一、可观测性
1、可观测性-是什么?
(1)可观测性的基本理解
在计算机系统的领域,可观测性可以理解为能够监控和了解一个系统内部状态的能力,这种能力它涵盖了几个方面:
- 能够监控和理解当前系统的状态
通过可观测性能够知道系统是否在正常运行中,可以及时发现不正常的状态。
- 能帮助定位、回溯系统发生的问题
如果系统处在不正常的状态,我们能够高效地去定位问题,并且回溯问题产生的根源。
- 能够预防问题的发生
对系统可能即将发生的问题有一定的预见性,能够通过告警等方式防止重大问题的发生。
(2)为什么现在可观测性会变得越来越重要?
随着大数据跟云计算等技术的迅猛发展,企业内部的系统变得越来越复杂,系统逐渐地开始分布式化,微服务成为了主流,这就导致了现在企业内部的系统中需要监控的服务组件越来越多。服务的组件之间的关联越多,系统可能发生故障的概率、类型也就越多。
如果系统能够实现很好的可观测性,就能更好地去应付复杂系统可能带来的问题,更好地控制内部复杂系统。
2、可观测性-如何实现
可观测性的实现主要包括三个方面:
- 数据采集和关联的能力
想要知道系统的状态,首先要依赖于系统中各个服务产生的数据,所以第一步需要去收集数据,并将这些相互独立的数据关联起来。
- 分析、可视化的能力
有了原始的可观测性数据,还需要对这些数据进行多样分析,通过这些数据去解读系统的状态。另外可视化也不可或缺的部分,它能够将分析结果以更直观的方式呈现出来,带来更为高效的可观测性。
- 事件响应能力
一个可观测性系统需要在出现或即将出现严重事件的时候,提供快速响应的能力,并以适当的方式通知用户,通知系统管理员,辅助用户恢复故障或者防范故障的发生。
3、可观测性-数据类别
在可观测性领域主要依赖三类数据,分别是:日志 Log、指标 Metrics 以及追踪 Trace。
二、数据采集-我们需要什么?
合格的数据采集工具,一般具备如下特性:
首先,尽可能多地支持从不同的数据源去采集数据。
其次,能够尽可能多地支持不同的数据分析平台,也就是数据的消费终端。采集到的数据能够很容易地被导入到数据的消费终端。
最后,具备一定的数据加工的能力,而不只是原封不动地把数据从源端搬运到终端而已。
在数据采集领域,有很多优秀的工具、很成熟的应用,例如 Elk 架构中的 Logstash、基于 Go 写的 Filebeat、基于ruby的Fluentd 等等。今天主要介绍的是Datadog 公司的开源工具 Vector。
三、Vector
1、Vector 的简单的介绍。
Vector 工具在 GitHub 上有超过 13.5K 的 Star,还有 1.1K 的 Fork,是非常热门的项目。

根据官方网站上的介绍,Vector 是一个高性能的端到端的可观测性数据流水线工具,可以更好地控制可观测性数据。这个工具本身是用 Rust 开发的,所以具备 Rust 原生的内存安全、以及性能方面的优势。支持跨平台的部署,支持 Linux、 Mac OS、 Windows 平台。
从上图中可以看到 Vector 的经典功能拓扑,它可以作为 Agent 代理端部署在数据的源端,收集不同类型的可观测性数据。同时也可以作为聚合的 Aggregator 将多个不同来源的 Agent 的数据聚合在一起并发送到不同的数据 Sink 里面。

Vector 主要有三大功能模块,如上图所示。
数据从 Source 进入到 Vector,经过一些 Transforms 逻辑进行数据加工,最后发往 Sink。可以看到 Vector 通过 Source、 Transform 、Sink 三种不同类型的组件组成了一个完整的数据流水线。
这里面的一个 Source 就是一个可供采集的数据源,例如文件、Kafka、Syslog 等。而一个 Sink 则是接收、消费数据的终端,比如Clickhouse、Splank、Datadog Logs 这类的数据库,或者日志分析平台。
简单归纳一下 Vector 具备的两种主要类型的功能:
- 数据采集与传输
它可以从数据采集端的 Source 获取数据,并最终传输到数据的消费端 Sink。
- 数据加工的能力
可以通过内部的 Transform 的功能模块对收集到的数据进行解析、采样、聚合等不同类型的加工处理。
(1)Vector-丰富的功能支持

上图中可以看到,官方文档上面 Vector 支持的 Source、Sink 、Transform 类型的列表,非常丰富。图中 Source、Sink 的列表都做了截断,因为它支持的类型太多了,具体完整的列表可以在其官方文档看到。
Vector 的这些 Source、 Sink 、 Transform 组件的功能都是内置的,跟 LogStash 通过扩展插件的支持方式不一样。
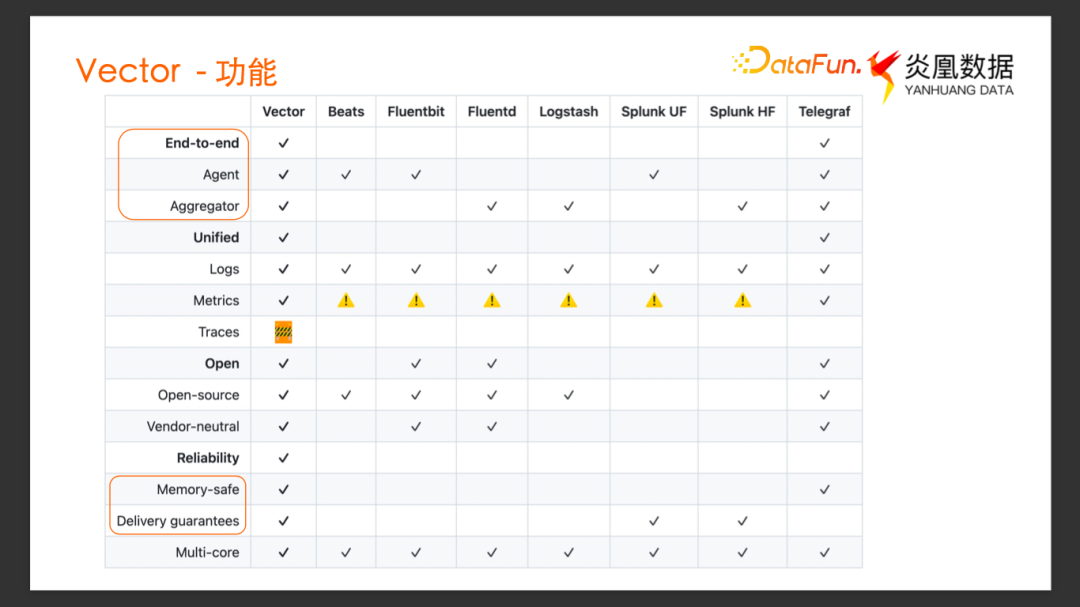
GitHub 首页列出了Vector与其它一些可观测性数据采集工具的对比,有几个比较吸引人的点:
End To End 特性。既可以作为 Agent 部署采集数据,也可以作为 Aggregator 聚合数据,在部署上有很大的灵活性,能够更好地去适应不同的场景。
可靠性。由于它使用 Rust 开发,具备内存安全的特性. 同时对于大部分的 Source、Sink 类型都支持实现了 At-Least-Once 传输保证。
除此之外,还有一些亮点功能,比如提供了 Buffer 功能,用户可以选择不同的缓冲模型,可以自己选择是采用内存 Buffer 缓冲来提高吞吐的性能,还是采用磁盘作为 Buffer 来提供更好的持久性。
(2)Vector-性能

官方提供的性能对比图,对比了很多知名竞品。可以看到,除了正则解析方面稍微弱一些以外,其它无论是文件source发送到TCP sink, 还是 TCP source到 HTTP sink等端到端的性能测试的 Case,Vector都是有优势的。
(3)Vector-基本用法
作为一个工具,vector的易用性很高。
它支持通过很多不同的方式安装,安装包下载、包管理器等等,安装完成以后,得到一个二进制的 Binary,它唯一的依赖就是一个配置文件。
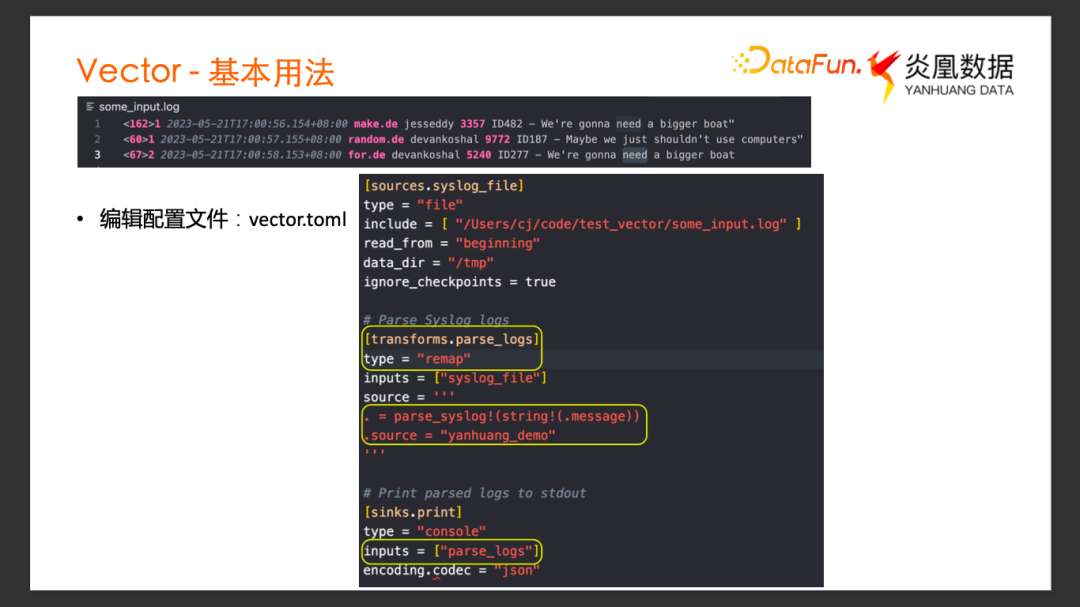
最简单的使用场景,比如有一个作为样例 Log 文件some-input-log,这里面有 3 条日志都是 syslog格式的。我们希望用 Vector 来采集这个文件里面的 Log,然后对 syslog的格式解析,将解析后的事件发送到 Terminal 终端,看是否正确解析。
首先创建一个配置文件 Vector.toml,Vector 的配置文件支持 Toml、 Yaml 、Json 三种不同格式。以 Toml 做示例。图中是一个简单的 Vector 配置文件的 Toml 格式写法,主要分成三个部分:Source、Transform和Sink。
Source 的类型是文件, Include 这个字段写需要采集的日志文件的路径。
Transform 中 Input 是 Source 的 Name, 表示上游的数据源,Source 端采集到的这些日志事件通过VRL 语法做解析,把源端数据的 Message 字段做 parse_sys_log 函数调用,作用就是把 syslog的日志解析出对应的有用的字段。我们还添加了一个 Source 字段,赋值叫 yanhuang_demo。
Sink 的 Inputs 里面写了上游数据源是哪里,是刚刚定义好的 Transform 叫 parse_logs,它的 Type 是 Console,也就是希望解析完的日志能直接打印到 Console 消费终端。

保存这个配置文件,然后在 Terminal 里面运行,只需要一个 Binary 和一个依赖配置文件, Vector -c Vector.toml 就运行起来。
可以看到,原始的数据里面只有一条完整的 syslog message,打印到 Console 的事件里有appname、facility 等字段,这些 syslog格式里面的标准字段,都被从原始 Log 中提取出来,并且我们配置的 source = yanhuang_demo 字段,也添加到了最终输出的log事件中。
这就是最简单的运行实例,它的配置和运行过程都很简单。
2、Vector-transform的使用

刚才是一个很简单的配置实例,只有一个 Source,一个 Transform 和一个 Sink。在实际的使用中,往往会有很多的 Source 需要去采集,可能需要将数据加工后发往不同的 Sink。这个时候需要用到很多不同的 Transform 单元去完成不同类型数据加工工作。官方的这张图展示了一类实际的使用场景。
这个流水线的拓扑就相对比较复杂,可观测的数据来自于不同的 Source,有日志文件的、系统指标等等。
第一个 Transform 单元,将来自于不同 Source 的不同类型的日志文件路由到相应的 Transform 单元,例如,如果是 Nginx 的日志,就会走到 Nginx 解析的 Transform 单元。如果是 Postgres 的日志就会走到 Postgres 的 Transform 单元。JSON 类型的文件就会走到 JSON 类型的 Transform 单元。这个示例中的服务可能都是部署在 AWS的EC2 Instance 上的, 因此前面这些 Log 和 Metrics汇总到了同一个 Transform 的 Stage 3,在这个单元里面统一处理日志的EC2 Meta Data,最后这个 Transform Stage 4 单元再对汇总来的日志事件经过采样以后,发送到 3 个不同的 Sink,比如发往 Elastic 去做数据分析,发往 AWS 的 S3 做数据固化,发往 Prometheus 做指标分析。
可以看到这个拓扑里面通过多个 Transform 功能可以很灵活地把不同类型的多个数据源最终统一归集在一起,得益于它丰富的 Transform 功能,才能很灵活地去构建数据采集的流水线。
Transform 含有很丰富的功能: 重映射(remap),过滤(filter)、聚合(aggregate)、路由(route)等等,还支持用户自定义功能。
(1)Transform-Remap
Remap-VRL
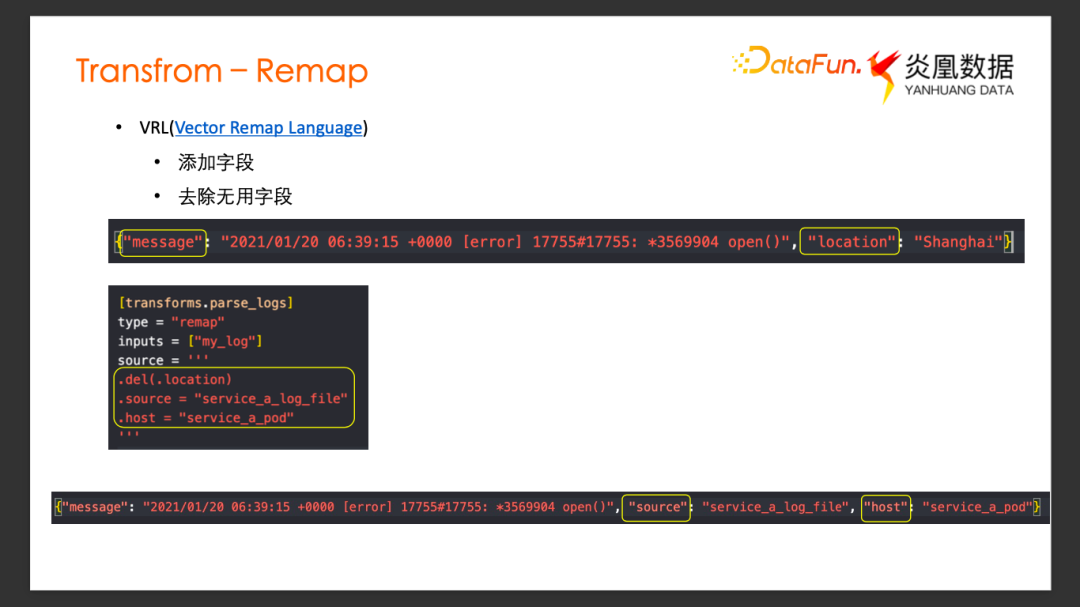
Transform最主要的用法就是 Remap。Remap 使用的是 Vector 自定义的配置语法 VRL(Vector Remap Language)。接下来结合实际案例来看 VRL 的使用。
现在希望对一条日志事件去除掉不关心的某些字段,同时添加关心的某个字段。原始数据是JSON 格式的一条Log,它有两个字段, Message 字段和 Location 字段。希望能经过一个 Transform去掉 Location 字段,同时添加自定义的 Host 和 Source 的信息。添加一个 Transform 配置单元,可以很直观地看到 Source字段里面采用 VRL 语法编辑一个 Transform 功能:通过 Delete 方法把 Location 字段删除掉,同时添加了 Source、 Host字段。经过这个 Transform 以后,结果中可以看到,Location 字段已经没有了,Source、Host 字段被添加到了下游的日志事件。
Remap-解析字段
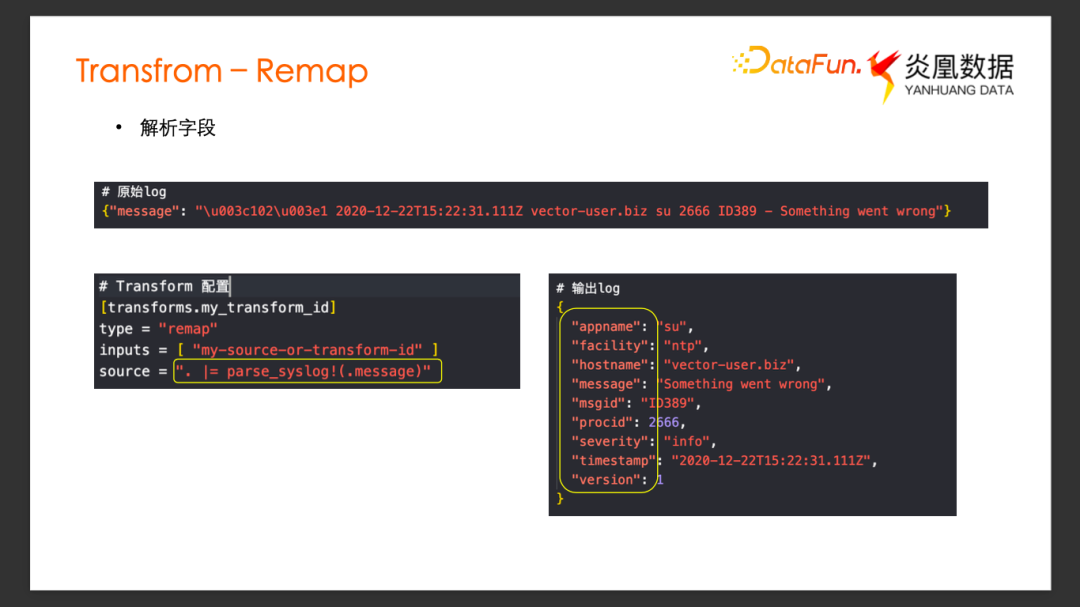
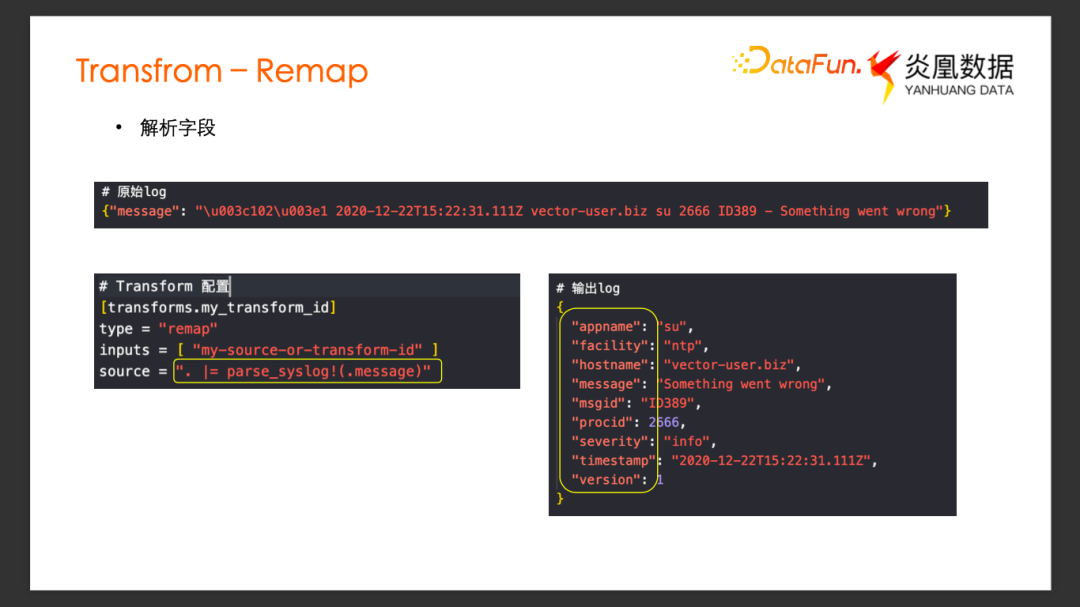
还可以利用 Remap 实现一些别的功能,比如字段解析。
假设原始 Log 有一个 Message 字段,内容是一条 syslog格式的日志,我们希望能将 Message 里面的 syslog字段都解析出来。用 VRL 里面内置的 parse_syslog方法即可把 Message字段内容作为syslog解析。提取出解析完的相应字段赋值给当前日志事件,所有解析出来的字段变成了当前的输出下游的日志事件的新的字段。
Remap-多策略解析
在实际的使用中同一个 Transform 单元还可能需要处理不同格式的数据。同一个 Transform 单元接收到上游日志可能不是相同格式的,可以利用 VRL 的 Remap 去做多策略的解析,比如,可能是syslog、Apache access Log,或者是自定义服务的某种格式的 Log。可以在一个 Transform 单元里面去定义一个适配多种策略的 VRL 的 Remap。
这个transform中,我们先把解析完的结果放到 Structure 变量里面,先把 Message 字段通过 parse_syslog 来做解析,后面的两个问号表示这一步如果失败的话(event不是正确的 syslog 格式),就会 fall back 到下一个阶段,也就是 parse_common_log,当做 Apache Log 去解析。如果还是解析错误的话,最终fall back 到 parse_regex 方法。parse_regex 通过自定义的正则表达式来解析自定义的日志格式。所以符合三种格式任意一种的事件,最终都能通过这个 VRL 的链路正确地解析到 Structured 变量,然后把解析完后的字段跟当前 Log 里面的其他字段去 Merge 在一起。
(2)Transform-Filter

实际的使用中,除了 Remap 还有一些其它类型的功能。比如,可以利用 Filter 类型的 Transform 过滤筛选出我们关心的 Log 事件,同时丢弃掉我们不关心的 Log 事件。比如,原始的 Log 数据源,是某个服务产生的日志文件,分为了不同的 Log Level,Debug 在最终的数据分析终端里面可能是不需要的,就可以通过这个 Vector 的Filter Transform 把它过滤掉。
Transform 的配置很直观,Type 设置 Filter。Condition 的配置就是设置的过滤的条件,这里过滤所有的 Level 字段不等于 Debug 的事件,经过这个 Transform,最后输出到下游的日志就只剩 Info Level 的事件了,就完成了过滤的功能。
(3)Transform-Aggregate

在收集 Metrics 的场景中可能经常需要对 Metric 做聚合,因为原始的数据源采集来的 Metrics 指标可能包含太多采样点的指标数据了,而下游的数据消费端可能更关心相对粗的时间粒度内的指标,这时就可以使用其 Aggregate 的聚合功能。
例如,原始的 Metric 数据收集了同一个时间点的两个不同服务的技术信息,可以看到它的 Timestamp 是一样的,都有 Counter 这个字段,但来源于不同的 Host,下游服务不关心具体哪一个 Host,或者分别的 Counter,希望以每 5 秒为一个时间窗口的粒度统计单个时间窗口内的 Counter 总数。创建一个 Transform 的配置单元,type 这边选择 Aggregate,设置 interval_ms为5000ms,希望以 5 秒的时间窗口聚合。可以看到最终输出到下游,属于同一个时间窗口的 Metrics 数据被聚合了,Counter 的数值做了相加。
(4)Transform-更多数据加工

Vector 的 Transform 还有很多其它功能, Remap 类型包含了大量内置的数据解析、转换等的方法。比如 Sample 类型允许通过采样来降低 Log 收集密度,还有 Metrics 可以转 Log, Log 转 Metrics 等等适配下游不同的数据消费终端。
如果都不能满足用户的数据转换解析的需求,它还支持通过 Lua 脚本内嵌的方式自定义 Transform 的功能,扩展原本不具有的 Transform 的能力。
简单总结一下 Vector Transform 功能给可观测性数据采集带来的收益:
- 第一 减轻了数据终端的解析成本
预提取出了一些字段,可以供最终的数据终端直接索引,不需要再解析。
- 第二 可以降低存储的成本
通过一些解析、增加删减字段,丢弃掉了不关注的字段,减少了日志最后存储下来的体积、存储成本。
- 第三 增加了不同数据来源的关联性
从很多不同的服务采集到日志以后,在 Vector 做聚合。不同服务之间是孤立的,日志也是无关联的。可以在 Vector 根据上下文的背景添加一些字段作为 Tag,最终数据消费终端收到这些日志,通过这些 Tag 可以进行一些不同服务的关联分析。
3、Vector-选择理由

炎黄数据的研发内部环境中,也大量使用了 Vector ,给客户的鸿鹄数据平台的部署环境中也经常推荐客户使用 Vector 进行原始数据的采集。在鸿鹄的数据平台里面,我们也添加了使用 Vector 导入数据的原生的支持。
选择 Vector 的理由如下:
- 第一 跨平台的支持
主流的 OS 都可以安装使用,可以满足客户不同的硬件环境。
- 第二 灵活的部署形式
可以作为 Agent,也可以作为 Aggregator。在比较复杂的分布式环境中部署具有灵活性。
- 第三 没有环境依赖
执行只需要一个二进制的 Binary,不像有些工具可能还需要 Python 或者 Java 运行时环境。让用户可以进行最小化的容器部署。
- 第四 丰富的 Source 支持及强大的 Transform 的功能。
支持丰富且配置简易灵活。在生产环境中要去新增某一种数据格式的采集时,可以很简单地通过添加一个独立的配置单元完成迭代。
- 最后,有良好的性能和可靠性
它包含了 Buffer 缓冲的功能、传输保障、内存安全等等这些特性
四、Vector + Honghu 构建可观测性
1、搭建可观测性数据流水线
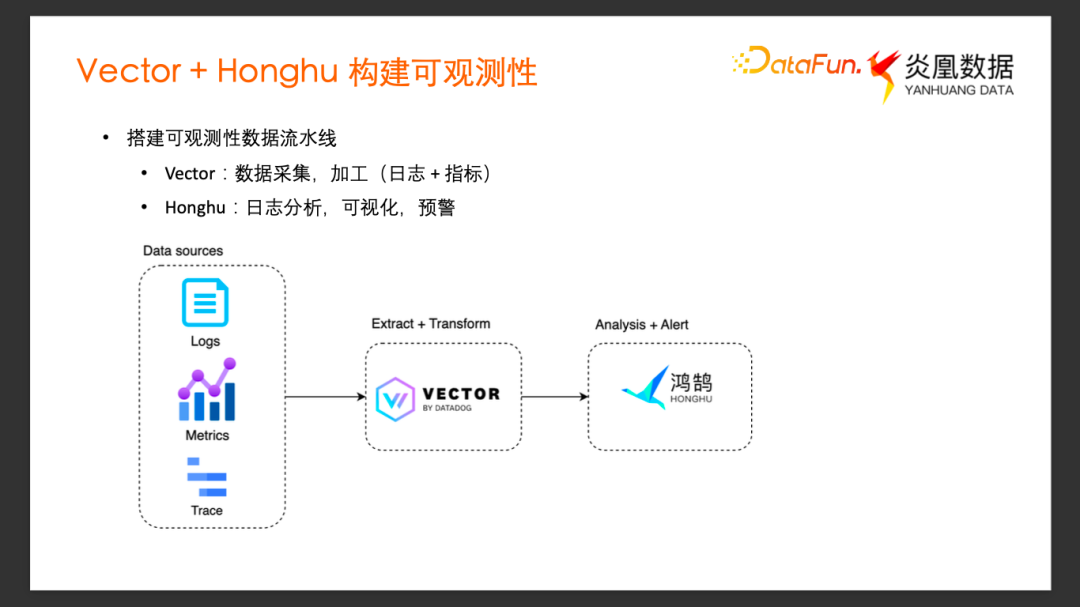
Vector 主要用于构建我们可观测性数据流水线的前半部分。接下来介绍我们如何利用 Vector 和鸿鹄数据平台搭建一个完整的可观测性数据流水线。
鸿鹄是炎凰数据独立研发的一款全栈式大数据分析平台,它提供了从端到端的数据采集、导入、索引搜索,到最终的数据展示、任务告警等一系列服务。我们主要利用它对于异构数据的即时分析,可视化和告警这些功能,来组成可观测性数据流水线的后半部分。
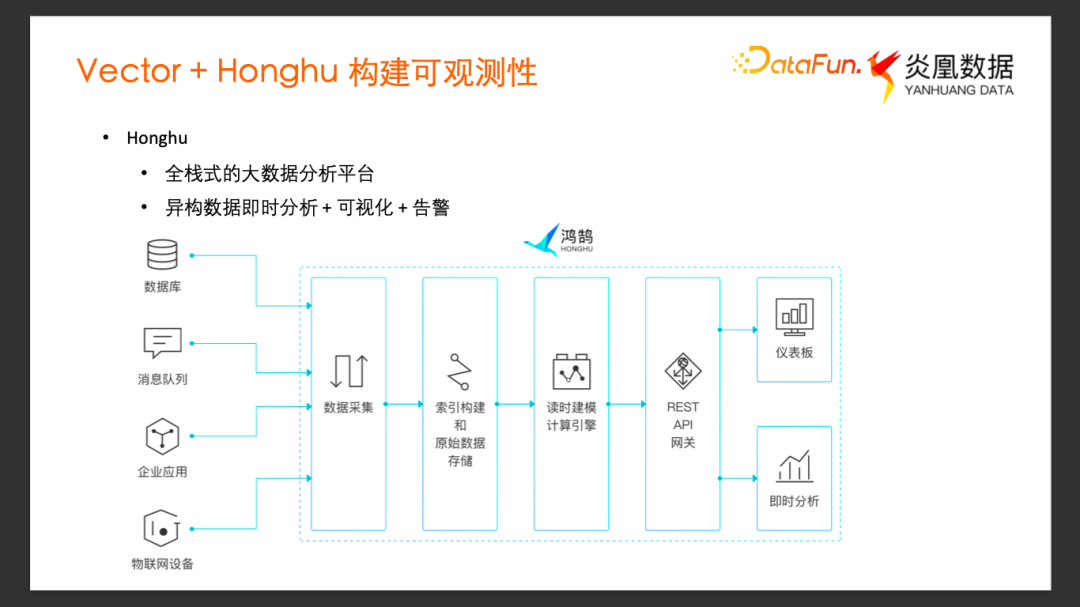
在搭建这个可观测性数据流水线的过程中,首先使用 Vector 完成可观测性数据的采集和加工,用它来收集日志和 Metrics 等等,然后用鸿鹄来完成日志分析、可视化和告警功能,构建最终的直观的可观测性。
这张图展示了大致的数据流向,Vector 对原始的数据做采集以及加工,然后把加工过的数据 Load 到鸿鹄系统中,在鸿鹄中做数据的分析、告警等等的功能。
Vector 官方的 Sink 没有鸿鹄 Sink,我们是怎么把数据 Load 进去的?
鸿鹄针对Vector 做了数据导入的原生支持,用户可以通过类型为vector的Sink 直接把数据导入到鸿鹄,只需要在鸿鹄上做一些简单的配置即可。
2、Honghu 支持通过 Vector 导入数据

首先我们在鸿鹄上开放了一个网络端口,扮演Vector Aggregator 的角色。打开鸿鹄的 Web UI 做一些简单配置,在鸿鹄的 web UI 上的数据导入页面,选择从外部数据源导入,就可以看到一个 Vector 类型的数据源,叫 system_default_vector_input,还可以看到配置里面有一个参数叫数据集范围(在鸿鹄里面数据集就等同于传统数据库概念中表的概念,所有进入鸿鹄的数据必须属于某个数据集,然后再从数据集中去查找使用它)。
我们编辑一下 Vector 的数据源配置:点击编辑按钮,弹出的窗口中可以配置的只有一项,就是数据集范围,这个数据集的范围是用来选择“允许通过 Vector导入数据到哪一些鸿鹄的数据集”,这是一个白名单机制。接收数据的网络端口默认是20000,不可以更改。

配置完成以后,点击下载配置模板,在弹出的模板选项里面,选择需要导入数据到哪一个目标数据集,以及导入的这个数据的数据源类型,比如格式 nginx.access_log,鸿鹄默认支持该数据的解析,选择 Data Type 类型,点击确定就会下载配置模板到本地,默认采用 Toml 格式。
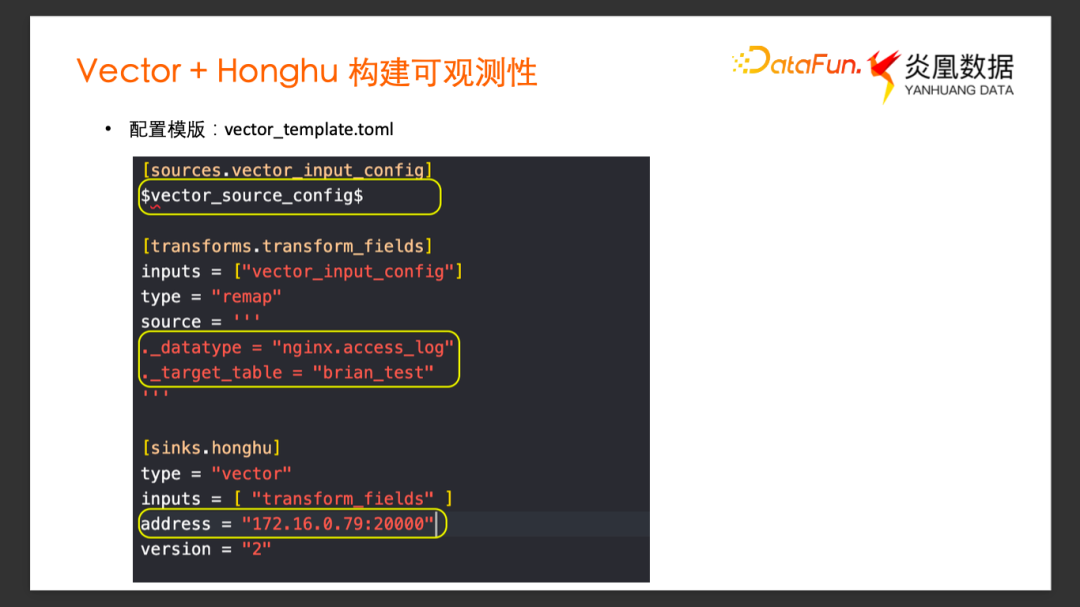
Vector template.toml 文件是标准的 vector的配置文件的模板。除了 Source 部分是预留给用户自己添加,Transform 单元跟 Sink 单元基本都不需要再改变了。Transform 单元根据前面 UI 上的配置添加了两个字段, _datatype 数据源类型是 nginx.access_log,_target_table 是数据最终要导入到的数据集,添加了这两个字段以后,最终的 Transform 不需要再做额外的事情了。
最后的 Sink 单元,可以看到自动生成了鸿鹄可达 IP 地址,以及开放的端口,最终 Vector 采集的数据会通过这个网络端口导入到鸿鹄系统中。我们接下来就可以用这个配置模板,再去添加一些 Source 相关的配置,以及增加一个前置的,用户所需的一些 Transform 逻辑就可以完成一个完整的 Vector 配置文件了。
五、示例-构建honghu生产环境可观测性
1、Honghu内部生产部署
前文对理论知识进行了介绍,接下来看一些具体的实例,
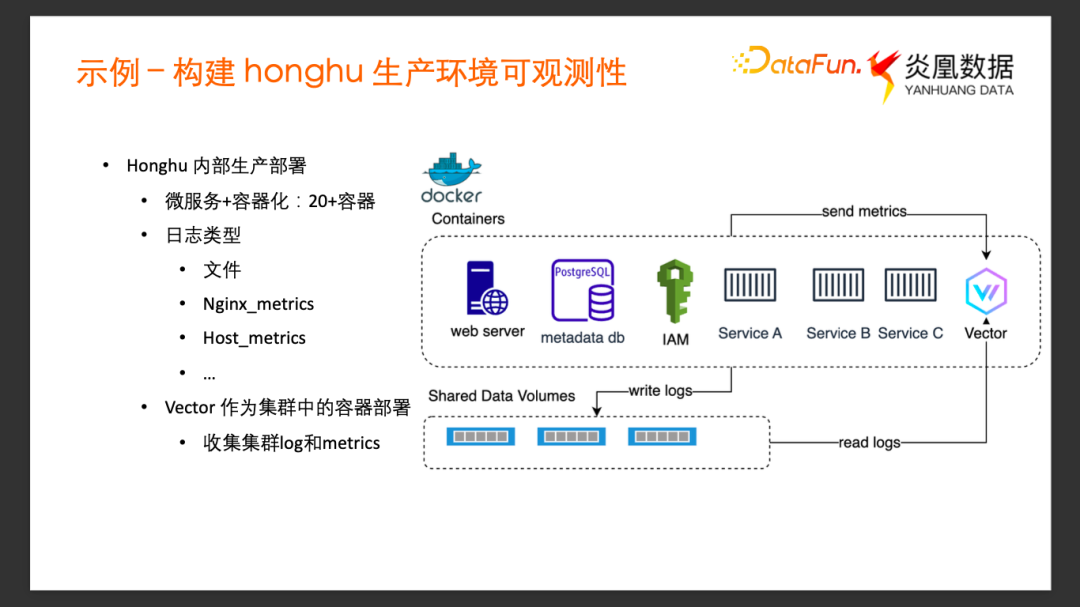
我们希望采用 Vector + 鸿鹄来构建鸿鹄内部生产环境的可观测性。由于鸿鹄数据平台是采用容器化 + 微服务的部署方式,在内部生产环境的部署中, 包含 Core DB 的服务、 Web 服务、 Metadata DB服务、身份认证服务等等。每一个微服务都是以容器的形式去运行的,因此鸿鹄生产环境中的每个服务都有各自的 Log,以及各自的 Metrics 需要采集。
在公司内部的鸿鹄生产环境中,除了前面提到的这些服务,由于测试需求,可能还会有更多的服务,比如,不同类型的 Database,不同的Message Queue如Kafka 等等。所以内部的部署环境有多达 20 个以上的容器微服务。日志的类型也非常多样,有自定义的 Log、Web server 的 access log,或者容器主机的 Host Metrics 等等。
具体的部署模式参加上图,我们把 Vector 也作为集群内的容器运行起来,首先将各个服务的日志文件Mount 到一个共享的 Volume 存储中,这样就可以通过内部Vector服务的文件 Source 采集所有的 Mount 到共享存储的这些 Log 文件的数据。其他的一些 Metric 的数据,采用相应的 Metric Source 直接发送到 Vector。Vector 在采集完数据并进行加工以后,会通过配置模板里面写好的端口直接发往鸿鹄的核心数据库,存入到指定的数据集去供鸿鹄构建查询与分析。
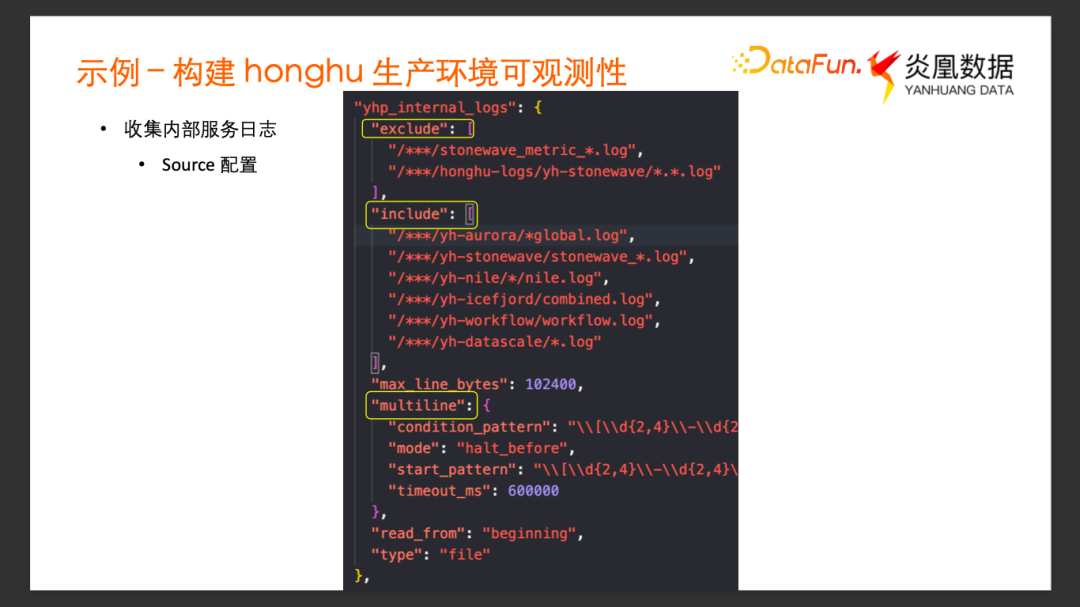
关于集群中 Vector的配置,这里仅挑选鸿鹄内部服务的 Log 文件的采集配置进行讲解。
Source 配置
Source 配置(yhp_internal_logs)采集炎凰内部的日志的配置,Source Type 是文件。通过 Exclude 跟 Include 来决定哪些日志文件需要采集,哪些不需要采集。这里Multiline 的配置是 Vector 提供的用于识别多行 Log 的功能。内部的服务中有时候会打印出来含换行符的Log,或者 Log 很长写文件的时候被自动分成多行,默认的日志采集又是以单独的一行作为一条事件的。通过 Vector 的Multiline 的配置项,可以灵活地定义内部的多行 Log 的格式,将一些比较长的多行 Log 正确地识别为一条单独的 Log 事件采集进来。

Transform 的配置和下载的模板文件没有太大的差别,这里面将 _datatype 设置为 yhp__log,将_target_table设置成 _internal。

Sink 的配置基本上也不需要改动。Address 已经预填好了,是鸿鹄服务的一个可达的地址加 20000 端口。
这里面有一个叫 Compression 的选项,由于 Vector 到鸿鹄的数据传输是通过网络走的,所以是否对传输的数据做压缩,会影响到网络的流量与速率。因为 Vector 跟鸿鹄的部署处于同一个主机的内部网络中,网络并不是瓶颈,所以在这里就选择了 False,不对数据传输进行压缩。
2、在 Honghu中查看日志

当Vector 采用定义好的配置文件跑起来以后,数据就会源源不断地进入到配置好的目标鸿鹄数据集里面去了。在鸿鹄的管理界面上查看数据集的状态,可以看到采集的内部的可观测性数据,分别发往了_internal、_metrics、_audit 这三个数据集。在这个数据集的管理页面可以看到这三个数据集的大小、事件计数以及事件的时间范围等信息。

数据采集和接入部分完成后,接下来看一下如何通过鸿鹄构建生产环境的可观测性。
鸿鹄是采用标准的 SQL 语言来进行数据的查询分析的。点开查询页面通过一个最基本的查询,先看看我们导入的日志事件是什么样的。在上方的搜索输入框里面可以看到我们对_internal 这个数据集进行了一个 select * 的查询,通过查询结果显示可以看到每一条日志事件,除了其原始的日志内容以外,还有通过 Vector 采集的时候添加的字段,以及鸿鹄根据这个事件配置本身写好的 data type做的自动抽取的字段。通过查询的结果,进一步地去修改查询,对日志事件进行分析,抽象出我们需要的持续的可观测性的结果。
3、通过可视化能力创建可观测性
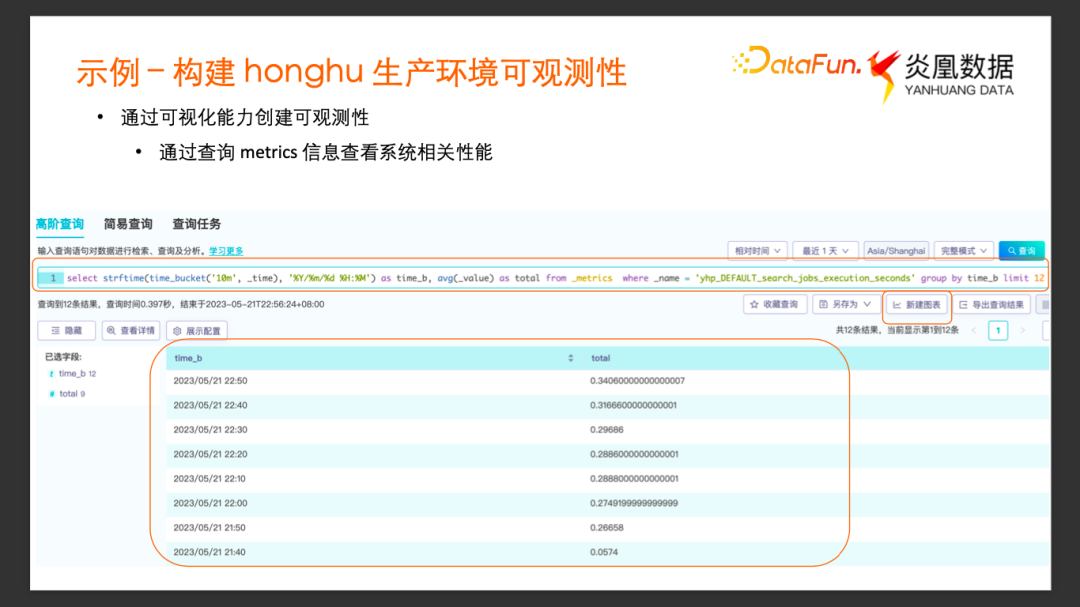
进一步通过示例来看如何通过查询分析的过程构建可视化的可观测性。
我们尝试通过 _metrics 数据集中的事件,来持续观测鸿鹄系统的查询性能的变化。Metrics 的数据集里面导入了自定义的一些 Metrics 事件,比如yhp_DEFAULT_search_jobs_execution_seconds这个指标,代表鸿鹄查询相关的执行时间的指标。我们希望利用这个指标数据,以每 10 分钟为一个时间窗口统计鸿鹄查询的平均耗时。
这个SQL分为几个部分, 先从 _metrics 数据集中过滤出所有_name为yhp_DEFAULT_search_jobs_execution_seconds的事件。然后通过 time_bucket 的表函数划分时间窗口,以每 10 分钟为时间窗口来得到 time_b列 (这里_time 字段表示这个metrics收集的时间戳, _value字段表示 Job 执行耗时的具体数值。),然后以 time_b分组统计每一个时间窗口中 _value平均值,做 average 的操作。
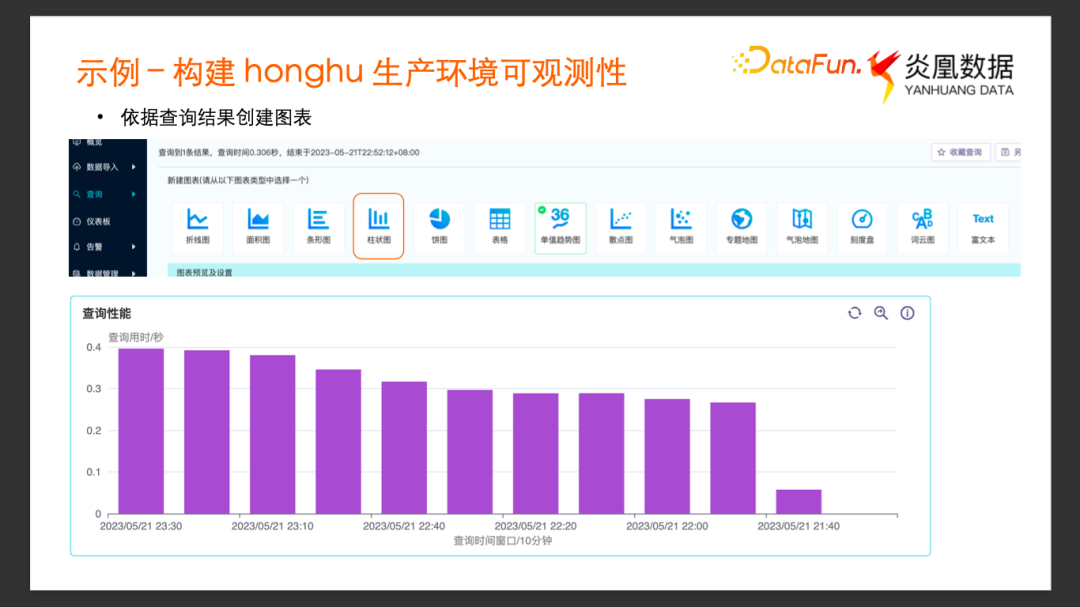
通过这个查询可以得到如下图所呈现的结果。
根据这个查询结果去构建可视化的图表,点击右上方的新建图表按钮,选择柱状图,通过对 X 轴、Y轴的简单配置就可以得到下面这张查询性能图表。这样就可以非常直观地来监测系统查询在不同时间段的性能。
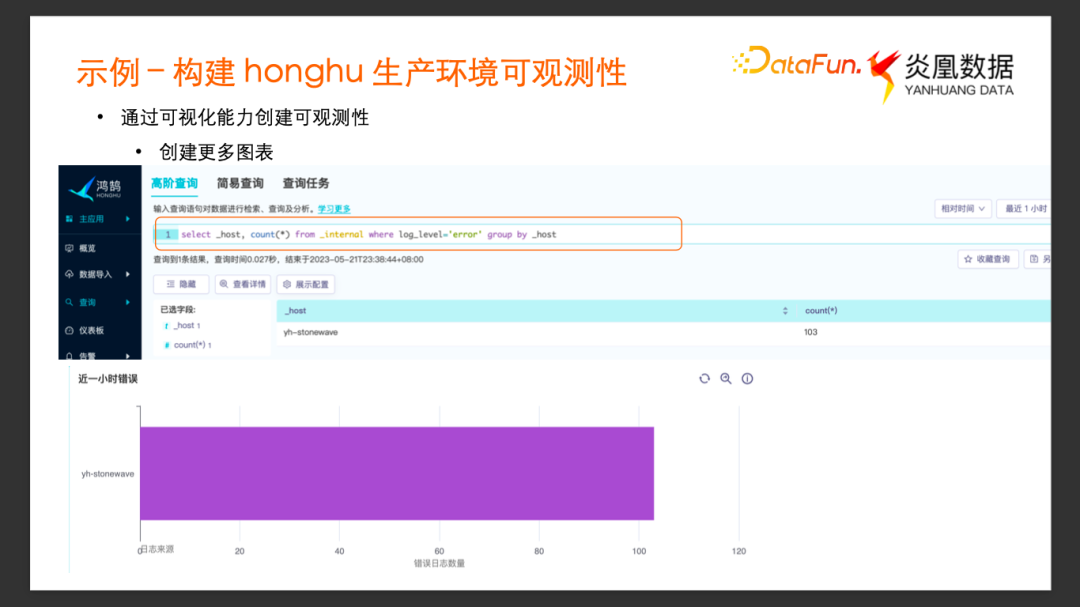
把这个图表添加到仪表板以后,继续添加更多的图表。
为了检测系统内部是否有异常状态,可以对_internal 的 Log 进行更多的分析。比如不同服务打印的 Error Log 的数量,以及 Error Log 分别来自于哪些服务,我们以_host 作为分组指标,统计最近一个小时内 Log Level 是 Error 的计数。
查询的结果可以看到有一个服务有 103 条 Error Log。把这个查询新建为一张条形图,也添加到仪表板去。
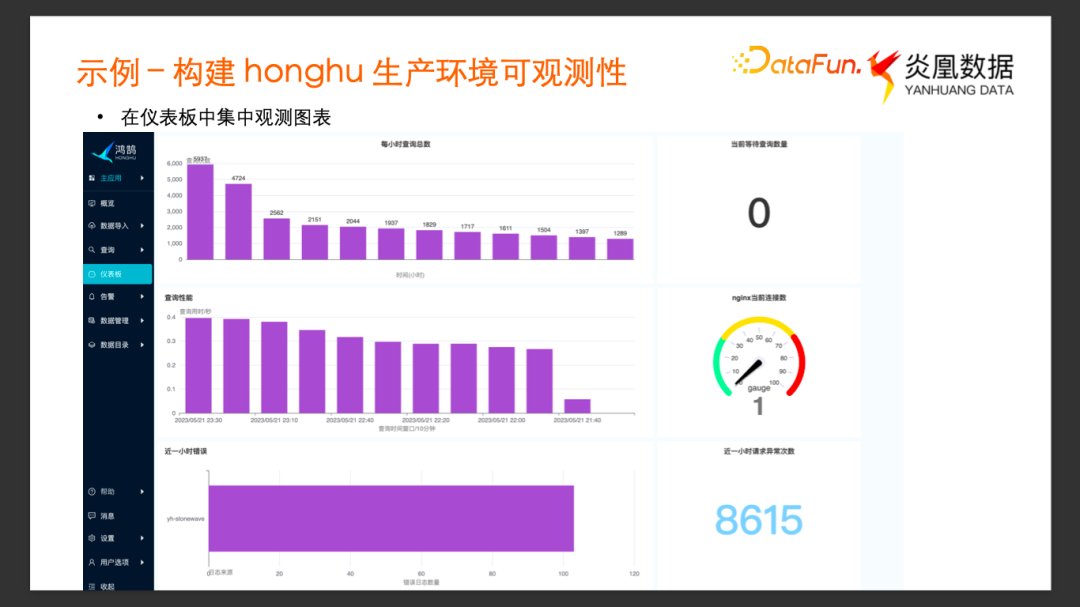
我们继续通过不同的查询构建不同的图表,并添加到仪表板,最终得到了以上的示例仪表板。
通过这个仪表板,我们可以观测到每个小时内鸿鹄系统查询的总数,反映了系统当前的业务负载;可以观测到每 10 分钟内的平均查询用时,以及当前在队列中等待的查询总数,通过这些图表可以实时查看查询系统是否过载。我们还可以通过查看 Nginx 当前连接数的仪表盘近一个小时内异常请求次数的单值图,来观察内部Web 服务的状态;通过Error Log 的条数观察内部的服务是否状态异常等等。通过添加图表,自由拖拽图表排版,以及设置合适的刷新间隔,就构建了一个实时可观测的仪表板。
4、利用查询定位问题
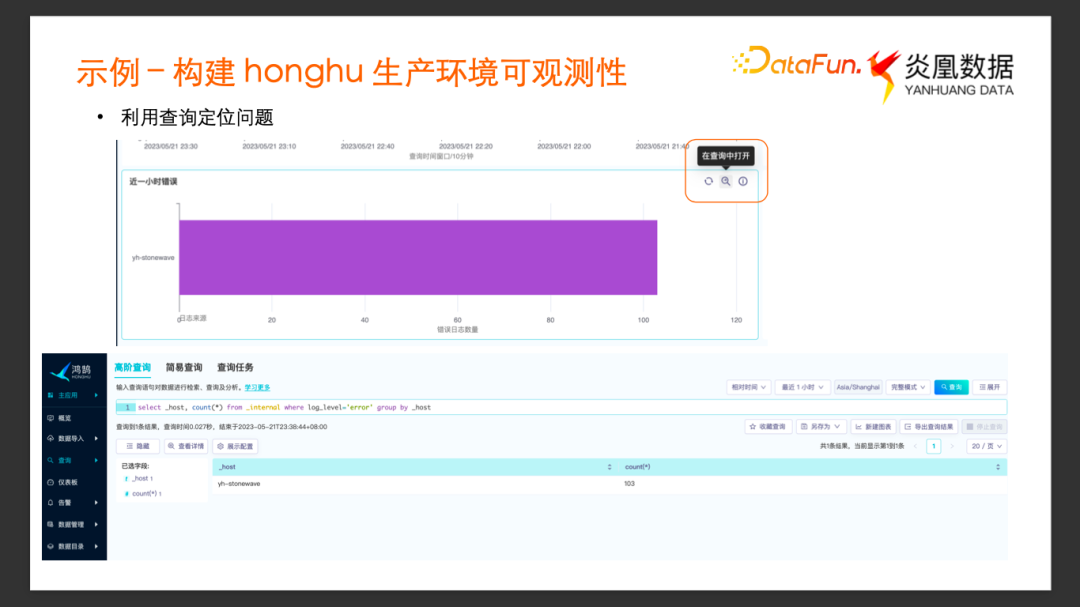
我们再来看看可观测性系统的另一个应用场景:发现与定位系统问题。
我们在前面创建的 Error Log 计数统计图表中,发现 stonewave这个服务打印了多条错误日志,于是我们尝试通过鸿鹄去定位这个问题。
点击图表右上角的 “在查询中打开” 按键会弹出一个窗口,进入图表对应的查询。为了理解发生了什么样的错误,我们对查询的 SQL 语句进行了适当的修改。

通过查询列出这个服务具体有哪些 Error Log,通过 Error Log 内容,大致可以了解服务发生了怎样的 Error,但是此时可能还不确定是什么原因导致了这个error。

于是进一步对单条的Log 进行分析,在有问题的这条 Log 事件操作中选择“查看事件上下文”。

用于定位的这条 Log 被蓝色高亮显示,也可以看到这个时间点前后的一些 Log。
然后通过右上方展示的信息,我们可以知道这个事件的上下文展示的是和该条 Log 相同 Host,相同 Source 来源的 Log 事件的上下文,是不会跟其它服务混淆的。这里默认的上下文 Log 数量是50,如果数量不足以辅助我们进行分析,也可以选择更大的行数。
通过往前回溯或者往下追踪其他 Log,可以进一步定位是什么原因导致了这个 Error,以及这个 Error 可能产生哪些后续的影响。
这就是一个可观测性辅助定位问题的例子。从最直观的可视化的图表开始去发现问题,然后通过进一步查询及下探这个事件的上下文,最终定位问题产生的原因及可能的影响,来辅助我们决策是否需要以及如何对出现问题的服务进行干预以保证服务的正常运行。
5、示例总结
以上就是利用鸿鹄 + Vector 去构建可观测性的实例。
在这个可观测性的数据流水线中,我们利用 Vector 的日志采集能力完成了数据的采集和加工,并将我们关心的事件导入到鸿鹄中,然后利用鸿鹄系统的实时查询以及可视化能力,完成对生产环境中各服务的实时分析以及可视化。最后还可以利用鸿鹄的告警功能设定一些查询计划,对于异常的查询结果可以采用邮件或者 Webhook 等方式完成告警。
这里只展示了部分的可观测性场景,在实际生产环境中检测的系统状态会比这里展示的更加复杂多样。在鸿鹄的企业版里面,使用的是 Kubernetes 的集群,K8S 的集群,里面会有更多的节点和更多的服务。需要观测的数据量也会要大得多。通过 Vector 的灵活性以及鸿鹄自身强大的异构数据的分析能力,能够高效地构建整个集群的可观测性。
除了上面分享的案例外,鸿鹄社区中还有很多利用 Vector 与鸿鹄构建可观测性数据流水线的案例。

大家如果感兴趣,可以通过鸿鹄的文档社区查看具体的实践。
以上就是本次分享的内容,感谢大家。
六、Q&A
Q1:Vector 通过 Agent 部署,支持收集 Docker 的日志,那么对于 Kubernetes 的日志来说也是能收集的。但是 Container 日志当中包含 Liveness 和 Readness probe ??的间隔信息,使用 Vector 是否可以收集并且聚合事件?
A1:Vector支持直接收集kubenetes logs,至于对liveness和readiness的聚合,可以通过 Vector 的 Transform 的功能来做,需要用户自己去编写 VRL配置。
Q2 :刚才陈老师有提到这个 Vector 里边具有缓冲策略,那是不是说如果数据采集中的数据流量较大,它能够保证数据不丢?
A2:Vector 提供具有一定灵活性的缓冲策略,能够通过配置一定大小 Memory Buffer,或者 Disk Buffer 来缓冲未处理完的事件。但是如果超过配置的大小的时候,会按一定策略丢弃掉未处理完的事件,所以它也是可能会丢数据的,取决于具体的实践中怎么样去调整它的配置。如果是对数据丢失比较敏感的场景中,建议还是去搭配一些比较成熟的 Memory queue的工具,例如 Kafka 结合使用保证更健壮的 Durability 特性。
Q3:关于 Vector 的一个图形界面的问题,目前看到的这些 Transform 的逻辑,需要专门写 VRL 语言的代码,是不是学习成本比较高?有没有图形化的界面可以拖拽来做 Transform 的操作?
A3:据我了解 Vector 好像没有图形界面的。关于 VRL 语言,个人觉得学习成本不算太高,大家可以看它的官方文档,里面有比较详细地列出了每一个的语法,以及内置的一些 Remap 函数的示例,整体的语法还是相对简单跟清晰的。
个人觉得没有图形界面,是它产品本身的特点决定的,它提供了很灵活的部署的方式,所以很多时候 Vector 是作为容器部署在集群内部,作为后台服务去运行的。只是一个简单的可执行文件 + 配置文件的搭配,很容易地去移植到不同的容器、不同的服务中。图形化的配置界面更适合是一些 Saas 或者基于 SaaS 的采集工具,资源都是集中在云上的,需要有一个统一的配置页面来用来管理这些配置,跟 Vector 的应用场景可能不太一样,所以我觉得 Vector 可能不需要也没有动力去做图形界面的管理工具。
Q4:Vector 运行之后是不是支持配置文件的热加载?
A3:vector支持热加载,可以在修改配置后reload,也可以在启动时使用watch选项自动观测配置文件的变化并热加载。它可以 gracefully restart, 保证加载新的配置以后不会把之前的一些进行一半的一些任务丢掉。
Q5:运行中的 Vector Transform 的节点是否能够根据数据量的大小做扩容和缩容, Vector 是怎么解决类似的这样的问题的?
A5:如果是考虑到单个vector服务的并发性能的话,Vector有一个很好的 Concurrency 的并发模型,不需要通过人为地去干预它的并发配置的调整,它会根据数据量大小去相应调整并发线程。不需要用户人为配置。
如果说的是vector节点数量的扩容的话,那其实涉及到具体的部署形式和场景的不同,可能需要考虑的东西也不一样,没法很笼统地概括。
Q6:采集到的数据经过多次的聚合之后,是否还能够保持数据的有序性?
A6:每一条原始event都会有 个timestamp ,这个timestamp可能是数据源产生的,也可能是vector帮你添加的。由于聚合操作是多到一的操作,因此每经过一次聚合,产生的新的 timestamp可能就与原始事件不同了。所以虽然vector能保证原始事件采集的有序性, 但是如果你经过了自定义的聚合操作,那聚合后的数据是否还是”有序的“,就要取决于你的聚合操作里的具体逻辑了。
Q7:收集到的数据有没有匹配的预警模型库?
A7:这位同学可能了解过数据可观测性相关的一些工具,比如说什么 Databend 或者 Integrate 这种工具专门用来做数据可观测性的,把整个链路都做得很完善,可以直接通过某个数据模型去生成预警。
但是我们的这套策略, Vector 本身不支持这个功能,而鸿鹄是一个实时的综合的通用的异构日志分析平台,可以利用鸿鹄的告警功能,通过 Vector 把数据导进来,然后自己去构建针对日志数据的查询,再通过鸿鹄的告警功能周期性地 Schedule 你关心的查询,根据查询的结果去触发相关的告警的功能。这是我们是用比较通用的工具做到专用工具能做到的事情的例子。
Q8:Vector 里边有丰富的 Transform 的功能,比如,日志解析的函数,看到最后的示例里边好像收集鸿鹄生产环境的日志的时候,没有用到很多的解析功能,这是什么样原因?
A8:这位同学观察得非常细致,在刚才采集内部日志和 Metrics 过程中,没有用之前提到的很多的 Transform 的方法,比如,既定数据格式的解析。这里面有两个原因,一个是当我们使用 Vector 的 Transform 去做一些解析并提取字段的时候,我们往往是很清楚自己需要这个原始的事件中的哪些字段信息的。同时会去丢弃掉一些不需要的字段信息。我们的内部 Log 其实包含了很多字段信息,在鸿鹄中做分析之前,很多时候我们不知道哪些信息是确定不需要的,所以更多的选择不在 Vector 采集的过程中去解析原始的事件。第二个原因是由于鸿鹄本身也有很强大的导入时以及查询时的事件解析功能,可以通过 Vector 只导入原始的事件,在鸿鹄中做字段解析,并索引解析后的字段,也可以去在查询的时候再决定如何对原始的事件做解析,抽取出关心的字段信息。
总的来说,由于鸿鹄有比较好的解析和查询能力,所以我们可以尽量地保留原始的日志事件,获得对日志解析的能力。所以在自己使用的时候,就觉得没有必要在 Vector 中提前做确定性的解析,因为这就丢失了后面可能用到的信息。
Q9:日志有做加密吗?行业内有没有安全存储的要求?
A9:第一个问题日志有没有做加密是想问日志中的一些敏感信息字段能否加密吗?vector的 Transform 过程中有很多的方法,可以针对某一些特定字段做处理,例如redact这个VRL function就可以对敏感字段的数据做mask处理。
第二个问题行业内有没有安全存储的要求? 日志在进入到鸿鹄系统以后是以我们特定的格式存储的。我不太确定你这里说的“行业内安全存储要求”具体是指什么,如果问题能描述得更清楚些我们可以再进一步讨论下。
主持人:关于这一块加密这一块的话可以稍微做一点补充,关于日志做加密,我猜想是想说做 Vector 做日志采集传输的时候,有没有一些加密的功能?本身 Vector 可以配置这个 TSL、SSL 传输的,可以通过这样的方式来保证传输过程当中的数据的安全可靠。也可以看一下鸿鹄社区最佳实践的文章里面也有相关的这个文章讲怎样做加密的数据传输?
Q10:多节点扩容 Vector 有解决方案吗?
A10:Vector 支持作为 Agent 以及 Aggregator 的不同部署形式,并且在配置上也支持热加载,不同vector之间也没有状态耦合。这些特性决定了在集群中添加或减少vector服务数量是比较方便的。但是同样的,“多节点扩容解决方案”也是一个比较笼统的需求,还是得看用户具体的业务部署模型是什么样的,才能更具体地解答这个问题。