为大家揭秘流批一体样本生成的过程,分享对 Hudi 内核所做出的优化和改造,探索其在数据处理领域的实际应用和效果。
本篇文章提纲如下:
- 业务场景
- 离线样本存储与迭代
- 流批一体的样本生成
- 功能与优化
1. 业务场景
为了让大家更容易理解接下来要讲的基于数据湖的样本存储和样本生成问题,文章先给大家简单介绍一些相关的基础概念。首先是机器学习系统的离线数据流架构,机器学习系统和其他线上服务系统类似,其中和样本有关的角色也比较集中。如下图所示,整个离线数据流架构分为流式和批式两种类型,其中的样本数据由两部分构成,分别是特征和标签。

在流式架构中,特征由在线预估服务在 serving 时 dump 对应的快照并发送到消息队列中。标签则来自实时行为采集服务,通过日志上报等方法采集得到。在线样本生成服务消费两个数据流,通过关联得到完整的样本,并发送到下游的流式训练服务中进行模型训练,完成样本数据的消费。
批式架构是流式架构的补充,批式架构在订阅流式数据的同时,还会加入批式的特征或者批式生成的标签。比如风控反作弊或者广告类的业务,会有批式生产的数据,并使用批式的样本生成模块生成样本,进而被模型训练组件消费。
流式和批式数据流架构中,还有元数据服务,元数据服务记录了特征的相关元数据,流式批式数据流都会访问元数据服务获取 meta 信息。因此,我们对于批式的特征存储有若干种特定的访问 pattern。
读方面有以下读数据 pattern:大范围的按天批式读取,关注吞吐指标;秒级的点查;高效的谓词下推查询能力;存在基于主键/外建的 join。
在写方面需支持以下能力:基于主键的 upsert;针对部分 cell 的插入与更新;针对行/列/cell 的删除;基于外键的 upsert。
在这样的背景下,我们了解 Hudi 在机器学习离线数据流中的若干应用场景。
2.离线样本存储与迭代
我们希望设计的样本离线存储方案能够适用于多种场景,主要包含以下三类情况。
第一,模型的重新训练,回放流式训练的过程,迭代/纠偏模型等等。
第二,样本的数据迭代,增加修改或者删除对应的特征/标签,并重新训练模型。
第三,样本的 OLAP 查询,用于日常 debug 等。
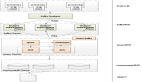
为了能够支持以上的场景的样本存储与迭代,我们提出的存储方案整体架构设计如下。在逻辑建模上,构建样本存储和构建特定 pattern 的 Hive 表非常类似,样本包含主键、分区键、内部元数据列等功能性 column,然后包含若干特征列和若干标签列。在物理架构上,通过流式和批式生产/采集的特征数据和标签数据通过多个作业混合 upsert 的方式写入 Hudi,更新位于 KV 存储的索引信息,并将实际的数据写入 HDFS 中。由于 Hudi 基于主键/外键 upsert 的特性,数据会被自然地拼接在一起,形成完整的包含特征和标签的样本数据,供消费使用。
 图片
图片
在对离线特征进行调研时,我们需要面临以下挑战:基于 HDFS 这种不可变的文件存储,如何实现低成本低读写放大的数据修改。在没有使用数据湖之前,用户做离线特征调研之前需要复制样本,修改并另存一份。其中消耗了巨大的计算和存储资源,伴随样本量的增大,这样的方案将消耗数个 EB 的存储,使得迭代变得不可能。
我们基于 Hudi 实现了 ColumnFamily 的能力。这个方案受到了经典 BigTable 存储 Apache HBase 的启发,将 IO pattern 不同的数据使用不同的文件进行存储,以减少不必要的读写放大。原理是将同一个 FileGroup 的不同列数据存储在不同的文件中,在读时进行合并。这种方法会将新增列的数据单独进行文件存储,发生修改或者新增成本很低。

我们通过为调研特征列赋予单独的 CF 的方式来减少读写放大,其他列复用线上的特征所在的 CF。这样资源的使用量只会和新增特征相关。这种方式极大得减少了迭代所需的存储使用,并且不会引入任何 shuffle 操作。

上文介绍了离线样本的存储与迭代方案,接下来我们进一步为大家介绍在线样本生成时的流批一体生成方案,讨论其如何降低在线存储的使用成本。
3. 流批一体的样本生成
在线样本生成服务中,我们使用 KV 或者 BigTable 类存储来满足样本拼接的需求,比如 RocksDB 等。这类存储点查性能好,延迟低,但是存储成本也较高。如果在数据有明显的冷热分层的情况下,这类存储本身并不能很好的满足这样的存储需求。Hudi 是一个具有 KV 语义的离线存储,存储成本较低,我们将冷数据存在 Hudi 上的方式来降低在线存储的使用成本,并通过统一的读写接口来屏蔽差异。这一架构也受到了目前市面的多种 HSAP 系统的启发。

为了能够让 Hudi 支持更好的点查,我们复用了写时的 HBase 索引。点查请求会先访问 HBase 索引找到数据所在文件,然后根据文件进行点查。整体端到端的延迟可以做到秒级。适合存储数据量大,qps 较低的场景。

4. 功能与优化
在使用 Hudi 满足诸多业务需求的过程中,我们也对其内核做了一些改造,以更好得服务我们的业务场景。
4.1 Local Sort
我们支持了单文件内的主键排序。排序是较为常见的查询性能优化手段。通过对主键的排序,享受以下收益
- CF 在读时,多 CF 合并使用 Sort Merge 的方式,内存使用更低。
- Compaction 时支持 Sort Merge。不会触发 spill,内存使用低。我们之前使用 SSD 队列来做 Compaction 以保证性能,现在可以使用一些廉价的资源(比如无盘的潮汐资源)来进行 Compaction。
- 在流批一体的样本生成中,由于主键是排好序的,我们点查时基于主键的谓词下推效果非常好。提升了点查性能。
4.2 Bulkload 并发写
并发写一直是 Hudi 的比较大的挑战。我们的业务场景中会发生行级别/列级别的写冲突,这种冲突无法通过乐观锁来避免。基于机器学习对于数据冲突的解决需求,我们之前就支持了 MVCC 的冲突解决方式。更进一步得,为了能够让 Hudi 支持并发读写,我们参考 HBase 支持了 Bulkload 的功能来解决并发写需求。所有写数据都会写成功,并由数据内部的 mvcc 来决定数据冲突。
我们首先将数据文件生成到一个临时缓冲区,每个缓冲区对应一个 commit 请求,多个写临时缓冲区的请求可以并发进行。当数据完整写入临时缓冲区之后,我们有一个常驻的任务会接受数据 load 的请求,将数据从缓冲区中通过文件移动的方式 load 进 Hudi,并生成对应的 commit 信息。多个 load 请求是线性进行的,由 Hudi Timeline 的表锁保证,但是每个 load 请求中只涉及文件的移动,所以 load 请求执行时间是秒级,这样就实现了大吞吐的数据多并发写和最终一致性。

4.3 Compaction Service
关于 Compaction,Hudi 社区提供了若干 Compaction 的开箱即用的策略。但是业务侧的需求非常灵活多变,无法归类到一种开箱即用的策略上。因此我们提供了 Compaction Service 这样的组件用来处理用户的 Compaction 请求,允许用户主动触发一次 Compaction,并可指定 Compaction 的数据范围,资源使用等等。用户也可以选择按照时间周期性触发 Compaction,以达到自动化数据生效的效果。
在底层我们针对 Compaction 的业务场景做了冷热队列分层,根据不同的 SLA 的 Compaction 任务,会选择对应的队列资源来执行。用来降低 Compaction 的整体成本。比如每天天级别的数据生效是一个高保障的 Compaction 任务,会有独占队列来执行。但是进行历史数据的单次修复触发的 Compaction,对执行时间不敏感,会被调度到低优先级队列以较低成本完成。
针对数据湖的样本存储与生成问题,我们搭建了适用于多种场景的存储方案架构,实现了批流一体的样本生成,并且通过对 Hudi 内核进行一定的改造,实现更加满足实际业务需求的功能设计。