我们日常生活中使用很多应用程序,有微信、抖音、王者这种涉及多人联网互动的大型应用,它们以操作系统作为宿主;也有网站、小程序、PWA等借壳的应用。面向用户表现为Android/iOS/Windows/MacOS/浏览器/H5/Terminal 等端上的应用程序,名为 Client。更多情况下,业务的核心逻辑体现在背后看不见的服务,名为 Server。
从普通用户视角跳出来,切换到程序员视角,应用程序可以理解为是M个Client和N个Server的组合。在软件开发过程中,Client/Server的边界如何划分,Server之间如何通信,多个Server如何组织能够保证整个系统按照预期的方式运行,都是服务架构要考虑的问题。
下面我们简单串一下主流的几个服务架构,包括分层架构、client-queue-worker架构、微服务架构、事件驱动架构、大数据、大计算架构,并从四个方面对每个架构进行总结:
- 架构的描述和架构图
- 推荐的使用场景
- 优点、潜在问题和最佳实践
- 一些现实场景中的示例
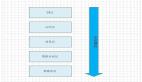
分层架构
WAF全称Web Application Firewall,就是防火墙
在开发传统企业应用中,分层架构得到了广泛使用。一个应用被划分为多个逻辑功能的层,比如展示层、业务逻辑层和数据访问层。这些分层同时也定义了依赖关系,每个层都只能调用它下面的层。每个层可以是一个独立的模块,整个系统的各个模块可以独立甚至并行开发和测试,交付质量可以得到比较好地保证,所以这是目前最为广泛使用的架构之一。但它也有一些难以解决的问题,尤其体现在产品上线后的变更上。体现在:
- 在大型系统中,层的划分逻辑并不那么明显,可能出现过度分层的问题
- 分层往往是从技术角度做的,没有按照业务领域进行,导致系统对业务扩展不友好
- 分层以后,跨层通信比较困难,对性能敏感的业务无法接受由此带来的网络通信开销和编解码开销
- 迭代困难,因为需要所有层的变更,协调多个团队的成本非常高
分层架构在私有云系统中非常常见,比如一个私有云的解决方案可以设计为:
- 物理机层:物理机、网络设备等
- 虚拟化层:将物理资源进行虚拟化,可以用kvm
- 资源管理层:对资源进行调度编排,也提供故障恢复、弹性扩容等功能,比如k8s
- 服务编排层:定义和管理服务的部署、配置和自动化,通常是k8s上做二次开发出的一层壳
- 用户展示层:通常是web界面、命令行,也可以是API
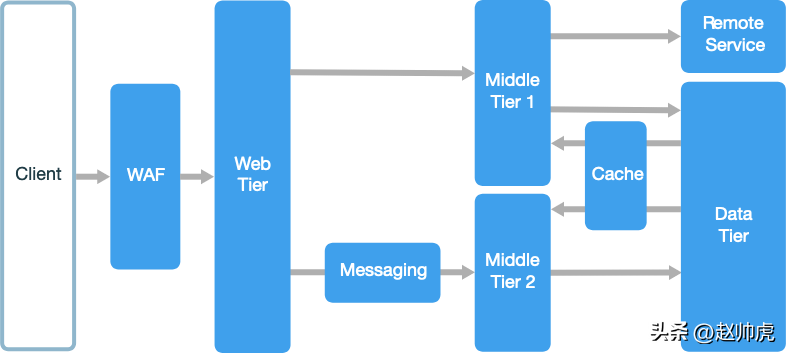
任务调度架构 Web-Queue-Worker
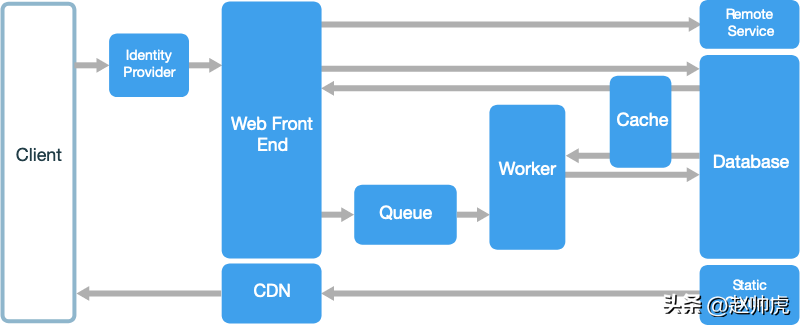
这个架构下,用户通过前端Web页面将任务异步发送到后端,协议可以是HTTP或RPC。通常情况下,后端的worker接收任务后,执行一段事件CPU密集型计算,生成结果。
作为对比,分层架构中来自client的请求大都同步到达,请求可以很快得到满足,server端处理完成后同步返回;相反,任务调度架构下,每个请求要得到满足,可能耗费server大量的计算/网络或存储资源,所以异步返回。
在通信方式上,任务调度架构更多地采用类似于队列的方式(不一定真的有一个消息队列,从数据库拉取任务也算)
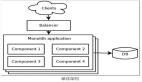
微服务架构
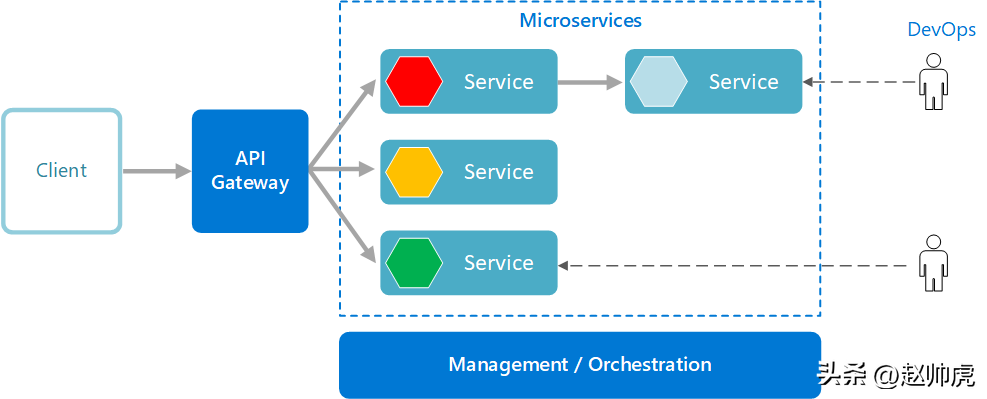
如果应用非常复杂,可以采用微服务模式。微服务应用是由很多小且独立的服务组合而成,每个服务都独立实现一套完整的业务能力。服务的关系非常松散,仅通过API进行通信。
每个服务都可以由一个独立的研发团队进行开发,理论上也可以单独部署,不用和其他团队进行太多的协同。因此,微服务架构非常鼓励频繁的更新。一个微服务架构可以非常复杂,它可以由多个分层架构应用和任务调度架构应用组合而成。
由于服务非常多,DevOps的重要性就凸显出来了。如果操作正确的话,这种架构可支持高度灵活的发布节奏、更快的创新和高度的弹性及扩展性。
目前大型互联网公司普遍采用微服务架构,处理用户侧发起的short-lived请求,以支撑超高的QPS。
事件驱动架构
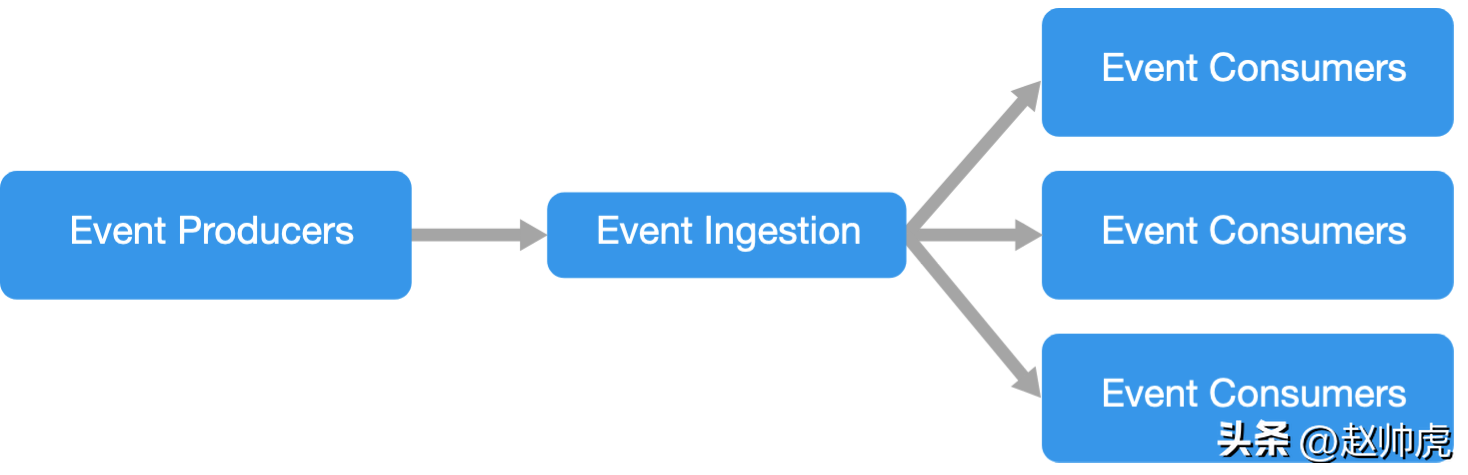
事件驱动架构采用了订阅-发布模型,也叫生产者-消费者模型。生产者负责发布事件到消息队列,消费者订阅消息队列。生产者和消费者互相独立,多个消费者之间也互相独立。
依赖的中间件有 Kafka、RocketMQ、Redis Pub/Sub 等。
事件驱动架构下,应用程序可以以非常低的延迟处理大量的数据,在数据采集分析场景下使用非常广泛。比如IoT场景、大型互联网应用的数据收集子系统(日志/埋点数据回收)。
大数据、大计算
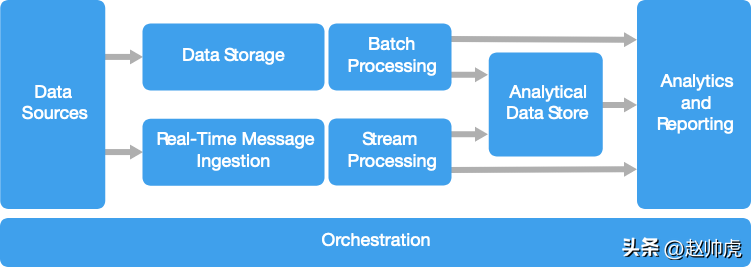
大数据是目前互联网的标配场景,它的第一步一般是流式地搜集应用日志,清洗后存到分布式存储中,应用到离线场景,或分发到消息队列,用于流式处理。这一点与事件驱动架构有部分重叠。
当我们聊大数据是,通常是说对一个超大数据集进行分片/区,执行并行计算,最终产出分析和报表。数据集大小可能是PB级。
大计算,也叫高性能计算(HPC),可以在上千核的CPU上并行计算。除了我们熟悉的大数据场景,也应用在图形渲染、流体动力学、金融风险建模、石油勘探、药物设计等领域。
不同架构模式的局限
任何架构在设计上都有受到一些限制,比如架构基本元素的形态,以及元素之间允许存在的关系。这些限制本质上是在某种架构下,我们可选的最大集合,它影响甚至间接塑造了架构的最终形态。当应用的构建遵循某种架构模式时,一些好的符合预期的特性也会出现。
上面这段话有点抽象,我们以微服务架构的限制为例:
- 每个服务承担独立单一的职责
- 服务之间相互独立
- 数据只归属于拥有它的服务,服务之间不共享数据的所有权
遵循这些限制之后,系统中的服务就可以独立进行部署。收益时事故隔离、支持频繁更新、可便捷地引入新技术。
在选择某种架构模式之前,我们需要理解架构的底层原则和限制。否则,架构设计只在最表层符合某种架构模式,但无法发挥这种架构模式的潜力。在使用架构过程中,务实很重要,有时候我们可能要放宽一些限制,而不是坚持架构的纯粹。
下面这张表总结了不同的架构模式如何管理依赖,以及适用的业务领域
架构模式 | 依赖管理 | 适用业务场景 |
分层架构 | 按照子网进行水平分层 | 传统业务领域,更新频率不高 |
Web-queue-worker | 前后端任务分离,通过异步消息进行解耦 | 相对简单的业务场景,需要执行一些资源密集型任务 |
微服务架构 | 功能/垂直节藕的服务,通过API调用进行通信 | 比较复杂的业务场景,支持高频率的更新 |
事件驱动架构 | 生产者/消费者,每个子系统有独立的数据视图 | IoT和实时系统 |
大数据架构 | 将一个超大数据集拆分成小的数据块,在之上进行并行计算 | 批处理和流式处理的数据分析,机器学习模型支持的预测分析 |
大计算架构(高性能计算) | 数据被分配到上千核CPU上进行计算 | 计算密集型的场景,比如模拟系统 |
不同架构模式面临的挑战vs收益
架构的限制使其在某些场景下面临一些挑战,所以在采用这些架构模式时,需要理解其中的利弊权衡。我们需要保证,在我们所在的子领域(场景),叠加场景的限制条件下,架构带来的收益超过要面临的挑战。
下面列出了在选择架构模式时面临的四类挑战:
- 复杂性。架构的复杂性是否匹配我们所在的业务领域?换句话说,架构模式在处理这个业务领域时是否太简单,以至于无法处理将来的情况?如果是,那么未来系统会演变成一堆屎山,因为架构无法帮你梳理清楚依赖关系。
- 异步消息和最终一致性。异步消息可以帮助我们解耦服务,增加系统稳定性和扩展性。但是在最终一致性上可能会有问题,比如重复消息、乱序消息。
- 服务间通信。把应用拆分成多个独立的服务之后,服务间的通信延迟可能成为一个风险,在数据量快速增长的情况下尤为明显。比如在微服务架构下面临的问题可能有,接口延迟过高,或者网络拥塞。
- 可管理性。管理应用的难度如何,包括监控、部署、更新等等?