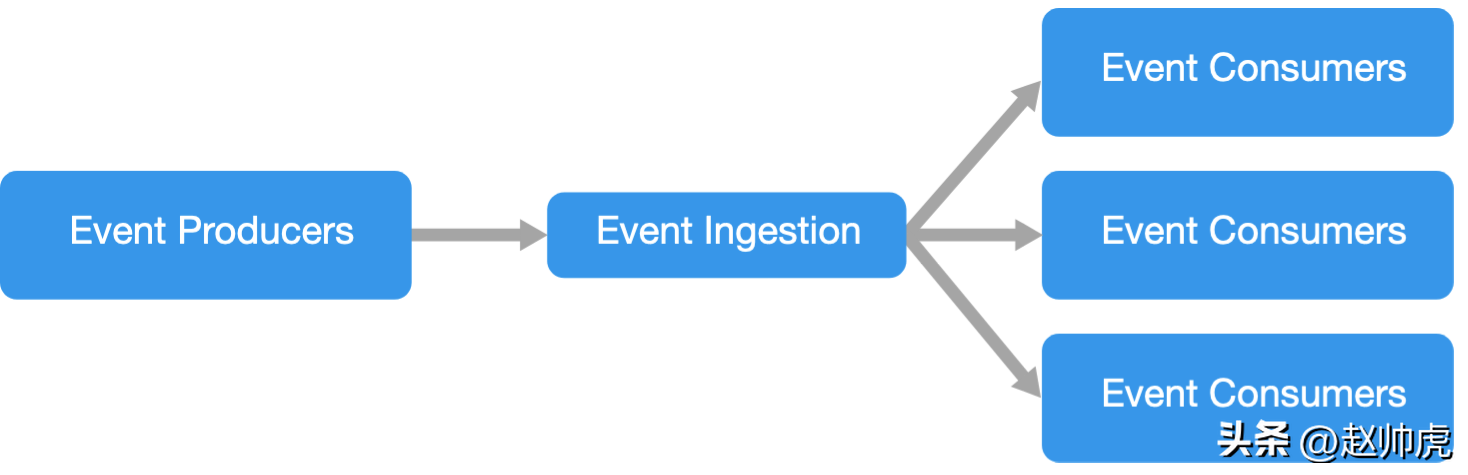
事件驱动架构是由生产者和消费者组成,生产者负责生产事件,消费者监听并消费事件。
事件驱动架构
事件分发以近实时的方式进行,所以当事件产生时,消费者可以立即做出应对。
- 生产者和消费者是解耦的,它不知道有哪些消费者在监听事件
- 消费者之间也是解耦的,每个消费者都可以读取所有事件。
还有一种模式,多个消费者是竞争的关系,它们从同一个队列消费,不出现错误的情况下每个事件都只被处理一次。
另外,在某些系统中,事件导入的吞吐量要求也很高,比如IoT系统。
事件驱动架构可以通过发布/订阅模型或事件流模型来实现:
- 发布/订阅模型:消息队列负责追踪订阅者,事件被发布后,消息队列负责发送给订阅者。一旦事件被接收,就不能再重放,新增的订阅者也看不到该事件。
- 事件流模型:将事件写入日志并持久存储下来,在单个分区里事件严格有序。client端不需要订阅这个事件流,而且能够从任意一个位置开始读取事件。当然,移动偏移量也要靠客户端自己完成。这意味着client可以在任意时间点加入,也支持事件重放。
在事件的消费上,也可以有一些略微不同的方式:
- 简单模式:事件产生后立刻触发消费者下一步的动作。比如风控、治理等场景下的异常行为检测。
- 复杂模式:消费者处理一组数据,找到其中的规律,比如基于时间窗口做聚合求sum/count/avg。
- 纯流式:通过流式平台比如Kafka作为数据中转的工具,接收事件并喂给下游的processor。下游的processor通常做简单的transform之后再写入的kafka。
事件通常来源于外部系统,比如IoT中的物理设备、互联网用户的端上。我们在设计时,必须认真评估总体的数据量和吞吐量,以保证系统能支撑这个量级。
在上面的流程图中,右侧的三个格子表示三种类型的消费者,每种类型的消费者下面有多个实例。在实际场景中,出于容灾的目的,多个消费者实例的情况非常普遍。为了保证事件处理的吞吐量,多个实例也是有必要的。
在处理事件时,一个消费者实例可以创建多个线程。这也能提高处理的吞吐量,不过事件被处理的顺序就乱了,业务上可能无法接受;另外多线程处理也很难保证exactly-once语义。
应用场景
- 多个子系统都需要处理这些事件
- 需要实时处理,且延迟越小越好
- 处理逻辑比较复杂的场景,比如要对事件继续模式匹配或者基于时间窗口的聚合
- 事件量级非常大,生产的速度也很快
架构优势
- 生产者和消费者解耦
- 没有点对点的集成,增加新消费者几乎没有难度
- 消费者可以即时处理到来的事件
- 天生分布式、可扩展性非常高
- 每个下游子系统都可以访问全部事件,且互相独立
有哪些挑战
- 不丢事件:一些业务场景要求,事件必须发送成功,不能丢。比如金融、电商等涉及钱的场景;
- 按顺序消费:由于架构的分布式特性,消费者本身就是多实例的,不支持全局有序消费;
- exactly-once消费:事件消费的每个环节都可能会失败,失败就会重试。重试的话,就需要额外的机制去保障exactly once
补充说明
在设计系统时,我们通常需要考虑单条消息的大小,它对系统的性能和金钱成本影响都非常大。如果走两个极端的话,可以是:
如果将所有需要的信息都放到单个事件里,处理起来会很方便,并且能够避免额外的信息查询。
如果将非常少的信息放到单个事件里,比如ID字段,那么会节省大量传输数据的时间和金钱成本,但其他信息需要访问其他服务才能获取到。
这其中的利益权衡,看自己的业务来定了。