一、背景与行业现状
1、数据湖理解的几个误区

现在很多企业都对数据湖存在一些误区,从上图左侧对数据湖的不同定义(红色字体标识)可以看出,数据湖并不像大家想象的那样。误区主要分为以下三种:第一种认为数据湖仅用来进行海量的存储;第二种认为数据湖是用来处理非结构数据的,不处理结构化数据;第三种认为数据湖仅可以用来做贴源层,不能建数仓。
我们从数据湖所承载的大数据平台技术上看,它除了存储之外,还具备批量计算、实时计算、交互式分析、机器学习等多种能力。所以基于以上大家对数据湖的理解来使用数据湖是限制了它的数据处理加工能力和使用范围,同时也提高了建设成本。
2、当前数据湖在数据处理的几种用法—数据湖能力并未充分利用
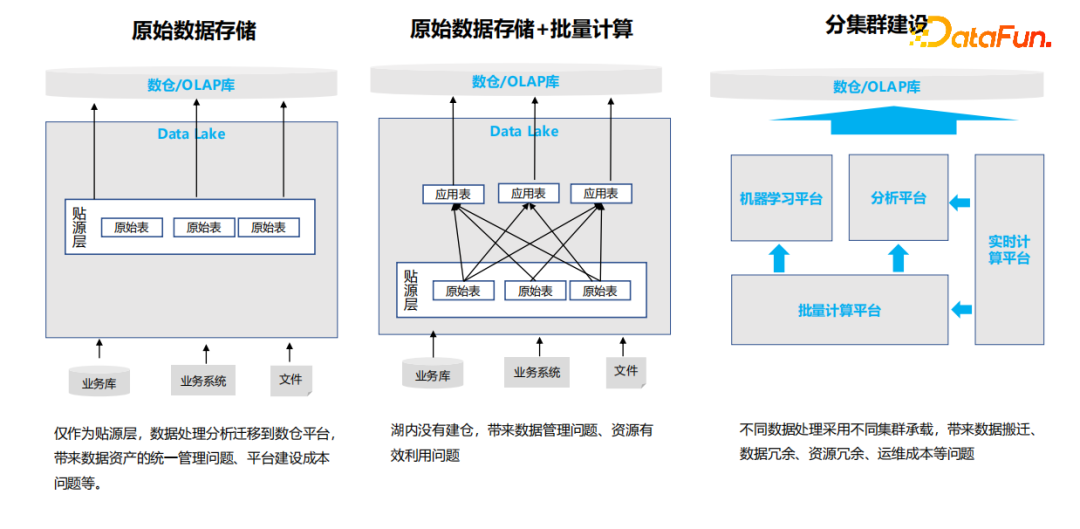
下面是几种常见的数据湖用法,但是这几种用法都没有把数据湖的能力完全发挥出来。
(1)数据湖做原始数据存储
数据湖作为一个贴源层,从业务数据库将原始数据导入到数据湖中存储起来,在用数环节需要将数据再导出到传统数仓或者其他查询库中,整个过程只是用了数据湖的存储能力。
(2)数据湖做原始数据存储+批量计算
第二种在上面的基础上增加了批量计算,基于贴源层写很多大表关联、多表关联,生成应用表,然后把应用表抽到分析仓库、数据仓库中。这种用法也没有把数据湖的全部能力用出来。
(3)数据湖分集群建设
第三种是分集群建设,把大数据平台真正的能力都用出来了,但是在集群规划部署的时候,按照不同负载建设了不同的集群,比如:创建一个批量集群、一个分析集群,一个实时计算集群。分集群建设的理念认为各种不同的负载会导致相互之间影响,为了保证负载和业务的SLA能够达到要求,就分开进行建设。其实大数据集群具有很好的资源隔离能力,分集群建设会导致资源浪费,数据共享难、数据存储冗余、运维成本高等问题。
这几种用法都没有真正发挥出数据湖的价值,只是用了它的一个方面。第三种用法比较典型,很多企业从组织架构上就会设置一个批量计算组、实时计算组,通常建设的集群也是两个。这样会造成集群资源冗余和数据重复考拷贝,增加了很多数据迁移和开发成本,以及底层资源的消耗。
3、Lakehouse相比于数据库、数据湖、数据仓库具备的能力介绍

针对以上使用数据湖存在的问题,我们对比一下数据平台发展过程中经历的几个阶段。
(1)第一个阶段是数据库
不管是从业务的角度还是从技术栈角度,大家对数据库都是最熟的。
(2)第二阶段是数据仓库
当数据库的整体能力达不到我们的存储要求之后,就出现了数据仓库。数据仓库定位也是偏OLAP。它把数据的存储的能力通过分布式的方式去加大,计算能力也相应增加了上去。在有些特性和用法上是非常相似的。
(3)第三阶段是数据湖
数据湖在存储规模和计算能力上进一步加大,整个集群规模可以上万台,整体的能力会有更大的提升,同时扩容更加平滑。另外它增加了很多数据库和数仓不具备的能力,比如实时计算、机器学习。它也会有一些弱势,比如相对前面两个它的交互式分析能力会弱一些。
(4)第四阶段是Lakehouse

数据湖得到广泛应用之后,在数据湖上承载的业务越来越多,这个时候就会发现数据湖的能力不具备支持更多的应用场景,比如:数据操作的事务能力、数据更新的能力,流数据与批量数据的共享、交互查询能力性能等。但是我们又不希望构建多个平台,我们希望一个平台能够承载所有业务,这时Lakehouse架构应运而生。Lakehouse在数据湖上叠加了一些数仓的能力,并且做了非常大的延伸,使一些数仓的能力在数据湖上构建起来。
左边图是Databricks发布的对Lakehouse技术体系的整体设想和架构,我们可以看到Lakehouse在事务性、数据更新能力和实时处理上都得到了非常大的提升,满足了我们对更多业务场景的需要,通过一个统一的平台解决不同业务场景的数据加工的需求。
4、Lakehouse架构使得实时计算进入流批一体阶段
实时计算有三种不同的架构,分别是Lambda实时架构、基于OLAP库的实时架构和基于Lakehouse的流批一体架构。
(1)Lambda实时架构
这种架构是Strom和Flink实时计算组件出现后广泛采用的架构,最大的特点就是批量与实时是存储和计算分开的两套架构,因此在集群建设和开发团队组建上也出现了分开建设的情况,这样就导致了流批数据共享问题、数据一致性问题和运维问题等。同时早期流式计算的计算模型也相对比较简单,承担数据业务场景多聚焦于实时监控和风控等场景,对原有的批量业务没有太大的增强。
(2)基于OLAP库的实时架构
这种架构其实是对Lambda架构的增强,Lambda架构计算的结果要写入到数据库或者数据仓库,以实现快速用数的需求,然后传统数据库或者数据仓库在实时性上都达不到要求,因此该架构主要也是改善这个问题,可实现大量数据的实时写入,大量数据存储以及实时查询的需求。
但是Lambda架构存在的问题,在该种架构中是依然存在的,比如:批量数据与实时数据共享问题,批和流的数据相互引用还是比较不方便的,都是异步的或者是定时、周期的,相互之间使用同步的方式去做,本质上批和流还是两套东西。同时行业内也将这种架构称为实时数仓,其实严格来说不完全具备实时数仓的能力,实时数仓处理具备实时写入和实时查询之外,还要具备在数仓分层存储架构,尤其是分层之间的数据流转也要具备实时性,目前该种架构的产品还不具备该能力。
(3)基于Lakehouse的流批一体架构
Lakehouse这种技术出来以后,尤其是以Hudi为代表的组件,提供了增量计算的能力。基于Lakehouse架构去做流批一体能够在数据进行加工处理的时候支持连续实时的计算。
基于实时的仓库,在Lakehouse里面可以做实时分层的数据加工。在分层内做完加工后的数据和批量的数据是一体的。比如同样一张表可以实时读或批量读;同样一张表可以实时写,也可以批量写,做到了批量数据和实时数据的统一存储。在某些场景下,也可以做到计算引擎的一体化和数据处理代码一体化。比如基于Flink SQL去做流式加工,在批量的时候也可以复用Flink SQL的代码,它的SQL 逻辑是完全一样的,可能只是改变一个参数来切换它的运行模式是流还是批,做到完全的代码一体。
在这三种实时计算的架构中,目前我觉得Lakehouse应该会是实时架构的一个大的趋势。
二、基于Lakehouse湖内建仓参考架构
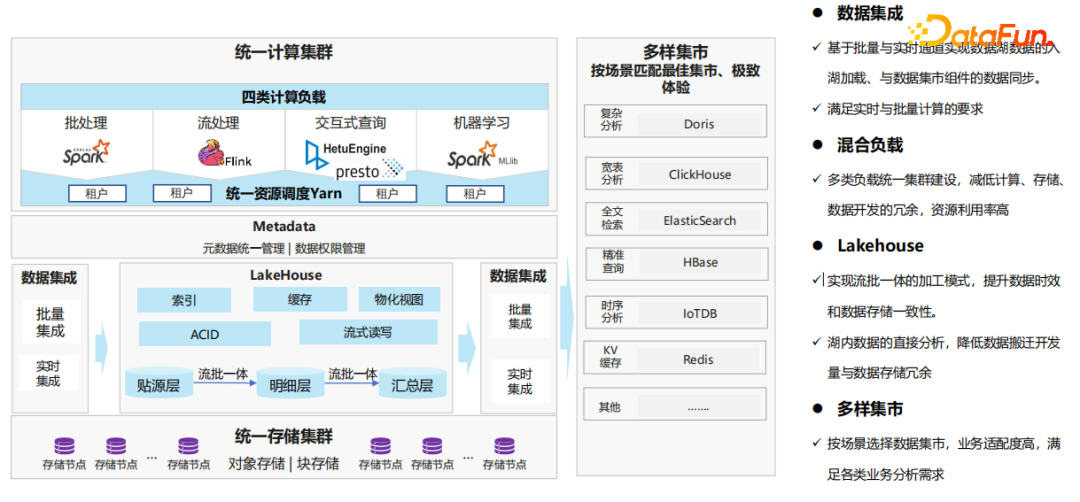
下面介绍基于Lakehouse湖内建仓参考架构。
1、统一的计算集群层

首先我们要把数据湖不同计算负载的能力用起来,在同一个集群实现批处理、流处理、交互式查询和机器学习,避免多集群建设的带来的运维成本和资源成本增加。数据湖可以按租户把资源隔离开,租户使用不同的资源池跑自己的作业,相互之间是不受影响的。这样就可以避免出现资源负载互相影响或者业务SLA的问题,所以可以通过统一的集群去构建多类负载的能力。
2、统一的元数据和权限管理层
基于数据湖构建统一的数据平台,提供了统一的元数据管理和数据权限管理。原来分集群建设,导致元数据和用户账号不统一,在数据和权限管理上也带来很大麻烦。如果统一元数据和账号体系的管理,就能更方便的做统一的数据管理和权限管理。
3、数据集成层
在数据入湖和出湖的时候,需要有一个比较好的数据集成平台。虽然有很多开源的组件可以实现,但是开源实现和商业版本相比,在稳定性和资源消耗上是存在短板的。所以不同的商业公司,包括各家云厂商都有数据集成的产品,在一键处理能力以及对资源消耗上都做了非常大的优化。
4、Lakehouse层
基于Lakehouse构建数据仓库,比如贴源层、明细层、汇总层。不同的企业根据自己的数据治理规范要求建设自身需要的分层体系。建完分层以后,各层之间的数据流转都是流批一体的,可以做大数据量的批量处理,也可以做增量的流式处理。在整个数据接入过程当中遵循ELT的理念,在接入的时候不做业务逻辑的处理,加载以后再做处理。Lakehouse架构提供事务的能力、数据更新的能力和流式读写的能力,以及查询性能提升的能力,比如索引能力、物化视图等能力。
5、统一存储集群层
底层存储采用统一的对象存储或分布式的块存储来解决海量数据存储的问题。
6、多样集市层
在整个架构里面,即使实现了数据的快速的消费,每个集市组件都有自己一定的适配场景,因此需要根据自身业务的技术要求选用合适的组件。单一一个组件很难满足所有的数据业务要求,因此集市层建设组件可以多样化。
现在有很多快速查的组件,比如Doris、ClickHouse、HBase、Redis、IotDB等。可以结合业务场景要求把结果数据同步到集市层组件,这样在业务场景中的适配度会比较高。比如要做千亿级别的,甚至字段能达到几千列的,那么使用ClickHouse的效果就会非常好,时序数据分析采用IotDB。基于传统数据仓库或者数据湖是没有办法达到这么高的性能。
我们认为整体的参考架构要把数据湖的能力全面地应用起来,解决大粒度的批流数据的加工处理。同时在数据消费的时候,根据具体场景,选用不同的组件来满足个性化的要求。而且经过统一的建设之后,整体建设成本大幅下降,很多资源冗余、数据冗余、开发的冗余也会大大降低。
三、湖内建仓典型场景方案介绍
下面列举几个在湖内建仓的典型场景。
1、实时数据湖典型场景:流批一体加工模式,批量数据与实时数据共享
在Lakehouse做流批一体加工的时候,有几种比较典型的加工模型:
(1)流式加工模式
所有的表都存在数据湖,基于Flink引擎/Spark引擎实现流式数据加工,把数据流式的写入到湖里的表,源表数据与目标表数据都可以长持久化存储。
(2)增量批加工模式
增量批处理是基于Hive和SparkSQL实现增量的批读数据。其处理语法逻辑与传统Hive和SparkSQL基本保持一致。增量批将全量批转化小表处理,性能高,资源消耗低,也避免了出现集群资源集中上涨的情况。
(3)全量批加工模式
基于Hudi的镜像读模式,实现数据全量读取。保持分区裁剪等数据过滤能力。语法逻辑与传统批量作业保持一致、原有批量作业可以直接搬迁。
其实上面这几种作业的SQL逻辑都是一样的,只是在有些参数和特定场景的处理上会有稍许的不同。批量加工和流式加工的数据是共用的。
2、数据加工—数据分层模型提升数据复用率、降低资源消耗、提升计算性能
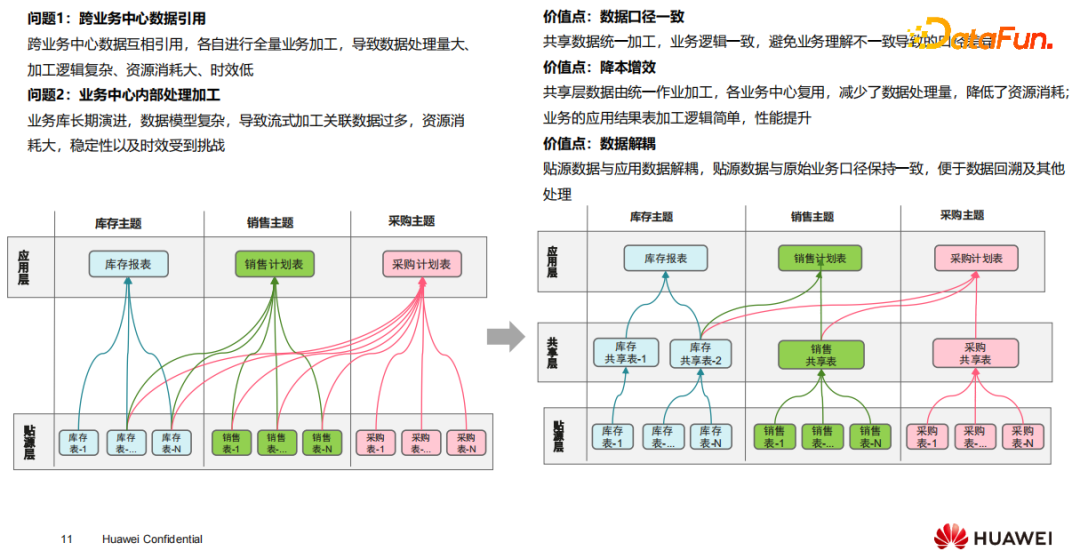
(1)数据加工存在的问题
在跨业务中心数据引用的时候,各自进行全量业务加工,导致出现数据处理量大、加工逻辑复杂、资源消耗大、时效低等问题;在业务中心内部处理加工的时候,由于业务库经过长期演进,数据模型变得更加复杂,导致流式加工关联数据过多、资源消耗大、稳定性以及时效受到挑战。通常大家都习惯于用数据库和数仓那种模式,直接写一个非常大的SQL把结果读出来。
有了数据湖以后,它的存储成本相对来说要廉价很多,这时存储成本和计算成本相比较的话,存储成本会更低。因为前者的用法计算成本很高,耗费了CPU和内存,节省了硬盘,所以下面其实更应该多用一用硬盘的存储能力。
(2)数据分层中增加“共享层”
我们推荐在做复杂处理的时候,中间增加一层或两层,把数据中一些共用的东西抽出来,降低每一层的加工复杂度。数据之间、各个作业之间的加工数据能够复用。这样在开发的时候会大幅简化作业逻辑,降低整体资源消耗,并提升端到端整体的时效性。
(3)数据分层的价值
首先,能够保证各业务之间数据共享时数据口径是一致的。
第二是降本增效,适当地增加一点冗余的存储资源,可以把计算资源消耗降低,同时数据时延也降下来了,可以提升整体性能。
第三是数据的解耦,贴源层跟业务层的业务逻辑保持一致,在数据业务加工的时候,不会改变贴源层的数据存储,在做数据回溯的时候,能够非常方便地去做问题的定位和排查。
3、现有存量的批量数据和任务转换为实时(按照业务需求进行切换)

如果我们已经有一个建好的数据湖,现在要上Lakehouse。如果把整个数据湖几万张表全部推倒重来,成本、代价、风险都非常高。
我们建议的方式是按照业务逐步切换,切换以后数据是可以沿用的,新的业务跑实时,或者用Lakehouse的架构去跑,老的业务继续跑HiveSQL。即使有一些数据是交叉的,也不会影响,因为原有的Hive技术可以读Lakehouse的表,所以这样去做会更加平滑。
4、历史批量表与Lakehouse实时表的互相引用方式

前面我们介绍了存量的批量数据和任务转换为实时,接下来我们看一下这些表之间会不会存在引用上的问题。
虽然批量模式下引用实时表,原有批量作业的代码和调用方式不用修改。但是在实时模式引用批量数据具有一定限制。比如ORC表不支持增量读的方式,只支持全量读,所以在碰到原有表数据加工的时候要做一定的适配。因为一般实时模式都是新业务,它本身就要重写,再适配也是可以接受的,并不会带来太多额外的工作量。我们可以基于应用逐步把所有业务切换完以后,就完全变成新的数据加工模式。
5、Lakehouse的典型场景:镜像表构建,简化方案、降低成本、数据事务性保证
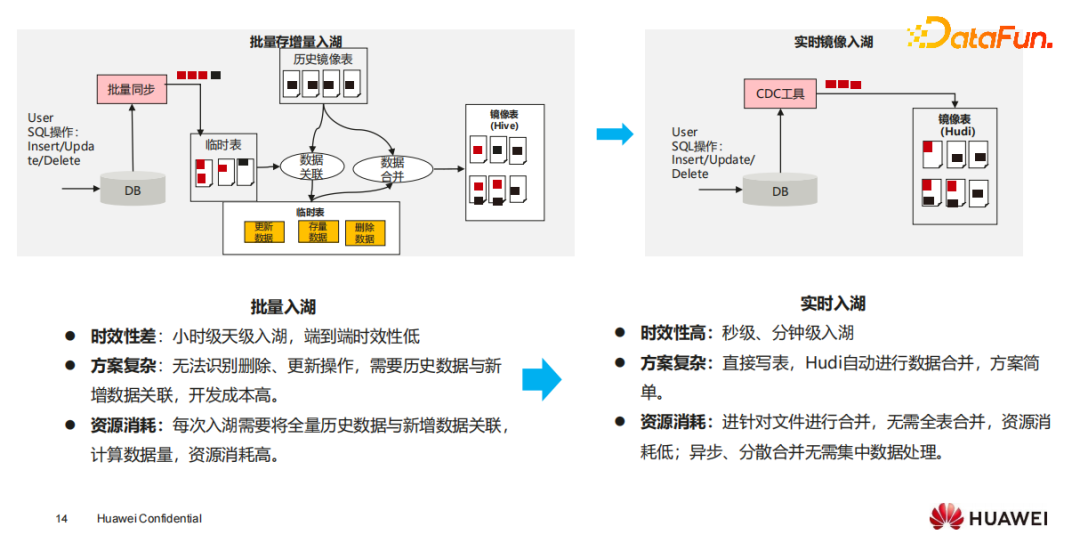
镜像表的生成在数据接入层有两种:第一种是批量同步方式,以T+1的方式进行全表同步,成本会比较高;第二种是增量同步方式,按照自增ID或时间戳把增量的数据同步过来,但要跟原有的表做存增量合并的处理,存增量合并是将增量数据与已有存量数据通过join方式得到新增、删除、更新的数据,然后进行Merge操作,得到最新的全量镜像表。
增量同步方式又可以进一步分为批量和实时,如下:
- 批量入湖
批量入湖在存增量合并的时候,经常会遇到端到端时效性低、开发成本高、资源消耗高等问题。在一些案例中,为了解决端到端的数据开发,在每一层都做存增量合并,资源消耗会占到业务开发的1/4到1/3,造成整体的成本很高,开发工作量也比较大。
- 实时入湖
引入Lakehouse以后,基于Lakehouse的upsert能力实现数据实时入湖,构建镜像表会非常方便。直接把增量数据写入湖中,如果有相同的数据,就直接更新,没有相同的数据,就会认为是新增的,镜像表就能非常快的构建出来。
镜像表构建的方案简化了,计算成本和存储成本也都可以降下来,并且还有事务性的保证。
6、Lakehouse的典型场景:拉链表构建,兼顾流式计算、批量计算和数据回溯

下面再举一个典型的场景,我们在数仓里面会构建拉链表,尤其是基于TD的数仓会构建大量的拉链表。拉链表在数仓里面针对某一个状态有开始时间和结束时间。基于时间戳会采用天级、分钟级或者更细粒度的状态管理,只要有变化都可以保留下来。
- 传统数仓的拉链表实现
传统数仓的拉链表基于Start_time和End_time实现不同粒度的拉链数据;数据的写入与读取都是采用批量方式进行,增量与全量表关联得到闭链操作目标数据。端到端时效性较差,T+1的数据可见性。
- 流批一体实现方案
基于流批一体的方案除了保留原有数仓的批量能力外,新增了实时处理能力。批量处理方式在落地实现上可以基于原有逻辑实现,也可以通过update、upsert能力简化实现复杂度。在实时处理上可以新增最新数据的流式计算,提升业务的时效。因此基于流批一体的实现既可以实现原有批量处理的能力,有可以实现实时的处理能力,且能保持拉链表的特点。
四、后续规划&挑战

1、挑战
- 并发挑战:业务方希望能够实现单表的高的并发写入要求。
- 复杂事务:跨表、跨语句的事务要求。如果事务很复杂,它的回滚量会非常大,会直接影响整个集成的稳定性。
- 门槛高:现代Lakehouse功能丰富、参数配置复杂,技术门槛高。这样在用的时候,就需要熟悉它的各种用法、各种场景,这也为落地带来了一定挑战。
此外,基于批量的处理模式大家都很熟悉,也习惯了批的处理模式;但是流式处理和流批一体的模式属于新的模式,在数据建模设计以及数据处理的理念上需要进一步适配,对于设计和开发人员会带来一定的挑战。
2、后期规划
针对这些问题,我们也做了很多规划。总结起来有两个方向:
(1)开箱即用
我们希望这么多丰富的功能使用上更简单。能够做到在部署好后直接把业务 SQL 搭上去就能跑,而且跑的很好。
(2)场景能力增强
数据湖做交互式查询的性能跟OLAP的库有一定的差别,我们要继续提升性能。我们希望实现更多的实时加工处理,并且速度能做得更快。结合具体场景,根据业务上的要求来丰富它的处理能力。
五、Q&A
Q1:现在 Lakehouse 有哪些开源版本吗?
A:目前开源的Lakehouse有Hudi、Iceberg和DeltaLake,是现在比较主流的。其中Hudi在国内的使用比较普及;Iceberg和DeltaLake在北美用得会比较多一些。
Q2;湖仓一起的架构中,底层的存储对于非结构化和结构化的数据怎么做到统一存储的?他们的元数据也能统一管理吗?
A:非结构化的存储和结构化数据存储在开始的时候,它的元数据肯定是没办法做到一起的。你比如一个文件它本身就没有什么元数据,它只有一个文件名的概念。非结构化存储在做了特征模型之后,是可以统一去存储的,去复用。另外关于结构化数据在一些机器学习里面,它也会有一些特征的处理,特征以后的数据是可以去做统一存储的。
如果是原始数据,统一存储在元数据层其实就是文件系统的元数据了。
Q3:湖仓分层与离线数据分层上处理上有什么特别注意的地方吗?
A:实时的分层处理(湖仓分层)和离线分层处理,其实从模型上面不会有太大的区别,最大的区别是我们对实时要求的区别。
比如我们希望数据处理的端到端更快,其实它可以在我们原有的离线数据分层上适当地去跳一跳,比如从明细层直接跳到结果层、应用层。在有些分层,比如我们贴源层是结构化数据,本身它的数据质量相对比较高,这个时候也可以从贴源层直接跳到应用层。总之,按照不同时效、不同业务要求,它的分层会比较灵活。