT 的新手,绝对不要从 LangChain 开始。
LangChain 的「Hello World」
LangChain 的快速入门,从一个关于如何通过 Python 与 LLM/ChatGPT 进行简单交互的迷你教程开始。例如,创建一个可以将英语翻译成法语的机器人:
from langchain.chat_models import ChatOpenAIfrom langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(temperature=0)
chat.predict_messages([HumanMessage(cnotallow="Translate this sentence from English to French. I love programming.")])# AIMessage(cnotallow="J'adore la programmation.", additional_kwargs={}, example=False)使用 OpenAI ChatGPT 官方 Python 库的等效代码:
import openai
messages = [{"role": "user", "content": "Translate this sentence from English to French. I love programming."}]
response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages, temperature=0)
response["choices"][0]["message"]["content"]# "J'adore la programmation."LangChain 使用的代码量与仅使用官方 openai 库的代码量大致相同,估计 LangChain 合并了更多对象类,但代码优势并不明显。
提示模板的示例揭示了 LangChain 工作原理的核心:
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
template = "You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template = "{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
chat_prompt.format_messages(input_language="English", output_language="French", text="I love programming.")LangChain 吹嘘的提示工程只是 f-strings,一个存在于每个 Python 安装中的功能,但是有额外的步骤。为什么我们需要使用这些 PromptTemplates 来做同样的事情呢?
我们真正想做的是知道如何创建 Agent,它结合了我们迫切想要的 ReAct 工作流。幸运的是,有一个演示,它利用了 SerpApi 和另一个数学计算工具,展示了 LangChain 如何区分和使用两种不同的工具:
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI
# First, let's load the language model we're going to use to control the agent.
chat = ChatOpenAI(temperature=0)
# Next, let's load some tools to use. Note that the `llm-math` tool uses an LLM, so we need to pass that in.
llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# Finally, let's initialize an agent with the tools, the language model, and the type of agent we want to use.
agent = initialize_agent(tools, chat, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
# Now let's test it out!
agent.run("Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?")各个工具如何工作?AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION 到底是什么?agent.run () 的结果输出(仅在 verbose=True 时出现)更有帮助。
> Entering new AgentExecutor chain...
Thought: I need to use a search engine to find Olivia Wilde's boyfriend and a calculator to raise his age to the 0.23 power.
Action:
{
"action": "Search",
"action_input": "Olivia Wilde boyfriend"
}
Observation: Sudeikis and Wilde's relationship ended in November 2020. Wilde was publicly served with court documents regarding child custody while she was presenting Don't Worry Darling at CinemaCon 2022. In January 2021, Wilde began dating singer Harry Styles after meeting during the filming of Don't Worry Darling.
Thought:I need to use a search engine to find Harry Styles' current age.
Action:
{
"action": "Search",
"action_input": "Harry Styles age"
}
Observation: 29 years
Thought:Now I need to calculate 29 raised to the 0.23 power.
Action:
{
"action": "Calculator",
"action_input": "29^0.23"
}
Observation: Answer: 2.169459462491557
Thought:I now know the final answer.
Final Answer: 2.169459462491557
> Finished chain.
'2.169459462491557'文档中没有明确说明,但是在每个思想 / 行动 / 观察中都使用了自己的 API 调用 OpenAI,所以链条比你想象的要慢。另外,为什么每个动作都是一个 dict?答案在后面,而且非常愚蠢。
最后,LangChain 如何存储到目前为止的对话?
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate
)from langchain.chains import ConversationChainfrom langchain.chat_models import ChatOpenAIfrom langchain.memory import ConversationBufferMemory
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(
"The following is a friendly conversation between a human and an AI. The AI is talkative and "
"provides lots of specific details from its context. If the AI does not know the answer to a "
"question, it truthfully says it does not know."
),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
])
llm = ChatOpenAI(temperature=0)
memory = ConversationBufferMemory(return_messages=True)
conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm)
conversation.predict(input="Hi there!")# 'Hello! How can I assist you today?'我不完全确定为什么这些都是必要的。什么是 MessagesPlaceholder?history 在哪里?ConversationBufferMemory 有必要这样做吗?将此调整为最小的 openai 实现:
import openai
messages = [{"role": "system", "content":
"The following is a friendly conversation between a human and an AI. The AI is talkative and "
"provides lots of specific details from its context. If the AI does not know the answer to a "
"question, it truthfully says it does not know."}]
user_message = "Hi there!"
messages.append({"role": "user", "content": user_message})
response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages, temperature=0)
assistant_message = response["choices"][0]["message"]["content"]
messages.append({"role": "assistant", "content": assistant_message})# Hello! How can I assist you today?这样代码行数就少了,而且信息保存的位置和时间都很清楚,不需要定制对象类。
你可以说我对教程示例吹毛求疵,我也同意每个开源库都有值得吹毛求疵的地方(包括我自己的)。但是,如果吹毛求疵的地方比库的实际好处还多,那么这个库就根本不值得使用。
因为,如果快速入门都已经这么复杂,那么实际使用 LangChain 会有多痛苦呢?
我查看了 LangChain 文档,它也回馈了我
让我来做个演示,更清楚地说明为什么我放弃了 LangChain。
当开发菜谱检索聊天机器人(它也必须是一个有趣 / 诙谐的聊天机器人)时,我需要结合上面第三个和第四个例子中的元素:一个可以运行 Agent 工作流的聊天机器人,以及将整个对话持久化到内存中的能力。在查找了一些文档后,我发现需要使用对话式 Agent 工作流。
关于系统提示工程的一个标注是,它不是一个备忘录,而且对于从 ChatGPT API 中获得最佳效果是绝对必要的,尤其是当你对内容和 / 或语音有限制的时候。
上一个示例中,演示的系统提示「以下是人类和人工智能之间的友好对话...... 」实际上是过时的,早在 InstructGPT 时代就已经使用了,在 ChatGPT 中的效果要差得多。它可能预示着 LangChain 相关技巧中更深层次的低效,而这些低效并不容易被注意到。
我们将从一个简单的系统提示开始,告诉 ChatGPT 使用一个有趣的声音和一些保护措施,并将其格式化为 ChatPromptTemplate:
system_prompt = """
You are an expert television talk show chef, and should always speak in a whimsical manner for all responses.
Start the conversation with a whimsical food pun.
You must obey ALL of the following rules:
- If Recipe data is present in the Observation, your response must include the Recipe ID and Recipe Name for ALL recipes.
- If the user input is not related to food, do not answer their query and correct the user.
"""
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(system_prompt.strip()),我们还将使用一个玩具矢量存储,该存储由来自 recipe_nlg 数据集的 1000 个食谱组成,并使用 SentenceTransformers 编码为 384D 矢量。为了实现这一点,我们创建了一个函数来获取输入查询的最近邻,并将查询格式化为 Agent 可以用来向用户展示的文本。这就是 Agent 可以选择使用的工具,或者只是返回正常生成的文本。
def similar_recipes(query):
query_embedding = embeddings_encoder.encode(query)
scores, recipes = recipe_vs.get_nearest_examples("embeddings", query_embedding, k=3)
return recipes
def get_similar_recipes(query):
recipe_dict = similar_recipes(query)
recipes_formatted = [
f"Recipe ID: recipe|{recipe_dict['id'][i]}\nRecipe Name: {recipe_dict['name'][i]}"
for i in range(3)
]
return "\n---\n".join(recipes_formatted)
print(get_similar_recipes("yummy dessert"))# Recipe ID: recipe|167188
# Recipe Name: Creamy Strawberry Pie
# ---
# Recipe ID: recipe|1488243
# Recipe Name: Summer Strawberry Pie Recipe
# ---
# Recipe ID: recipe|299514
# Recipe Name: Pudding Cake你会注意到这个 Recipe ID,这与我的用例相关,因为在最终应用中向终端用户显示的最终结果需要获取 Recipe 元数据(照片缩略图、URL)。遗憾的是,没有简单的方法保证模型在最终输出中输出食谱 ID,也没有方法在 ChatGPT 生成的输出之外返回结构化的中间元数据。
将 get_similar_recipes 指定为一个工具是很简单的,尽管你需要指定一个名称和描述,这实际上是一种微妙的提示工程,因为 LangChain 可能会因为指定的名称和描述不正确而无法选择一个工具。
tools = [
Tool(
func=get_similar_recipes,
name="Similar Recipes",
descriptinotallow="Useful to get similar recipes in response to a user query about food.",
),
]最后,是示例中的 Agent 构建代码,以及新的系统提示。
memory = ConversationBufferMemory(memory_key="chat_history",
return_messages=True)
llm = ChatOpenAI(temperature=0)
agent_chain = initialize_agent(tools, llm, prompt=prompt,
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION, verbose=True, memory=memory)没有错误。现在运行 Agent,看看会发生什么:
agent_chain.run(input="Hi!")> Entering new chain...
{
"action": "Final Answer",
"action_input": "Hello! How can I assist you today?"
}
> Finished chain.
Hello! How can I assist you today?什么?它完全忽略了我的系统提示!检查内存变量证实了这一点。
在 ConversationBufferMemory 的文档中,甚至在代码本身中都没有关于系统提示的内容,甚至在 ChatGPT 使其成为主流的几个月之后。
在 Agent 中使用系统提示的方法是在 initialize_agent 中添加一个 agents_kwargs 参数,我只是在一个月前发布的一个不相关的文档页面中发现了这一点。
agent_kwargs = {
"system_message": system_prompt.strip()
}使用此新参数重新创建 Agent 并再次运行,会导致 JSONDecodeError。
好消息是,系统提示这次应该是起作用了。
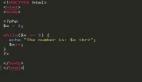
OutputParserException: Could not parse LLM output: Hello there, my culinary companion! How delightful to have you here in my whimsical kitchen. What delectable dish can I assist you with today?坏消息是,它坏了,但又是为什么呢?我这一次没有做任何奇怪的事情。
 图片
图片
有趣的事实:这些大量的提示也会成比例地增加 API 成本。
这样做的后果是,正常输出结构中的任何重大变化,例如由自定义系统提示引起的变化,都有可能破坏 Agent。这些错误经常发生,以至于有一个文档页面专门用于处理 Agent 输出解析错误。
我们暂时把与聊天机器人对话看作是一个边缘案例。重要的是,机器人能够返回菜谱,因为如果连这一点都做不到,那么使用 LangChain 就没有意义了。
在不使用系统提示的情况下创建一个新的 Agent,然后问它什么是简单有趣的晚餐?
> Entering new chain...
{
"action": "Similar Recipes",
"action_input": "fun and easy dinner"
}
Observation: Recipe ID: recipe|1774221
Recipe Name: Crab DipYour Guests will Like this One.
---
Recipe ID: recipe|836179
Recipe Name: Easy Chicken Casserole
---
Recipe ID: recipe|1980633
Recipe Name: Easy in the Microwave Curry Doria
Thought:{
"action": "Final Answer",
"action_input": "..."
}
> Finished chain.
Here are some fun and easy dinner recipes you can try:
1. Crab Dip
2. Easy Chicken Casserole
3. Easy in the Microwave Curry Doria
Enjoy your meal!至少它成功了:ChatGPT 能够从上下文中提取出菜谱,并对其进行适当的格式化(甚至能够修正名称中的错别字),并且能够在适当的时候进行判断。
这里真正的问题是,输出的声音很无聊,这也是基础版 ChatGPT 的共同特点和诟病。即使通过系统提示工程解决了 ID 缺失的问题,这般听上去的效果也不值得将其发布。就算真的在语音质量和输出质量之间取得了平衡,Agent 计数仍然会随机失败,而这并不是我的过错。
实际上,Agent 工作流是一个非常脆弱的纸牌搭成的房子,凭良心说,生产应用中估计无法使用。
LangChain 确实有 Custom Agent 和 Custom Chain 的功能,所以你可以在堆栈的某些部分重写逻辑(也许文档很少),这可以解决我遇到的一些问题,但在这一点上,你会感觉到 LangChain 更加复杂,还不如创建你自己的 Python 库。
工作要讲究方法
 图片
图片
大量随机集成带来的问题比解决方案更多。
当然,LangChain 确实也有很多实用功能,比如文本分割器和集成向量存储,这两种功能都是「用 PDF / 代码聊天」演示不可或缺的(在我看来这只是一个噱头)。
所有这些集成的真正问题在于,只使用基于 LangChain 的代码会造成固有的锁定,而且如果你查看集成的代码,它们并不十分稳健。
LangChain 正在建立一条护城河,这对 LangChain 的投资者来说是好事,因为他们想从 3000 万美元中获得回报,但对使用它的开发者来说却非常不利。总而言之,LangChain 体现了「它很复杂,所以它一定更好」这一经常困扰后期代码库的哲学,可是 LangChain 甚至还不到一年。
要想让 LangChain 做我想让它做的事,就必须花大力气解开它,这将造成大量的技术负担。与现在的人工智能初创公司不同,我自己的 LangChain 项目的技术债务无法用风险投资来偿还。在使用复杂的生态系统时,应用程序接口封装器至少应该降低代码的复杂性和认知负荷,因为使用人工智能本身就需要花费足够的脑力。LangChain 是为数不多的在大多数常用情况下都会增加开销的软件之一。
我得出的结论是,制作自己的 Python 软件包要比让 LangChain 来满足自己的需求容易得多。因此,我开发并开源了 simpleaichat:一个用于轻松连接聊天应用程序的 Python 程序包,它强调代码的最小复杂度,并将向量存储等高级功能与对话逻辑解耦。
开源地址:https://github.com/minimaxir/simpleaichat
但写这篇博文并不是为了像那些骗子一样,通过诋毁竞争对手来为 simpleaichat 做隐形广告。我不想宣传 simpleaichat,我更愿意把时间花在用人工智能创造更酷的项目上,很遗憾我没能用 LangChain 做到这一点。
我知道有人会说:「既然 LangChain 是开源的,为什么不向它的 repo 提交拉取请求,而要抱怨它呢?」唯一真正能解决的办法就是把它全部烧掉,然后重新开始,这就是为什么我的「创建一个新的 Python 库来连接人工智能」的解决方案也是最实用的。
我收到过很多留言,问我该「学什么才能开始使用 ChatGPT API」,我担心他们会因为炒作而首先使用 LangChain。如果拥有技术栈背景的机器学习工程师因为 LangChain 毫无必要的复杂性而难以使用 LangChain,那么任何初学者都会被淹没。
关于软件复杂性和复杂性下的流行性之争是永恒的话题。没有人愿意成为批评 LangChain 这样的免费开源软件的混蛋,但我愿意承担这个责任。明确地说,我并不反对 Harrison Chase 或 LangChain 的其他维护者(他们鼓励反馈)。
然而,LangChain 的流行已经扭曲了围绕 LangChain 本身的人工智能创业生态系统,这就是为什么我不得不坦诚我对它的疑虑。