













作者 | 崔皓
审校 | 重楼
摘要

在自然语言处理领域,为了让模型能够处理特定领域的问题,需要进行Fine-tuning,即在基础模型上训练模型以理解和回答特定领域的问题。在这个过程中,Embedding起到了关键作用,它将离散型的符号转换为连续型的数值向量,帮助模型理解文本信息。词嵌入是一种常用的Embedding方法,通过将每个单词转换为多维向量来捕获其语义信息。本文通过LangChain,ChromaDB以及OpenAI实现Fine-tuning的过程,通过更新Embedding层来让模型更好地理解特定领域的词汇。
开篇
在自然语言处理领域,最常见的用例之一是与文档相关的问题回答。虽然这方面ChatGPT已经做的足够好了,但它也只能作为一个通才,如果需要了解更多专业领域的内容还需要进一步学习。 你可以想象一下将你所在领域的文档,包括pdf、txt 或者数据库中的信息教给模型, 让模型也具备回答相关领域问题的能力。此时的模型就好像一个行业专家可以回答行业内的各种问题, 当然你需要喂给它大量的数据才能让它饱读诗书。
Fine-tuning
假设你正在使用一个预训练的语言模型来建立一个电影推荐系统。这个语言模型已经在大量的文本数据上进行了训练,因此它已经学会了理解和生成人类语言。但是,此时该模型并不知道和电影相关的事情,如果你希望这个模型能够理解和回答有关电影的特定问题,例如“这部电影的评分是多少?”或“这部电影的主角是谁?”。
为了让模型能够处理这些特定的问题,你需要对模型进行Fine-tuning。具体来说,就是需要收集一些电影相关的问题和答案,然后使用这些数据来训练模型。在训练过程中,模型的参数(或者说“权重”)将会被稍微调整,以使模型更好地理解和回答这些电影相关的问题。这就是Fine-tuning的过程。
需要注意的是,Fine-tuning通常比从零开始训练模型需要更少的数据和计算资源,因为预训练的模型已经学会了许多基础的语言知识。我们所做的Fine-tuning,只是在基础知识添加相关电影的知识从而帮助模型完成处理电影问答的工作。
Embedding
有了上面的思路,我们知道如果让一个通才变成我们需要的专才就需要对其进行专业知识的教学,这个就是Fine-tunning 要做的事情。 它在基础的模型上面进行微调,告诉它更多的专业知识。这些专业的知识是以文本的形式存在,并保存到已经生成的模型库中。
以电影专业为例,我们会将大量的电影相关的信息转换成文本,然后将其保存到数据模型库中。这也就意味着需要将文本的内容拆成一个个的单词并对其进行保存。
这里我们就需要用到"Embedding", 它是将离散型的符号(比如单词)转换为连续型的数值向量的过程。在我们的电影推荐系统例子中,Embedding可以帮助模型理解电影名称、演员名字、电影类型等文本信息。
例如,当我们谈论电影或演员的名称时,我们通常会使用词嵌入(word embeddings)。这种嵌入可以把每一个单词转换为一个多维的向量,这个向量能捕获该词的语义信息。词嵌入的一个重要特性是,语义相似的词会被映射到向量空间中相近的位置。如图1所示,“king,” “queen,” “man,” 和 “woman.”根据经验直观地理解这些词之间的关系。例如,man在概念上比queen更接近king。所以我们将这些词转化为笛卡尔空间上的数据,以直观的方式标注词在空间中的关系。

但是这还不够,我们还需要进一步衡量词与词之间的关系。从词义上man和king会更加接近一些,对woman和queen也是这样。于是,我们将坐标轴中的点变成向量,也就是有长度和方向的量。图2 中,Man 和King 分别用黄色和蓝色的向量线表示,它们形成的夹角就表示了它们之间的关系,这个角越小关系就更紧密。对于Woman 和Queen 来说也是如此。 因此,我们可以通过词嵌入之后形成的向量夹角来测量词与词之间的关系。
说明:
在词嵌入中,向量的"大小"通常指的是向量的长度,这是由向量的所有元素(或坐标)的平方和的平方根计算出来的。这是一个数学概念,与向量在几何空间中的实际长度相对应。
然而,这个"大小"或"长度"在词嵌入中通常没有明确的语义含义。也就是说,一个词的嵌入向量的长度并不能告诉我们关于这个词的具体信息。例如,一个词的嵌入向量的长度并不能告诉我们这个词的重要性、频率、情感等。
在创建词嵌入时,我们通常不会直接定义向量的大小。相反,向量的大小是由嵌入模型(如Word2Vec或GloVe)在学习过程中自动确定的。这个过程通常是基于大量的文本数据,并考虑到词语在文本中的上下文信息。
在某些情况下,我们可能会对词嵌入向量进行归一化,使得每个向量的长度都为1。这样做的目的通常是为了消除向量长度的影响,使得我们可以更纯粹地比较向量之间的角度,从而衡量词语之间的语义相似性。
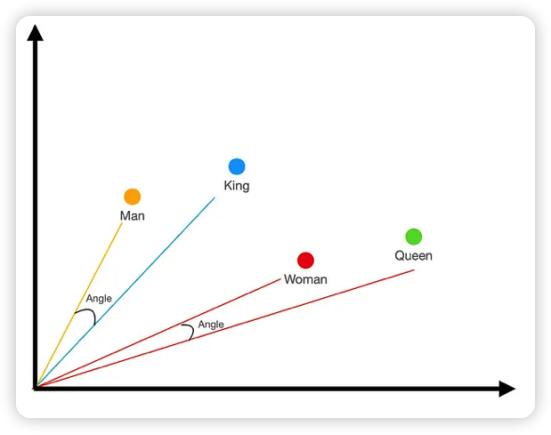 图2
图2
实际上在将专业知识不断更新到模型库的过程就是Fine-tuning,在更新过程中需要将词保存到模型的操作就是Embedding。此时,模型的Embedding层会因为Fine-tuning 而被更新。例如,如果预训练的模型是在通用的文本数据上训练的,那么它可能并不完全理解电影相关的一些专有名词或者俚语。在Fine-tuning过程中,我们可以通过更新Embedding层来让模型更好地理解这些电影相关的词汇。
需要注意的是,虽然我们有时候会在Fine-tuning过程中更新Embedding层,但不是必须的。如果预训练的模型已经有很好的词嵌入,并且新任务的数据不够多,我们可能会选择冻结(即不更新)Embedding层,只更新模型的其他部分,以防止模型在小型数据集上过拟合。
假设你正在使用一个预训练的模型来识别各种影片。你的预训练模型可能是在数百万条影片信息上训练而来的,由于训练的数据足够大,模型已经识别各种影片。然而,你想要使用这个模型来识别特定种类的影片,比如说文艺片和纪录片。
此时,你需要对模型进行Fine-tuning,但是,你手上的文艺片和记录片的训练集只有几百条,这比预训练模型的几百万相差很大, Embedding 的效果就不会太好了。
此时,需要"冻结"模型的Embedding层。这个层已经在预训练过程中学会了如何从众多影片信息中提取有用的电影特征。如果执意进行Fine-tuning,并Embedding你手上的 几百条信息,模型可能会过度适应小型数据集,导致其在未见过的数据上表现不佳。这就是我们所说的过拟合。
如何进行我们的Fine-tuning 和Embedding
有了上面的概念,我们需要确定创建自己专业模型的思路。首先,需要有一个预处理的模型,就是一个已经被别人训练好的LLM(大语言模型),例如OpenAI的GPT-3等。有了这个LLM之后,把我们的专业知识(文本)Embedding 到其中形成新的模型就齐活了。
为了达到上面的目的,我们使用了LangChain作为管理和创建基于LLMs的应用程序的工具。LangChain是一个软件开发框架,旨在简化使用大型语言模型(LLMs)创建应用程序的过程。作为一个语言模型集成框架,LangChain的使用案例大致与一般的语言模型重合,包括文档分析和摘要,聊天机器人和代码分析。
说明:
LangChain于2022年10月作为一个开源项目由Harrison Chase在机器学习初创公司Robust Intelligence工作时发起。该项目迅速获得了人气,GitHub上有数百名贡献者进行了改进,Twitter上有热门讨论,项目的Discord服务器活动热烈,有许多YouTube教程,以及在旧金山和伦敦的见面会。这个新的初创公司在宣布从Benchmark获得1000万美元的种子投资一周后,就从风投公司Sequoia Capital筹集了超过2000万美元的资金,公司估值至少为2亿美元。
有了处理LLM的工具,那么再找个LLM 让我们在上面 Fine-tuning 就好了。 我们选择了Chroma,它是一个开源的嵌入式数据库。如图3所示,Chroma通过使知识、事实和技能可以轻松地为大型语言模型(LLMs)插入信息,从而简化了LLM应用的构建。它可以存储嵌入和元数据,嵌入文档和查询,搜索嵌入式。我们会使用ChromaDB作为向量库,用来保存Embedding 的信息。
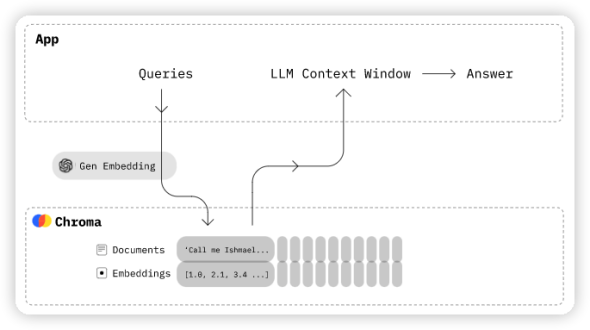 图3
图3
当然还需要OpenAI 提供的预处理模型,将文本转化为机器可以理解的向量形式,方便Embedding。
这个编程环境我使用了CoLab,Google Colab(全名为Google Colaboratory)是一个由Google提供的免费云端Jupyter Notebook环境。用户可以在其中编写和执行Python代码,无需进行任何设置,仅需要一个Google帐户即可使用。Google Colab被广泛用于数据分析、机器学习、深度学习等领域。它还提供了免费的计算资源:包括CPU,GPU,甚至TPU(Tensor Processing Units)。这样就省去了我安装Python 的烦恼,打开网页就可以直接使用。
开始编码
首先,需要安装一些库。需要Langchain和OpenAI来实例化和管理LLMs。
每个命令的含义如下:
pip install langchain
pip install openai
pip install chromadb
pip install tiktoken上面的代码主要是安装各种工具:
- pip install langchain:安装Langchain库。
- pip install openai:安装OpenAI库。OpenAI库提供了一个Python接口,用于访问OpenAI的各种API,包括用于生成文本的GPT-3等模型的API。
- pip install chromadb:安装ChromaDB库。ChromaDB是一个开源的嵌入数据库,它提供了存储和搜索嵌入向量的功能。
- pip install tiktoken:安装TikToken库。TikToken是OpenAI开发的一个库,它能够用于分析如何计算一个给定文本的token数量。这里的token是用来记录Embedding中字、词或者句子的个数。
接着,需要一个文本文件,也就是我们需要教模型学习的内容。这里可以通过网络获取,为了方便,我就手动写了几个字符串,用作测试。
import requests
#text_url = '【输入你的文本的网络地址】'
#response = requests.get(text_url)
#data = response.text
data="Bob likes blue. Bob is from China."接着,我们导入需要的类。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma导入了`OpenAIEmbeddings`,用于获取OpenAI大型语言模型生成的词向量(或者句向量)。
导入了`CohereEmbeddings`,用于获取Cohere大型语言模型生成的词向量(或者句向量)。Cohere是一个提供预训练语言模型服务的公司。
导入了`CharacterTextSplitter`,用于将文本按照字符进行切割。
导入了`ElasticVectorSearch`,用于在Elasticsearch中进行向量搜索。
导入了`Chroma`,用于操作ChromaDB。
总的来说,是导入一些处理文本、获取和存储词向量、以及进行向量搜索的工具。
接着将导入的文本进行处理,主要是将我们输入的文本转换成向量,并且保存到ChromaDB的向量库中。我将代码的含义通过注释的方式展示如下:
import openai
#将你的OpenAI API的密钥存储在变量myApiKey中
myApiKey = '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'
#创建了一个CharacterTextSplitter的实例,这是一个用于将文本分割成较小部分的工具
text_splitter = CharacterTextSplitter()
#使用text_splitter将输入的文本data分割成较小的部分,并将这些部分存储在变量texts中。
texts = text_splitter.split_text(data)
print(texts)
#创建了一个OpenAIEmbeddings的实例,用于获取OpenAI大型语言模型生成的词向量(或者句向量)。
embeddings = OpenAIEmbeddings(openai_api_key=myApiKey)
persist_directory = 'db'
#使用ChromaDB创建了一个文本的词向量数据库。它将texts中的文本部分转换为词向量,然后将这些词向量和相应的元数据存储在指定的持久化目录中。
docsearch = Chroma.from_texts(
texts,
embeddings,
persist_directory=persist_directory,
metadatas=[{"source":f"{i}-pl"} for i in range(len(texts))]
)既然上面的代码将我们的文本Embedding到项目库中了,那么当我们提问的时候就可以从这个库中读取相关的信息。下面的代码使用LangChain库构建一个检索型问答(Retrieval-based Question Answering)系统,然后使用这个系统来回答一个特定的问题。
#从LangChain库中导入了RetrievalQAWithSourcesChain类,这是一个用于构建检索型问答系统的类。
from langchain.chains.qa_with_sources.retrieval import RetrievalQAWithSourcesChain
#创建了一个RetrievalQAWithSourcesChain的实例,即一个检索型问答系统。该系统使用OpenAI的大型语言模型(设置了温度参数为0)进行问答,使用Retriever进行信息检索,并且设置了返回来源文档的选项。
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm = OpenAI(openai_api_key=myApiKey,temperature=0),
chain_type="stuff",
retriever = retriever,
return_source_documents = True
)
#一个函数,用于处理问答系统返回的结果。该函数会打印出答案以及来源文档。
def process_result(result):
print(result['answer'])
print("\n\n Sources: ", result['sources'])
print(result['sources'])
#提出问题
question = '鲍勃喜欢什么颜色'
#使用定义的问答系统来回答问题,并将结果存储在result变量中
result = chain({"question":question})
#调用定义的函数来处理并打印问答结果。
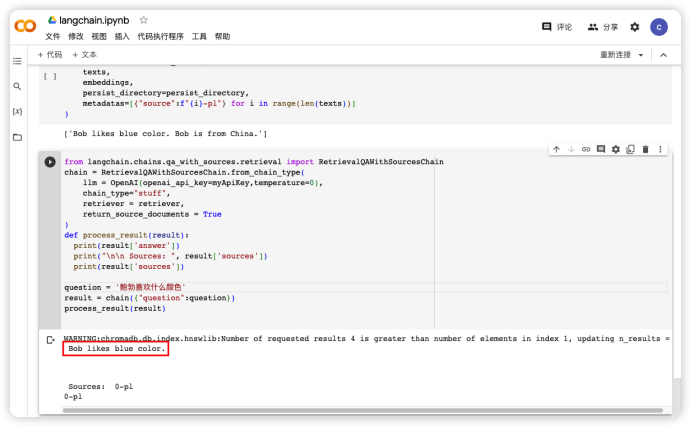
process_result(result)执行上面的代码得到如图4 结果。可以看到我们输入的文本“Bob likes blue color”被作为答案回应了我们的提问。
整体代码清单
pip install langchain
pip install openai
pip install chromadb
pip install tiktoken
import requests
#text_url = '【输入你的文本的网络地址】'
#response = requests.get(text_url)
#data = response.text
data="Bob likes blue. Bob is from China."
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
import openai
#将你的OpenAI API的密钥存储在变量myApiKey中
myApiKey = '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'
#创建了一个CharacterTextSplitter的实例,这是一个用于将文本分割成较小部分的工具
text_splitter = CharacterTextSplitter()
#使用text_splitter将输入的文本data分割成较小的部分,并将这些部分存储在变量texts中。
texts = text_splitter.split_text(data)
print(texts)
#创建了一个OpenAIEmbeddings的实例,用于获取OpenAI大型语言模型生成的词向量(或者句向量)。
embeddings = OpenAIEmbeddings(openai_api_key=myApiKey)
persist_directory = 'db'
#使用ChromaDB创建了一个文本的词向量数据库。它将texts中的文本部分转换为词向量,然后将这些词向量和相应的元数据存储在指定的持久化目录中。
docsearch = Chroma.from_texts(
texts,
embeddings,
persist_directory=persist_directory,
metadatas=[{"source":f"{i}-pl"} for i in range(len(texts))]
)
#从LangChain库中导入了RetrievalQAWithSourcesChain类,这是一个用于构建检索型问答系统的类。
from langchain.chains.qa_with_sources.retrieval import RetrievalQAWithSourcesChain
#创建了一个RetrievalQAWithSourcesChain的实例,即一个检索型问答系统。该系统使用OpenAI的大型语言模型(设置了温度参数为0)进行问答,使用Retriever进行信息检索,并且设置了返回来源文档的选项。
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm = OpenAI(openai_api_key=myApiKey,temperature=0),
chain_type="stuff",
retriever = retriever,
return_source_documents = True
)
#一个函数,用于处理问答系统返回的结果。该函数会打印出答案以及来源文档。
def process_result(result):
print(result['answer'])
print("\n\n Sources: ", result['sources'])
print(result['sources'])
#提出问题
question = '鲍勃喜欢什么颜色'
#使用定义的问答系统来回答问题,并将结果存储在Result变量中
result = chain({"question":question})
#调用定义的函数来处理并打印问答结果。
process_result(result)最后的思考
在自然语言处理领域,为了让模型能够处理特定领域的问题,需要进行Fine-tuning,并利用Embedding方法将文本信息转换为数值向量。这样的过程使得模型能够具备特定领域的专业知识,从而能够回答相关问题。词嵌入是一种常用的Embedding方法,通过将单词转换为多维向量来捕获其语义信息。在Fine-tuning过程中,我们可以更新Embedding层来增强模型对特定领域词汇的理解能力。整个过程需要借助工具和库来实现,如LangChain和ChromaDB。通过这样的流程,我们可以建立一个专业领域的问答系统,提供准确的答案和相关的来源文档。
作者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。





























