一、元学习
1、个性化建模的痛点

在推荐场景会遇到数据二八分布的问题,20%的场景应用80%的样本,这就导致一个问题:单模型对大场景预估更友好。如何兼顾各场景,提升模型个性化能力是个性化建模的痛点。
业界方案:
- PPNet/Poso:这种模型通过偏置gate等实现个性化,性能和成本较优,但是多个场景共享一套模型参数,个性化表征受限制。
- 端上个性化:在每一个端上部署一个模型,利用端上的实时数据进行训练,实现端模型参数的个性化,但是会依赖端的性能,并且模型不能特别大,需要使用小模型进行训练。
针对业界模型存在的问题,我们提出了如下解决思路:
- 利用云端丰富算力,为每个场景部署一套模型,实现模型的极致个性化;
- 模型通用性强,可应用于用户/人群/item等个性化建模场景。
2、元学习解决模型个性化问题

- 需求:为每个用户、人群部署一套个性化的模型,模型对成本和性能是没有损失的。
- 方案选型:如果为每一个用户都部署一套模型,模型结构不一样、模型参数也不一样,会造成模型训练和服务的成本比较高。我们考虑在同一模型结构下,为每个场景提供个性化的模型参数,来解决模型个性化的问题。
- 部署地点:将模型部署在云上,利用云上的丰富算力进行计算;同时想在云上,对模型进行灵活控制。
- 算法思路:传统的元学习是解决少样本和冷启动的问题,通过对算法的充分了解,在推荐领域,运用元学习的创新性来解决模型极致个性化的问题。
整体思路是利用元学习在云端为每一个用户部署一套个性化模型参数,最终达到对成本和性能没有损失的效果。
3、元学习(meta-learing)介绍

元学习指的是学习到通用知识来指导新任务的算法,使得网络具有快速的学习能力。例如:上图中的分类任务:猫和鸟、花朵和自行车,我们将这种分类任务定义成K-short N-class 的分类任务,希望通过元学习,学习到分类知识。在预估finetune过程,我们希望对于狗和水獭这样的分类任务,用很少的样本,进行微调就能得到极致的预估效果。再举一例,我们在学习四则混合运算时,先学习加减,后学习乘除,当这两个知识掌握了,我们就能够学习这两个知识融在一起如何来算,对于加减乘除混合运算,我们并不是分开来算,而是在加减乘除的基础上,学习先乘除后加减的运算规则,再用一些样本来训练这个规则,以便快速了解这个规则,以至于在新的预估数据上得到比较好的效果。元学习的思路与此类似。

传统的学习方法,目标是学习到使得所有数据达到最优的θ,即全局最优的θ。元学习是以task为维度,来学习场景上的通用 ,在所有场景上面loss都能达到最优。传统的学习方法学到的θ,更靠近大场景的人群,对大场景预估更好,对中长尾预估效果一般;元学习是学习到各个场景都相近的一个点,在用每个场景的数据或新的场景的数据在这个点上进行微调,达到各个场景最优的一个点。所以可以实现,在每一个场景构建个性化的模型参数,达到极致个性化的目标。上述实例中是以人群为task进行元学习,也适用于用户或item为task进行建模。
,在所有场景上面loss都能达到最优。传统的学习方法学到的θ,更靠近大场景的人群,对大场景预估更好,对中长尾预估效果一般;元学习是学习到各个场景都相近的一个点,在用每个场景的数据或新的场景的数据在这个点上进行微调,达到各个场景最优的一个点。所以可以实现,在每一个场景构建个性化的模型参数,达到极致个性化的目标。上述实例中是以人群为task进行元学习,也适用于用户或item为task进行建模。

元学习有三种分类:
- 基于度量的方法(Metric-based):利用KNN、K-means等度量学习方法,来学习新的场景和当前已经存在的场景的距离,预估属于哪一个分类,代表算法是Convolutional Siamese、Neural Network、Matching Networks、Prototypical Networks.
- 基于模型的方法(Model_based):通过memory或RNN等快速学习模型参数,代表算法是:Memeory-Augmented、Neural Networks
- 基于优化的方法(Optimization-based):这是近几年比较流行的方法,利用梯度下降方法为每一个场景计算loss,来获取最优参数,代表算法是MAML,目前是采用这种算法来进行个性化建模。
4、元学习算法

Model-Agnostic Meta-Learning(MAML)是与模型结构无关的算法,适合通用化,分为两部分:meta-train和finetune。
meta-train有一个初始化θ,进行两次采样,场景采样和场内样本采样。第一步,场景采样在这一轮采样过程中,全体样本有十万甚至上百万的task,会从上百万的task中采样出n个task;第二步,在每个场景上,为这个场景采样batchsize个样本,把batchsize个样本分为两部分,一部分是Support Set,另一部分是Query Set;用Support Set 使用随机梯度下降法更新每个场景的θ;第三步,再用Query Set为每个场景计算loss;第四步,把所有的loss相加,梯度回传给θ;整体进行多轮计算,直到满足终止条件。
其中,Support Set可以理解为训练集合,Query Set理解为validation集合。

Finetune过程和meta-train过程很接近,θ放在具体的场景中,获取场景的support set,利用梯度下降法(SGD),获得场景的最优参数 ;使用
;使用 对task场景待打分的样本(query set)产生预估结果。
对task场景待打分的样本(query set)产生预估结果。
5、元学习工业化挑战

将元学习算法应用在工业化的场景中会有比较大的挑战:元学习算法的meta-train过程涉及到两次采样,场景采样和样本采样。对于样本而言,需要把样本组织好,同时按照场景的顺序存储下来并进行处理,同时需要一个字典表来存储样本和场景的对应关系,这个过程十分消耗存储空间和计算性能,同时需要将样本放到worker中进行消费,这对工业化场景具有非常大的挑战。
我们有如下的解决方法:
- 解法1:在meta-train batch内进行样本选择,同时,对于千万量级的模型训练,我们修改无量框架,以便支持元学习样本组织和千万量级的模型训练。传统的模型部署方式是在每一个场景中都部署一套模型,这会导致千万量级模型size非常大,训练和serving成本增加。我们采用即调即用即释放的方式,只存储一套模型参数,这样可以避免增加模型大小。同时,为了节省性能,我们只学习核心网络部分。
- 解法2:在serving过程进行finetune,传统的样本存储链路,使样本的维护成本较高,因此我们摒弃传统的方式,只存储中间层的数据,作为元学习的输入。
6、元学习方案

首先在meta-train中实现batch内场景和样本的选择,每个batch内会有多条数据,每个数据属于一个task。在一个batch内,将这些数据按照task抽取出来,抽取出来的样本放到meta-train训练过程中,这样就解决了需要独立维护一套场景选择和样本选择的处理链路的问题。

通过实验调研以及阅读论文,我们发现,在fine-tune以及在元学习过程中,越接近预估层,对模型的预估效果影响越大,同时emb层对模型的预估效果影响较大,中间层对预估效果没有很大的影响。所以我们的思路是,元学习只选取离预估层较近的参数就可以,从成本上考虑,emb层会导致学习的成本增加,对emb层就不进行元学习的训练了。

整体训练过程,如上图中的mmoe的训练网络,我们对tower层的参数进行学习,其他场景的参数还是按照原始的训练方式来学习。以user为维度来进行样本的组织,每一个用户有自己的训练数据,把训练数据分为两部分,一部分是support set,一部分是query set。在support set中,只学习local侧的内容进行tower update,进行参数训练;再用query set数据对整体的网络进行loss计算后梯度回传,来更新整个网络的参数。
因此,整个训练过程是:整体网络原训练方式不变;元学习只学习核心网络;从成本方面考虑,embedding不参与元学习;loss=原loss+元loss;fintune时,把emb进行存储。serving过程,用emb微调核心网络,同时可用开关来控制元学习随开随关。
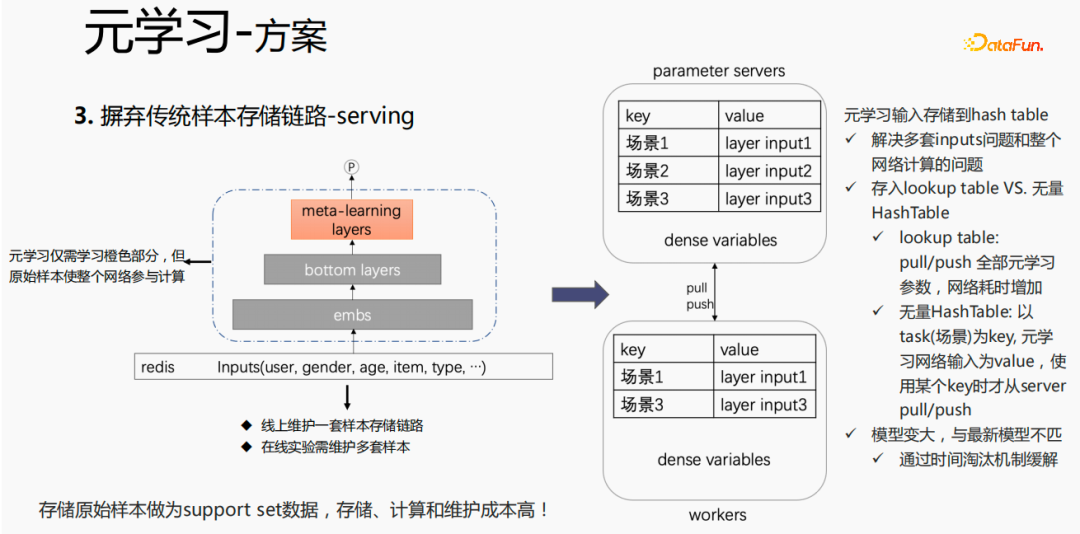
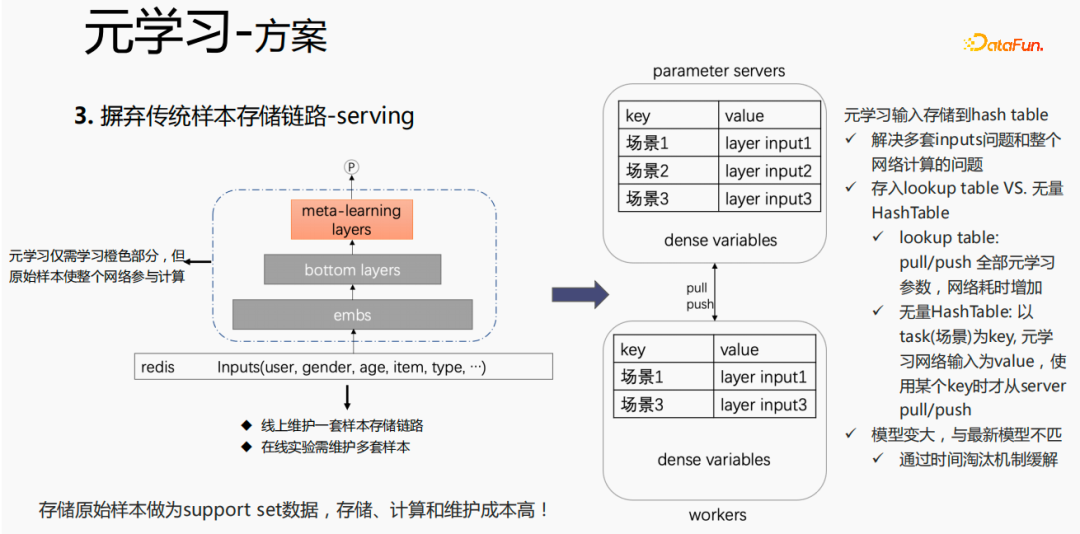
对于传统的样本存储方式,如果在serving过程,直接进行finetune,会存在较严重的问题:需要在线上维护一套样本存储链路;多套在线实验需要维护多套样本。同时,finetune过程,用原始样本进行finetune,样本要经过emb层、bottom layers层以及meta-learning层,但是元学习在serving过程仅需要学习meta-learning layers,不关心其他部分。我们考虑在serving过程,仅保存meta-learning input 存到模型中,这样就能节省样本链路的维护,同时达到一定的效果,如果只存emb这一部分,可节省该部分的计算成本和维护成本。
我们采用如下的方法:
把存储放到模型的lookup table中,lookup table 会被认为是一个 dense 的 variables,存储在ps中,所有的参数都会pull到worker 上,更新时,也会push到所有的 variables ,这样会增加网络的耗时。另一种方式是使用无量HashTable,HashTable是以key、value的形式存储,key是场景,value是meta layer的input,这样做的好处是,只需将所需要的场景的input layer从ps上进行push或者pull,整体会节省网络的耗时,所以我们采样该方法来存储meta layer 的input。同时,如果将 meta-learning layers 存储到模型中,会使得模型变大,也会遇到过期的问题,导致和目前的模型不匹配,我们使用时间淘汰极致来解决该问题,即淘汰掉过期embedding,这样既使得模型变小,也能解决实时性的问题。

这个模型在 serving 阶段,会使用embedding,embedding输入到bottom layers,打分时,并不像原始的方式一样,而是通过meta-learning layers拿到support set 中的数据,将该层的参数更新,使用更新后的参数进行打分。这个过程在GPU上无法进行计算,因此我们在CPU上执行该过程。同时,无量GPU推理做了Auto Batch合并,将多个请求进行合并,合并后的请求在GPU上进行计算,这样处理,梯度会随着batch的增加而变化,针对该问题,我们在batch和grad的基础上,增加一个num维度,计算梯度时,将grad进行相加,按照num 进行处理后,保持梯度的稳定性。最终实现成本和性能可控,同时实现了千境千模。
7、元学习工业化实践

借助框架、组件将元学习通用化,用户接入时,只需修改模型代码,用户无需关心训练和serving,只需调用我们已经实现好的接口,例如:support set读写接口、meta-train和finetune实现接口以及GPU serving适配接口等。用户只需传入loss、task inputs、label等业务相关参数。这样设计,节省了算法工程师调研、开发、实验和试错的成本,提升了算法的迭代效率;同时,通用化的代码,可服务多个业务场景,节省人力和资源成本。
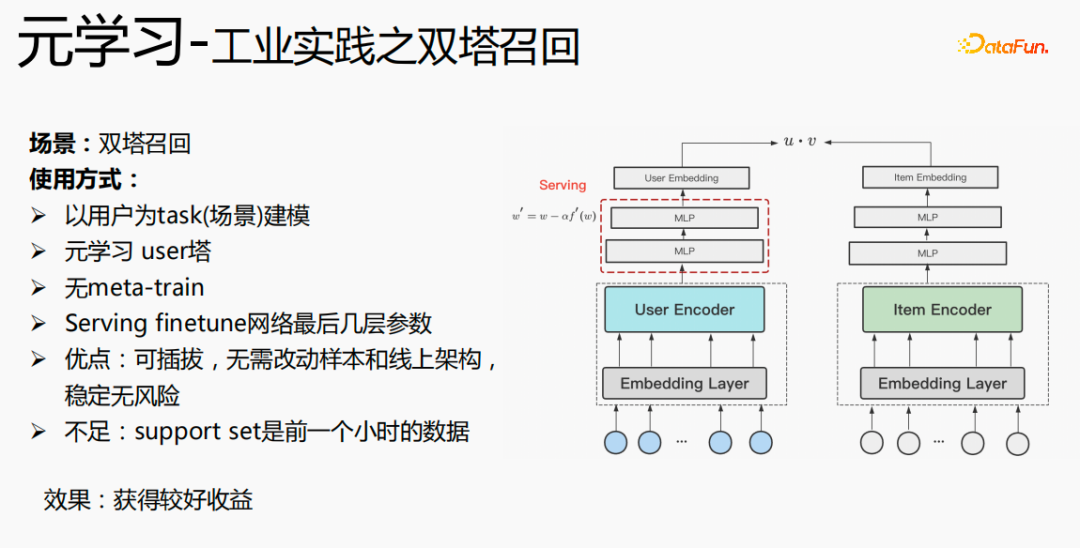
元学习在双塔召回场景下的使用,是以用户为维度进行建模,包括user塔和item塔。模型的优点是:可插拔,无需改动样本和线上架构,稳定无风险;缺点是support set是前一个小时的数据,存在实时性的问题。

元学习的另一个应用场景是在序列召回场景,该场景是以用户为场景来建模,以用户的行为序列作为support set,用户行为序列只有正样本,我们会维护一个负样本队列,采样队列中样本做为负样本,并拼接上正样本作为support set。这样做的好处是:实时性更强,成本更低。

最后,元学习也应用在排序场景中,如上图中的mmoe精排模型,实现方式有两种:仅使用finetune,以及同时使用meta-train和finetune。第二种实现方式效果更优。

元学习在不同的场景中都取得了较好的收益。
二、跨域推荐
1、跨域推荐痛点

每个场景有多个推荐的入口,需要为每个场景都建立一套召回、粗排到精排的链路,成本较高。尤其小场景和中长尾流量数据稀疏,优化空间受限。我们能否将一个产品内相似推荐入口的样本、离线训练和在线服务融合成一套,达到节省成本并提升效果的目的。

但是,这样做也存在一定的挑战。在浏览器上搜索谷爱凌,会出现相关搜索词,点击具体的内容并返回后,会出现结果点击后的推荐,这两种的流量占比、点击率以及特征分布的差异都比较大,同时在预估目标上也有差异。

如果将跨域的模型使用多任务模型,就会产生比较严重的问题,并不能拿到比较好的收益。

在腾讯实现跨场景建模具有较大挑战。首先在其他企业,两个场景的特征能够一一对应,但在腾讯的跨域推荐领域两个场景的特征无法对齐,一条样本只能属于一个场景,数据分布差异大,预估目标难对齐。

针对腾讯跨域推荐场景的个性化需求,采用上述方式进行处理。对于通用特征进行shared embedding,场景个性化的特征自己独立 embedding空间,在模型部分,有共享的expert和个性化的expert,所有的数据都会流入共享的expert,每个场景的样本会数据各自的个性化expert,通过个性化gate将共享expert和个性化expert融合,输入到tower,用star的方式来解决不同场景的目标稀疏的问题。对于expert部分,可以采用任意的模型结构,例如Share bottom、MMoE、PLE,也可以是业务场景上的全模型结构。该方式的优点是:模型的通用性强,适合各类模型融合接入;由于可以直接将场景expert迁移,对原场景效果无损,实现跨场景知识迁移效果提升;融合后模型减小,训练速度提升,同时节省成本。
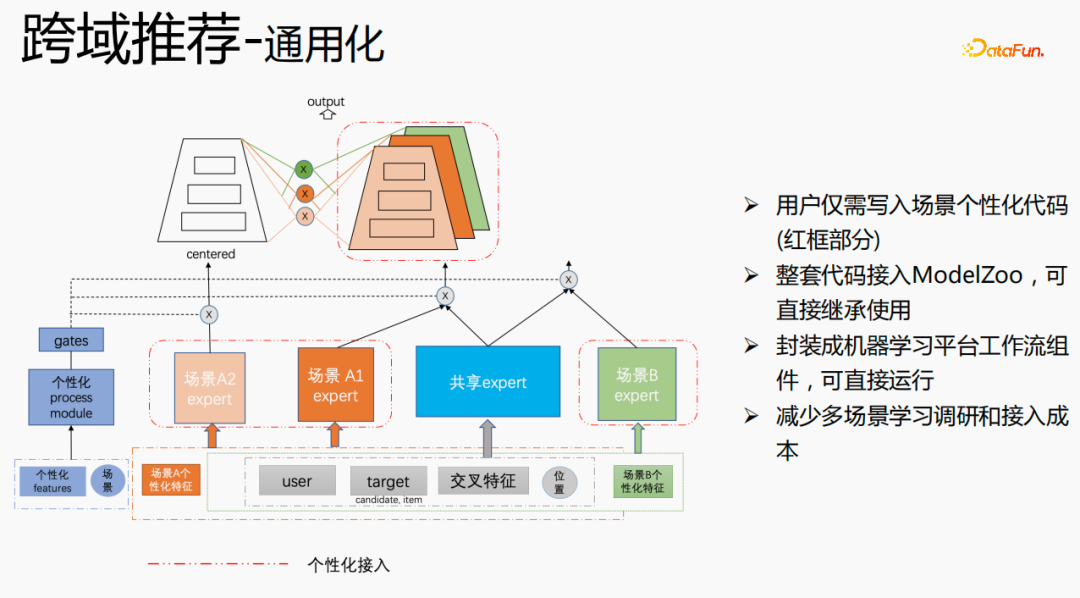
我们进行了通用化建设,红色部分是需要个性化接入的内容,例如:个性化特征、个性化模型结构等,用户只需写入个性化的代码即可。其他部分,我们已经将整套代码接入ModelZoo,可直接继承使用,并将其封装成机器学习平台工作流组件,可直接运行,该方式减少了多场景学习调研和接入成本。

这种方式使样本量变多,模型结构变得复杂,但效率反而提升了。原因如下:由于一些特征是共享的,融合后的特征数比两个场景特征数的加和要少;由于shared embedding的功能,batch内key均值,比两个场景的加和要小;减小了从server端pull或push的时间,从而节省了通信耗时,整体降低了训练耗时。
多场景的融合能使整体成本减少:离线样本处理,能够减少21%的成本;采用CPU追数据,会节省24%的成本,同时模型的迭代时间也会减少40%,在线训练成本、在线服务成本、模型大小都会降低,所以使全链路的成本降低了。同时,将多个场景的数据融合在一起,更适合GPU计算,将两个单场景的CPU融合到GPU上,节省的比例会更高。

跨域推荐可通过多种方式来使用。第一种,多场景单目标的模型结构,可直接使用多场景的建模架构,不建议使用tower侧的star;第二种,多场景多目标的融合,可直接使用多场景的建模框架;第三种,同一个精排产品,不同目标模型融合,可直接使用多场景建模框架,不建议使用tower侧的star;最后一种,同产品多个召回、粗排模型融合,目前正在进行中。

跨域推荐不仅在效果上有提升,在成本上也节省了很多。