问题背景
在大数据行业内,尤其是数仓建设中,一直有一个绕不开的难题,就是大表的分析计算(这里的大表指亿级以上)。特别是大表之间的 Join 分析,对任何公司数据部门都是一个挑战!
主要有以下挑战:
- 由于数据量大,分析计算时会耗费更多 CPU、内存和 IO,占用大量的集群资源。
- 由于数据量大,分析计算过程缓慢,挤占其它任务资源使用,从而影响数仓整体任务产出时间。
- 由于数据量大,长时间占用资源,会造成该任务在时间、资源和财务各方面成本巨大。
当前业内流行的优化方案
1.增加集群资源
优点:简单粗暴,对业务和数据开发人员友好,不用调整。
缺点:费钱,看你公司是否有钱。
2.采用增量计算
优点:可以在不大幅增加计算集群成本的情况下,完成日常计算任务。
缺点:对数据和业务都有一定要求,数据一般要求是日志类数据。或者具有一定的生命周期数据(历史数据可归档)。
问题场景和 Spark 算法分析
Spark 经典算法 SortMergeJoin(以大表间的 Join 分析为例)。
- 对两张表分别进行 Shuffle 重分区,之后将相同Key的记录分到对应分区,每个分区内的数据在 Join 之前都要进行排序,这一步对应 Exchange 节点和 Sort 节点。也就是 Spark 的 Sort Merge Shuffle 过程。
- 遍历流式表,对每条记录都采用顺序查找的方式从查找表中搜索,每遇到一条相同的 Key 就进行 Join 关联。每次处理完一条记录,只需从上一次结束的位置开始继续查找。
该算法也可以简化流程为: Map 一> Shuffle 一> Sort 一> Merge 一> Reduce

该算法的性能瓶颈主要在 Sort Merge Shuffle 阶段(红色流程部分),数据量越大,资源要求越高,性能越低。
大表问题思考
大数据计算优化思路,核心无非就三条:增加计算资源;减少被计算数据量;优化计算算法。其中前两条是我们普通人最常用的方法。
两个大表的 Join ,是不是真的每天都有大量的数据有变更呢?如果是的话,那我们的业务就应该思考一下是否合理了。
其实在我们的日常实践场景中,大部分是两个表里面的数据每天只有少量(十万百万至千万级)数据随机变化,大部分数据是不变的。
说到这里,很多人的第一想法是,我们增加分区,按数据是否有变化进行区分,计算有变化的(今日有更新的业务数据),合并未变化的(昨日计算完成的历史数据),不就可以解决问题了。其实这个想法存在以下问题:
- 由于每个表的数据是随机变化的,那就存在,第一个表中变化的数据在第二个表中是未变的,反之亦然(见图片示例)。并且可能后续计算还有第三个表、第四个表等等呢?这种分区是难以构建的。
- 变化的数据如果是百万至千万级,那这里也是一个较大规模的数据量了,既要关联计算变化的,也要关联计算未变化的,这里的计算成本也很大。
 图片
图片
问题读到这里,如果我们分别把表 A、表 B 的有变化记录的关联主键取出来合并在一起,形成一个数组变量。计算的时候用这个变量分别从表 A 和表 B 中过滤出有变化的数据进行计算,并从未变化的表(昨日计算完成的历史数据)中过滤出不存在的(即未变化历史结果数据)。这样两份数据简单合并到一起,不就是表 A 和表 B 全量 Join 计算的结果了吗!
那什么样的数组可以轻易的存下这百万千万级的数据量呢?我们第一个想到的答案: 布隆过滤器!
使用布隆过滤器的优化方案
- 构建布隆过滤器:分别读取表 A 和表 B 中有变化的数据的关联主键。
- 使用布隆过滤器:分别过滤表 A 和表 B 中的数据(即关联主键命中布隆过滤器),然后进行 join 分析。
- 使用布隆过滤器:从未变化的表(昨日计算完成的历史数据)中过滤出数据(即没有命中布隆过滤器)。
- 合并 2、 3 步骤的数据结果。
也许这里有人会有疑惑,不是说布隆过滤器是命中并不代表一定存在,不命中才代表一定不存在!其实这个命中不代表一定存在,是一个极少量概率问题,即极少量没有更新的数据也会命中布隆过滤器,从而参与了接下来的数据计算,实际上只要所有变化的数据能命中即可。这个不影响它已经帮我买过滤了绝大部分不需要计算的数据。
回看我们的 Spark 经典算法 SortMergeJoin,我们可以看出,该方案是在 Map 阶段就过滤了数据,大大减少了数据量的,提升了计算效率,减少了计算资源使用!
Spark 函数 Java 代码实现
大家可以根据需要参考、修改和优化,有更好的实现方式欢迎大家分享交流。
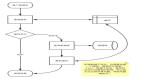
程序流程图
 图片
图片
Spark 函数 Java 代码实现。
使用示例演示
表信息和数据准备。
原来处理的 SQL 语句。
使用布隆过滤器的 SQL(Java 函数导入 Spark,函数名为 “bloom_filter”)。
从上面代码可以看出,使用布隆过滤器的 SQL,核心业务逻辑代码只是在原来全量计算的逻辑中增加了过滤条件而已,使用起来还是比较方便的。
实测效果
以我司的 “dim.dim_itm_sku_info_detail_d” 和 “dim.dim_itm_info_detail_d” 任务为例,使用引擎 Spark2。
 图片
图片
总结
从理论分析和实测效果来看,使用布隆过滤器的解决方案可以大幅提升任务的性能,并减少集群资源的使用。
该方案不仅适用大表间 Join 分析计算,也适用大表相关的其它分析计算需求,核心思想就是计算有必要的数据,排除没必要数据,减小无效的计算损耗。