作者 | 波哥
作为一名程序员,你可能经常使用 HashMap 这个重要的数据结构,但你对它的底层实现原理可能不够了解。本文将通过图文结合的方式,为你详细解析 HashMap 的底层实现原理,并回答一些常见问题,让你能够更好地理解和应用 HashMap。
1. HashMap 概述
HashMap 是 Java 集合框架中最常用的映射表实现,它提供了键值对的存储和检索功能。底层基于数组和链表(或红黑树)实现,通过哈希算法将键映射到数组的索引位置,以实现快速的插入和查找操作。下面我们来看一下 HashMap 的底层代码流程图:
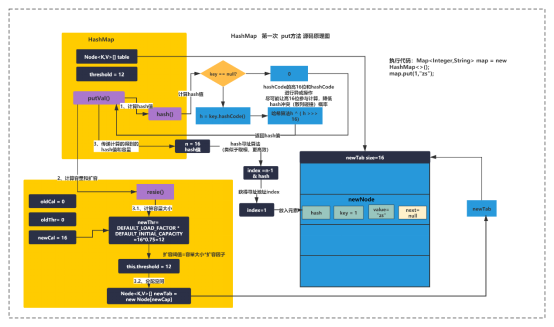
2. HashMap 的主要方法分析
2.1 put方法
put方法用于将键值对插入到 HashMap 中。让我们看一下put方法的源代码:

首先,通过has(key)方法计算键的哈希码,并调用putVal()方法进行插入操作。下面是putVal()方法的源代码:
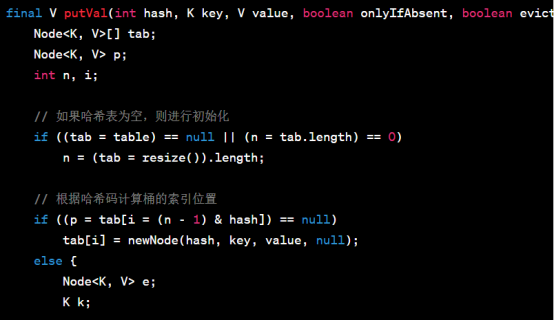
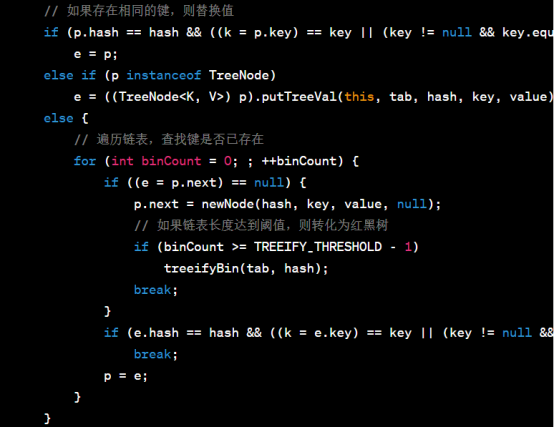
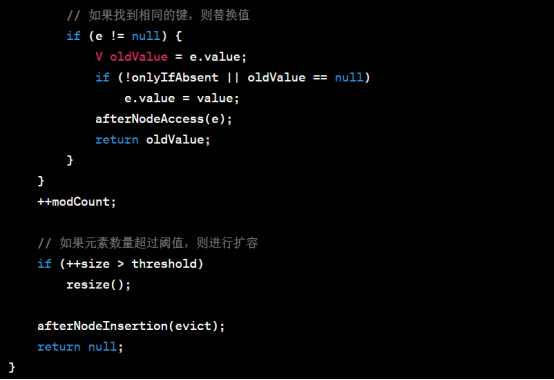
putVal()方法的核心是通过哈希码定位桶,然后在桶中进行插入操作。如果桶为空,则直接在桶中插入新节点。如果桶不为空,则遍历链表或红黑树,查找键是否已存在。如果键已存在,则替换对应的值;如果键不存在,则将新节点插入到链表的末尾,并根据链表长度是否达到阈值来决定是否将链表转化为红黑树。最后,更新修改次数和元素数量,并进行必要的操作。
2.2 resize方法
resize方法用于动态扩容 HashMap。当元素数量超过阈值时,HashMap 会自动触发扩容操作。下面是resize方法的源代码:
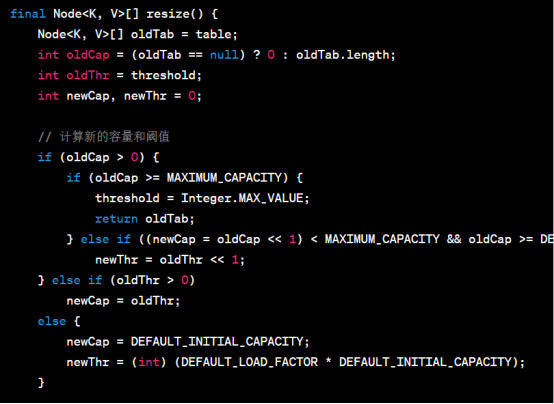
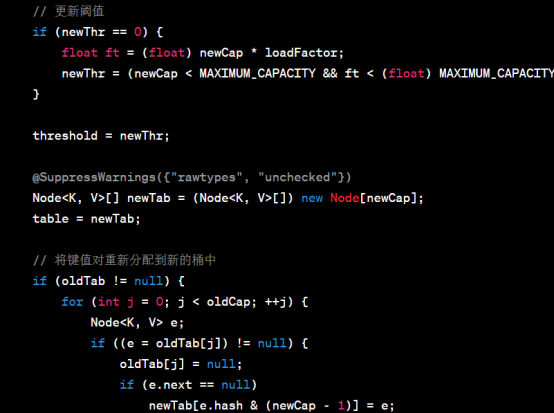

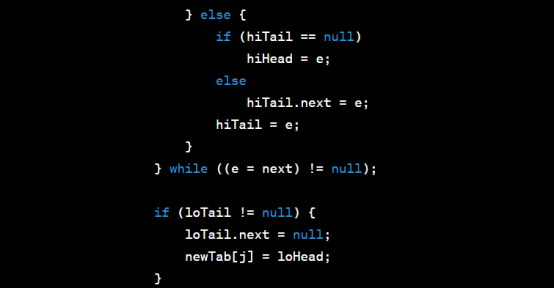
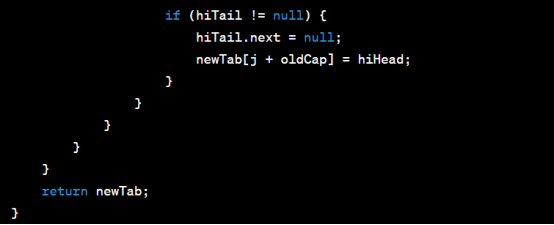
resize方法的主要功能是创建一个新的数组,并将所有键值对重新计算哈希码和索引位置,然后将它们分配到新的桶中。扩容后的容量是原来的两倍,并根据负载因子重新计算阈值。在转移键值对时,会根据哈希码的高位来确定是保留在原来的位置还是移动到新的位置。如果链表长度超过阈值,则会将链表转化为红黑树以提高查找效率。
2.3 get方法
当我们需要根据键来获取值时,可以使用 HashMap 的get(key)方法。下面讲解下 HashMap 的get方法的原理。
首先,我们传入要查找的键key,然后通过hash(key)方法计算键的哈希码。哈希码被用来确定键在 HashMap 中的桶(bucket)位置。根据哈希码,我们可以确定键在数组中的索引位置。
接下来,我们在确定的索引位置找到对应的桶。如果桶为空,即没有键值对存在,那么返回 null,表示没有找到对应的值。
如果桶不为空,那么可能存在多个键值对,这时我们需要遍历链表或红黑树来找到具有相同键的节点。在遍历过程中,我们会使用键的 equals() 方法来比较传入的键和当前节点的键是否相等。如果找到了相等的键,那么返回对应节点的值。
如果遍历完整个链表或红黑树仍然没有找到相等的键,那么返回 null,表示没有找到对应的值。
整个get()方法的原理就是根据键的哈希码确定索引位置,然后在对应的桶中遍历链表或红黑树,通过 equals() 方法比较键的相等性来找到对应的值。
以下是get方法的伪代码示例:
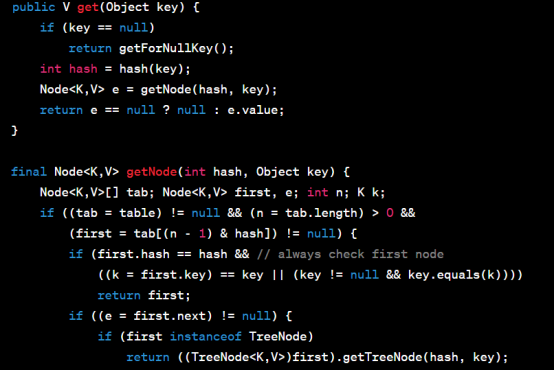
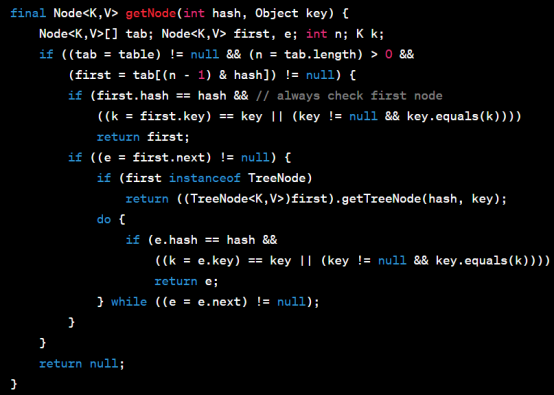
通过分析上述代码,我们可以看到get方法的实现流程:首先计算键的哈希码,然后根据哈希码找到对应的桶,最后在桶中遍历链表或红黑树,查找具有相同键的节点,如果找到则返回对应的值,否则返回 null。
3. 常见问题分析
3.1为什么哈希码很重要?
哈希码在 HashMap 中扮演着重要的角色。它通过哈希函数将键转换为一个唯一的整数,决定了键值对在数组中的存储位置。如果两个键的哈希码不同,它们会被分配到不同的桶中,提高了查找效率。如果哈希码相同,就会发生哈希冲突,需要进一步处理。
3.2如何处理哈希冲突?
当两个不同的键具有相同的哈希码时,HashMap 会使用链表或红黑树来解决哈希冲突。链表是 JDK 8 之前的解决方案,而红黑树是 JDK 8 之后的优化。HashMap 在桶中通过链表或红黑树结构存储冲突的键值对,以便在查找时能快速定位到正确的键值对。
3.3为什么需要动态扩容?
动态扩容是为了避免哈希冲突过多,提高 HashMap 的性能。当键值对的数量接近数组容量的阈值时,HashMap 会自动触发扩容操作。它创建一个更大的数组,并重新计算每个键的哈希码和索引位置,然后将键值对重新插入到新数组中。这样可以减少桶的数量,降低哈希冲突的概率,提高存储和检索的效率。
3.4如何保证键的唯一性?
HashMap 通过哈希码和链表/红黑树结构来保证键的唯一性。当存储键值对时,如果发现相同的键已经存在于桶中,HashMap 会检查键的 equals() 方法来确定是否是同一个键。如果 equals() 方法返回 true,新的键值对会替换旧的键值对;如果 equals() 方法返回 false,新的键值对会被添加到桶中。这样就确保了 HashMap 中的键是唯一的。
3.5HashMap 和线程安全有关吗?
HashMap 在默认情况下是非线程安全的。多个线程同时对 HashMap 进行插入、删除或查找操作可能会导致不一致的结果。如果在并发环境下使用 HashMap,应考虑使用线程安全的 ConcurrentHashMap 或使用适当的同步机制来保护 HashMap 的访问。
3.6如何选择适当的初始容量和负载因子?
HashMap 的初始容量和负载因子会影响其性能和空间利用率。初始容量是指 HashMap 初始化时的桶数量,默认为 16。负载因子是指 HashMap 在扩容之前允许的平均桶占用比例,默认为 0.75。
选择适当的初始容量和负载因子取决于你的应用需求。如果预计存储的键值对数量较多,可以选择一个较大的初始容量,以减少动态扩容的频率。负载因子较小可以减少哈希冲突的概率,但会增加空间占用。综合考虑,通常可以使用 HashMap 的默认值,并根据实际情况进行调整。
HashMap 是一个强大而灵活的数据结构,合理使用它可以提高程序的性能和效率。通过深入了解 HashMap 的底层实现原理,你可以更好地理解其工作方式,并在实际开发中做出更明智的设计和优化决策。
结论
通过以上的源代码分析和常见问题的解答,相信你已经对 HashMap 的底层实现原理有了更深入的理解。HashMap 的底层使用数组和链表(或红黑树)实现,通过哈希算法将键映射到数组的索引位置,以实现快速的插入和查找操作。动态扩容过程会创建一个更大的数组,并重新分配键值对到新的桶中,以提高性能。同时,我们还回答了一些常见问题,希望能帮助你更好地理解和应用 HashMap。
作者介绍
波哥,在互联网行业从业10余年,先后担任项目总监及架构师。目前专攻技术,喜欢研究技术原理。技术全面,主攻Java,精通JVM底层机制及Spring全家桶底层框架原理,熟练掌握当前主流的中间件、服务网格等技术原理。