译者 | 崔皓
审校 | 重楼
摘要

这篇文章介绍了如何将文本转语音(TTS Text-to-Speech)技术应用于ChatGPT,从而提高其用户体验。本文认为,通过听到ChatGPT的解释,用户可以获得更沉浸式和有趣的体验,特别是在学习新的主题或探索不熟悉话题的时候。文章还详细介绍了如何使用Python和Google的文本到语音库(gTTS)将ChatGPT的输出转化为语音并大声播放。最后,作者提出了一个完全无文本的工作流程的可能性,即通过语音到文本库的方式给ChatGPT提出指令。
开篇
如果你点击进入这篇文章,我相信你已经使用过ChatGPT一段时间了。我也是 :) 在过去的几个月里,我一直专注于如何从ChatGPT中获得更好的输出——所谓的提示工程——或者通过构建大型语言模型(LLM)进行自定义应用。然而,最近我一直在思考如何提升ChatGPT的用户体验。
虽然ChatGPT提供的网络交互界面很好用,但经过几次迭代后,它的表现并不那么优秀了。可以想像,如果我们能进一步赋予ChatGPT声音,让ChatGPT像AI助手一样大声回应你,那是怎样一种体验。
在这篇文章中,我们将探讨如何在ChatGPT输出的基础上添加“文本转语音”(TTS)功能,从而提升ChatGPT的用户体验,这样就能够让我们听见ChatGPT,而不仅仅是阅读它了。
让我们给ChatGPT一个声音,让你的交互更具吸引力,更易于访问,更方便!
文本转语音技术
文本转语音技术已经成为提升用户体验的工具。正如TTS(Text-to-Speech)的字面意思,这项技术可以将任何输入文本转化为语音。如今,TTS技术在我们的日常生活中无处不在,其应用范围横跨各个领域。
例如,流行的虚拟助手如Siri、Alexa或Google Home使用TTS来对用户查询提供口头回应。这些设备将基于文本的信息转化为合成语音,使用户可以通过语音命令与它们交互并接收听觉反馈。
流行的GPS导航系统如Google Maps也是一个例子。TTS技术将书面的街道名称和方向转化为口头提示,而不仅仅依赖视觉指示,使驾驶者在接收指导的同时可以专注于道路安全。
无障碍和TTS
将TTS集成到我们的日常生活中的一个显著优点是它们对无障碍的积极影响。
文本到语音技术为视力障碍者打开了一扇新世界的大门。通过提供书面内容的听觉输出,TTS系统使视力障碍者能够独立获取信息。
它使得无物理交互或打字就可以轻松进行对话,这对于运动障碍者来说非常有帮助。此外,TTS在对话自然性方面也表现优秀,对音频学习者以及阅读困难者更加友好。
ChatGPT和TTS
给ChatGPT添加一个文本到语音层可以使AI模型更像人类,易于建立更强的连接,使对话内容更有趣和对话过程更加愉快。当学习新的主题或探索不熟悉的话题时,听到ChatGPT的解释能够带来有趣的沉浸式体验。这种方式结合文本交互和音频解释,ChatGPT打造了一个适应多种学习风格和偏好的全面学习环境。这可以导致增强的知识保留和对讨论概念的更深入理解。
例如,当使用ChatGPT学习新语言时,ChatGPT的语音合成能力可以输出所学语言的准确音频,从而帮助学习者提高语言技能。这可以提高学习者的语言实践能力,纠正口音,以及促进整体流利度的发展,提升学习体验。
架构
在这篇文章中,我们将关注如何将ChatGPT的输出转化为语音,并将语音大声播放。然而,我们也可以让这个过程形成闭环,也就是用我们的声音作为输入给ChatGPT提供提示。
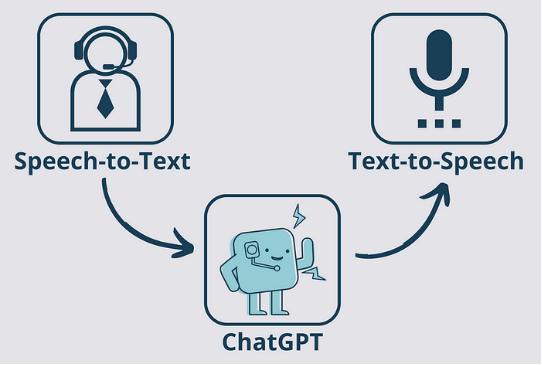
自制图表。表示 “语音到文本 → ChatGPT API → 文本到语音” 循环
Python集成 TTS 功能
让我们开始动手,将ChatGPT API和一个TTS库集成到一个Jupyter笔记本中。
ChatGPT API
下面是用来调用ChatGPT API的基本代码结构:
import openai
import os
openai.api_key_path = "/path/to/key"
def get_completion(prompt, model="gpt-3.5-turbo"):
"""
This function calls ChatGPT API with a given prompt
and returns the response back.
"""
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0
)
return response.choices[0].message["content"]
user_text = f"""
<Any given text>
"""
prompt = f"""
You will be provided with text delimited by triple quotes.
Can you provide the summary of the text in 1500 words approximately?
\"\"\"{user_text}\"\"\"
"""
# A simple call to ChatGPT
response = get_completion(prompt)get_completion()函数调用ChatGPT API并给出一个提示。如果提示包含额外的用户文本,它将用三引号与代码的其余部分分开。
Google文本转语音(gTTS)库
为了将ChatGPT的输出大声播放出来,我们将使用开源的gTTs库。
gTTS库是Google文本到语音API的一个免费的Python包。它允许你将文本转化为语音并生成音频文件。库的一些关键特性和功能包括:
1. 文本到语音转换:它允许你通过利用Google的文本到语音API的力量将文本转化为语音。
2. 语言和口音选择:你可以为生成的语音指定语言和口音。它支持广泛的语言和口音,如澳大利亚英语等。
3. 音频文件生成:该库生成MP3格式的音频文件,可以保存并播放。
4. 其他音频特性:它包括其他可能性,如slow选项可以更慢地阅读输出文本,或lang_check可以捕获文本中的任何语言错误。
此外,它可以方便地集成到Jupyter笔记本。
给ChatGPT一个声音
将TTS层实现到ChatGPT是非常直接的。我们只需要将ChatGPT的响应传递给gTTS()方法,然后将其保存为.mp3文件。最后,我们可以使用IPython模块来重复播放响应。
# Import the required module for tts
from gtts import gTTS
# Import the module required to
# play the converted audio
import IPython
prompt = "Can you explain me the latest Python features?"
response = get_completion(prompt)
# Passing the text and language to the engine.
myobj = gTTS(text=response, lang=language)
# Saving the converted audio in a mp3 file
myobj.save("response.mp3")
IPython.display.Audio("response.mp3")通过使用这种实现,任何ChatGPT调用在我们的Jupyter笔记本中都会如下所示:
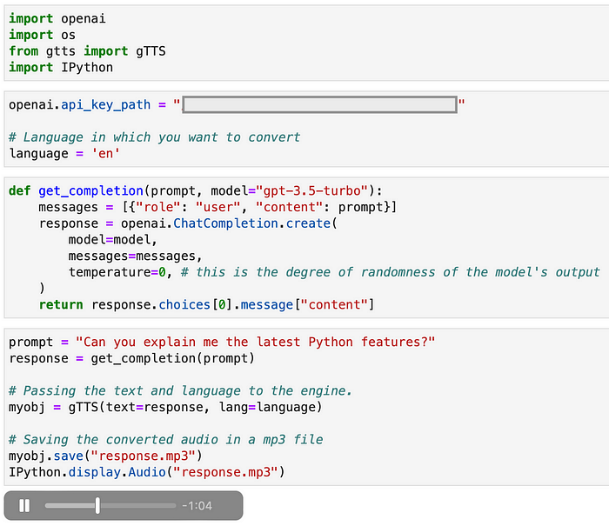
自制Jupyter笔记本示例截图
总结
通过听的方式获取ChatGPT的回应,可以加强用户的理解力。具有语音能力的ChatGPT将加强各个领域应用的可能性,如教育、无障碍技术、客户支持和语言学习,增强了用户体验。通过使用简单的API调用、gTTS和IPython库,人们可以通过大声播放来自ChatGPT的输出,从而提升ChatGPT的用户体验。正如文章中提到的,通过使用语音到文本库大声给ChatGPT提供指令,也可以实现无文本输入的工作流程。
原文标题:Unlocking a New Dimension of ChatGPT: Text-to-Speech Integration,作者:Andrea Valenzuela