














一、为什么需要物化视图
日常生活中,我们每天都会产生大量的数据。根据统计,仅在2020年,人类每天就产生了约2.5EB(即2.5 x 10^18字节)的数据。而预计到2025年,这个数字将会达到463EB(即463 x 10^18字节),增长速度非常可观。随着数据规模的不断扩大,数据分析查询变得更加复杂和耗时,加速查询成为分析的关键任务。

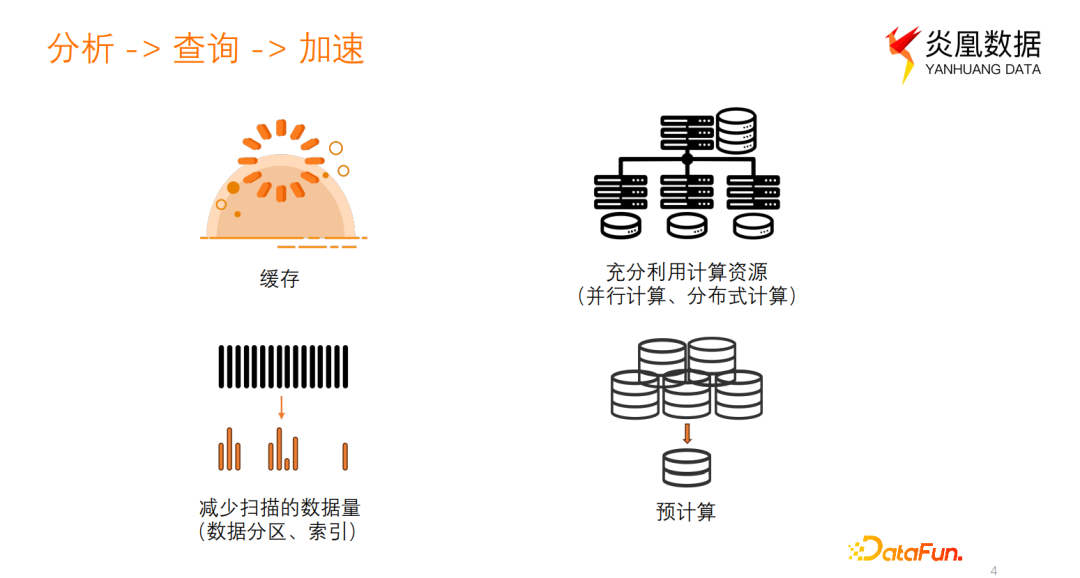
常用的分析查询加速手段主要包括以下几种:
- 缓存:通过将数据从慢存储介质缓存到快存储介质,例如内存中,可以在分析数据过程中获得更快的数据读取响应,从而实现加速效果。
- 并行计算和分布式计算:将计算任务分解为多个子任务并行处理,充分利用计算资源,提高分析查询的速度和效率。
- 数据分区和索引:减少查询时需要扫描和分析的数据量,从而达到加速的效果。
- 预计算:提前对数据进行计算和聚合,并将结果物化存储,以便在查询时直接使用计算好的结果来进行加速。物化视图是预计算的一种重要实现方式。
二、什么是实时物化视图
物化视图是预先计算出常用耗时或复杂查询的结果集,使得在查询时能够快速访问和使用这些预先计算的结果。如下图左表是一张商品订单信息表,包含简单的商品售卖信息。传统方式下,每次需要计算每个商品的总销售额时,都要从左边原始数据表中读取数据并进行计算,这既耗时又消耗系统资源。通过物化视图,我们可以事先对数据进行预计算,并将计算结果存储为右侧的结果表。下一次查询时,只需直接从右表物化视图中读取数据,无需再进行复杂的计算操作,节省了大量时间和资源开销,大幅提升查询的效率和响应速度。

然而在实际场景中,随着时间的增长,数据量也会持续增加。不同时间查询商品总销售额时,结果也会相应地发生变化,存储下来的物化数据也需要随着时间的推移进行更新。从时间序列数据中进行全量数据更新十分耗时,且物化结果会随着新数据的产生而失效。但时间序列数据通常具有Append-only特性,即已经存在的数据几乎不会发生变化。在物化数据和计算过程中,可以重复使用历史的物化计算结果,当新数据到来时,只需对原有的物化预计算数据进行增量更新。
实时物化视图就是一种适用于时间序列数据的预计算加速过程,其核心思想是将历史物化数据与计算结果保留下来,并在新数据到来时进行增量更新。在高效地管理和维护物化操作的同时,减少计算的开销。

在时间序列上实现实时物化视图的关键点主要有三个:
- 存储:在实时物化视图中,需要定义好物化表的结构,将物化数据存储下来。存储可以采用适当的存储介质和数据结构,以满足查询性能和存储需求。通过合理的存储设计,加上合适的索引压缩方式,可以确保物化数据的高效访问和使用。
- 更新:实时物化视图需要进行定期更新或事件驱动的增量更新。定期更新意味着根据一定的时间间隔,例如每小时、每天或每周对物化数据进行更新。事件驱动更新则是根据数据的变化事件触发更新操作。通过定期更新或事件驱动更新,可以保持物化数据与原始数据的一致性,并确保查询结果的准确性。
- 预计算:在实时物化视图中,预计算是一个重要环节,需要提供增量更新下的预计算方式。

三、怎样实现实时物化视图
炎凰产品本身是一个面向可观测性数据的分析平台,可观测数据天然带有时间戳,分析时会自然而然给查询带上查询时间窗。炎凰产品在设计实时物化视图时,期望物化视图的查询能适应任意的时间窗口,并得到准确的查询结果。基于这样的目标进行了如下实现。
对随着时间增长的原始时间数据,通常会拆分成小的数据块分片存储。分片规则通常基于导入时间范围、累积数据量、其他标签信息等进行分片。针对每个原始时间数据分片分别进行预计算得到对应的物化数据分片,当有新数据来临时,只需要对新数据进行物化预计算操作。
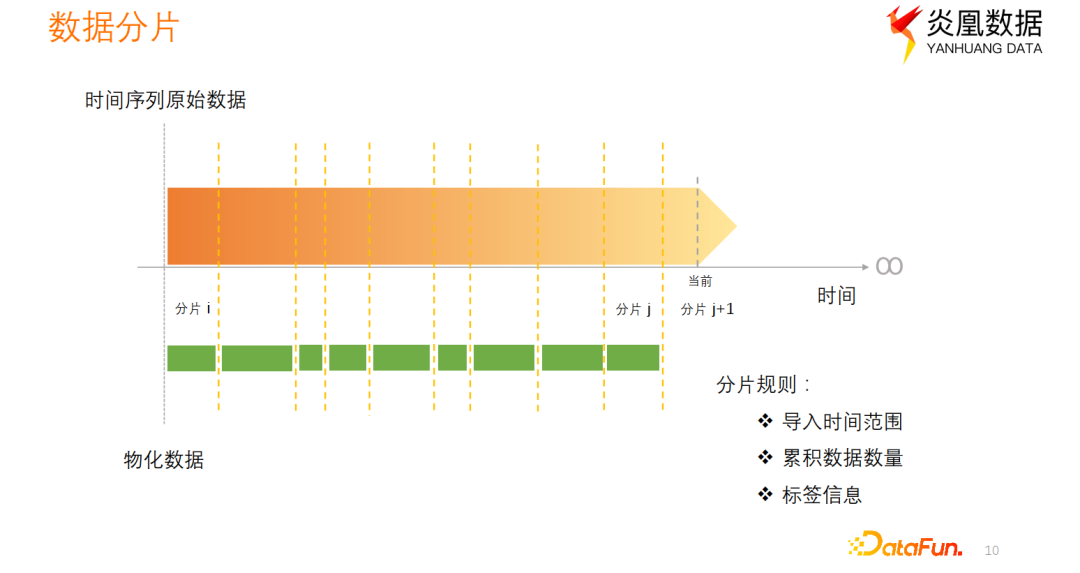
得到每个原始数据分片对应的预计算物化数据分片后,查询时通常要把这些物化分片合并再聚合。该过程类似于常见的Map-reduce计算框架:Map过程将数据拆分成小数据块,分发到不同计算节点进行计算,得到部分数据的部分聚合结果。Reduce阶段将部分结果合并再聚合得到最终结果返回给请求端。实时物化视图的实现中,对每个原始数据分片进行物化预计算操作类似于Map操作。这意味着每个分片都会独立进行预计算,生成部分聚合结果。而在查询结果时,需要将这些物化数据分片进行合并聚合,类似于Reduce操作。
需要注意的是,实时物化视图的实现过程中,每个数据分片进行预计算的时机是灵活的。它可以根据需要随着时间的增长而分别进行一些预计算操作。这意味着不同的分片可能会在不同的时间点进行预计算,根据数据的变化和更新情况来动态地进行预计算操作。


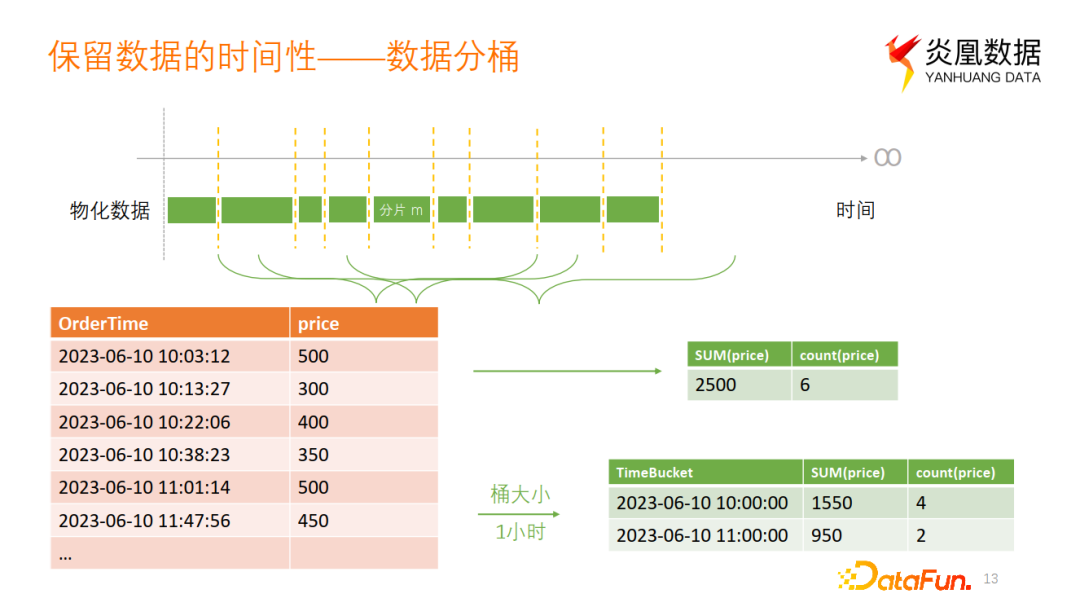
以价格的平均值为例,如上图所示,基于原始数据表①求价格的平均值,通常会先求和再计数,将中间预计算结果②存储下来。依此类推,对每个原始时间序列数据分片计算对应的部分数据的部分聚合计算操作。查询结果时只需要从表②中读取部分聚合结果,对其合并得到如表③的平均值。
在查询时,查询时间范围通常不会覆盖完整的物化分片所对应的时间范围,可能只包含某些物化分片的部分时间范围,也可能包含正在导入的数据或没有物化数据的时间范围。为了适应不同时间范围的查询,我们期望预计算物化数据保留一定的时间性。上述商品订单信息①中,会天然带有时间戳信息,得到的部分聚合结果②,是十分单薄的数据表总和和数量值,完全丧失了时间信息。在此基础上对预计算数据进行时间分桶,例如将②中结果进行一小时的分桶,得到右下方绿色表的中间结果。该预计算中间结果带有时间信息,包含每一小时时间桶下部分数据的部分聚合结果。
将上述计算价格平均值AVG的过程抽象成计算表达式:在预计算过程中会保留SUM和COUNT值,在最后请求查询结果的时候通常会对SUM求和之后再除以SUM数量值,这样就得到了最后查询请求结果SUM(SUM)/SUM(COUNT)。在这个基础上想要对预先物化数据进行时间分桶,相当于在预计算步骤中加上GROUP BY操作。具体见下图。

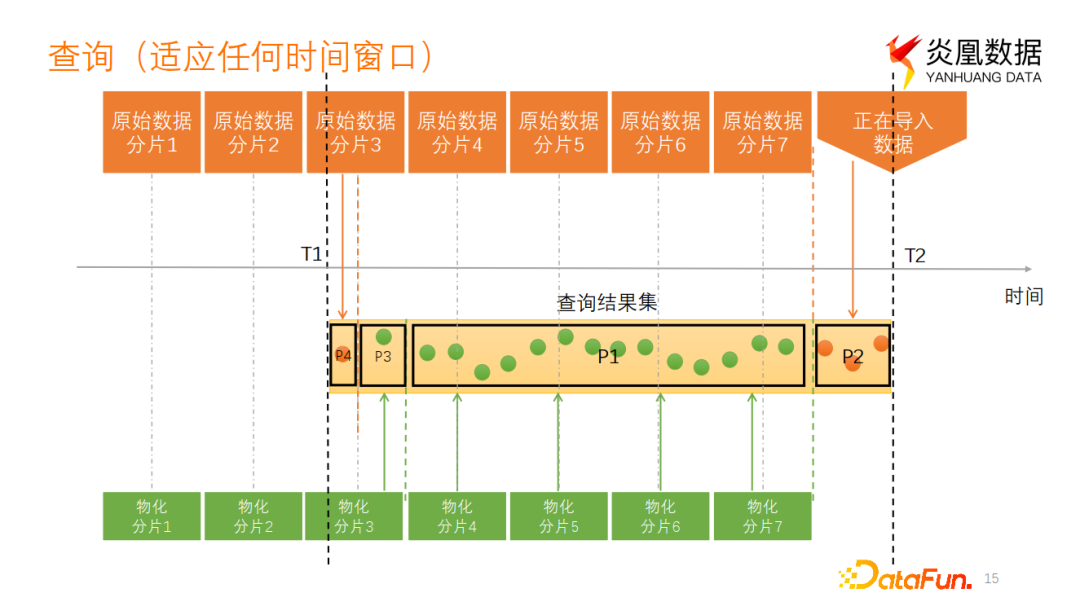
至此,我们得到了每个原始数据分片对应的预计算物化结果分片,每个物化分片包含了时间桶信息。查询物化视图时,查询时间窗口可能包含完整的物化分片范围,也可能包含正在导入的或者没有物化的数据分片的时间范围。如上图所示,将时间窗口按照是否已预计算物化进行划分。在物化分片4-7对应的时间范围上,可以采用预计算好的物化分片中的存储结果参与计算,这作为第一部分P1。对于右侧正在导入的数据,还在内存中未进行数据分片落盘,需要直接从原始数据中读取数据参与计算,这作为第二部分P2。对于左侧剩余时间范围,包含了物化分片3的部分时间范围,由于物化分片3上的数据已经进行了部分聚合操作,丧失了完整的原始时间信息,因此没有办法完全利用物化分片完整的部分聚合结果参与计算。将这部分数据按照时间分桶进行拆分,落在完整时间桶中的数据可以从物化分片结果中读取数据参与计算,作为第三部分P3。没有落在完全时间桶范围中的时间范围,只能从原始数据分片中读取数据参与计算,作为第四部分P4。通常P1加P3占查询时间范围比例比较高,当我们在查询物化视图时,对这部分数据进行了预计算加速,从而加速整个查询。

P3、P4部分的划分略显抽象,假设查询起始时间为11:22,给定时间分桶大小是1小时(1h),物化分片3占用的时间分桶为10:00到14:00。那么以12:00为分界限,则12:00-14:00部分时间已经落入完整时间桶范围即是P3部分。而11:22-12:00没有完整落入时间桶范围,必须从原始数据中读取时间参与计算,即为P4部分。

以上,我们将查询时间范围划分成了四个部分。第一部分是包含完整物化分片所在时间范围的数据。第二部分是没有物化的数据的时间范围。这里可以是正在导入的数据时间范围,也可能是创建完物化视图之后还没有来得及进行物化预计算的数据时间范围。第三部分是已经物化的数据但只取了部分时间桶里的数据结果。第四部分虽然已经进行过物化但由于丢失部分时间信息,没办法从时间桶的部分聚合结果中直接使用参与计算。基于这四部分时间窗口的划分,对P2和P4的时间窗口的数据,需要在查询时进行预计算相关的操作,例如AVG需要进行SUM/COUNT的计算。对于P1和P3数据已经做了聚合操作,直接从物化分片中读取聚合结果就可以了。得到这两部分数据再将所有SUM和COUNT进行聚合就得到了最终的查询结果。这样就完成了查询物化视图适应任何时间窗口的目标,并保证结果一致性。

炎凰产品提供SQL接口进行查询分析,针对上述实现定义了物化视图创建的DDL。如上图所示,在DDL中给定WITH语句,提供了创建物化视图的两个参数。前文中四个时间窗口中未物化数据部分,是需要从原始数据中去读取数据的,当物化程度比较高时,这部分数据所占比例会非常小,当请求端不需要非常准确的查询结果时,往往可以忽略这部分数据不参与计算,DDL建模时可以通过指定MATERIALIZED_ONLY=true在查询中忽略这部分数据,进一步加速查询分析。TIME_BUCKET即是前述时间桶的配置,该参数需要根据常用查询的时间范围和数据的时间分布来自定义。另外,在创建物化视图时,如果不需要关注过去数据的情况,就可以指定WITH NO DATA,不对过去数据进行后台的预计算操作。同时,炎凰产品提供了SHOW MATERIALIZED VIEW语句来展示物化视图的基本信息和状态。
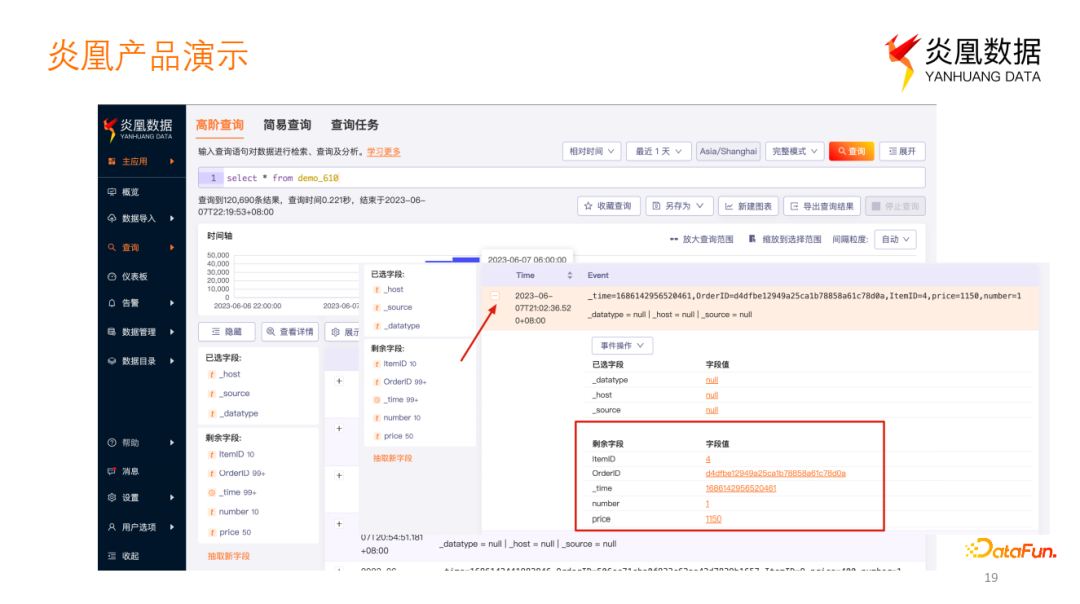
上图在炎凰产品中定义了一个简单的数据集,查询本身带有时间窗口。点开每条数据可以看到数据上的每个字段。在这个数据集上创建一个时间桶大小为1小时的物化视图,计算平均值,如下所示。

通过SHOW语句可以看到物化视图的基本信息,并提供了对应物化进度的状态展示,物化进度是通过已经物化的数据分片占所有需要物化数据分片的比例来表达的。

在炎凰产品中,预计算结果存成了Parquet数据格式。Parquet是一种网格存储,使用了高效的压缩算法和数据编码方式实现数据精简,能够减少数据IO,同时提高性能。实时物化视图更新是系统自动维护的,是数据变化事件驱动更新。当有新数据到达或满足某些特定条件时候系统会自动触发相应预计算和更新操作,更新操作范围是以数据分片为单位的,这种事件驱动方式使物化视图能够灵活响应数据变化和查询请求,保持物化视图的实时性。前文中描述的例子多以聚合为主,物化视图的定义也可以使用非聚合的查询,当我们只需要某部分字段或者某些过滤条件下的特定数据时,也可以创建物化视图来加速查询分析。
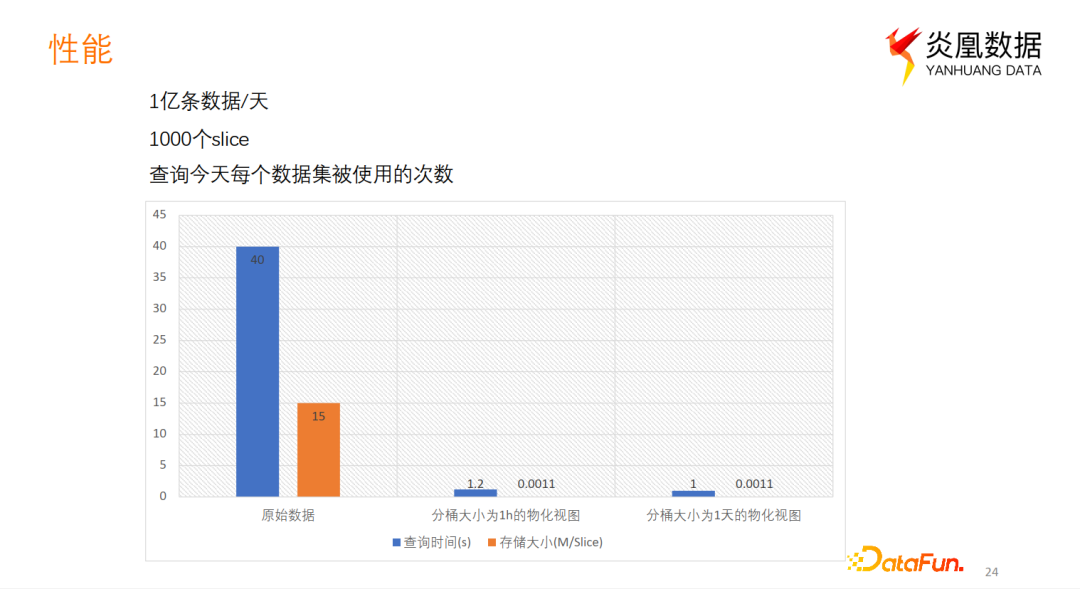
这种实现下物化视图的性能,与数据的时间分布、查询的时间范围,以及分片大小、时间分桶的大小等因素息息相关。这里我们用产品进行一个简单的性能测试,在炎凰系统中打开调试debug日志,每天大约能收集到1亿条数据,占用1000个数据分片。在这样的数据上查询每个数据集被使用的次数时,需要40s。
分别在该数据集上创建分桶大小为1小时和1天的实时物化视图。如下图可以看到查询性能有明显改善,时间分桶大小为1天的物化视图查询效率优于1小时,这是由于查询的时间窗口大小为1天和时间桶大小一致。原始数据分片存储大小为15M/Slice,不同时间分桶下的物化分片在存储上的优势相当,这得益于parquet的高性能存储。
四、展望和总结
前文介绍了产品中对实时物化视图的实现。我们还会对物化视图进行进一步的探索:
- 智能路由:当查询原始数据时,利用了物化视图中的一些聚合逻辑或过滤逻辑时,系统可以自动将基于原始数据的查询改写成基于物化视图的查询,进行智能路由,自动为查询加速。
- 分层物化:文中提到的物化存储主要是按时间范围划分的,但实际上,物化结果物理表的存储,可以按特定条件进行进一步分区,从而进一步加速。
- 另一种ETL:物化视图的维护过程是从原始数据中读取数据,进行预计算操作,再将预计算结果存储下来,这一过程是非常类似于ETL的。在系统中针对数据的所有计算操作都可以用DLL来表达,包括索引过程、查询过程等。

本次主要分享了实时物化视图的实现。实时物化视图通过预先物化和存储物化数据,使得查询操作可以从物化视图中直接获取数据,而不需要重新在原始时间序列数据上执行复杂操作,从而大大提高了查询性能。实现中将数据进行时间分桶,以数据事件触发自动维护更新,保持了物化视图查询与原始数据查询的实时一致性。但实时物化视图会带来额外的存储空间以及维护成本,使用物化视图需要结合实际场景,充分考虑查询的时间窗口范围、数据时间分布,来定制分析加速。

在物化视图方面还有很多值得探索的方面,期待以后有机会和大家交流分享。
五、Q&A
Q1:物化视图能替换现有报表模型吗?
A:会在报表中利用物化视图加速。很多时候会去频繁查看报表,报表背后的查询通常会使用物化视图查询,加速报表展示。
Q2:这里提到具体物化视图的实现,具体是用哪个框架实现的?
A:这是炎凰产品自己的物化视图实现,没有依赖于其他框架。
Q3:这里涉及的聚合函数有什么要求吗?
A:在整个分享过程中,讲述了实时物化视图的基本实现思路。预计算过程和系统底层的计算引擎相关。当计算引擎能支持聚合计算预计算(pre-aggregation)和后处理(post-aggregation)的操作分解时,在实时物化视图中都可以使用。通常而言,物化视图不支持非确定聚合计算、非线性聚合计算、依赖于动态参数的聚合计算等。

















