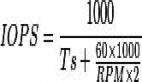一、湖仓系统 阿里云EMR湖仓系统

相较于传统的数仓、数据湖来讲,湖仓系统是一种新的数据管理系统。上图展示了阿里云EMR湖仓系统的整体架构,它是围绕着Delta Lake、Iceberg、Hudi等开源数据湖格式构建的,它同时具备数仓的高性能和数据湖的低成本、开放性。这些数据湖格式基于开源的Parquet和ORC构建,能够在AWS S3、阿里OSS等低成本存储系统上运行,它还具备ACID事务、批流一体以及Upsert等能力,可以对接多种商业或开源的查询计算引擎。这些能力使得湖仓体系逐步成为了一种趋势。
湖仓系统有一定的学习成本,比如合理配置、小文件、清理策略、性能调优等等。下面将从湖仓系统设计上入手,了解三种格式的差异。以Spark计算引擎为例,去分析读写计算过程中的一些主要的链路和影响性能的关键点。
二、核心设计
Delta Lake、Iceberg、Hudi三个数据湖格式在功能、特性、支持程度上基本一致,但是在具体设计上各有利弊和权衡,这些设计形成了支撑湖格式特性的基石,下文将主要分析元数据、MOR读取这两块核心设计。
1、元数据
元数据由schema、配置、有效的数据文件列表三个主要部分构成。传统数仓系统有单独服务来管理原数据和事务,三个数据湖格式都是将自己的元数据以自定义的数据结构持久化到了文件系统中,放置在表的路径下,但又和表数据分开存储。Hive表路径或分区路径下的所有数据文件都是有效的,而数据湖格式引入了多版本的概念,所以当前版本的有效数据文件列表需要从元数据中挑选出来。三个湖格式都封装了自身元数据的加载和更新的能力,这些可以方便的嵌入到不同的引擎,由各个引擎Plan和Execute自己的查询。
以Spark为例来看看Delta Lake的元数据设计,它的元数据算是三个系统中最简洁的:每次对Delta Lake的写操作,或者添加字段等DDL操作,会生成一个新版本的json deltalog文件,这里面会记录元数据的变更,包含一些schema的配置和file的信息,多次commit之后,会自动产生一个checkpoint的parquet文件,这个parquet文件会包括前面所有版本的元数据信息,用于优化查询加载。

Delta Lake元数据加载流程:
- 定位最新的checkp元数据文件
- List后面的delta log json文件
- 按版本号依次解析,得到表的schema、配置和有效数据文件列表
Iceberg也有一个统一的元数据集,与Delta Lake不同的是,Iceberg是三层的架构。

其中metadata文件很像Delta Lake的checkpoint文件,包含了全部的信息,但是不同的是,metadata文件还包括了前几个快照的信息,并且Iceberg是三层架构,其manifest file能够对局部的数据文件做统计信息收集,因此也能用于分区之下、文件之上的裁剪。
Iceberg元数据加载流程:
- 定位到当前metadata文件,得到表的schema和配置,和当前数据文件快照snapshot的manifest list文件
- 解析manifest list文件,得到一组manifest文件
- 解析manifest文件,得到有效数据文件列表
Hudi和前面两个很不一样,其一是它没有统一的元数据结构,其二Hudi会对数据文件进行分组,并对文件名进行编码,这是Hudi特有的file group概念。Hudi的数据必须有主键,主键可以映射到一个file group,后续对于这些主键所有的更新,都会写到这个file group,直到显式的调用修改表的文件布局。也就是说,一个file group随着多次的commit,会产生多个版本。获取当前有效数据文件列表时,会先列出当前分区下的所有文件,按照file group分组,取出每个group的最新文件,再按照timeline筛选掉已经被删除的group,最后得到一个有效的文件列表。

Hudi元数据加载流程:
- 解析hoodie.Properties
得到表的schema和配置
- 获取有效文件列表
- 未开启metadata:List filesystem + timeline
- 开启metadata:读取metadata表
Delta Lake、Iceberg、Hude元数据对比如下:
2、Merge-On-Read(MOR)
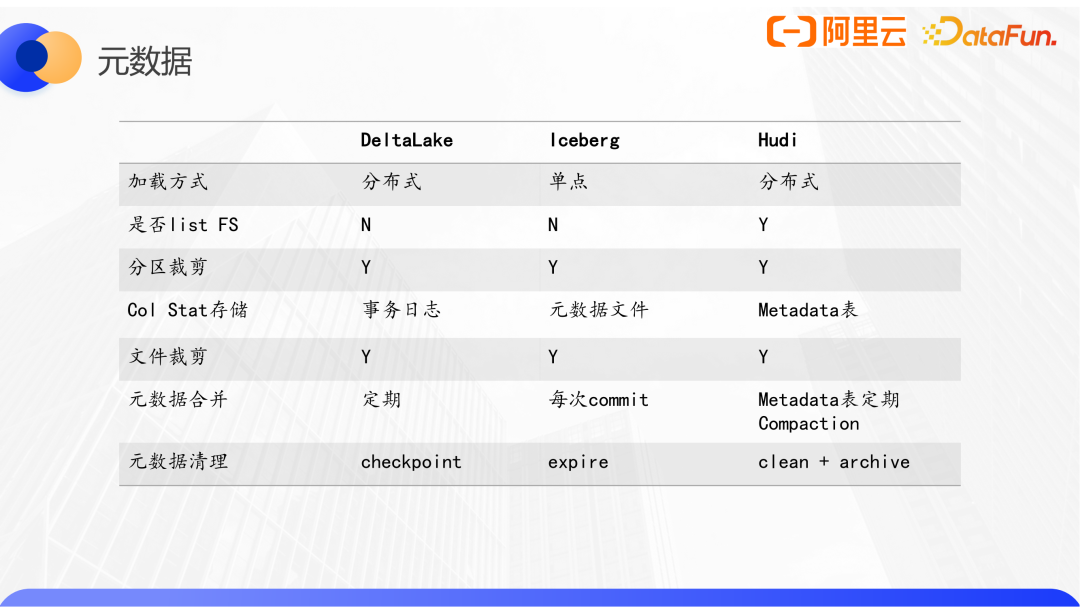
在一般情况下,在更新一个Copy-On-Write表时,即使我们只想执行一条更新操作,也需要将所有涉及到的数据文件加载进来,然后应用更新表达式,再将所有数据一起写出,这里就包含一些没有更新的数据,这就是写放大的现象。为了解决写放大现象,三个数据湖格式中Hudi第一个实现了Merge-On-Read表。
MOR的设计思想是,只持久化需要写出的数据,再通过某种方式标识出来,原来的数据文件里的数据成为过期数据,读的时候进行合并;为了提高效率,会定期进行合并(Compaction),通常是按照Copy-On-Write的方式写一遍。不同的MOR实现的写入、合并策略会有所不同。
Hudi定义了一个filegroup概念,每个group包括最多1个原始数据文件和多个日志文件,数据文件运行不存在。
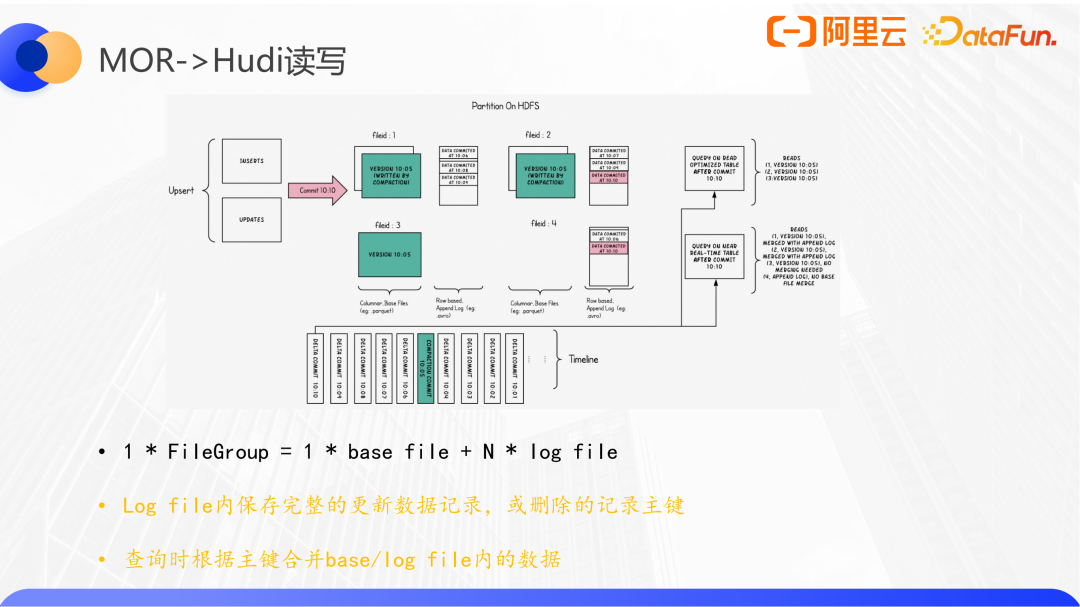
数据通过主键映射到filegroup,如果更新数据将会追加写到映射到filegroup内的日志文件,如果是删除,则只需要做一个主键记录,在合并的时候,首先读取原始的数据,然后按照这部分数据的主键去判断在增量日志中有没有相关的记录,如果存在就做合并。
Delta Lake通过Deletion Vector的设计解决写放大的问题。Delta Lake将需要更新、删除的数据在原数据文件中的offset标识出来,写入一个辅助文件。Iceberg V2表有两个MOR的实现,其中基于position的设计和Delta Lake的DV是基本一样,仅在具体实现上有些区别。DV的写入仅两步:1)根据update或者delete的condition,找到文件中匹配的记录,记录他们在文件中的offset。持久化到一个bin文件中;2)将更新后的数据,写到普通的一个新文件中。
相较于Hudi允许存在多个日志文件, Delta Lake在查询性能做了权衡,一个普通数据文件只允许伴随至多一个DV文件,当对一个已存在DV文件的数据文件再做一个更新的时候,最终写出时会把两个DV合并的。由于DV文件中offset信息是通过位图(RoaringBitMap)来保存的,合并操作是比较高效的。另外Hudi是将更新的数据也写入日志文件,Delta Lake是直接写入普通的parquet文件,然后在bin文件中做一个标记。以及hudi日志文件是行存格式,Delta Lake的DV采用自定义的格式,而数据使用的parquet的列存。

Delta Lake在DV下的查询方式我们可以直接看LogicalPlan,会更加清晰,即将原本的DeltaScan转换成Project + Filter + Delta Scan的组合。在Parquet Scan某个数据文件时,追加了_skip_row的辅助字段,上层应用_skip_row = false的过滤,然后通过Project的投影保证仅了无辅助字段的额外输出。
显然核心就是_skip_row的标记,DeltaLake自定义了ParquetFileFormat,在读取parquet文件后,对每个数据判断roaringBitMap是否包含该offset,有标记为true,没有就是false。这样就完成了Deletion Vector模式下DeltaLake表的查询。
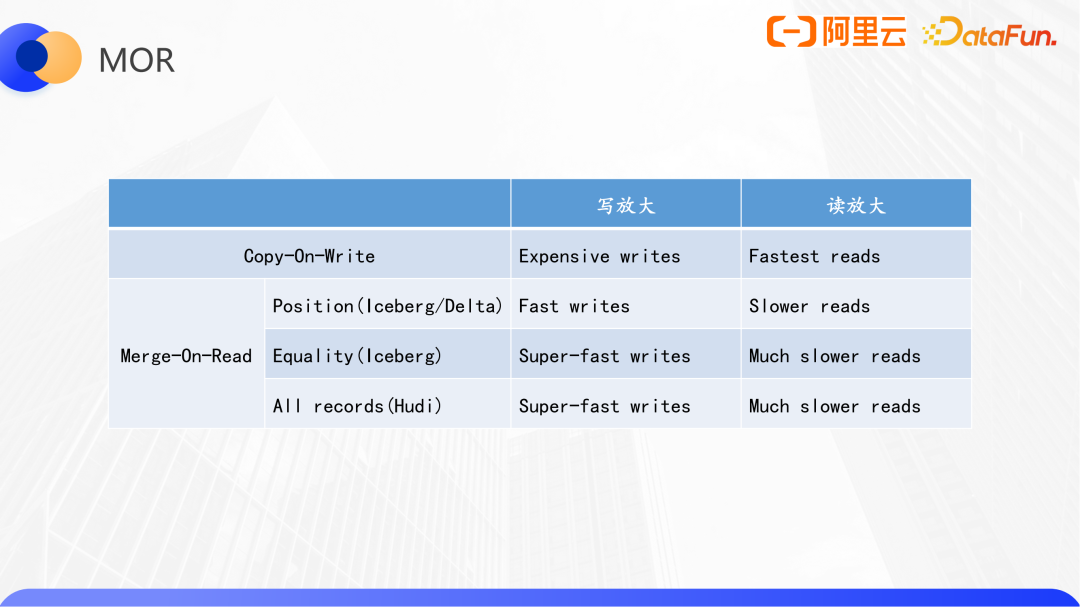
Delta Lake、Hudi、Iceberg的MOR实现对比:
基于offset或者position的MOR实现,由于会通过扫描文件来确定位置,因此写性能上会慢于iceberg的equality或hudi mor的实现,而由于该方案不需要类似hash join的读时合并策略,查询性能会好一些。
三、性能优化
1、查询
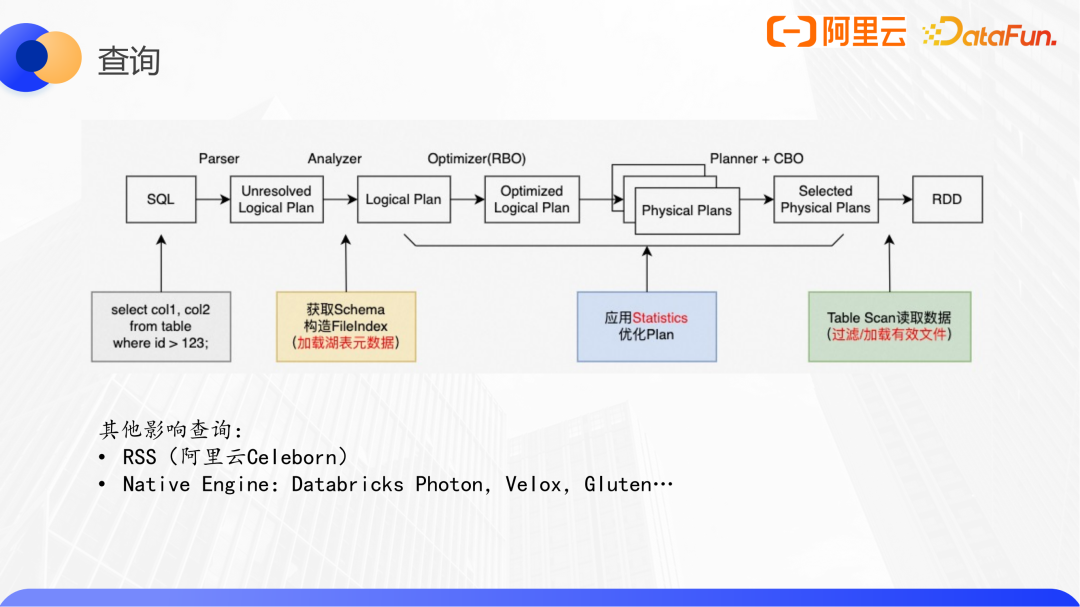
以Spark为例,一个完整的query链路如下:
其中与数据湖相关的有三点:元数据加载、优化plan、Table Scan。
(1)元数据加载
元数据加载包括获取schema、构造fileindex等,分为单点加载和分布式加载两种。单点加载的代表有Iceberg、Delta Lake-Standalone,适用于小表,有内存压力。分布式加载的实现有Hudi、Delta Lake,适用于大表,需提交Spark Job。
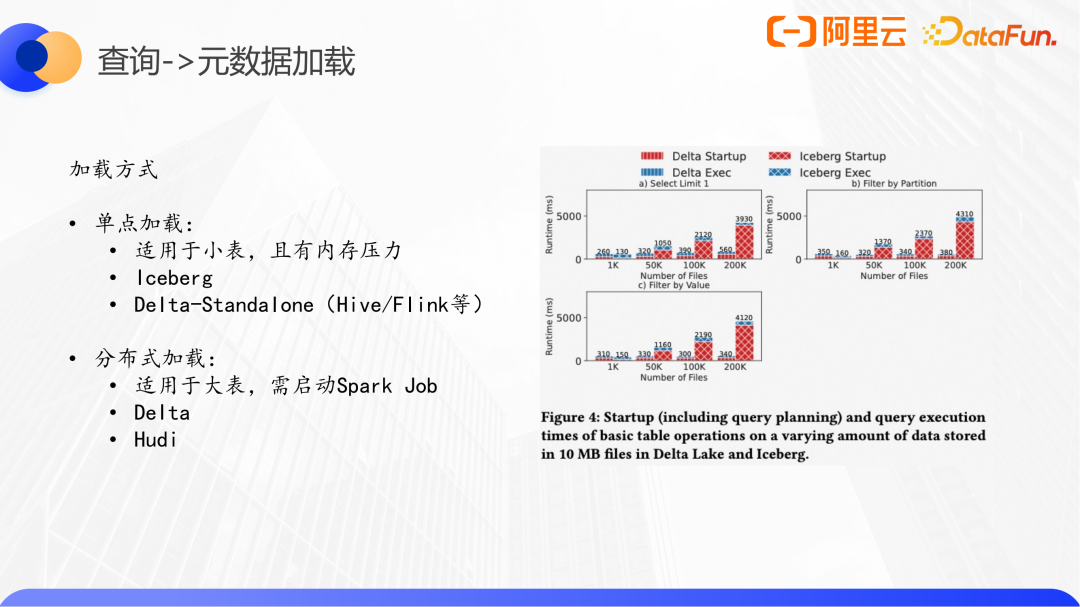
这里我们给出LHBench做了一个测试结果:使用的是TPC-H的store-sales表,设置的filesize都是10MB,单个图表内表的文件数量从1千到20W,三个图表对应的仅读取一行,读取一个分区,和普通字段作为过滤条件的三个场景。从趋势上三个场景是一致的。我们分析第一个,最左侧小表Iceberg的单点模式要稍好些,但与Delta Lake的分布式元数据加载差距不大。最右侧单点方式整个Query的执行时间中蓝色执行部分基本一致,很明显被红色startup部分限制,这部分在plan是一致的情况下可等同于元数据加载的时间。可见,如何智能的选择合适的加载模式,是一个可选的优化方向。
以下是两个EMR的优化案例。
案例1:EMR Manifest,是一个无服务化的优化元数据加载方案。
阿里云EMR一客户的核心ODS表,通过Spark Streaming写入Delta Lake,每天增量数据3TB,目前全表2.2PB,1500万个数据文件,仅元数据10GB。在正常情况下使用Hive/Presto查询,使用的Delta-Standalone的单机加载方式,会完全卡住或者需要超高内存。

该优化方案是将数据文件的元数据按照分区结构提前持久化到一个manifest文件,同时记录manifest的元数据版本。在用户查询的时候,根据filter做分区裁剪,直接去读分区下面的manifest文件,解析出本次查询的有效数据文件,跳过了所有元数据加载的步骤。如果emr_manifest的版本有滞后,我们也会拿到滞后的元数据,合并得到正确的数据快照。另外manifest文件中还会保存一些size、stats这些信息,会应用于一些文件级别的data-skipping优化。该方案在该表体量仅为300TB时提供,当时需要10GB内存90s加载完整的元数据,优化后可以实现秒级返回,且内存不需要额外调整。
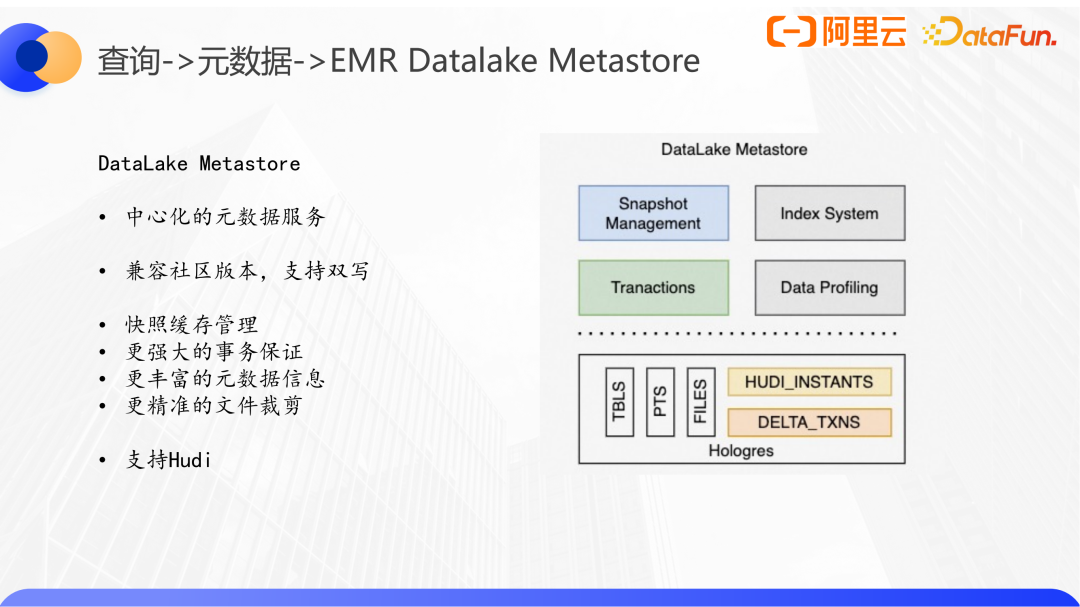
案例2:EMR DataLake Metastore,有服务的中心化的优化元数据加载方案。
这里不得不和HMS做一个对比,HMS仅存储表的分区级信息,查询普通表时根据分区位置去list路径,拿到有效的数据文件列表。而数据湖格式具备多版本概念,所以针对湖格式的Metastore设计必须到文件级别。另外Hudi、Iceberg基于分布式锁来实现事务性,而Delta则是基于所在文件系统的原子性和持久性,在某些场景下无法提供更强的一致性保障,这也是我们实现DataLake Metastore的另外一个原因。
EMR DataLake Metastore目前已经支持了Hudi格式,完全兼容社区版本和元数据协议,同时支持元数据双写。在提供了文件快照和事务的同时,后续也将继续拓展data profiling和行级索引为查询提供更精准的裁剪优化。
(2)优化plan
数据湖的第二点优化是plan优化,在前面的Spark查询例子里,调用Spark sql内核结合各种的状态统计信息去优化logic plan。比如根据运行时的一些统计信息,通过AQE去改变join的方式,基于表的静态信息和一些cost模型来优化的CBO等。
统计信息只有表级别和column级别两类,其中表级别有statistics信息包括bytes、rows等信息,字段级别有min、max等。
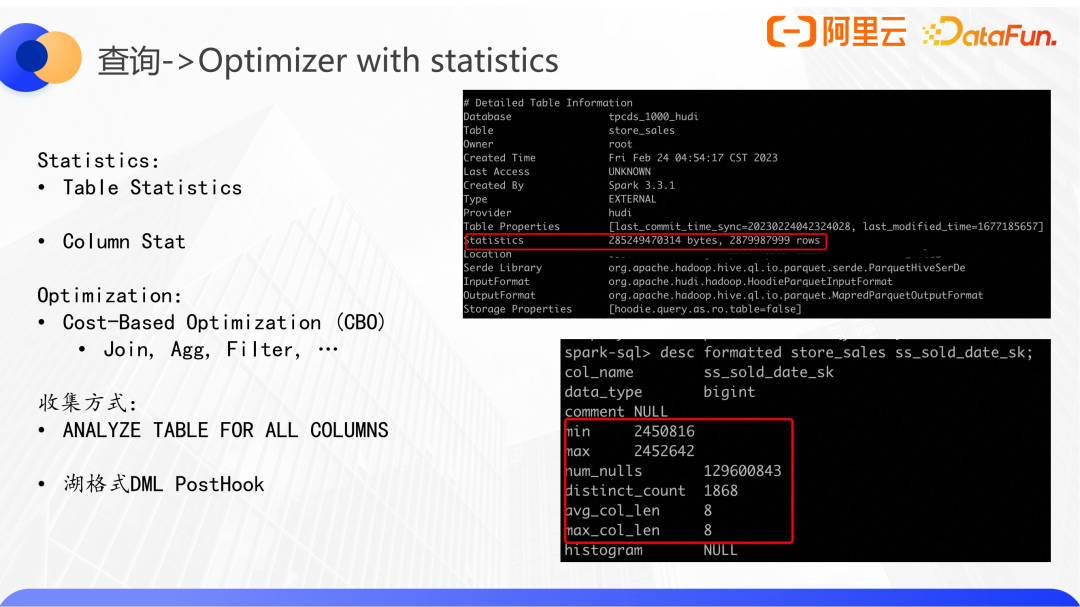
对于一个简单的join,仅使用表级别的rowcount信息就能够去调整join顺序,使得整体的plan过程中需要join的数据量达到最少。但是如果sql带有aggregate或者filter,就需要结合列的信息去估算整个scan的cost。
关于通过统计指标来优化查询,有几下几点思考:
- 如何更好的利用statistics来优化查询。比如Delta Lake中count整表的sql可以直接通过元数据层面的统计信息得到count值,将原本的aggregate操作转换成LocalRelation,避免Scan全表。
- 如何高效收集/实时更新statistics。
- 如何打通湖格式自身和Spark需要的statistics。spark会从table properties获取统计信息,而一般情况湖格式的统计信息都是记录到自己的元数据中,这部分需要更好的打通和复用。
(3)Table Scan
在完整Logical Plan的优化并转化为Phyiscal Plan后,下一步就要执行具体的数据文件读取,即Table Scan阶段。
这里小文件对查询的影响是大家所熟悉的。三个湖格式都提供了相应的合并小文件的功能,关键问题其一是目标文件设置多大是合适的,其二合并操作执行的时机和方式,这点我们后续再展开。默认情况下parquet在各引擎都是128M左右,但这是否是最优的还要看表的整体规模。过多的文件,将会导致元数据规模变大,影响元数据的读写,databricks和阿里云emr都提供了自动调教file size的功能。这里给出databricks的设置文件大小和表规模的映射关系。为了控制元数据的规模,对于10TB的表建议文件大小设置为1G。

在得到表的全部有效数据文件后,我们还是要根据查询条件来尽可能的进行裁剪,以减少最终读取Parquet或者ORC文件的体量。Table scan优化分为两类:一是元数据裁剪,二是行级索引。元数据裁剪又可以分为分区裁剪、Manifest裁剪(Iceberg特有)、File裁剪等不同粒度。

三个数据湖格式都支持Z-Order和DataSkipping:先将min-max信息写到元数据当中,然后结合查询过滤条件去实现过滤。
针对点查,传统数据库更多是通过行级索引来实现。Databricks商业版Delta Lake支持BloomFilter,使用单独的目录文件,保存数据文件的索引信息;Hudi也支持Multi-Modal Index多模索引。EMR也计划在DataLake Metastore中嵌入Index System来支持点查加速。
最后就是实际的Reader来读取数据文件了。以Parquet为例,各引擎集成parquet之后,读写性能已经非常不错。但是有一些具体的湖格式场景会关闭一些优化参数,相关的比如谓词下推,向量化等。另外文件的压缩格式和压缩比也会影响文件的加载,以及目前一些Native框架支持的Native Parquet Reader(如Arrow,Presto,Velox等)。
2、写入
以一个带where条件的update SQL为例,首先要能找到匹配这些查询条件的所在的数据文件,然后加载文件,对匹配到的数据应用表达式完成更新,并最终写出。在完成提交后,也许还要执行一些表的table service,包括clean、checkpoint、compaction等。
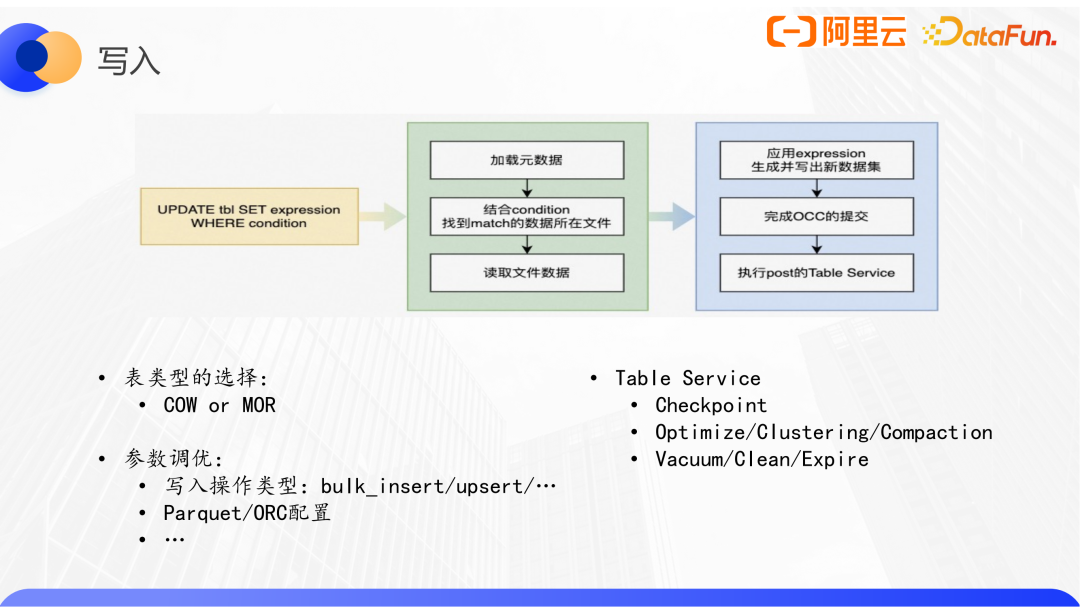
优化写操作,选择适合当前场景的表类型(如MOR表),并配置合适的参数。在湖格式场景下,这种后置的追加在湖格式写入后面的table service其实是逐渐成为了影响效率或者整体作业稳定性的关键性因素。要解决这样的问题,比较通用的做法就是拆成两个链路:一个链路就是正常写入,另外一个链路是用离线的方式通过调度一个作业来执行table service任务,包括像clean、Hudi表管理等等。
在阿里云EMR场景下,有些同时使用Flink和Spark引擎的客户,会采用Flink Hudi入湖和Spark离线管理的方案。另外EMR也提供了中心化的自动化湖表管理,是结合阿里云的DLF服务实现的。如图所示,湖格式自动将commit信息同步到DLF湖表服务,该服务将根据预定义的策略和实际表的状态及配置判断是否要产生湖表管理类的操作。

这里的核心其实是采取怎样的策略来更好的管理湖表。EMR目前上线了两大类5个策略。在同一类中,又设置优先级避免多条策略的命中而造成计算资源的浪费。举个例子,大多数入湖的表是以时间分区的,DLF湖表管理能够判断到新分区的到达,而在第一时间对已完成写入的分区执行小文件合并或者zorder的操作,以便快速提供这部分数据的高效查询。