














API 速率限制器是一个用于控制应用程序或服务对API请求的频率的服务。速率限制通常用于控制资源的使用、防止滥用和维护服务的稳定性。
类似的产品有:Express Rate Limit、Spring Boot Rate Limiter、Ratelimiter
难度级别:中等
1、什么是API速率限制服务?
想象一下,我们有一个服务正在接收大量请求,但它每秒只能处理有限数量的请求。为了处理这个问题,我们需要某种节流或速率限制机制,只允许一定数量的请求,这样我们的服务就能对所有请求进行响应。从高层次来看,速率限制器限制了一个实体(用户、设备、IP等)在特定时间窗口内可以执行的事件数量。例如:
- 一个用户每秒只能发送一条消息。
- 用户每天只能有三次信用卡交易失败。
- 单个IP每天只能创建二十个账号。
总的来说,速率限制器限制了发送者在特定时间窗口内可以发出的请求数量,当达到上限时,它会阻止请求。
2、为什么需要API速率限制?
速率限制的作用就好比是给你的服务穿上一件“防弹背心”,能够抵御一些恶意攻击,比如拒绝服务攻击,暴力破解密码或者信用卡信息等。这些攻击往往像海量的HTTP/S请求砸过来,表面上看似乎是真实用户在操作,实则可能是机器人在背后操控,因此这种攻击更加难以发现,也更有可能导致你的服务、应用或API被拖垮。
另外,速率限制还能帮助我们节省开支,降低维护网络设施的费用,避免垃圾邮件和网络骚扰。以下是一些能从速率限制中获益,使服务或API更稳定可靠的情况:
- 控制不守规则的客户端或脚本:有些用户或者脚本可能会一股脑儿地发送大量请求,这无论是故意还是无意,都可能让你的服务受不了。另外,有些用户可能会频繁地发送一些不那么重要的请求,我们得确保这种行为不会影响到重要的流量。比如,有的用户可能频繁地请求数据分析,我们不能让这种行为妨碍到其他用户的重要操作。
- 提升安全性:例如我们可以限制用户在双重认证中尝试密码的次数,避免密码被尝试破解。
- 防止滥用和不合理的设计实践:如果我们对API的使用没有限制,开发者可能会懒散下来,比如反复请求同样的信息,这样不仅浪费资源,也不符合好的开发习惯。
- 控制成本和资源使用:我们的服务通常是为正常使用情况设计的,比如一个用户每分钟发一篇帖子。如果没有限制,一些计算机可能会一秒钟就通过API推送成千上万条信息。所以我们需要用速率限制来控制API的使用情况。
- 提高收入:某些服务可能会根据用户的付费级别来限制他们的操作,这样就能根据限制来产生收入。例如,我们可以对所有的API设定一个默认的使用上限,如果用户想要更多使用权,就需要付费升级。
- 避免流量突增:确保服务即使面临大量请求,也能继续正常为其他用户提供服务。
3、系统需求和目标
我们的流量控制器需要达到以下要求:
功能要求:
- 限制一个实体在一段时间内可以向API发送的请求次数,例如每秒钟15次请求。
- API是通过集群来提供的,所以限流应该在整个集群中进行,跨服务器的请求都应纳入考虑。无论是在单台服务器还是在多台服务器上,只要超过了预设的阈值,用户都应该看到一个错误信息。
非功能要求:
- 系统是高可用。流量控制器需要随时待命,因为它是我们的服务对抗外部攻击的重要工具。
- 我们的流量控制器不应引入过多的延迟,以避免影响用户体验。
4、怎样进行流量控制?
流量控制其实就是设定用户可以多快、多频繁地访问API的规则。在一段时间内,限制客户对API的使用叫做"节流"。节流可以在应用层面或者API层面进行。一旦超出节流限制,服务器就会返回HTTP的"429 - 请求过多"状态码。
5、节流的类型有哪些?
以下是三种常见的节流类型,都被不同的服务使用过:
- 硬节流:API请求的次数绝对不能超过节流的限制。
- 软节流:这种类型下,我们可以设定API请求的次数超过一定比例。例如,如果我们的流量限制是每分钟100条消息,并且允许超过10%,那么我们的流量控制器每分钟最多会允许110条消息。
- 弹性或动态节流:在弹性节流下,如果系统有剩余资源,那么请求次数就可以超过设定的阈值。例如,如果用户每分钟只能发100条消息,那么在系统有剩余资源的情况下,我们可以让用户每分钟发送超过100条消息。
6、用于流量控制的都有哪些算法?
常用的流量控制算法有两种:
固定窗口算法:在这种算法中,时间窗口是从时间单位的开始到时间单位的结束。比如说,对于一个分钟,无论API请求在什么时候发出,我们都会看作是在0-60秒这个时间段内。比如在下面的图示中,0-1秒之间有两条消息,1-2秒之间有三条消息。如果我们的流量限制是每秒钟两条消息,那么这个算法只会控制'm5'。
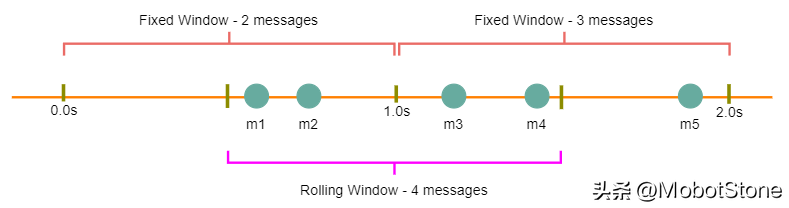
滑动窗口算法:在这个算法中,时间窗口从发出请求的那一刻开始,再加上窗口的长度。例如,如果在一秒的第300毫秒和第400毫秒各发送了一条消息,我们会把这两条消息看作是从这一秒的第300毫秒开始到下一秒的第300毫秒之间的两条消息。在上面的例子中,如果流量限制是每秒钟两条消息,我们就会控制'm3'和'm4'。
7、流量控制器的整体设计
流量控制器的职责是判断哪些请求将由API服务器接收,哪些请求将被拒绝。当新的请求来临时,Web服务器首先向流量控制器询问这个请求应该被接收还是应该被拒绝。如果请求没有被拒绝,那么它就会被发送到API服务器进行处理。
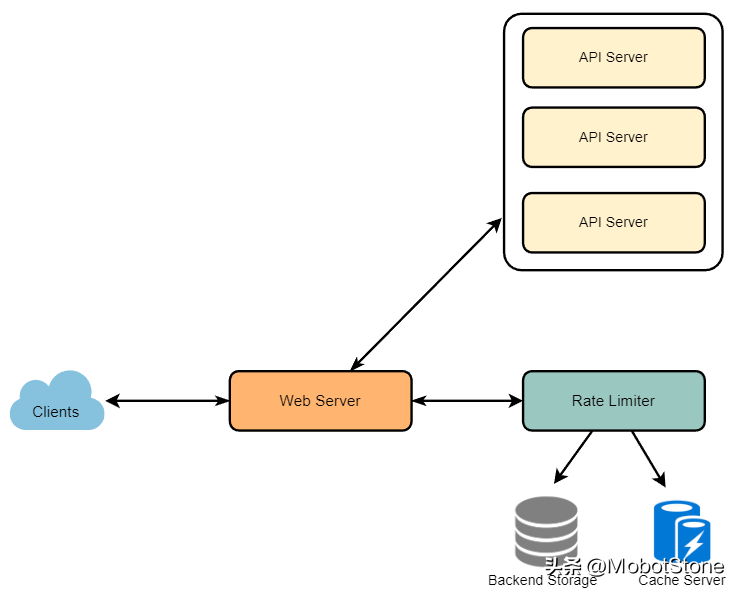
8、基本的系统设计和算法
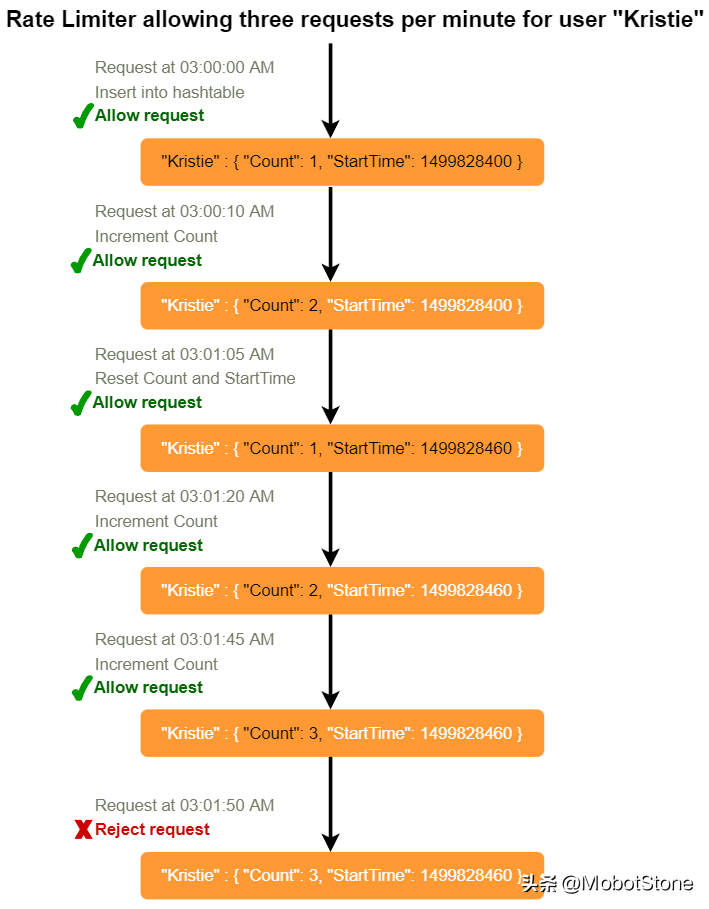
我们以每个用户的请求次数限制为例。在这种场景下,我们为每个用户设置计数器,记录用户已经发出了多少个请求,以及我们开始计数请求的时间戳。我们可以将这些信息存放在一个哈希表中,其中'key'是'UserID','value'是一个包含一个用于'Count'的整数和一个用于Epoch时间的整数的结构:

假设我们的流量控制器允许每个用户每分钟发出三个请求,那么每当有新请求进来,我们的流量控制器将执行以下步骤:
- 如果'UserID'在哈希表中不存在,将其插入,将'Count'设为1,将'StartTime'设为当前时间(规范化为分钟),然后允许该请求。
- 否则,找到'UserID'的记录,如果 CurrentTime – StartTime >= 1分钟,将'StartTime'设为当前时间,'Count'设为1,并允许请求。
- 如果 CurrentTime - StartTime <= 1分钟,且 如果 'Count< 3',增加计数并允许请求。 如果 'Count>= 3',拒绝请求。
我们的算法存在什么问题?
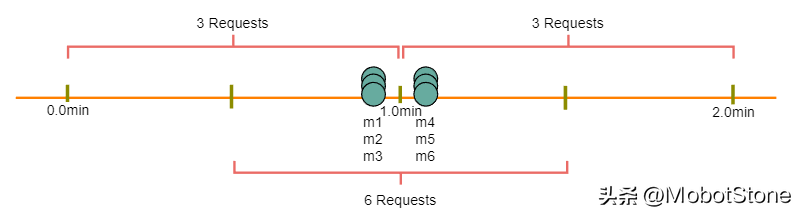
- 固定窗口算法:因为我们在每分钟结束时重置'StartTime',这意味着可能每分钟允许两倍数量的请求。假设一个用户在一分钟的最后一秒发送了三个请求,然后她在下一分钟的第一秒立即发送了三个更多的请求,这就导致在两秒内有6个请求。这个问题的解决方案是滑动窗口算法,我们稍后将讨论。
- 原子性:在分布式环境中,“读-然后-写”的行为可能会产生竞态条件。假设用户当前'Count'是"2",并且她发出了两个或者更多的请求。如果这两个请求由两个独立的进程处理,并且在任何一个进程更新它之前同时读取了Count,那么每个进程都会认为用户还能有一个请求,并且她还没有达到速率限制。

如果我们使用Redis来存储我们的键值,解决原子性问题的一个解决方案是在读取-更新操作期间使用Redis锁。然而,这将以降低同一用户的并发请求速度和增加另一层复杂性为代价。我们可以使用Memcached,但是它会有相似的问题。
如果我们使用简单的哈希表,我们可以对每条记录进行锁定以解决我们的原子性问题。
我们需要多少内存来存储所有的用户数据呢?让我们假设一个简单的解决方案,即我们将所有的数据保存在一个哈希表中。
假设'UserID'需要8 bytes。我们也假设一个2 bytes的'Count',可以计数到65k,对我们的使用场景来说已经足够了。尽管epoch时间需要4 bytes,我们可以选择只存储分钟和秒部分,这可以用2 bytes来存储。因此,我们需要总共12 bytes来存储用户的数据:
8+2+2=12bytes
假设我们的哈希表每条记录需要额外20 bytes的开销。如果我们需要在任何时候跟踪一百万用户,我们需要的总内存是32MB:
(12+20)bytes∗1millinotallow=>32MB
如果我们假设需要一个4-byte的数来锁定每个用户的记录以解决我们的原子性问题,我们将需要总共36MB的内存。
这可以轻松地放在一台服务器上;然而我们不希望将所有的流量都路由到一台机器上。此外,如果我们假设一个速率限制为每秒10个请求,那么这将对我们的流量控制器产生1000万QPS!这对一台服务器来说太多了。实际上,我们可以假设我们将在一个分布式环境中使用类似Redis或Memcached这样的解决方案。我们将所有的数据存储在远程的Redis服务器中,所有的流量控制器服务器将在处理或节流任何请求之前读取(和更新)这些服务器。
9、Sliding Window(滑动窗口)算法
如果我们能够追踪每个用户的每个请求,我们就可以维护一个滑动窗口。我们可以在哈希表的'value'字段中的Redis Sorted Set(有序集合)中存储每个请求的时间戳。

假设我们的速率限制器每分钟每用户允许3个请求,那么,每当有新请求进来,速率限制器将执行以下步骤:
- 从Sorted Set中移除所有早于"CurrentTime(当前时间) - 1分钟"的时间戳。
- 计算Sorted Set中元素的总数。如果这个计数大于我们的阈值"3",则拒绝请求。
- 在Sorted Set中插入当前时间并接受请求。
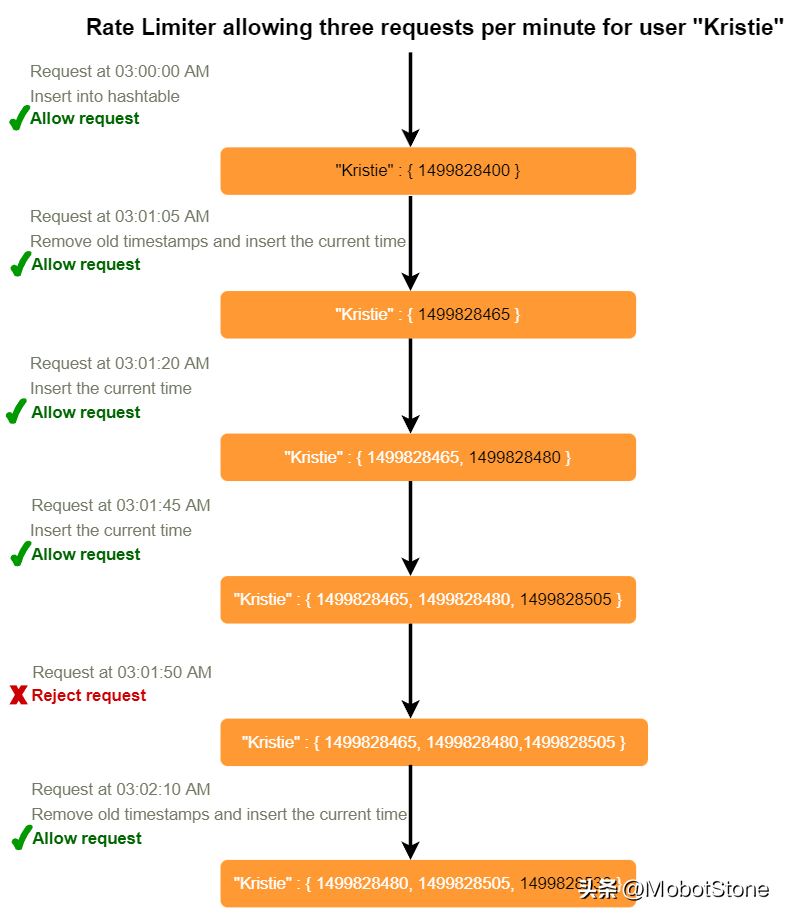
我们使用滑动窗口,要存储所有用户的数据需要多少内存呢?假设'UserID'需要8 byte。每个epoch时间将需要4byte。假设我们需要每小时500个请求的速率限制。假设哈希表有20 byte的开销,Sorted Set有20 byte的开销。最多,我们需要总共12KB来存储一个用户的数据:
8 + (4 + 20 (Sorted Set开销)) * 500 + 20 (哈希表开销) = 12KB
这里我们为每个元素预留了20 byte的开销。在一个Sorted Set中,我们可以假设我们至少需要两个指针来维护元素之间的顺序 —— 一个指向前一个元素,一个指向后一个元素。在64位机器上,每个指针将占用8byte。所以我们将需要16byte用于指针。我们额外增加了一个word(4 byte)用于存储其他开销。
如果我们需要在任何时候跟踪一百万用户,我们需要的总内存将是12GB:
12KB∗1million =12GB
与Fixed Window(固定窗口)相比,Sliding Window算法占用了大量的内存;这会是一个可扩展性问题。如果我们能够结合使用上述两种算法来优化我们的内存使用会怎样呢?
10、带计数器的滑动窗口
如果我们用多个固定的时间窗口来追踪每个用户的请求计数,例如,1/60的我们速率限制的时间窗口大小会怎样呢?例如,如果我们有一个小时的速率限制,我们可以每分钟计数一次,并在收到新请求时计算过去一个小时内所有计数器的总和,以计算阈值。这样可以减少我们的内存占用。比如,我们限制每小时500次请求,每分钟最多10次请求。这意味着,当过去一小时内带时间戳的计数器之和超过请求阈值(500)时,用户就超过了速率限制。此外,她每分钟不能发送超过十个请求。这是一个合理而实用的考虑,因为没有真实的用户会频繁发送请求。即使他们这么做,他们也会因为每分钟限制都会重置而看到重试的成功。
我们可以在Redis哈希中存储我们的计数器,因为它为少于100个键提供了极其高效的存储。当每个请求在哈希中增加一个计数器时,它也会设置哈希在一小时后过期。我们将每个'time'(时间)标准化到一分钟。
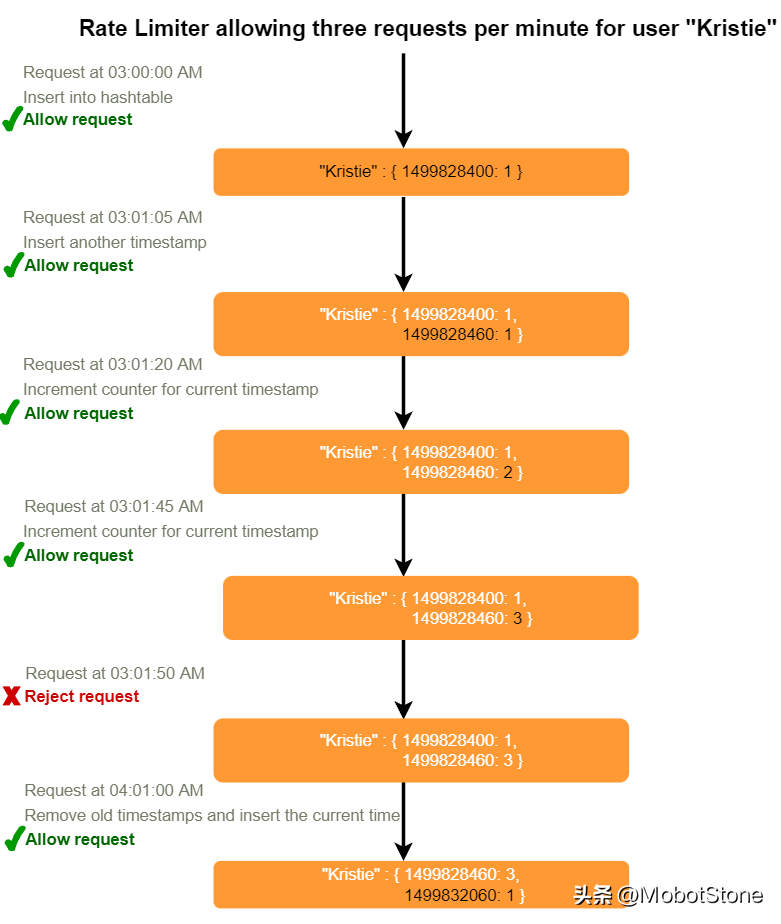
我们使用带计数器的滑动窗口,存储所有用户的数据需要多少内存呢?假设'UserID'需要8byte。每个epoch时间将需要4byte,Counter(计数器)将需要2byte。假设我们需要每小时500个请求的速率限制。假设哈希表有20byte的开销,Redis哈希有20byte的开销。因为我们每分钟都会进行计数,所以最多,每个用户需要60个条目。我们需要总共1.6KB来存储一个用户的数据:
8 + (4 + 2 + 20 (Redis哈希开销)) * 60 + 20 (哈希表开销) = 1.6KB
如果我们需要在任何时候跟踪一百万用户,我们需要的总内存将是1.6GB:
1.6KB * 1百万 ~= 1.6GB
所以,我们的'带计数器的滑动窗口'算法比简单的滑动窗口算法少用86%的内存。
11、数据分片和缓存
对于用户ID的数据,我们可以进行分片处理以分散用户数据。为了容错和复制,我们应该使用“一致性哈希”。如果我们希望对不同的API实施不同的限流标准,我们可以选择每个用户每个API进行分片。以“URL短链接生成器”为例,我们可以对每个用户或IP的createURL()和deleteURL() API设置不同的限流规则。
如果我们的API是分区的,一个实际的考虑是为每个API分片也设置一个相对较小的限流器。以我们的URL短链接生成器为例,我们希望限制每个用户每小时不超过100个短URL的创建。假设我们使用基于哈希的分区方式对createURL() API进行分区,我们可以设置每个分区的限流器,允许每个用户每分钟创建不超过3个短URL,另外每小时创建不超过100个短URL。
我们的系统可以从缓存近期活跃用户中获得巨大的好处。应用服务器可以在击中后端服务器之前快速检查缓存是否有所需记录。我们的限流器可以从Write-back缓存中获得显著的好处,只在缓存中更新所有计数器和时间戳。对永久存储的写入可以在固定的时间间隔进行。这样我们可以确保限流器对用户请求增加的延迟最小。读取操作始终先击中缓存,这在用户达到最大限制时非常有用,因为限流器将只读取数据而不进行任何更新。
对于API速率限制服务来说,最近最少使用(Least Recently Used,LRU)可能是一个合理的缓存驱逐策略。
12、我们应该按照IP还是用户进行限流?
让我们来讨论一下使用这两种方案的优缺点:
IP:在此方案中,我们对每个IP的请求进行限流;尽管在区分“好”与“坏”行为者方面并非最佳,但它仍然比完全没有限流要好。基于IP的限流最大的问题在于,当多个用户共享一个公网IP时,如在网吧或使用相同网关的智能手机用户。一个行为不当的用户可能导致对其他用户的限流。另一个问题可能出现在缓存IP限制时,因为即使一个计算机也有大量的IPv6地址可供黑客使用,让服务器因跟踪IPv6地址而耗尽内存是轻而易举的事!
用户:限流可以在用户认证后对API进行。一旦认证成功,用户将获得一个令牌,用户将在每次请求时传递该令牌。这将确保我们对具有有效认证令牌的特定API进行限流。但是,如果我们必须对登录API本身进行限流怎么办?这种限流的弱点是,黑客可以通过输入错误的凭证达到限流阈值来对用户进行拒绝服务攻击;之后,实际的用户将无法登录。
如果我们结合以上两种方案会怎么样呢?
混合:一个正确的方法可能是同时进行每IP和每用户的限流,因为它们在单独实施时都有弱点,然而,这将导致更多的缓存条目,每个条目需要更多的细节,因此需要更多的内存和存储空间。










