本文整理自澜舟科技创始人兼CEO周明在WOT2023大会上的主题分享,更多精彩内容及现场PPT,请关注51CTO技术栈公众号,发消息【WOT2023PPT】即可直接领取。

大模型概括一下就是几件事:一是要有大规模的文本,比如说互联网文本;二是用大规模的算力、用无监督的方式训练一个大模型。大模型基本上就告诉你输入的句子或者词在上下文中的作用。你可以简单地理解出它的语义、语法、前后文的制约等等。
基于这样的理解,我们做下面的一些任务的时候,要么就做微调——在GPT-3之前,像BERT、T5都是通过微调的方式来支持下游任务的。所谓微调,就是对整个模型从底层到最高层,从输入层到输出层都要做一些调整,一个模型支持一个任务。
现在有了GPT-3以后,尤其是ChatGPT发展了提示词的功能,就不用微调了。你告诉清楚你要做什么,如果还不能执行好的话,你给它一两个例子,它就可以完成你要的相应任务,这个就大幅度提高模型的训练能力,使得一个模型可以支持N多个任务。
现在来讲,大模型代表了两件事:
第一,像ChatGPT这样的模型支持了语言理解、多轮对话和问题求解,使这些功能进入到了可实用的阶段。
第二,解决了AI或NLP任务碎片化开发问题,大幅度提高了研发效率,标志着NLP进入了工业化可实施阶段。
大模型引导智能水平越来越高
AI最近几年从AI 1.0到AI 2.0,到未来的AGI一点一点发展,整个趋势,就是能力越来越强,开发效率越来越高,使用越来越简单,结果越来越可控。

什么叫AI 1.0呢?就是一个任务一个模型,或者一个模型就管这一个任务。除了这个任务之外,其他的任务都不怎么支持,开发的周期比较冗长,投入资源也比较高。微调了什么能力就有什么能力,没有所谓的涌现能力。我把所有大模型之前的能力,包括大模型早期的微调能力,都叫做AI 1.0模型。
有了ChatGPT和GPT-4后,就进入到所谓AI 2.0阶段。用一个提示词的技术,就把能力调用起来了。而且它上下文可以看得很长,出现了一些涌现能力。
所谓涌现能力,就是原来模型小的时候有些能力比较弱,模型一大或者数据量增加的时候,有些能力产生了跃迁,产生了一些意想不到的高水平能力。
AI 1.0和AI 2.0在目前是并存的,但是整个发展趋势是不断的从AI 1.0模型到AI 2.0模型,使得效率越来越高。
未来我们沿着这个趋势,假设一个模型支持N多任务、而且N是越来越多的话,似乎就一点点走向所谓的AGI。但是也不一定那么容易,其实还是有很多问题。比如说对结果的可解释性和不断自我学习的能力,目前的大模型还是有点弱。再比如对能力和结果的可控,要符合人类伦理和社会规范,目前也还有挑战。
但是不管怎么样,大家可以看到目前存在这样的一个趋势,就是大模型、大数据引导着智能水平越来越高。
针对大模型的困惑和挑战
大模型出来之后,各行各业都很兴奋,想要试试大模型,也认为这是一个产业升级的机会。可是他们存在着很多困惑:
- 这么多大模型,我该采购呢?还是找一家模型厂商合作呢?甚至现在开源的这么多,是不是也可以自研?
- 我不论怎么选择,怎么知道这个大模型的水平?如何评估?
- 我想知道这个大模型跟我这个行业知识、行业数据怎么一起工作。
- 大模型有正儿八经胡说八道的问题,就是所谓幻觉问题。我怎么用其长、克其短。
- 如何保护企业的隐私安全。
- 成本问题,大模型现在动不动报价几百万,甚至上千万,我怎么来节省成本?
大模型厂商也存在相应的一些挑战: - 怎么来理解行业,行业到底需要什么,不需要什么,多做什么,少做什么?
- 大模型的功能和规格,大模型越练越大,军备竞赛受得了吗?
- 最后一公里,大模型做好了之后,如何跟用户的业务嵌在一起,使它能够很平滑地运转?
- 所谓的飞轮效应。你做企业服务的话,企业有数据保护的问题,你怎么来实现飞轮效应?要么数据飞轮,要么功能飞轮。
- 大模型企业商业模式是什么?你是在云上部署、API调用、计量计费?还是到用户那里本地部署?这两者的利弊是什么?或者两者都做的话,如何随着时代的变化而做一些演变?
大模型服务企业的关键解决之道
以上简单介绍了大模型的发展,下面就介绍大模型服务企业的一些关键,我也希望我讲的这些东西对于以上的疑问有一些解答。
第一,企业为什么要用大模型?用它干什么?这不能追风,别人用了你就得用。
企业现在都面临很多的问题:一是降本增效。比如客服,服务1000人用10个人的客服,1万人就是100个客服。线性增长的话,光客服就受不了,当然还有其他方面的因素。
客服偏向于劳动密集型,还有一些所谓智力密集型行业,比如做营销文案设计,小红书、微博、微信...不同的产品有不同的风格,设计任务很繁重。
第二,企业能不能做所谓的数智化转型呢?它的前提是数据问题。企业过去十几年,尤其是央企国企都有很多好的数据存在那儿。现在恰好是大模型时代,把这样的数据好好用起来,就能够实现降本增效的功能。
大模型如果做好的话,完全可以当成一个“企业大脑”来支持各个部门的应用。
大模型时代怎么来促进企业新一代的软件开发水平呢?可能很多人都用过Copilot(微软在Windows 11中加入的AI助手),Copilot就是你编程的时候,它给你很多的提示和各种帮助。
我这里想强调的是,大模型时代实际上产生了一种新的软件工程范式,软件工程都不像以前那么做了。以前做一个项目,任务碎片化严重,数据标注代价大、开发周期大、交付成本高、维护困难。
现在有了大模型,你要做的事情是什么?就写prompt或者微调,prompt就是一个模型管N个功能,你把prompt写好之后在前面加一个界面就完事了。有的特别重要的功能你不好写prompt,或者以前没有积攒那么好的数据,你用大模型也是可以来加速整个开发过程的。
对于企业数智化转型,搞一个多大的模型才好呢?其实我们要盲目跟风的话,搞个上万亿参数的模型是不是更好呢?但这就意味着成本非常之大。这样的模型训练的代价大,部署的成本也比较高。给企业用,企业都不敢用,因为可能是32块卡以上,甚至更多的A100以上才能把大模型支起来。
对于企业服务,到底用多大模型才好呢?我这里画了一个曲线,来说明大模型应该做多大为好。
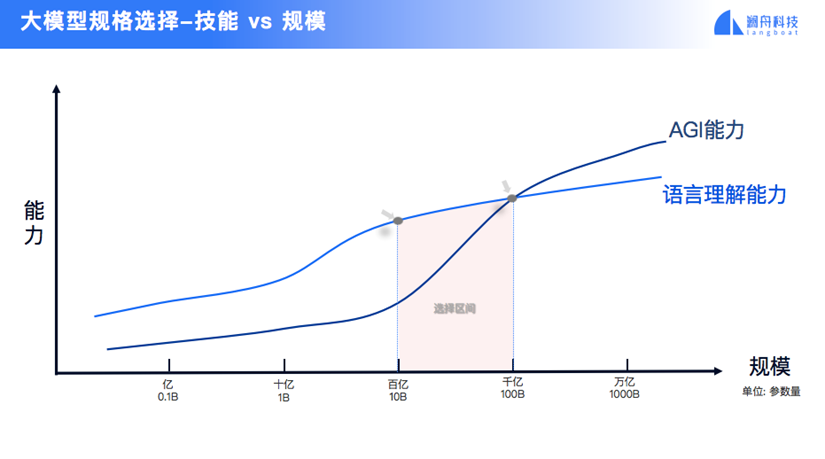
其实我们今天所看到的大模型实际上是包含了两个能力:语言理解能力和AGI能力。但是我们平时是混在一起用的,所以也分不清楚哪些地方是语言理解、哪些地方是AGI。就像高中毕业的同学跟一个院士对话,他俩的语言理解能力是一样的,但是专业水平或解题能力不一样。
那我们做企业服务的时候,更注重哪一块呢?其实更注重语言理解能力。对于解题能力,企业有专门的引擎或者专门的资深专业人士来解决,大模型有时候正儿八经胡说八道还可能添乱。
如果我们要做语言理解能力,我们要回到现实:只要做百亿模型到千亿之间任何一个选择,就可以支持企业的数智化转型了。
反过来推你需要多少卡去训,基本上是300块卡到500块卡就可以解决这样的问题了,所以大家都放心了。
大模型做好之后,我们还要问一个问题:怎么去服务企业?怎么做好最后一公里?拿着大模型到企业说“你拿去用吧,准保好用”,基本都不好用,为什么?企业的需求跟通用模型的需求是不一样的——最好的通用模型都不一定能解决企业的基本需求。
得先把人家所在的行业搞清楚,把行业的专家知识、数据灌到模型上,把你的模型充实。这就相当于高中毕业之后读了某个专业,比如计算机专业,然后才能解答计算机专业的问题。
有了行业模型,要解决具体问题的时候,还要对每一个任务场景了解,这就是所谓最后一公里的问题。
比如以金融为例,就是金融研报提取、市场情绪、金融摘要生成、金融搜索、金融实体识别等等,有很多这样的问题。你拿你的行业模型去试,如果不work的话,就得把企业已有的数据加进去,要么微调,要么写prompt,把最后一公里的问题写进去。
做大模型的人要跟企业合作,才能了解企业需求。第二你要跟企业一起做,把它的场景理解清楚,把它的业务理解清楚,把最后一公里做好。用这样的模式服务企业,才能把大模型一步一步做到比较深入、彻底。
大模型和行业模型做好之后,怎么来做商业模式?其实仁者见仁、智者见智,底层是训练,然后训出很多模型,然后有那么多功能。现在来讲,要么就是通过云的方式,API计时计量。要么有些企业说我的数据不能上公有云,我要做本地部署。

你如何给企业做深度定制,然后本地部署?你的工作效率要足够高,否则你没有钱赚,你做一个会赔一个。这是第一件事,就是你如何有一个高效率的研究、开发和交付一条龙的团队,高效率地完成从接单到支付的全过程。这时候就应该把所谓大模型的技术好好用起来,比如说大模型的prompt技术用起来,来增加开发的效率或者降低成本等等。
第二是所谓飞轮问题,你要没有飞轮的话,做完A再做B是一点收益也没有,还得从头开始做,做ToB企业服务最麻烦的就是很难产生飞轮。不过我觉得,在大模型时代,还是有一些机会能做出飞轮的。
一是在做行业模型的时候,如果是同一行业的不同企业,他们行业数据假设没有保密的话,互相之间共享,然后把行业模型越做越大,这个是有可能产生一些飞轮效应的。
二是prompt。你在服务不同企业的时候,服务的具体任务会写prompt。那些prompt一般不是保密的,因为一个prompt对应某一个功能。prompt积累下来,也会形成某种意义上的飞轮效应。日积月累的话,你对行业越了解越深,数据积累越来越多,功能越来越多,某种意义上也形成了所谓的行业壁垒,使得你这个企业在这个行业可能是做到最好。其他企业刚进来缺乏这些飞轮效应的话,可能落后于你,这样你会有先期的机会。
以金融为例,大模型如何在行业落地
大模型做完之后怎么在行业落地?我举一个金融行业的例子。金融行业大模型实际上是所谓L2模型,它是基于L1通用模型的基础上,拿金融很多不同的数据灌进去,然后训练出金融模型。
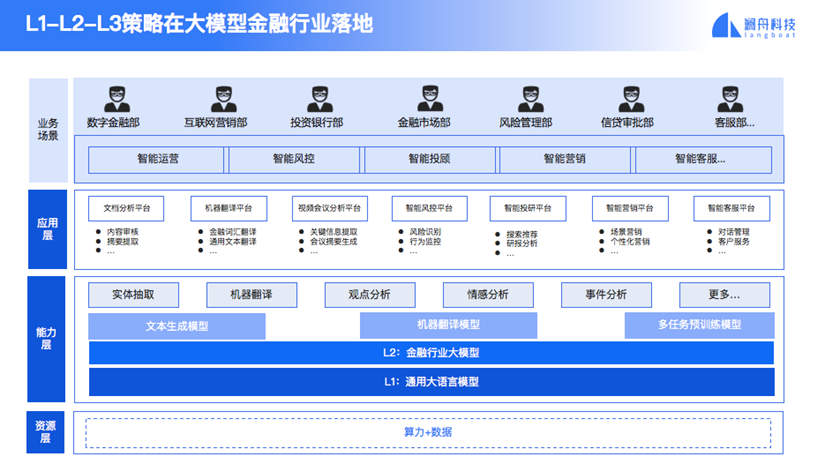
这个金融模型能够干什么呢?它能够支持金融行业通用的一些任务,比如搜索问答、翻译、文档抽取、情感分析、文档审核等等。另外支持企业的各种应用场景,就是所谓Application Driven过程,它的底座一定要强。目前我们用孟子的通用模型,就是L1模型来支持各个行业的模型开发。
假设行业模型做好之后,在金融有哪些具体的场景呢?比如说客服,我们把金融大模型做好之后,金融客服怎么做?大家知道大模型有一个正儿八经胡说八道的问题,所以简单地把客服数据端对端训练也有可能产生一些正儿八经胡说八道。比如你把前几年的数据灌进去训,说某一件商品打折了,可能业务部门突然说这个商品不打折了。大模型学习得挺好,告诉用户打折了,来买这个商品吧,那这个会对业务产生极大的烦扰。
这个时候大模型要用其长、克其短,它的长处就是意图理解和对话生成。意图理解完了之后,还是应该走客服的业务数据库。业务数据库回复结果之后,再通过大模型的生成能力,多样化、有温度、个性化的生成所谓大模型的客服场景。
客户的营销场景,比如保险公司要推销理财产品或者保险产品等等,那怎么来做营销?无非是营销内容怎么生成?保险产品怎么推荐?销售如何辅助,保险产品咨询等等。甚至营销人员的培训都可以用大模型来支撑。
我们投研人员经常要做搜索,搜索完结果后研判,再写报告。用大模型就可以把这三件事串在一起一体化来解决。大模型的匹配能力也增强了,语言理解能力增强,搜索结果就变好了。搜索完之后,对搜索结果做所谓的Chat,你可以了解一些细节,然后形成洞见、观点或者摘要。最后再通过文本生成的技术,写一篇研报发给有关人士共享。这三者都是通过一个大模型来支撑的。
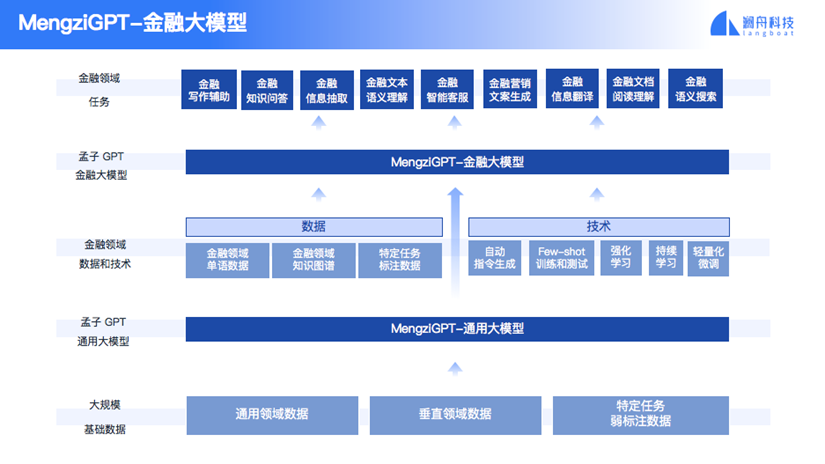
这就是孟子大模型的体系结构,最底层的是各种各样的数据,比如通用数据、金融行业的垂直数据。孟子大模型训练出来,把这些金融数据灌进去,训练一个L2金融模型,然后有各种各样的能力支撑,服务于金融企业。
最近我们练的模型,也跟现在市面上的已经开源的通用大模型和开源的金融大模型做了对比。当然,也跟我们孟子大模型本身进行了对比。大家看到,1750亿的参数的ChatGPT表现真的是不错,在很多场合都是不错的。但是我们虽然是100亿级别的模型,由于专门做行业模型,也有一些场合比ChatGPT好。
所有的金融大模型训练出来的结果,它的水平比通用模型都好那么一些。这就说明从L1走到L2是有道理的,把金融场景数据灌进去,它的水平确实得到了相应的提升。
基于这些大模型,在金融行业怎么落地?就是所谓L3的问题,很多的场景怎么落地?像我们的大模型做信用卡业务咨询、换汇业务咨询,然后海量数据中快速获取关键信息用于智能投顾,然后是金融稿件的助写,包括报告题纲和金融模板,以及理财产品的营销、养老金的营销,这些都是大模型可以写出来的,只需要把需求写清楚即可。理财咨询,金融行业中外文之间的信息交流要做翻译,目前的大模型也可以支持16种语言之间的金融领域的翻译。
如果不用Chat这种交互方式,大模型还能带来一种新的软件工程开发范式的改变。举一个例子,我们要做基于孟子大模型的行业搜索,过去非常麻烦的一件事。现在有大模型就简单了,所有这些能力用prompt就带出来了。然后用API调用这些prompt,就有这样的能力。
剩下你要做的工作,就是把界面设计清楚,体现出最佳的用户体验就行了。像这样的搜索引擎,比如可以用金融的视频会议分析,分析出它的摘要。整个会议两个多小时讲了什么东西,有哪些是正面情感,有哪些负面情感。沿着时间顺序讲了哪些主题?你可以浏览。也可以分析整个参会人员有哪几个,出现了哪些实体或者关键词,你可以快速浏览一个金融会议。
同样的道理,做金融的研判也是一样可以快速实现。大家可以看到用大模型实现具体行业L3的功能,就变得相对比较容易了。
这是再重温一下L1、L2、L3的开发场景落地过程。L1就是通用大模型,L2是金融大模型,L3是各种场景模型。利用我刚才所讲的软件工程的开发规范,用prompt来写各种各样的能力调用,就可以快速生成一些具体的场景任务。
拥抱大模型:现在不起步就落伍了
最后讲一些未来的思考,我们还是回到刚才开篇讲到的企业困惑。
第一,大模型眼花缭乱,我该采购还是找一家厂家合作研究呢?还是利用开源自己做?
我觉得不同的人有不同的需求,有的大型企业有自己的能力想自己做;有的人稍微能力弱可能去买;也有的企业能力要好不坏,可能找一些大模型厂家合作,希望培养长期的能力。
我给大家的建议,如果你的任务是通用任务,也不要重新造一个轮子,直接调大模型厂家提供的云服务。如果觉得数据不能出来,干脆聊本地化部署的问题。
如果你的任务是特殊任务需要定制,你跟大模型厂家聊一聊,看看能不能帮你定制所谓L3的能力,或者考虑要么API调用,要么本地部署。如果想自研需要考虑有没有一个厉害的团队,而且自己要有足够的大数据、大算力能力。
如果想用开源的话,你得研究开源能不能支撑这个能力,或者开源能不能支持你的内部商用。这都是很多很多的问题。如果对自研没有把握,最好找大模型厂家做深度合作。
第二,这么多大模型,包括自研的大模型怎么知道好和坏呢?
这就是所谓评测的问题,评测是很难的,但是特别重要。有一些公开评测从不同的角度评测,但都不代表权威的评测,有的是不同方面,你自己要做甄别。你喜欢哪些,不喜欢哪些,要集成在一起来做一些判断。你自己关心的任务自己要做评测,对你要采用的各种模型,包括自研和外采都要做好评测,你觉得它好再进行深入地探讨。
第三,行业知识怎么跟大模型工作?
有的人说,我的行业知识数据是不是都灌到大模型去训?你自己要判断。有的是比较稳定的数据可以灌在所谓L2模型上做Continue-Training。有的不能,你只能外挂,因为它是动态的、实时的变化,它是业务的数据。外挂怎么挂?现在有一些大模型的分发能力、调用集成像LangChain、向量数据库等等,帮助你来实现某种意义上的外挂。
第四,大模型有很多“幻觉”,怎么用其长、克其短?
最好只用它的长处,就是意图理解和多轮对话。轻易不要用它的AGI能力,如果底层有一些推理能力是可以用的,表层的AGI能力不一定可用。
第五,保护隐私的问题。
如果特别强调隐私,你就是本地化部署,否则也可以考虑云。无论哪种方式,你要对数据安全和隐私拥有完全的控制权。
第六,造价成本的问题。
现在大模型刚刚起来,练大模型的厂家花费巨大,大模型的成本是居高不下的。你要考虑,要么调用API,你就是计量计费;要么找一些小点的模型,像我这边是力推轻量化模型,因为百亿模型和千亿模型造价成本差至少10倍以上。但是在企业服务的角度来讲,百亿模型的能力跟千亿模型几乎是一样的。大家可以好好考虑这个问题。
最后强调一下,一定要拥抱大模型。不管是迟疑、观望、等待还是自研,首先要采取行动,因为大模型会改变你所在的行业和所在企业的数智化能力。如果现在不起步的话,可能就落伍了。再过两三年,你的竞争对手早就跑到你的前面去了。