撰稿 | 王瑞平
审校 | 云昭
开源、Github标星狂飙2万、CVP(即,ChatGPT+VectorDB+Prompt)架构...又一匹数据库黑马突出重围。
它就是Milvus向量数据库,几年前便在Github上开源,瞬间引爆全球,不仅完美诠释了新兴CVP架构,也成为“群模乱舞”当下的一股清流。
 图片
图片
Milvus旨在为AI应用程序和嵌入相似度搜索提供支持,使非结构化数据更易于搜索和访问,无论部署环境如何都能使用户获得相同的体验。
1、AIGC新纪元从“向量数据库”迈入“大模型记忆体”
Milvus以4个月5000星的速度迈入Github 2万星项目的队列,越来越多开发者也正在为Milvus进入AIGC新纪元注入更多力量。
2019年,GitHub上将Milvus的源代码开源。彼时,行业尚无“向量数据库”一说,用户最关心的问题是“什么是向量数据库”。
2023年,ChatGPT 引发AIGC热潮,在这个大模型恣意生长的年份,越来越多的人关心“向量数据库可以做什么?”
在大语言模型时代,向量数据库必不可少,它不仅是大模型的记忆体,还能通过向量检索让大模型变得博闻强识。
在此过程中,AIGC开发者可以看到的是Milvus在2.2.9版本和中新增了JSON、动态schema和PartitionKey三大功能,简化了开发者使用门槛,并接入了开源项目GPTCache,提升LLM应用性能。
2、大模型时代,数据库也需要跟上
我们正处在拥抱人人互联新时代,传输电子邮件、社交媒体照片传输、蛋白质分子结构解析等过程中都会产生海量的非结构化数据(文本文件、电子表格等)。
然而,你绝不能任由这些数据“满天飞”!所以,它们必须被计算机定期处理!那么,如何处理呢?
首先,embedding技术可以将这些数据转化为“向量”。随后,Milvus会存储这些“向量”并为其建立索引,这就形成了传说中的“向量数据库”。
与现有的主要可用作处理结构化数据的关系型数据库不同,Milvus在底层设计上就是为了处理由各种非结构化数据转换而来的Embedding向量而生。
该数据库可以对接包括图片识别、视频处理、声音识别、自然语言处理等深度学习模型,从而为向量化后的非结构数据提供搜索分析服务。
你可以使用Milvus搭建符合个人场景需求的向量相似度检索系统,具体可应用在以图搜图、视频去重、音频检索、文本搜索等场景下。
3、快速入门:安装Milvus
 图片
图片
你需要首先明确的是:Milvus使用Docker Compose控制服务的启动和暂停,过程包括:
- 新建工作目录,下载YAML文件
- 启动Milvus容器:
sudo docker-compose up -d
- 停止Milvus容器:
sudo docker-compose down
4、用例:以图搜图
Milvus官方还给出了以图搜图的用例,具体流程分为构建图像向量库和执行搜索:
 图片
图片
1)构建图像向量库
首先准备图像数据集,使用深度学习库提取图像特征,获得每张图像的特征向量,最后将特征向量存储到Milvus数据库中。
2)执行搜索
输入一张待检索图像,经过深度学习库获取图像对应的特征向量,然后将这个向量与Milvus中所有图像的特征向量进行相似度对比,从而获得距离最近的图像结果。
5、整体性能够硬,生态已成气候
从上述的安装与使用过程中我们不难看出,Milvus作为一款云原生向量数据库,具备高可用、高性能、易拓展的特点,可用于海量向量数据的实时召回。
 图片
图片
Github上也对其整体性能做出了完整总结:
- 高性能:性能高超,可对海量数据集进行向量相似度检索。
- 简化管理:专为数据科学工作流设计的丰富API;
- 高可用、高可靠:Milvus支持云上扩展,其容灾能力能够保证服务高可用;
- 高度可扩展和弹性:组件级可伸缩性使按需扩展和缩减成为可能。
- 混合查询:Milvus支持在向量相似度检索过程中进行标量字段过滤,实现混合查询;
- 开发者友好:支持多语言、多工具Milvus生态系统;
- 社区支持,行业认可:拥有超过1000名企业用户以及活跃的开源社区。
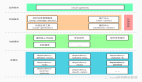
6、系统架构:四个层次
Milvus作为一款云原生向量数据库,采用存储与计算分离的架构设计,所有组件均为无状态组件,极大增强系统弹性和灵活性。
 图片
图片
整个系统架构可分为四个层次:
- 接入层:系统的门面,由一组无状态proxy组成。对外提供用户连接的endpoint,负责验证客户端请求并合并返回结果。
- 协调服务:系统的大脑,负责分配任务给执行节点。协调服务共有四种角色,分别为 root coord、data coord、query coord 和 index coord。
- 执行节点:系统的四肢,负责完成协调服务下发的指令和 proxy 发起的数据操作语言(DML)命令。执行节点分为三种角色,分别为 data node、query node 和 index node。
- 存储服务:系统的骨骼,负责Milvus数据的持久化,分为元数据存储(meta store)、消息存储(log broker)和对象存储(object storage)三个部分。
7、2.0重磅升级
在Milvus官网上,我们找到了Milvus1.0与2.0究竟有哪些区别,具体如下表:
 图片
图片
事实上,自Milvus升级至2.0版本以来,仍在不断改进优化,推出了诸如从文件中批量导入数据、基于磁盘的近似最近邻(ANN)索引算法等新功能,也提升了元数据存储、批量导入等性能。
远的不说,从Milvus 2.2到Milvus 2.3版本都进行了哪些变化和升级呢?
Milvus 2.2提升了向量搜索的稳定性、搜索速度,具有灵活的扩缩容能力,提供了一系列新的 API,用于支持从文件中更有效率地批量导入数据。
此外,Milvus 2.2还修复了部分bug并进行了诸多改进以增强Milvus稳定性、可观测性和性能。
而在2.3版本中,Milvus移除了Annoy索引,降低了维护成本,还会支持count接口,用于统计collection的行数。新增的count接口除了能计算collection行数外,还支持query的查询表达式用于统计带条件的行数。
8、用户:使用Milvus,并不孤单
从最初的Milvus到2.3版本,每一次版本升级背后都离不开用户的支持与建议。升级、迭代,每次更新过后,Milvus都会趋向于完美。
截至目前,GitHub在上已达到2.08万星。因此,当在活跃的开源社区中使用Milvus时,你并不孤单!
参考资料:
https://www.yii666.com/blog/393941.html?actinotallow=onAll
https://github.com/milvus-io/milvus
https://blog.csdn.net/hello_dear_you/article/details/127841589