大模型离线推理
特点介绍

大数据离线推理
大模型离线推理(Batch 推理)是指在具有数十亿至数千亿参数的大规模模型上进行分布式计算推理的过程,具有如下特点:
- 一次对一批数据进行推理,数据量通常是海量的,所以计算过程通常是离线计算;
- 推理作业执行过程一般同时包含数据处理及模型推理;
- 作业规模通常较大,采用分布式计算,消耗大量计算资源;
- 相比于在线推理,离线推理对延迟的要求并不高,主要关注吞吐和资源利用率。
关键挑战
GPU Memory Wall
 图片
图片
大模型离线推理的关键挑战 — GPU Memory Wall
第一个挑战是内存的挑战,机器学习的模型越来越大,尤其是继 Transformers 类的模型后,模型大小迅猛增长。从上图中可以看到,过去几年机器学习领域的模型参数增长非常迅猛,而相比于模型参数的增长,GPU 算力的提升相对较慢,两者之间就形成了越来越大的 Gap。这就带来一个问题,在进行推理或者训练时,GPU 内存可能放不下,需要对模型进行切分。
 图片
图片
模型切分
常见的模型切分方式有上图左侧所列的两种:
- 按层切分的 Pipeline Parallelism 模式
- 按权重切分的 Tensor Parallelism 模式
按层切分比较简单,就是将模型的不同层切开,切分成不同的分组,然后放到不同的 GPU 上。比如左上的图中有两个GPU,第一个 GPU 存 L0-L3,第二个 GPU 存 L4-L7。因为每个层的大小不一样,所以不一定是平均分配,有的层可能会非常大,独占一个 GPU ,小的层就多个挤在一个 GPU 上。
按权重切分就是将模型的同一层,把权重切开放到不同的 GPU 上,比如左下的图中,将 L0 的一部分权重 A0 放到 GPU 0 上,另外一部分权重 A1 放在 GPU 1 上,在推理的过程中,通过矩阵运算得到最终的结果。除了这两种方式以外,也有一些更复杂的切分方式,如将这两种方式进行结合的混合方式,或 Zero 的切分方式。
进行模型切分具有以下几点优势:
- 支持更大模型:可以在现有的硬件基础上,支持更大模型的离线推理;
- 降低成本:把现有的模型经过切分之后,放到显存比较小的卡上,可以降低一部分的成本,那么更高端的卡就可以出让给训练,毕竟训练会更加消耗资源;
- 空分复用:目前很多场景会用到空分复用技术,比如英伟达的 Multi-Process Service 技术,即将 GPU 的显存按照空间切分给不同的进程,能够提高 GPU 的利用率。但这种情况下,每个进程拿到一部分 GPU 显存,如果不进行切分,可能要占据整张卡,所以就是说进行了切分之后,在这种场景下也可以把离线推理运行起来。
分布式调度
 图片
图片
大模型离线推理的关键挑战 — 分布式调度
第二个挑战是关于分布式调度的挑战。有两点需求:
第一个是需要支持异构资源,前面说到推理的过程往往同时有数据处理及推理,那么数据的处理就希望放到 CPU 上进行,从而不占用 GPU,把 GPU 给到推理使用,所以这就需要框架能够比较友好地支持异构资源调度。
第二点是对于弹性资源调度的需求,模型经过切分后切成不同的组,在作业的运行过程中,每个组可以理解成一个 Stage,因为每个组包含的模型的 Layers 是不同的,所以不同 Stage 对于算力的需求也不同,而且在跑一个作业之前,很难预先估计算力需求,就需要不断地调整参数,才能达到最佳执行效率。所以我们希望计算框架能够在运行过程中根据计算效率自动对每个 Stage 的算力进行扩缩,使得执行速度快的 Stage 可以自动出让一些算力给慢的 Stage。
上述两点需求,目前主流的计算框架,如 Flink 和 Spark,没有办法轻易地做到,主要是因为 Spark 和 Flink 一般绑定了比较固定的批/流的计算范式,在调度层面不够灵活。
性能
性能方面,由于是离线计算作业,我们希望它的吞吐和 GPU 的利用率能够越高越好。
第一点是数据在 Stage 之间能够方便且高效的传输,应当尽量避免数据落盘带来的序列化开销,纯内存的传输方式是比较好的方式。
第二点是在推理侧,应当尽量减少数据 IO 等待,避免 IO 导致 GPU 空闲,最大化提高 GPU 使用率。
第三点是结合资源弹性,释放掉利用率较低的 GPU,从而提高整理利用率。
案例
 图片
图片
案例:Vit + Albert
以下是一个实际的案例,也是一个多模态的例子—— Vit + Albert 双塔的模型。在这个案例中,我们同时对两个模型进行切分,一个 GPU 里面一部分放 Albert 的 Layers,另一部分是 Vit 的 Layers,其中 Embedding 层通常比较大,所以单独切到一个分组中。作业总共包含了3个 Stage,Stage 间传递 Image 和文本 Tokerns。因此这 3 个 Stage 所需的计算资源是不同的,即需要弹性分配算力的能力。
02
使用 Ray 构建大模型推理框架
Ray 简介
 图片
图片
Ray 简介
Ray 项目是 UC Berkeley 的 RISElab 实验室在 2017 年前后发起的,RISElab 实验室的前身是比较著名的 AMP Lab,也就是孵化出了 Spark 引擎的实验室。该实验室在更名为 RISElab 之后,孵化出了 Ray 引擎,Ray 的定位是通用的分布式编程框架——Python-first。理论上通过 Ray 引擎用户可以轻松地把任何 Python 应用做成分布式,尤其是机器学习的相关应用,目前 Ray 主攻的一个方向就是机器学习,伯克利的发起者也基于 Ray 创建了创业公司—— Anyscale,目前这个项目在 GitHub 上获得了两万多的关注。在业界,Uber、 OpenAI、蚂蚁、字节等公司也都有基于 Ray 的相关应用实践。
Ray 的架构分为三层,最下面一层是各种云基础设施,也就是说 Ray 帮用户屏蔽了底层的基础设施,用户拉起一个 Ray Cluster之后就可以立即开始分布式的编程,不用考虑底层的云原生或各种各样的环境;中间层是 Ray Core 层。这一层是 Ray 提供的核心基础能力,主要是提供了 Low-level 的非常简洁的分布式编程 API。基于这套 API,用户可以非常容易地把现有的 Python 的程序分布式化。值得注意的是,这一层的 API 是 Low-level,没有绑定任何的计算范式,非常通用;最上层是 Ray 社区基于 Ray Core 层做的丰富的机器学习库,这一层的定位是做机器学习 Pipeline。比如,数据加工读取、模型训练、超参优化、推理,强化学习等,都可以直接使用这些库来完成整个的 Pipeline,这也是 Ray 社区目前主攻的一个方向。
更加值得一提的是,据 OpenAI 的公开资料显示,今年爆火的 ChatGPT,是基于 Ray 进行的包括预训练、Fine Tune、强化学习等 ChatGPT 的训练。
Ray 基础架构
 图片
图片
Ray 基础架构
上图展示的是 Ray Cluster 的基本架构,每一个大框就是一个节点。(这里的节点是一个虚拟的概念,可以是一个物理机,一个 VM 或一个 Linux 的 Docker。比如在 K8s 上,一个节点就是一个 Pod。)
- Head 节点:是 Ray Cluster 的调度中心,比较核心的组件是 GCS,负责全局存储、调度、作业、状态等,Head节点也有可观测性 Dashboard。
- Worker 节点:除了 Head 节点之外,其他都是 Worker 节点,承载具体的工作负载。
- Raylet:每个节点上面都有一个守护进程 Raylet,它是一个 Local Scheduler,负责 Task 的调度以及 Worker 的管理。
- Object Store 组件:每个节点上都有 Object Store 组件,负责节点之间 Object 传输。在整个 Cluster 中每个节点的 Object Store 组件组成一个全局的分布式内存。同时,在单个节点上,Object Store 在多进程之间通过共享内存的方式减少 copy。
- Driver:当用户向 Ray Cluster 上提交一个 Job,或者用 Notebook 连接的时候,Ray挑选节点来运行 Driver 进行,执行用户代码。作业结束后 Driver 销毁。
- Worker:是 Ray 中 Task 和 Actor 的载体。
此处值得大家关注的是,Ray 为了提供简洁的分布式编程体验, 在 Raylet 这一层做了非常多的设计,实现过程也比较复杂,感兴趣的朋友可以查看相关论文。
Ray 分布式编程
 图片
图片
Ray 分布式编程
上图左侧是 Ray Core 的 API 编程:Class 是 Python 的一个类,如果想把它做成分布式化的话,只需要在类上面加上 @ray.remote 装饰器,接着创建并调用 Actor 方法,最后通过 ray.get 方法把值取回;因为 Counter 这个类在远端的其他节点上,所以我们通过定义一个 Task(Python 函数),使用 Object 进行分布式的数据传输。
右侧是使用 Ray 上层的 Library 编程,通过 RayTrain 训练一个简单的机器学习模型。使用时需要先定义一个模型,这个过程和直接用 Python 定义模型相同,接着用 RayTrain API 填进去一些 Config 就可以开始训练。
所以我们看到,这两种方式一种是 Low-level、一种是 High-level,对于 Ray 来说都是推荐用户使用的。
基于 Ray 构建大模型推理框架
 图片
图片
使用 Ray 构建大模型推理框架 – Ray Datasets
Ray Datasets
在构建大型模型推理框架的选型上,我们选择了 Ray Datasets。Ray Datasets 提供了丰富的数据源接入方式,兼容目前机器学习领域常用的数据源,并且提供常用的数据处理算子,还支持通用的并行计算,比如在离线的 Bach 推理等。还有一个特点是能够支持 Pipeline 的执行模式,可以将数据的 Block 划分为不同的 Window,大大加速了整个并行计算的执行。总之,Ray Datasets 是一个非常实用的数据处理工具,可以帮助我们更高效地构建大型模型推理框架。
 图片
图片
使用 Ray 构建大模型推理框架 v1 — Based on native Ray Dataset Pipeline
因此我们尝试基于原生的 Ray Datasets Pipeline 构建大模型推理框架。
左边的伪代码描述了对应的执行过程,假设将模型按层切分成两组——ModelLayers1 和 ModelLayers2。调用 Ray Datasets Window API 创建一个 Pipeline,调用 Map Message 在两个模型分组上进行并行推理。其中 Computer 参数选择 Actor,表示 Datasets 会在后面为每一个 Map Batches 的计算过程启动一个 Actor Pool 进行计算。第三个参数是每个计算 Actor 所需的 GPU 数量, 这个参数会直接作用到背后的 Actor 上,可以看到即使是 Datasets 这类比较高级的库,它的 API 仍然很容易支持异构资源。
与 Spark 相比,使用 Ray 可以显著提高执行效率,并且随着作业规模的扩大,优势更加明显。具体在一个简单的例子中来看,假如我们只有两个 GPU,模型切了两组,任务目标是处理三个数据样本。在使用 Spark 的情况下,需要启动两个 Executor 分别加载第一个模型分组的参数并处理 3 个数据样本,处理后把数据写到外部存储中;接下来两个 Executor 分别再去加载第二个模型分组的参数,然后再分别处理样本,需要进行跟上一步同样的处理,最终再将结果写到外部存储。由此可见这个过程比较繁琐,而且对异构资源的支持不太友好。
而使用 Ray 就只需要启动两个 Actor,对应 Spark 的两个 Executor。但是这两个 Actor 可以分别加载两个模型分组的参数,两个 Actor 间的执行过程可以 Pipeline 起来,数据样本依次经过两个 Actor。此外也可以非常方便的再增加一个 CPU 上的 Actor 专门做数据的读取或存储。框架通过使用 Ray ObjectStore 存储中间结果数据,纯内存存储避免了序列化的开销,并且可以显著提高执行效率,由此可见在此类场景下,使用 Ray 相比于 Spark 可以显著地提升效率。
 图片
图片
使用 Ray 构建大模型推理框架 v1 — Based on native Ray Dataset Pipeline
上面介绍的是第一版的大模型推理框架,它已经能够很好地解决异构资源调度的问题,并且在理论上,它的执行效率也超过了同类的计算引擎,但是我们发现仍然存在一些问题:
- 每个 Window 都要创建和销毁 Actor Pool,而每次拉起 Actor 加载模型的开销太大;
- 在每个 Actor 进行推理时,数据的 IO 和推理过程并没有并行起来,导致 GPU 利用率不高;
- Actor Pool 缺乏弹性,在每个 Stage 算力需求不一样的情况下会浪费资源,需要不断调整参数以解决这个问题;
- 使用 API 调试参数困难;
- 缺乏容错和推测执行能力。
 图片
图片
使用 Ray 构建大模型推理框架 v2 — Streaming execution semantics in Ray Dataset Pipeline
为了解决以上问题,我们开发了第二版推理框架。深入到 Ray Datasets Pipeline 的内部实现中添加了 Streaming 执行语义。各个 Stage 通过 Queue 前后连接起来,Queue 中传递的是 Ray Object Reference 而不是实际数据,实际数据在 Actor 侧。相当于我们写程序时函数之间传递指针数组而不是实际数据。
第二版推理框架和第一版不同,每一个 Stage 背后是一个稳定的 Actor Pool,从一开始被创建之后就不会释放。在运行的过程中,该 Stage 就从它的 Input Queue 中读取 Object Reference,读到数据后在自己的 Actor Pool 中选择一个 Actor 来处理数据。因为 Actor Pool 是自定义的,可以实现弹性能力,使负载重的 Stage 的 Actor Pool 会主动尝试申请更多的资源来增加自己的并行度,而负载轻的 Stage 的 Actor Pool 会逐渐空闲下来,并最终释放掉一些 Actor,从而出让资源给需要资源更多的 Stage。当然,这个也需要配合一定的调度策略,也就是 Stage 在分发数据的时候如何选择一个 Actor。我们现在使用的是 Most Recently Used 的策略,忙的 Actor 就让他更忙,这样空闲的 Actor 就可以容易空闲下来释放掉。在 Actor 侧,利用 Actor 内多线程实现 IO 和推理计算并行,提高了 GPU 的利用率。
需要注意的是,Stage 之间 Queue 的长度是有限的,可以避免上游的 Stage 产生过多的数据导致作业 OOM,相当于流计算中反压的作用。第二版的伪代码和第一版并没有太多的不同,因此业务不需要花费很大的精力进行改造。
 图片
图片
使用 Ray 构建大模型推理框架 v2 — v2.3 社区合作
在开发第二版的同事,注意到 Ray 开源社区也在考虑类似的问题。社区提出了一个官方 REP,其中列出的问题与我们的目标非常相似,尤其是在提高 GPU 利用率和解决 Ray Datasets API 参数配置困难这两个方面。社区提出了新的架构,在 API 层下面拆分出了 Operator 和 Executor,增加了更多的灵活性和扩展性。后面,我们也会和社区展开合作,将我们的实现做为新架构下的一种 Executor。
03
Ray 云原生部署实践
 图片
图片
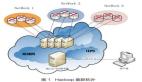
Ray 云原生部署 — KubeRay
在部署 Ray 时,我们使用了开源社区完整的解决方案 Kuberay 项目。前面提到每个 Ray Cluster 由 Head 节点和 Worker 节点组成,每个节点是一份计算资源,可以是物理机、Docker 等等,在 K8s 上即为一个 Pod。启动 Ray Cluster 时,使用 Kuberay 的 Operator 来管理整个生命周期,包括创建和销毁 Cluster 等等。目前,这个项目也比较活跃,字节、微软、蚂蚁等公司都有参与研发和使用。
 图片
图片
Ray 云原生部署 — KubeRay
在字节内部,用户可以通过内部的平台使用 Ray,通过提交 Job 或使用 Notebook 进行交互式编程。平台通过 Kuberay 提供的 YAML 和 Restful API 这两种方式进行操作。Kuberay 同时也支持自动扩展和水平扩展。Ray Cluster 在内部用于收集负载的 Metrics,并根据 Metrics 决定是否扩充更多的资源,如果需要则触发 Kuberay 拉起新的 Pod 或删除闲置的 Pod。
最后总结一下,我们今天讨论了大模型离线推理以及其中关键的挑战,并介绍了如何使用 Ray 构建大模型推理框架。未来,我们将继续加强与社区的合作,优化我们的平台,并挖掘更多的 Ray 上的应用场景。