













译者 | 崔皓
审校 | 重楼
摘要
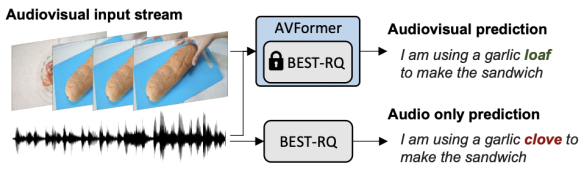
Google Research的研究科学家Arsha Nagrani和Paul Hongsuck Seo介绍了一种名为AVFormer的新技术,该技术将视觉理解能力注入现有的仅音频ASR模型中,以提高其在各种领域的泛化性能。AVFormer通过使用轻量级的可训练适配器,将视觉嵌入注入冻结的ASR模型中,这些适配器可以在少量弱标签视频数据上进行训练,额外的训练时间和参数最少。这种方法实现了零样本性能,即在未经手动注释的AV-ASR数据集上进行训练的情况下,实现了最先进的性能。

【编者:在机器学习和深度学习中,"冻结"一般指的是在训练过程中保持模型的某些部分或参数不变。这通常是通过禁止反向传播过程中对这些参数的更新来实现的。"冻结的语音模型"意味着这个语音识别模型在被用于新的视觉任务时,其参数保持不变,不会被进一步训练或调整。】
开篇
自动语音识别(ASR)是一项成熟的技术,广泛应用于各种应用,如电话会议、视频转录和语音命令。虽然这项技术的挑战主要集中在嘈杂的音频输入上,但多模态视频(例如,电视,在线编辑的视频)中的视觉流可以为提高ASR系统的鲁棒性提供强有力的线索,这就是所谓的音频视觉ASR(AV-ASR)。
【编者:"Zero-shot"是机器学习中的一个术语,通常用于描述一种特殊的训练和测试情况。在这种情况下,模型在没有看过任何特定类别的训练样本的情况下,被要求识别该类别的实例。这通常通过训练模型来理解和利用类别之间的某种结构或关系来实现。
例如,如果你有一个模型,它已经学会了识别猫和狗,然后你要求它识别一只兔子,尽管它从未在训练数据中见过兔子。如果模型能够正确地识别出兔子,那么我们就说它具有"零样本/零射击"的能力。
在这篇文章中,"Zero-Shot"是指模型在未经手动注释的AV-ASR数据集上进行训练的情况下,实现了最先进的性能。换句话说,模型能够处理和理解它在训练阶段从未见过的数据类型或情况。】
尽管唇动可以为语音识别提供强烈的信号,并且是AV-ASR最常关注的区域,但在野外的视频中,口部往往不直接可见(例如,由于以自我为中心的视点,面部覆盖物和低分辨率),因此,一个新兴的研究领域是无约束的AV-ASR(例如,AVATAR),它研究整个视觉帧的贡献,而不仅仅是口部区域。
然而,构建用于训练AV-ASR模型的音频视觉数据集是具有挑战性的。如How2和VisSpeech这样的数据集已经从在线教学视频中创建,但它们的规模较小。相比之下,模型本身通常很大,包含视觉和音频编码器,因此它们倾向于在这些小数据集上过度拟合。尽管如此,最近发布了一些大规模的仅音频模型,这些模型通过大规模训练在大量仅音频数据上进行了大量优化,这些数据来自音频书籍,如LibriLight和LibriSpeech。这些模型包含数十亿个参数,随时可用,并在各个领域显示出强大的泛化能力。
考虑到上述挑战,在“AVFormer:将视觉注入冻结的语音模型,实现零样本AV-ASR”中,我们提出了一种简单的方法,用视觉信息增强现有的大规模仅音频模型,同时进行轻量级的领域适应。AVFormer将视觉嵌入注入冻结的ASR模型(类似于Flamingo如何将视觉信息注入大型语言模型进行视觉-文本任务),使用轻量级可训练的适配器,这些适配器可以在少量弱标签视频数据上进行训练,额外的训练时间和参数最少。我们还引入了一个简单的课程方案,在训练过程中,我们发现使模型能够有效地处理音频和视觉信息至关重要。最终的AVFormer模型在三个不同的AV-ASR基准测试(How2,VisSpeech和Ego4D)上实现了最先进的零样本性能,同时也保持了在传统的仅音频语音识别基准测试(即LibriSpeech)上的良好性能。
使用轻量级模块注入视觉"
我们的目标是将视觉理解能力添加到现有的仅音频ASR模型中,同时保持其对各种领域(包括AV和仅音频领域)的泛化性能。
为了实现这一目标,我们将现有的最先进的ASR模型(Best-RQ)增强了以下两个组件:(i)线性视觉投影器和(ii)轻量级适配器。前者将视觉特征投影到音频令牌嵌入空间。这个过程使模型能够正确地连接单独预训练的视觉特征和音频输入令牌表示。然后,后者最小化地修改模型,以增加对来自视频的多模态输入的理解。然后,我们在HowTo100M数据集的未标记网络视频上,以及ASR模型的输出作为伪真实值,训练这些额外的模块,同时保持Best-RQ模型的其余部分冻结。这样的轻量级模块使得数据效率和性能的强大泛化成为可能。
我们在零样本设置中,在AV-ASR基准测试上评估了我们的扩展模型,其中模型从未在手动注释的AV-ASR数据集上进行过训练。
为视觉注入设置课程学习
在初步评估之后,我们经验性地发现,通过一轮简单的联合训练,模型很难一次性学习适配器和视觉投影器。为了解决这个问题,我们引入了一个两阶段的课程学习策略,该策略解耦了这两个因素——领域适应和视觉特征集成——并以顺序的方式训练网络。在第一阶段,优化适配器参数,完全不需要输入视觉令牌。一旦适配器被训练,我们在第二阶段添加视觉令牌,并单独训练视觉投影层,同时保持训练过的适配器冻结。
第一阶段专注于音频领域的适应。到了第二阶段,适配器完全冻结,视觉投影器只需学习生成视觉提示,将视觉令牌投影到音频空间。通过这种方式,我们的课程学习策略允许模型同时接纳视觉输入和适应AV-ASR基准测试中的新音频领域。我们只应用每个阶段一次,因为交替阶段的迭代应用会导致性能下降。
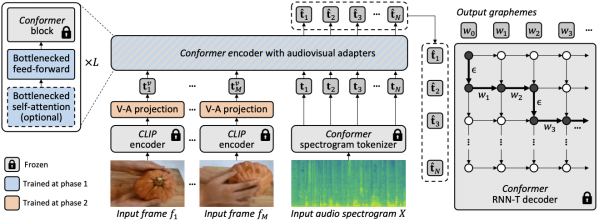
【编者:在第一阶段,他们优化了模型的"适配器"参数。适配器是模型的一部分,它的任务是帮助模型适应新的领域或任务。在这个阶段,他们并没有使用任何视觉信息,只是让模型更好地处理音频信息。
一旦适配器被训练好,他们进入了第二阶段。在这个阶段,他们开始添加视觉信息,并训练模型的"视觉投影器"部分。视觉投影器的任务是将视觉信息转换成模型可以理解的形式。在这个阶段,他们保持适配器的参数不变,只训练视觉投影器。
这种分阶段的训练策略允许模型逐步学习如何处理视觉和音频信息,而不是一次性地学习所有的东西。这样做的好处是,它可以防止模型在训练过程中出现性能下降的问题。】
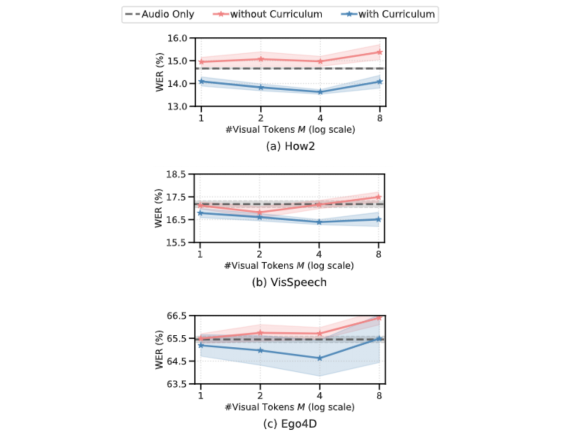
以下的图表显示,如果没有课程学习,我们的AV-ASR模型在所有数据集上都比仅音频的基线模型差,随着添加更多的视觉令牌,差距增大。相比之下,当应用了我们提出的两阶段课程时,我们的AV-ASR模型的性能明显优于基线的仅音频模型。
零样本AV-ASR的结果
我们将AVFormer与BEST-RQ(我们模型的音频版本)和AVATAR(AV-ASR的最新技术)进行比较,对三个AV-ASR基准测试:How2,VisSpeech和Ego4D的零样本性能进行比较。AVFormer在所有方面都超过了AVATAR和BEST-RQ,甚至在LibriSpeech和完整的HowTo100M集合上进行训练时,也超过了AVATAR和BEST-RQ。值得注意的是,对于BEST-RQ而言训练参数为600M,而AVFormer的训练参数是4M,因此只需要训练数据集的一小部分(HowTo100M的5%)就可以达到效果。此外,我们还在LibriSpeech上评估了性能,仅音频这一项,AVFormer就超过了两个基线。
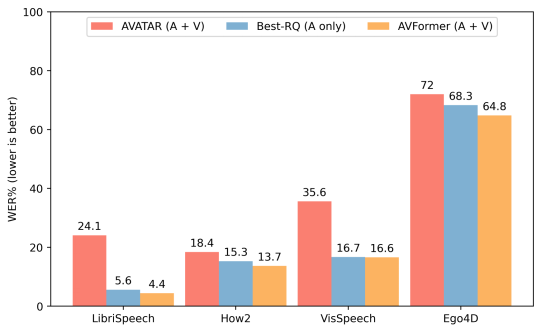
与不同AV-ASR数据集的零样本性能的最新方法进行比较。展示了在仅音频的LibriSpeech上的性能。结果显示WER%(越低越好)的报告。AVATAR和BEST-RQ在HowTo100M上进行了端到端的微调(所有参数),而AVFormer即使只使用了数据集的5%,也能有效工作,这得益于微调参数的小集合
结论
我们介绍了AVFormer,这是一种轻量级的方法,用于将现有的,冻结的最先进的ASR模型适应AV-ASR。我们的方法实用且高效,实现了令人印象深刻的零样本性能。随着ASR模型越来越大,调整预训练模型的整个参数集变得不切实际(对于不同的领域更是如此)。我们的方法无缝地实现了,在同一个参数有效的模型中进行领域转移和视觉输入混合。
译者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。
原文标题:AVFormer: Injecting vision into frozen speech models for zero-shot AV-ASR,作者:Arsha Nagrani,Paul Hongsuck Seo




























