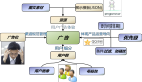
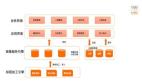
什么是图数据库以及应用范围?
图数据库是 NoSQL 的一种,一种将关联数据的实体作为顶点,关系作为边来存储的特殊类型数据库,能够高效地对这些点边结构进行存储、检索和查询。它的优点是可以很自然地表示现实世界。比如社交关系(可以清楚地看到共同好友)、股东关系甚至银行账户流动关系。
 图片
图片
 图片
图片
属性图
从数学角度来说,图论是研究建模对象之间关系结构的学科。但是从工业界使用的角度,通常会对基础的图模型进行扩展,称为属性图模型。属性图通常由以下几部分组成:
- 节点,即对象或实体。
- 节点之间的关系,通常简称为边(Edge)。通常边是有方向或者无方向的,以表示两个实体之间有持续的关系。
在属性图模型中,每个顶点包括:
- 唯一的标识符。
- 出边的集合。
- 入边的集合。
- 属性的集合 (键-值对)
每个边包括 :
- 唯一的标识符。
- 边开始的顶点(尾部顶点)
- 边结束的顶点(头部顶点)
- 描述两个顶点间关系类型的标签。
- 属性 的集合 (键-值对)。
很多数据可以建模为图。典型的例子包括 :
社交网络
顶点是人,边指示哪些人彼此认识 。
Web 图
顶点是网页,边表示与其他页面的 HTML 链接。
公路或铁路网
顶点是交叉路口,边表示他们之间的公路或铁路线。
公司股权关系
点的属性可以为股票代码、简称、市值、板块等;边的属性可以为股权。
有很多著名的算法可以在这些图上运行。例如,汽车导航系统搜索道路网中任意两点之间的最短路径,PageRank 可以计算 Web 图上网页的流行度,从而确定搜索排名。
在政采云,可以有很多使用的场景,比如:
1.项目图谱,项目、供应商、专家可以用图中的点来表示,项目的中标供应商、评标专家可以用边来表示。
 图片
图片
2.商品图谱,商品、协议可以作为顶点,商品的合规、交易可以作为边。
 图片
图片
3.安全风控: 业务部门有内容风控的需求,希望在专家、供应商、代理机构中通过多跳查询来识别围标、窜标等行为。
数据库关系和选择什么数据库?
数据模型可能是开发软件最重要的部分,它们不仅对软件的编写方式,而且还对如何思考待解决的问题都有深远的影响。
大多数应用程序是通过一层一层叠加数据模型来构建的 。每一层都面临的关键问题是:如何将其用下一层来表示?例如 :
- 作为一名应用程序开发人员,观测现实世界(其中包括人员、组织 、货物 、行 为、资金流动、传感器等),通过对象或数据结构,以及操作这些数据结构的 API 来对其建模。这些数据结构往往特定于该应用。
- 当需要存储这些数据结构时,可以采用通用数据模型(例如 JSON 或 XML 文档、 关系数据库中的表或图模型)来表示。
- 数据库工程师接着决定用何种内存、磁盘或网络的字节格式来表示上述 JSON/XML/关系/图形数据。数据表示需要支持多种方式的查询、搜索、操作和处理数 据。
这和我们通常说的 MVC 模型也有点相似,数据层、应用层、展示层都需要接受上一层的数据模型,通过封装和处理给下一层使用。
这里说到数据模型,主要是为了说明不同的数据关系是我们选择不同的数据库的原因,因为不同的数据模型对应了更适合哪种数据关系。
关系模型
现在最著名的数据模型可能是 SQL,它基于 Edgar Codd 于1970年提出的关系模型: 数据被组织成关系( relations),在SQL中称为表( table),其中每个关系者J)是元组(tuples)的无序集合 (在 SQL中称为行)。
多对多关系是不同数据模型之间的重要区别特征 。
如果数据大多是一对多关系(树结构数据)或者记录之间没有关系,那么文档模型是最合适的 。
但是,如果多对多的关系在数据中很常见呢 ?关系模型能够处理简单的多对多关系, 但是随着数据之间的关联越来越复杂,将数据建模转化为图模型会更加自然。
虽然关系型数据库与文档类型的数据库,都可以用来描述图结构的数据模型,但是,图(数据库)不仅可以描述图结构与存储数据本身,更着眼于处理数据之间的关联(拓扑)关系。具体来说,图(数据库)有这么几个优点:
- 图是一种更直观、更符合人脑思考直觉的知识表示方式。这使得我们在抽象业务问题时,可以着眼于“业务问题本身”,而不是“如何将问题描述为数据库的某种特定结构(例如表格结构)”。
- 图更容易展现数据的特征,例如转账的路径、近邻的社区。例如,如果要分析某个公司的股权关系,表的组织方式如下:
 图片
图片
这显然没有图数据库直观:
 图片
图片
我们都知道关系型数据库和 NoSQL 数据库,目前最广泛使用的关系型数据库有 Mysql、Oracle 和 Postgre。NoSQL 数据库其实不是一个合适的词,因为它其实并不代表具体的某些技术。
NoSQL 可以分为以下几种数据库:
1.文档数据库,比如 MongoDB 和 Elasticsearch;
2.键值数据库,比如 Redis。
3.列式存储,比如 HBase、Cassandra、HadoopDB
4.最后一种就是今天要说的图数据库,图数据库以点、边、属性的形式存储数据。其优点在于灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱。常见的图数据库有:NebulaGraph、Neo4j、OrientDB、 DGraph等。
图数据库的类型和选型
在图数据库的选型上我们主要考虑遗下四点:
- 项目开源,暂不考虑需付费的图数据库;
- 分布式架构设计,具备良好的可扩展性;
- 毫秒级的多跳查询延迟;
- 支持千亿量级点边存储;
现在有图数据库产品
JanusGraph | Nebula Graph | Dgraph(原谷歌团队) | Neo4j | |
开放性 | 完全开源,Java 开发 | 企业版和社区版差异体现不具体 | 部分管理工具差距 | 闭源 |
部署成本 | 需要额外部署Hbase,Cassanda | 原生 | 原生 | 原生 |
学习成本 | gremlin 查询语句,apache 推荐,java 语言开发 | nGQL,C++ 语言开发 | DQL,类似 GraphQL | cypher 查询 |
实践案例 | ebay、360、redhat | 美团、腾讯、知乎 | 思科、西门子、贝壳 | 国外目前最广泛使用 |
社区&文档 | 不活跃,文档数量尚可 | 活跃,中文友好,官方中文文档 | 活跃,中文不友好,文档较少 | 有社区版 |
分布式支持 | 原生支持 | 原生支持 | 原生支持 | 支持 |
我们将图数据库分为三类:
- 第一类:Neo4j[3]、ArangoDB[4]、Virtuoso[5]、TigerGraph[6]、RedisGraph[7]。 此类图数据库只有单机版本开源可用,性能优秀,但不能应对分布式场景中数据的规模增长,即不满足选型要求
- 第二类:JanusGraph[8]、HugeGraph[9]。 此类图数据库在现有存储系统之上新增了通用的图语义解释层,图语义层提供了图遍历的能力,但是受到存储层或者架构限制,不支持完整的计算下推,多跳遍历的性能较差,很难满足 OLTP 场景下对低延时的要求,即不满足选型要求。
- 第三类:DGraph[10]、NebulaGraph[11]。 此类图数据库根据图数据的特点对数据存储模型、点边分布、执行引擎进行了全新设计,对图的多跳遍历进行了深度优化,基本满足我们的选型要求。
DGraph 是由前 Google员工 Manish Rai Jain 离职创业后,在 2016 年推出的图数据库产品,底层数据模型是 RDF(实际上也是属性图差不多),基于 Go 语言编写,存储引擎基于 BadgerDB 改造,使用 RAFT 保证数据读写的强一致性。
NebulaGraph 是由前 Facebook 员工叶小萌离职创业后,在 2019 年推出的图数据库产品,底层数据模型是属性图,基于 C++ 语言编写,存储引擎基于 RocksDB 改造,使用 RAFT 保证数据读写的强一致性。
实时写入性能
 图片
图片
查询性能
 图片
图片
在查询和插入的性能测试方面,两个数据库各有优劣,都能满足我们的需求,我们最后选择了 Dgraph 作为我们使用的图数据库,因为两个原因:
- NebulaGraph 不支持模糊查询,需要依赖 ElasticSearch,运维成本较高,
- Dgraph 是使用RDF通用数据类型,遵守 w3c 查询语句规范,而 NebulaGraph 的查询是 nGQL,自己开发的一套语言,不具有通用性
Dgraph
一、架构模型
 图片
图片
dgraph可以分为三个部分:ratel、alpha、zero。
ratel:提供用户界面来执行数据查询,数据修改及元数据管理。
alpha:用于管理数据(谓词和索引),外部用户主要都是和 alpha 进行数据交互。
zero:用于管理集群,并在 group 之间按照指定频率去均衡数据。alpha 节点分成若干个 group,每个 group 存储若干个数据分片。由于分片的大小是不均匀的,因此不同 group 也是不均匀的。zero 节点的任务之一就是平衡 group 之间的数据大小。具体方法是,每个 group 周期性地向 zero 报告各个数据分片的大小。zero 根据这个信息在 group 之间移动分片,使得每个 group 的磁盘利用率接近。
group:多个 alpha 组成一个 group,group 中的多个 alpha 通过 raft 协议保证数据一致性。
二、扩展、复制和分片
每个集群将至少有一个 Dgraph 零节点和一个 Dgraph Alpha 节点。然后以两种方式扩展数据库。
高可用性复制
为了实现高可用性,Dgraph 使用三个零和三个 alpha 运行,而不是每个一个。
对于大多数生产应用程序所需的规模和可靠性,建议使用此配置。
拥有三台服务器既可以使整个集群的容量增加三倍,也可以提供冗余。
分片
当数据大小接近或超过 1 TB 时,Dgraph 数据库通常会被分片,这样完整的数据副本就不会保留在任何单个 alpha 节点上。
通过分片,数据分布在许多节点(或节点组)中以实现更高的规模。
当需要提供大规模和理想的可靠性时,分片和高可用性相结合。
自我修复
在 Dgraph 的云产品中,Kubernetes 用于自动检测、重启和修复任何集群(HA、分片、两者或两者都不),以保持事物平稳运行并满负荷运行。
三、数据存储
在 Dgraph 中,数据的最小单位是一个三元组。三元组既可以表示一个属性(subject-predicate-value),也可以表示一条边(subject-predicate-object)。Dgraph 为每个对象分配一个全局唯一的 id,称为 uid。Uid 是一个 64 位无符号整数,从 1 开始单调递增。
Dgraph 基于 predicate 进行数据分片,即所有相同 predicate 的三元组形成一个分片。在分片内部,根据 subject-predicate 将三元组进一步分组,每一组数据压缩成一个 key-value 对。其中 key 是 <subject, predicate>,value 是一个称为 posting list 的数据结构。

Posting list是一个有序列表。对于指向值的 predicate(如 name),posting list 是一个值列表;对于指向对象的 predicate,posting list 是一个 uid 列表,Dgraph 对其做了整数压缩优化。每 256 个 uids 组成一个 block,block 拥有一个基数(base)。Block 不存储 uid 本身,而是存储当前 uid 和上一个 uid 的差值。这个方法产生的压缩比是 10。
Dgraph 的存储方式非常有利于连接和遍历,一个边遍历只需要一个 KV 查询。例如,找到 X 的所有粉丝,只需要用 <follower,X> 当做 key 进行查询,就能获得一个 posting list,包含了所有粉丝的 uid;寻找 X 和 Y 的公共粉丝,只需要查询 <follower, X> 和 <follower, Y> 的 posting lists,然后求两者的交集。
如果有太多的三元组共享相同的 <subject,predicate>,posting list 就变得过大。Dgraph 的解决方法是,每当 posting list 的大小超过一个阈值,就把它分成两份,这样一个分割的 posting list 就会对应多个 keys。这些存储细节都是对用户透明的。
四、索引
当通过应用函数进行过滤时,Dgraph 使用索引来高效地搜索潜在的大型数据集。 所有标量类型都可以被索引。
类型int、float、bool、geo只有一个默认索引,他们都只有自己的分词器。
对于 string 类型,支持正则表达式、fulltext、term、exact 和 hash 索引;
对于 datetime 类型,支持按年、月、日、小时索引;
对于 geo 类型,支持 nearby、within 等索引。
字符串函数 | 索引/分词器 |
eq | hash,exact,term,fulltext |
le,ge,lt,gt | exact |
allofterms,anyofterms | term |
alloftext,anyoftext | fulltext |
regexp | trigram |
索引跟数据一样,以 key-value 的形式存储,区别是 key 有所不同。数据的 key 是 <predicate, uid>,而索引的 key 是 <predicate, token>。Token 是索引的分词器从 value 中获取的,例如 hash 索引生成的 token 就是 hash 函数所计算的 hash 值。
在定义 schema 的时候,可以给 predicate 创建一个或多个索引。对该 predicate 的每次更新会调用一个或多个分词器来产生 tokens。更新的时候,首先从旧值的 tokens 的 posting lists 中删除相应的 uid,然后把 uid 添加到新产生的 tokens 的 posting lists 里。
五、查询
遍历
Dgraph 的查询通常从一个 uidlist 开始,沿着边进行遍历。
{
movies(func: uid(0xb5849, 0x394c)) {
uid
m_name
code
star{
s_name
}
}
}查询的起点是 uid 为0xb5849 的单个对象,处理过程如下:
- 查询 <m_name,0xb5849>、<code,0xb5849> 两个 key,分别获得一个值(或者值列表)和一个 uidlist。
- 对于 uidlist 中的每一个 UID,查询 <s_name, UID>、<s_name, UID>,获取相应的值。
函数
通常我们不知道 uid,需要根据名称查询
//查询示例:具有dog,dogs,bark,barks,barking等的所有名称。停止词the which 会被删除掉。
{
movie(func:alloftext(name@en, "the dog which barks")) {
name@en
}
}查询 的处理过程是:
- term 分词器从"the dog which barks"字符串中获取到 dog 和 barks 两个 tokens。
- 发出两个查询 <name, dog> 和 <name, barks>,获得两个 uidlist。由于使用了函数 anyofterms,所以求这两个 uidlist 的并集,得到一个更大 uidlist。
- 同查询遍历步骤。
过滤
过滤是查询语句的主要成分之一。过滤条件也是由函数组成的。
{
me(func: anyofterms(name, "Julie Baker"))@filter(eq(sex, "female")){
pred_A
pred_B {
pred_B1
pred_B2
}
}
}深度查询
这是一个查询 4 度关注的语句。通过 A 的 uid 可以查询到 E 的 name
A<-B<-C<-D<-E
{
find_follower(func: uid(A_UID)) @recurse(depth: 4) {
name
age
follows{
name
}
}
}图数据库的业务实践
一、业务背景
1.知识图谱
知识图谱是应客户要求直观的展示项目信息,包括招投标供应商、采购单位、代理机构、评标专家、预警、违规信息、公告信息,这些数据量在五百万到千万级别,后期甚至可能到上亿,查询条件复杂、数据量较大,如果使用普通的关系数据库,难以应对低延迟、数据量大的查询需求。现改用 Dgraph 图数据库,则可以轻松查询千万级数据。
2.机构股权关系展示
不同于市面上的股权展示,客户要求能展示多个公司的股权关系,包括有无共同股东。核心数据在 30万 左右,总数据量在 500万 左右,边关系约有 1800万。此需求的数据量不是特别大,但是假设股权关系复杂,理论上一家公司的股权关系可以无限套娃,举个例子:假如 A 持有 B 股权,B 持有 C 股权,C 持有 D 股权,要查询 D 公司的股权,则遍历三次,深度每加一层,数据量呈指数级上升,会导致查询时间久、甚至超时的现象。图数据库特有的物理索引和数据存储模型,对图的多跳遍历进行了深度优化,可以满足大数据量和多跳查询,经测试 Dgraph 满足我们的性能要求。
二、解决方案
总体架构图

dgraph客户端(SDK)
目标
封装对图数据库(例如:Dgraph、nebula graph)客户端连接、查询、写入等操作,对外提供透明的操作接口,方便接入方低成本高效接入,减少其他团队学习 Graph 的成本。
设计
客户端的设计参照 Mybatis 查询的半自动模版配置模式,即在模版中写半自动的 Dgraph 语句,在代码中将参数、条件等写入,目前已经完成通用模版的配置,调用方无需自己写 Dgraph 语句,只需调用接口,构造查询条件,SDK 即可生成 Graphql 语句并执行查询,返回查询结果。
 图片
图片
设计框架图
 图片
图片
Dgrpah数据生产
目标
不管是现有的数据还是以后实时产生的数据,原来的业务数据都是存储在各个业务方的关系数据库,我们都需要将历史数据和实时增量数据导入到 Dgraph 数据库。
设计
业务数据由大数据部门统一收集,再通过 Kfaka 消息发送给我们,我们再通过 Dgraph 的 java 客户端写入到 Graph。由于数据量较大,时间较紧,我们采取批量接受 Kafka 消息,经过转换数据,再批量写入数据到 Dgraph 的方式提高导入数据效率,在测试环境,每万条数据只需要数秒时间,生产环境应当更快。
设计框架
 图片
图片
总结和展望
本文一开始介绍了图数据库的概念和优点,后面说明了数据模型、数据关系是诞生和选择图数据库重要原因,中间主要是介绍 Dgraph 及其他图数据库的特点,对比各个图数据库和选择 Dgraph 的原因;最后一部分是在公司业务的实践应用,比如解决大数据量查询带来的查询缓慢的痛点;深度查询带来的难点,在使用方面做出的优化,包括 sdk 的封装和数据的导入。
图数据库的应用,远远不止简单的查询。在智能问答、安全风控、商品图谱、数据挖掘等各方面的应用都可以使用图数据库。图数据库在很多方面都优于关系数据库,更快速、更灵活、更直观,可以预见,将来图数据库会更普及,根据 verifiedmarketresearc, fnfresearch, marketsandmarkets, 以及 gartner 等智库的统计和预测,图数据库市场(包括云服务)规模在 2019 年大约是 8 亿美元,将在未来 6 年保持 25% 左右的年复合增长(CAGR)至 30-40 亿美元,这大约对应于全球数据库市场 5-10% 的市场份额。
参考资料
https://dgraph.io/docs/dgraph-overview/
https://dgraph.io/docs/dql/dql-syntax/dql-query/
https://docs.nebula-graph.com.cn/3.5.0/1.introduction/0-0-graph/
https://docs.nebula-graph.com.cn/3.5.0/1.introduction/0-1-graph-database/#_6
https://docs.nebula-graph.com.cn/3.5.0/1.introduction/0-2.relates/
https://tech.meituan.com/2021/04/01/nebula-graph-practice-in-meituan.html