













想象一下,一位画家准备创作一幅杰作,但却被限制在有限的调色板上。他们能创作出美丽的作品吗?当然可以!这与软件测试的世界非常相似,我们无法获得多样化和丰富的测试数据。幸运的是,生成式人工智能(Generative
AI)可以在这种情况下改变游戏规则。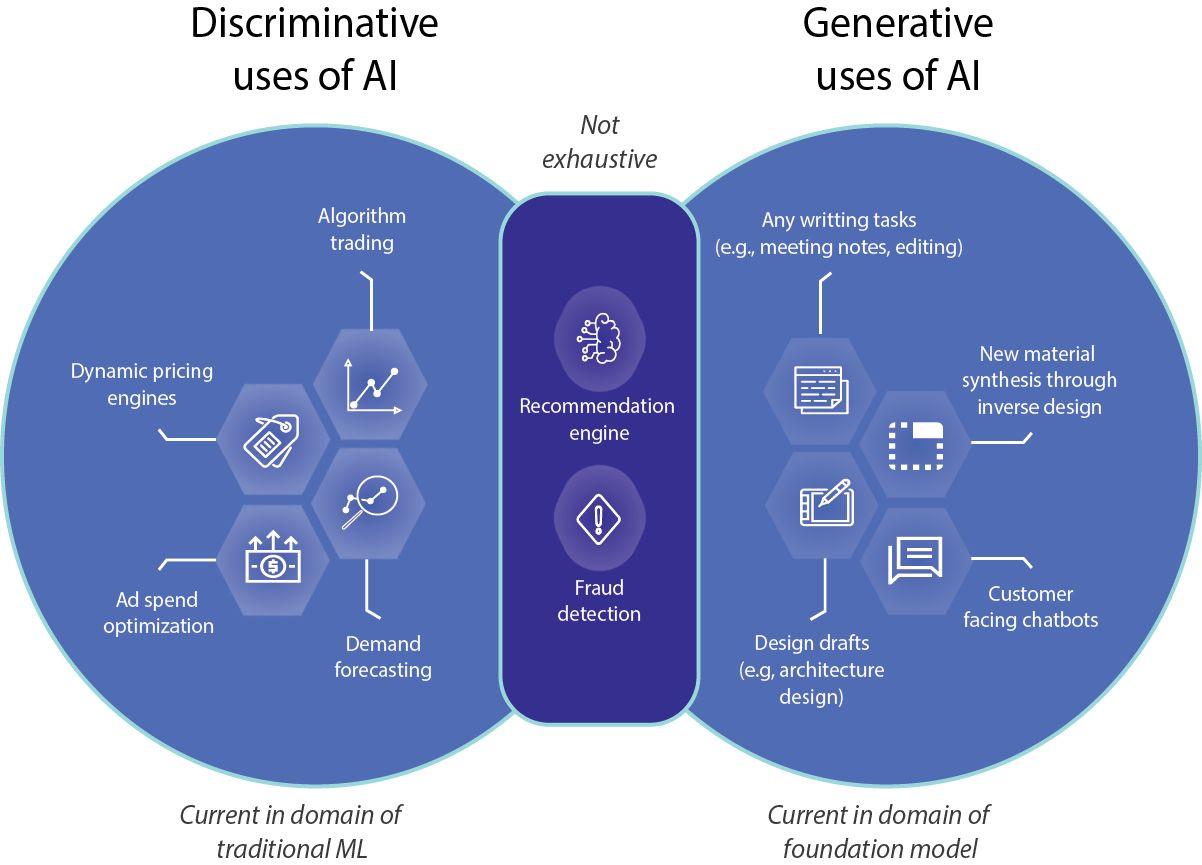
生成式人工智能就像一个艺术学生,观察、吸收,然后重新创作能与经验丰富的画家作品竞争的绘画作品。这种人工智能学习输入数据中的模式,然后生成模拟这些模式的新数据。额外的好处是,它可以接受训练,以遵守防止使用原始数据的治理、隐私、安全或道德准则。
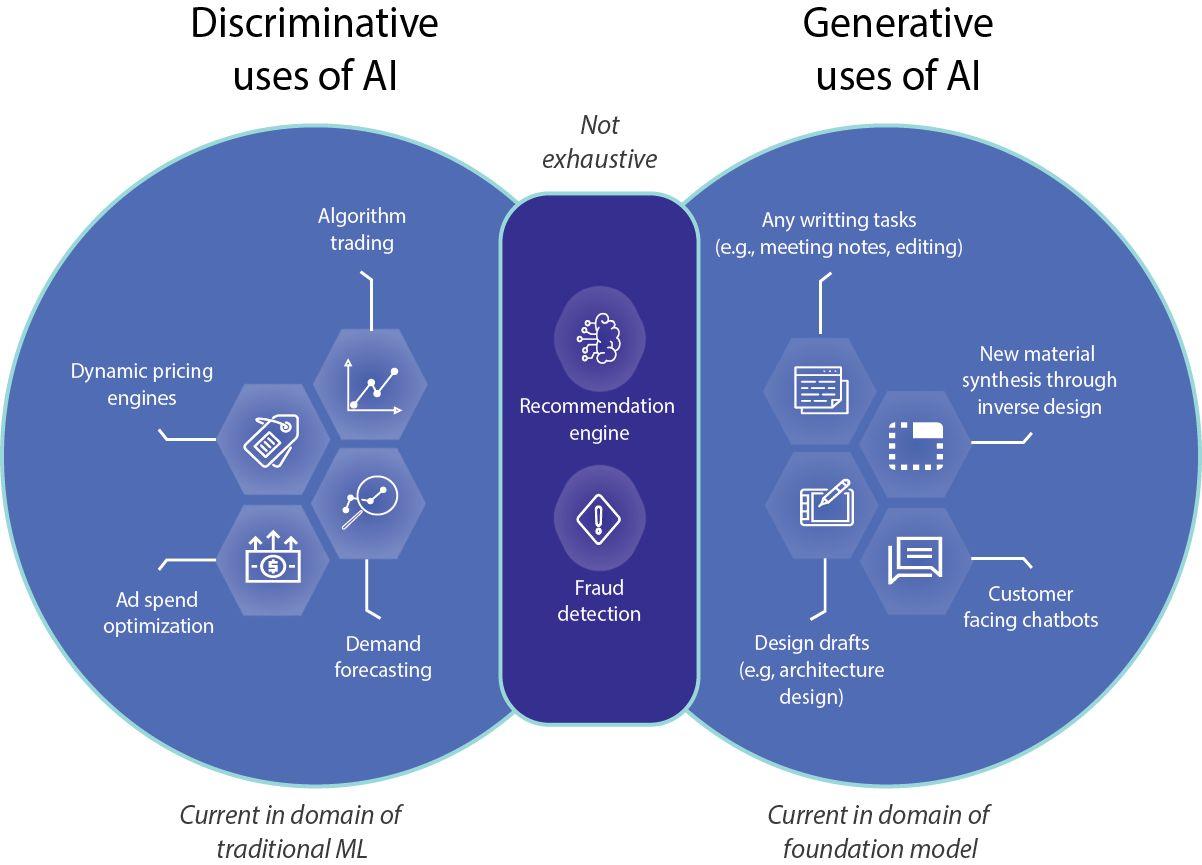
了解生成式人工智能和合成数据 生成式人工智能是人工智能的一个子领域,就像一个有创造力的学徒。它学习输入数据中的模式,然后产生与这些模式相似的新数据。合成数据是以密切模仿原始数据特征而创建和制作的数据。
利用生成式人工智能进行欺诈检测:一个案例 想象一下Alpha公司,一个金融机构,正在开发一个欺诈检测系统——一个通过机器学习模型训练的系统,用于区分欺诈和合法交易。为了有效地训练这个模型,他们需要一个大规模且多样化的数据集,足以充分代表两种类型的交易。
真实数据面临的挑战 事实上,欺诈交易就像在一堆中找针一样,他们非常罕见。因此,生成一个包含大量欺诈交易的真实世界数据集是很困难的。治理和道德约束可能进一步增加并限制用于训练模型的可用数据。
因此,对这样的数据集进行训练可能会产生一个在预测合法交易方面表现良好但无法识别欺诈交易的系统。这种对多数类别(合法交易)的偏见是一个常见的问题,被称为“类别不平衡”。
生成式人工智能派上用场 这里就是生成式人工智能所能发挥作用的地方。假设在一个包含一百万个交易的数据集中,只有1000笔是欺诈交易。可以在这个数据集上对生成式人工智能模型进行训练,识别出欺诈和合法交易的特征。
一旦经过适当的训练,模型可以生成紧密匹配真实交易的合成交易。生成式人工智能的一个显著特点是,它可以被指示以特定的比例生成数据。在这种情况下,人工智能可以生成一个包含欺诈和非欺诈交易的数据集。这个新的合成数据集,富含欺诈交易,密切模仿真实世界的情况。
通过在这个数据集上进行训练,欺诈检测系统更不容易受到偏见,更能够识别欺诈和非欺诈交易,因为数据集是平衡的。
真实影响 通过使用生成式人工智能创建一个平衡的数据集,Alpha公司可以构建一个更有效的欺诈检测系统。一个表现更好的系统有可能通过捕捉可能会被忽视的欺诈交易来为机构节省数百万。此外,它还可以提高客户的信任和满意度。通过遏制此类事件,机构可以保留客户的信任和忠诚。
此外,使用合成数据进行严格的测试和开发,而不会侵犯客户的隐私或违反数据保护法规。这可以避免机构可能遇到的法律问题和声誉损害。
在本质上,生成式人工智能的应用不仅增强了机构欺诈检测系统的技术能力,也显著提升了其业务目标和客户关系。
用于简化测试数据管理的生成式人工智能 想象一下,试图维护一个巨大、混乱的图书馆,这有时会让人觉得管理大量测试数据就像这样。生成式人工智能提供了一个更智能的解决方案;它可以根据需要生成测试数据,减少对大量存储空间的需求,并确保数据始终是新鲜的。
在连续测试环境中,每天运行多个测试并使用静态测试数据可能会导致由于数据过时而导致无效的测试。然而,通过生成式人工智能,测试团队可以为每次测试运行生成一组新的数据,确保覆盖各种场景。
一个真实的例子:电子商务测试 考虑一个全球知名的电子商务公司Alpha公司,他们管理着一个为全球数百万客户提供服务的复杂网站平台。该平台拥有众多功能,包括产品浏览、客户评价、购物车管理和复杂的结账和支付处理。为了确保顺利运行,Alpha公司采用连续测试以及及时发现和解决问题。
Alpha公司的测试团队每天进行大量测试,以验证系统的功能、性能和安全性。为了使这些测试有效,他们需要多样化和更新的数据,以模仿真实世界客户的互动。
传统设置面临的挑战 在传统设置中,测试团队会使用从生产数据复制的静态数据集。然而,这种方法存在两个主要问题:
数据过时:随着市场动态和客户行为的不断变化,静态数据很快就会过时,导致测试效果不佳。
存储问题:保持一个与生产数据多样性和数量相匹配的大型静态测试数据集需要大量的存储空间和不断的管理,增加了复杂性和成本。
生成式人工智能派上用场 然而,Alpha公司已经将生成式人工智能纳入他们的测试过程,以应对这些挑战。在每次测试运行之前,生成式人工智能模型会根据生产数据的模式创建一个与真实数据密切相似的全新合成数据集。
例如,在测试支付处理系统时,生成式人工智能模型会为不同类型的信用卡、购买金额、用户位置和交易时间生成合成数据,模仿当前客户的交易行为。
真实影响 数据的新鲜度确保它反映了客户行为的最新趋势和模式,从而实现更有效和相关的测试。由于合成数据是根据需求生成的,并且可以在测试后丢弃,因此大大减少了对庞大存储和数据管理基础设施的需求。
通过将生成式人工智能整合到他们的测试数据管理中,Alpha公司确保了更有效和高效的连续测试,提高了系统的可靠性和增强了客户体验。
挑战和考虑因素 采用生成式人工智能也存在一些挑战。AI模型的训练数据的质量最终影响着输出数据的质量。除非我们清楚了解用于生成人工智能模型训练的数据源,否则对创建的数据的质量会产生质疑。此外,使用生成式人工智能生成测试数据需要大量的计算资源,这对于所有组织来说可能是不可行的。
在伦理方面,尽管合成数据不包含任何敏感信息,但确保它不会意外透露有关训练数据中个人的任何信息非常重要。负责任地处理这些挑战是关键。
生成式人工智能注定将改变软件测试的格局。通过使我们能够创建多样化和真实的合成数据,它迎来了软件测试的新时代——更高效、全面和灵活的时代。
展望未来,生成式人工智能的前景令人兴奋。这项技术的进步有可能重塑当前的工作流程和实践。组织必须保持更新,准备适应。
虽然集成生成式人工智能的道路可能会遇到一些困难,但潜在的回报——更高效、全面和适应性强的软件测试——使它成为一段值得走的旅程。让我们以负责任的态度引导这条道路,并拥抱生成式人工智能所带来的光明未来。






























