经过对前面两篇文章《Arrow数据类型》[1]和《Arrow Go实现的内存管理》[2]的学习,我们知道了各种Arrow array type以及它们在内存中的layout,我们了解了Go arrow实现在内存管理上的一些机制和使用原则。
Arrow的array type只是一个定长的、同类型的值序列。在实际应用中,array type更多时候只是充当基础类型,我们需要具有组合基础类型能力的更高级的数据结构。在这一篇文章中,我们就来看看Arrow规范以及一些实现中提供的高级数据结构,包括Record Batch、Chunked Array以及Table。
我们先来看看Record Batch[3]。
1. Record Batch
Record这个名字让我想起了[Pascal编程语言](https://en.wikipedia.org/wiki/Pascal_(programming_language "Pascal编程语言"))中的Record。在Pascal中,Record的角色大致与Go中的Struct类似,也是一组异构字段的集合。下面是《In-Memory Analytics with Apache Arrow》[4]书中的一个Record例子:
// 以Go语言呈现
type Archer struct {
archer string
location string
year int16
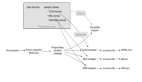
}Record Batch则顾名思义,是一批Record,即一个Record的集合:[N]Archer。
如果将Record的各个字段作为列,将集合中的每个Record作为行,我们能得到如下面示意图中的结构:
 图片
图片
Go Arrow实现中没有直接使用“Record Batch”这个名字,而是使用了“Record”,这个“Record”实际代表的就是Record Batch。下面是Go Arrow实现定义的Record接口:
// github.com/apache/arrow/go/arrow/record.go
// Record is a collection of equal-length arrays matching a particular Schema.
// Also known as a RecordBatch in the spec and in some implementations.
//
// It is also possible to construct a Table from a collection of Records that
// all have the same schema.
type Record interface {
json.Marshaler
Release()
Retain()
Schema() *Schema
NumRows() int64
NumCols() int64
Columns() []Array
Column(i int) Array
ColumnName(i int) string
SetColumn(i int, col Array) (Record, error)
// NewSlice constructs a zero-copy slice of the record with the indicated
// indices i and j, corresponding to array[i:j].
// The returned record must be Release()'d after use.
//
// NewSlice panics if the slice is outside the valid range of the record array.
// NewSlice panics if j < i.
NewSlice(i, j int64) Record
}我们依然可以使用Builder模式来创建一个arrow.Record,下面我们就来用Go代码创建[N]Archer这个Record Batch:
// record_batch.go
func main() {
schema := arrow.NewSchema(
[]arrow.Field{
{Name: "archer", Type: arrow.BinaryTypes.String},
{Name: "location", Type: arrow.BinaryTypes.String},
{Name: "year", Type: arrow.PrimitiveTypes.Int16},
},
nil,
)
rb := array.NewRecordBuilder(memory.DefaultAllocator, schema)
defer rb.Release()
rb.Field(0).(*array.StringBuilder).AppendValues([]string{"tony", "amy", "jim"}, nil)
rb.Field(1).(*array.StringBuilder).AppendValues([]string{"beijing", "shanghai", "chengdu"}, nil)
rb.Field(2).(*array.Int16Builder).AppendValues([]int16{1992, 1993, 1994}, nil)
rec := rb.NewRecord()
defer rec.Release()
fmt.Println(rec)
}运行上述示例,输出如下:
$go run record_batch.go
record:
schema:
fields: 3
- archer: type=utf8
- location: type=utf8
- year: type=int16
rows: 3
col[0][archer]: ["tony" "amy" "jim"]
col[1][location]: ["beijing" "shanghai" "chengdu"]
col[2][year]: [1992 1993 1994]在这个示例里,我们看到了一个名为Schema的概念,并且NewRecordBuilder创建时需要传入一个arrow.Schema的实例。和数据库表Schema类似,Arrow中的Schema也是一个元数据概念,它包含一系列作为“列”的字段的名称和类型信息。Schema不仅在Record Batch中使用,在后面的Table中,Schema也是必要元素。
arrow.Record可以通过NewSlice可以ZeroCopy方式共享Record Batch的内存数据,NewSlice会创建一个新的Record Batch,这个Record Batch中的Record与原Record是共享的:
// record_batch_slice.go
sl := rec.NewSlice(0, 2)
fmt.Println(sl)
cols := sl.Columns()
a1 := cols[0]
fmt.Println(a1)新的sl取了rec的前两个record,输出sl得到如下结果:
record:
schema:
fields: 3
- archer: type=utf8
- location: type=utf8
- year: type=int16
rows: 2
col[0][archer]: ["tony" "amy"]
col[1][location]: ["beijing" "shanghai"]
col[2][year]: [1992 1993]
["tony" "amy"]相同schema的record batch可以合并,我们只需要分配一个更大的Record Batch,然后将两个待合并的Record batch copy到新Record Batch中就可以了,但显然这样做的开销很大。
Arrow的一些实现中提供了Chunked Array的概念,可以更低开销的来完成某个列的array的追加。
注:Chunked array并不是Arrow Columnar Format的一部分。
2. Chunked Array
如果说Record Batch本质上是不同Array type的横向聚合,那么Chunked Array就是相同Array type的纵向聚合了,用Go语法表示就是:[N]Array或[]Array,即array of array。下面是一个Chunked Array的结构示意图:
 图片
图片
我们看到:Go的Chunked array的实现使用的是一个Array切片:
// github.com/apache/arrow/go/arrow/table.go
// Chunked manages a collection of primitives arrays as one logical large array.
type Chunked struct {
refCount int64 // refCount must be first in the struct for 64 bit alignment and sync/atomic (https://github.com/golang/go/issues/37262)
chunks []Array
length int
nulls int
dtype DataType
}按照Go切片的本质,Chunked Array中的各个元素Array间的实际内存buffer并不连续。并且正如示意图所示:每个Array的长度也并非是一样的。
注:在《Go语言第一课》[5]中的第15讲中有关于切片本质的深入系统的讲解。
我们可以使用arrow包提供的NewChunked函数创建一个Chunked Array,具体见下面源码:
// chunked_array.go
func main() {
ib := array.NewInt64Builder(memory.DefaultAllocator)
defer ib.Release()
ib.AppendValues([]int64{1, 2, 3, 4, 5}, nil)
i1 := ib.NewInt64Array()
defer i1.Release()
ib.AppendValues([]int64{6, 7}, nil)
i2 := ib.NewInt64Array()
defer i2.Release()
ib.AppendValues([]int64{8, 9, 10}, nil)
i3 := ib.NewInt64Array()
defer i3.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Int64,
[]arrow.Array{i1, i2, i3},
)
defer c.Release()
for _, arr := range c.Chunks() {
fmt.Println(arr)
}
fmt.Println("chunked length =", c.Len())
fmt.Println("chunked null count=", c.NullN())
}我们看到在Chunked Array聚合了多个arrow.Array实例,并且这些arrow.Array实例的长短可不一致,arrow.Chunked的Len()返回的则是Chunked中Array的长度之和。下面是示例程序的输出结果:
$go run chunked_array.go
[1 2 3 4 5]
[6 7]
[8 9 10]
chunked length = 10
chunked null count= 0这样来看,Chunked Array可以看成一个逻辑上的大Array。
好了,问题来了!Record Batch是用来聚合等长array type的,那么是否有某种数据结构可以用来聚合等长的Chunked Array呢?答案是有的!下面我们就来看看这种结构:Table。
3. Table
Table和Chunked Array一样并不属于Arrow Columnar Format的一部分,最初只是Arrow的C++实现中的一个数据结构,Go Arrow的实现也提供了对Table的支持。
Table的结构示意图如下(图摘自《In-Memory Analytics with Apache Arrow》[6]一书):
 图片
图片
我们看到:和Record Batch的每列是一个array不同,Table的每一列为一个chunked array,所有列的chunked array的Length是相同的,但各个列的chunked array中的array的长度可以不同。
Table和Record Batch相似的地方是都有自己的Schema。
下面的示意图(来自这里[7])对Table和Chunked Array做了十分直观的对比:
 图片
图片
Record Batch是Arrow Columnar format中的一部分,所有语言的实现都支持Record Batch;但Table并非format spec的一部分,并非所有语言的实现对其都提供支持。
另外从图中看到,由于Table采用了Chunked Array作为列,chunked array下的各个array内部分布并不连续,这让Table在运行时丧失了一些局部性。
下面我们就使用Go arrow实现来创建一个table,这是一个3列、10行的table:
// table.go
func main() {
schema := arrow.NewSchema(
[]arrow.Field{
{Name: "col1", Type: arrow.PrimitiveTypes.Int32},
{Name: "col2", Type: arrow.PrimitiveTypes.Float64},
{Name: "col3", Type: arrow.BinaryTypes.String},
},
nil,
)
col1 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
ib := array.NewInt32Builder(memory.DefaultAllocator)
defer ib.Release()
ib.AppendValues([]int32{1, 2, 3}, nil)
i1 := ib.NewInt32Array()
defer i1.Release()
ib.AppendValues([]int32{4, 5, 6, 7, 8, 9, 10}, nil)
i2 := ib.NewInt32Array()
defer i2.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Int32,
[]arrow.Array{i1, i2},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(0), chunk)
}()
defer col1.Release()
col2 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
fb := array.NewFloat64Builder(memory.DefaultAllocator)
defer fb.Release()
fb.AppendValues([]float64{1.1, 2.2, 3.3, 4.4, 5.5}, nil)
f1 := fb.NewFloat64Array()
defer f1.Release()
fb.AppendValues([]float64{6.6, 7.7}, nil)
f2 := fb.NewFloat64Array()
defer f2.Release()
fb.AppendValues([]float64{8.8, 9.9, 10.0}, nil)
f3 := fb.NewFloat64Array()
defer f3.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Float64,
[]arrow.Array{f1, f2, f3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(1), chunk)
}()
defer col2.Release()
col3 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
sb := array.NewStringBuilder(memory.DefaultAllocator)
defer sb.Release()
sb.AppendValues([]string{"s1", "s2"}, nil)
s1 := sb.NewStringArray()
defer s1.Release()
sb.AppendValues([]string{"s3", "s4"}, nil)
s2 := sb.NewStringArray()
defer s2.Release()
sb.AppendValues([]string{"s5", "s6", "s7", "s8", "s9", "s10"}, nil)
s3 := sb.NewStringArray()
defer s3.Release()
c := arrow.NewChunked(
arrow.BinaryTypes.String,
[]arrow.Array{s1, s2, s3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(2), chunk)
}()
defer col3.Release()
var tbl arrow.Table
tbl = array.NewTable(schema, []arrow.Column{*col1, *col2, *col3}, -1)
defer tbl.Release()
dumpTable(tbl)
}
func dumpTable(tbl arrow.Table) {
s := tbl.Schema()
fmt.Println(s)
fmt.Println("------")
fmt.Println("the count of table columns=", tbl.NumCols())
fmt.Println("the count of table rows=", tbl.NumRows())
fmt.Println("------")
for i := 0; i < int(tbl.NumCols()); i++ {
col := tbl.Column(i)
fmt.Printf("arrays in column(%s):\n", col.Name())
chunk := col.Data()
for _, arr := range chunk.Chunks() {
fmt.Println(arr)
}
fmt.Println("------")
}
}我们看到:table创建之前,我们需要准备一个schema,以及各个column。每个column则是一个chunked array。
运行上述代码,我们得到如下结果:
$go run table.go
schema:
fields: 3
- col1: type=int32
- col2: type=float64
- col3: type=utf8
------
the count of table columns= 3
the count of table rows= 10
------
arrays in column(col1):
[1 2 3]
[4 5 6 7 8 9 10]
------
arrays in column(col2):
[1.1 2.2 3.3 4.4 5.5]
[6.6 7.7]
[8.8 9.9 10]
------
arrays in column(col3):
["s1" "s2"]
["s3" "s4"]
["s5" "s6" "s7" "s8" "s9" "s10"]
------table还支持schema变更,我们可以基于上述代码为table增加一列:
// table_schema_change.go
func main() {
schema := arrow.NewSchema(
[]arrow.Field{
{Name: "col1", Type: arrow.PrimitiveTypes.Int32},
{Name: "col2", Type: arrow.PrimitiveTypes.Float64},
{Name: "col3", Type: arrow.BinaryTypes.String},
},
nil,
)
col1 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
ib := array.NewInt32Builder(memory.DefaultAllocator)
defer ib.Release()
ib.AppendValues([]int32{1, 2, 3}, nil)
i1 := ib.NewInt32Array()
defer i1.Release()
ib.AppendValues([]int32{4, 5, 6, 7, 8, 9, 10}, nil)
i2 := ib.NewInt32Array()
defer i2.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Int32,
[]arrow.Array{i1, i2},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(0), chunk)
}()
defer col1.Release()
col2 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
fb := array.NewFloat64Builder(memory.DefaultAllocator)
defer fb.Release()
fb.AppendValues([]float64{1.1, 2.2, 3.3, 4.4, 5.5}, nil)
f1 := fb.NewFloat64Array()
defer f1.Release()
fb.AppendValues([]float64{6.6, 7.7}, nil)
f2 := fb.NewFloat64Array()
defer f2.Release()
fb.AppendValues([]float64{8.8, 9.9, 10.0}, nil)
f3 := fb.NewFloat64Array()
defer f3.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Float64,
[]arrow.Array{f1, f2, f3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(1), chunk)
}()
defer col2.Release()
col3 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
sb := array.NewStringBuilder(memory.DefaultAllocator)
defer sb.Release()
sb.AppendValues([]string{"s1", "s2"}, nil)
s1 := sb.NewStringArray()
defer s1.Release()
sb.AppendValues([]string{"s3", "s4"}, nil)
s2 := sb.NewStringArray()
defer s2.Release()
sb.AppendValues([]string{"s5", "s6", "s7", "s8", "s9", "s10"}, nil)
s3 := sb.NewStringArray()
defer s3.Release()
c := arrow.NewChunked(
arrow.BinaryTypes.String,
[]arrow.Array{s1, s2, s3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(2), chunk)
}()
defer col3.Release()
var tbl arrow.Table
tbl = array.NewTable(schema, []arrow.Column{*col1, *col2, *col3}, -1)
defer tbl.Release()
dumpTable(tbl)
col4 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
sb := array.NewStringBuilder(memory.DefaultAllocator)
defer sb.Release()
sb.AppendValues([]string{"ss1", "ss2"}, nil)
s1 := sb.NewStringArray()
defer s1.Release()
sb.AppendValues([]string{"ss3", "ss4", "ss5"}, nil)
s2 := sb.NewStringArray()
defer s2.Release()
sb.AppendValues([]string{"ss6", "ss7", "ss8", "ss9", "ss10"}, nil)
s3 := sb.NewStringArray()
defer s3.Release()
c := arrow.NewChunked(
arrow.BinaryTypes.String,
[]arrow.Array{s1, s2, s3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(arrow.Field{Name: "col4", Type: arrow.BinaryTypes.String}, chunk)
}()
defer col4.Release()
tbl, err := tbl.AddColumn(
3,
arrow.Field{Name: "col4", Type: arrow.BinaryTypes.String},
*col4,
)
if err != nil {
panic(err)
}
dumpTable(tbl)
}运行上述示例,输出如下:
$go run table_schema_change.go
schema:
fields: 3
- col1: type=int32
- col2: type=float64
- col3: type=utf8
------
the count of table columns= 3
the count of table rows= 10
------
arrays in column(col1):
[1 2 3]
[4 5 6 7 8 9 10]
------
arrays in column(col2):
[1.1 2.2 3.3 4.4 5.5]
[6.6 7.7]
[8.8 9.9 10]
------
arrays in column(col3):
["s1" "s2"]
["s3" "s4"]
["s5" "s6" "s7" "s8" "s9" "s10"]
------
schema:
fields: 4
- col1: type=int32
- col2: type=float64
- col3: type=utf8
- col4: type=utf8
------
the count of table columns= 4
the count of table rows= 10
------
arrays in column(col1):
[1 2 3]
[4 5 6 7 8 9 10]
------
arrays in column(col2):
[1.1 2.2 3.3 4.4 5.5]
[6.6 7.7]
[8.8 9.9 10]
------
arrays in column(col3):
["s1" "s2"]
["s3" "s4"]
["s5" "s6" "s7" "s8" "s9" "s10"]
------
arrays in column(col4):
["ss1" "ss2"]
["ss3" "ss4" "ss5"]
["ss6" "ss7" "ss8" "ss9" "ss10"]
------这种对schema变更操作的支持在实际开发中也是非常有用的。
4. 小结
本文讲解了基于array type的三个高级数据结构:Record Batch、Chunked Array和Table。其中Record Batch是Arrow Columnar Format中的结构,可以被所有实现arrow的编程语言所支持;Chunked Array和Table则是在一些编程语言的实现中创建的。
三个概念容易混淆,这里给出简单记法:
- Record Batch: schema + 长度相同的多个array
- Chunked Array: []array
- Table: schema + 总长度相同的多个Chunked Array
注:本文涉及的源代码在这里[8]可以下载。
5. 参考资料
- Apache Arrow Glossary[9] - https://arrow.apache.org/docs/format/Glossary.html
- 参考资料
- [1] 《Arrow数据类型》: https://tonybai.com/2023/06/25/a-guide-of-using-apache-arrow-for-gopher-part1
- [2] 《Arrow Go实现的内存管理》: https://tonybai.com/2023/06/30/a-guide-of-using-apache-arrow-for-gopher-part2
- [3] Record Batch: https://arrow.apache.org/docs/format/Glossary.html#term-record-batch
- [4] 《In-Memory Analytics with Apache Arrow》: https://book.douban.com/subject/35954154/
- [5] 《Go语言第一课》: http://gk.link/a/10AVZ
- [6] 《In-Memory Analytics with Apache Arrow》: https://book.douban.com/subject/35954154/
- [7] 这里: https://arrow.apache.org/docs/format/Glossary.html#term-table
- [8] 这里: https://github.com/bigwhite/experiments/blob/master/arrow/advanced-datastructure
- [9] Apache Arrow Glossary: https://arrow.apache.org/docs/format/Glossary.html
- [10] “Gopher部落”知识星球: https://wx.zsxq.com/dweb2/index/group/51284458844544
- [11] 链接地址: https://m.do.co/c/bff6eed92687