业务背景
B站是一个以PUGV为主的视频社区,用户使用的最主要场景是在视频详情页观看视频。随着业务发展壮大,在这个「主战场」上会有越来越多的扩展业务,例如:话题、视频荣誉、笔记、用户装扮等等。
 图片
图片
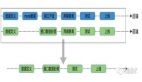
(图1:所有流量都会汇聚到视频详情页)
从图一中看到,我们可以将APP上功能的页面分为两类:列表页(ListView Page),如推荐、搜索、动态、分区等等绝大多数页面都是列表型的,它给用户提供了丰富的内容筛选和预览的场景;另一类是详情页(DetailView Page),当用户在任何列表页点击感兴趣的内容时,都会汇入到详情页观看。
 图片
图片
(图2:视频详情页聚集了视频关联的多种信息与功能入口)
从图2可以看到,视频详情页聚集了该视频相关的属性和功能入口,例如:热门、全站排行榜、每周必看等稿件荣誉,视频拍摄模板,视频合集,视频配乐以及所属话题等等信息。这些信息以及入口可以帮助用户进一步地探索相关的主题内容和功能。
现状与问题
在技术实现上,B站面向用户的应用架构主要分为四层:
- 终端层:直接与用户交互的客户端,包括手机APP、H5,PC上Web和客户端,以及其他屏幕终端,例如:TV,车载,音响以及PS等等。
- 接入网关:一般为LB(Load Balance)加AGW(API-Gateway), AGW主要会负责请求路由,协议转换,协议卸载,限流熔断,安全封禁等。
- BFF(Backend for Frontend):由于终端的增加,为了保证client-specific的逻辑能够做到比较好的隔离,通常实践会按终端拆分应用,例如:web-interface(面向网页),app-interface(面向APP),tv-interface(面向电视端)等等。除此之外,由于页面逻辑越来越复杂,流量越来越大,也会将页面的BFF逻辑分拆单独的应用做到发布与部署的隔离,例如:app-feed(首页),app-view(视频详情页)等。
- 业务Service:负责业务域或能力的接口,通常会按照功能/能力和业务领域拆分。
 图片
图片
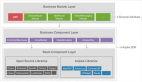
(图3:应用架构分层)
由图3可以看出,视频详情页的主要逻辑集中在BFF层,随着DAU增长以及业务的不断扩展,我们面临了两个问题:
问题一:读扩散(fanout read)的数量随着业务扩展越来越大,对BFF自身以及下游业务都带来巨大流量负载和复杂度。如下图所示,为了展示关联视频的功能入口,业务Service需要一方面承载所有视频详情请求的流量以及带来的CPU资源消耗;另一方面还需要通过实现类似bloom filter机制来避免所有未关联视频请求带来的大量回源查询。
 图片
图片
(图4:负载随BFF的读扩散无差别的放大到所有Service,并带来Service的实现复杂化)
问题二:或许问题一我们可以通过增加机器和实现复杂度来解决,但是随着fanout read的扩散数不断增加,单个视频详情请求latency会持续恶化,直到用户不可接受。(图4.a【参考1】,fanout数增加会大幅增加整体请求超时的概率。图4.b 是真实的Bilibili APP视频详情BFF的fanout请求拓扑,已经比较庞大(图已经看不清了),而且fanout个数还在不断随着业务增加而持续增加。)
 图片
图片
(图4.a fanout数与超时率的相关性,摘自《The Tail At Scale》)
 图片
图片
- (图 4.b 视频详情页BFF的fanout实际情况,通过内部Trace系统绘制)
分析与建模
如上文提到的,很多视频详情的下游业务Service仅仅覆盖了部分视频,即只有部分视频有关联数据,所以常常会使用类BloomFilter的机制来过滤未关联视频的请求。
我们对视频详情BFF请求下游的Response大小进行分桶打点(使用Prometheus Histogram打点)。进过分析发现,有较多的业务Service返回的Response呈现出下图所示的分布:
 图片
图片
(图5:BFF请求Service返回包大小分布)
可以看出,BFF访问的不少业务Service接口Response 90%以上都为“空”,即代表请求的视频并没有关联该业务。但是在实现上,视频详情BFF在每次获取视频详情信息都会请求这些业务,根本原因是在BFF层在处理请求时并不知道视频关联了哪些业务。
如果我们可以在BFF层提前知道本次请求的视频关联了哪些业务,就可以大幅降低BFF的读扩散数量和业务Service的负载,做到按需访问。
我们可以给每个视频建立一个包含其关联业务的稀疏向量,称为视频-业务索引。如下图所示:
 图片
图片
(图6:视频id与所关联业务的索引模型)
在实际落地实现时,视频业务索引并不一定以稀疏向量的方式存储视频与业务的关联关系,可以使用一些现成的kv系统。例如我们是用redis的hash key来实现的。另外需要考虑的是,当业务与视频关联关系发生变化时,需要有全量(初始阶段)和增量的将变更通知到索引服务进的机制。
实现
基于前面的问题分析与建模,我们将视频详情BFF的架构优化为如下图所示:
 图片
图片
(图7:优化后的架构与处理流程)
在BFF请求处理流程中,①引入了业务关联索引服务,在BFF请求下游业务Service前通过获取视频关联业务的索引,②提前获取本次请求应该访问的哪些业务Service将不相关的业务请求过滤掉。索引是通过redis的hashmap实现,同时也使用了公司内部的KV存储做持久化和redis故障降级。redis的key设置示例如下:
HMSET index_vid1234 biz1 0 biz2 1 bizM "hot"视频关联业务的索引构建是通过将下游业务的关联信息全量+增量导入构建。为了方便下游业务的更高效的将异构数据导入索引,我们提供了一套支持在线进行业务变更消息清洗与导入函数编写的后台系统。如下图所示:
 图片
图片
(图8:业务变更事件处理函数与索引更新推送后台)
架构扩展
经过我们进一步的调研发现:不仅仅是视频详情,Story(短视频)、直播、动态和我的页等详情页都呈现出类似的聚合场景,而且如图3这些聚合场景也会同时出现在APP、TV、Web等多个端对应的BFF中。那是否可以通过一套更加标准且通用的方案来统一解决类似视频详情的聚合问题?
如前文图3所示,BFF的主要处理逻辑分为:参数处理,聚合逻辑,返回对象(VO)的组装。我们可以将视频、直播、用户等复杂的聚合逻辑抽象成更为通用聚合服务,提供给所有BFF使用。要做到这点,通用聚合服务需要具备以下能力:
- 支持不同终端BFF按需获取聚合模型。
- 支持更加灵活的扩展聚合模型,即在满足1的基础上拓展一个新业务的成本尽可能的低。
- 支持前面基于业务关联索引进行降低负载的能力。
关于第1点,业界常见的做法包括以下几种:
- GraphQL:通过字段选择器实现所需信息的筛选。GraphQL虽然功能全面且灵活,但是引入会使得系统实现和问题排查的复杂度急剧升高,不利于长期的维护和迭代。(详见参考2)
- Protobuf field mask:Google APIs提出的通过在请求参数中增加google.protobuf.FieldMask类型的字段来指定所需要的返回范围,旨在减少不需要的返回字段带来的网络传输海和服务端计算成本。不过,Google APIs已经宣布了read_mask已经处于废弃状态。
- View Enum:为了满足field mask的按需获取机制,Google APIs提供了一种更好的替代方案(详见参考3)。通过定义View Enum,由服务提供方定义常见的按需访问场景,例如:BASIC返回基本信息并用于列表场景,ALL用于返回详情用于详情页场景。同时也支持更加丰富的枚举定义,这正好契合了我们的需求。
以下是我们针对视频详情页的View Enum定义:
enum ArchiveView {
//未指定,不返回数据
UNSPECIFIED = 0;
// 以下是最常见场景的视图定义
// 返回稿件简易信息(用于信息查询)
SIMPLE = 1;
// 返回稿件基础信息(可用于首页、搜索列表查询)
BASIC = 2;
// 返回稿件基础信息+分P信息(最简版详情,用于分享等场景)
BASIC_WITH_PAGES = 3;
// 返回APP端视频详情所有信息
ALL_APP = 4;
// 返回WEB端视频详情所有信息
ALL_WEB = 5;
// 返回TV端视频详情所有信息
ALL_TV = 6;
// 可以持续增加新的场景
}关于第2点,我们将聚合逻辑抽象成DAG图,之所以使用DAG模型是因为部分业务Service之间会存在前后依赖,例如:一些视频的属性依赖与视频基础信息(通过访问视频基础信息Service获取)中的视频作者信息。这样任何新增的业务只需要:1. 指定依赖的其他节点,2. 编写节点内的逻辑,包括访问Service服务和业务逻辑处理,3.配置该节点应该在哪些View Enum的使用。
关于第3点,前面已经介绍过实现原理,我们只需要:将索引从视频-业务索引扩展到直播、用户-业务的索引即可。
综上所述,我们将通用数据聚合服务命名为DAGW(Data Aggregate Gateway),DAGW的内部结构以及与BFF层以及Service的交互如下图所示:
 图片
图片
(图9:引入通用数据聚合网关层DAGW统一满足聚合场景需求)
效果
DAGW通用数据聚合网关以及业务关联索引上线后,支持了视频、用户等信息聚合能力,已经有近30个业务Service接入并平均帮助业务Service降低了超过90%的流量和负载。以下是视频的高能看点业务和用户的粉丝勋章业务接入效果:
1. 视频的高能看点业务Service的流量中,来自播放页(app-view)的流量高峰时期达到100k+ QPS,经过接入DAGW优化后效果非常显著,下图监控中可以看出来请求QPS降低了99%。
 图片
图片
2. 粉丝勋章是用户通过长期观看主播直播以及参与互动获取的可佩戴的铁杆粉丝荣誉,因为获得门槛较高且只有在特定主播内容下才展示,通过接入DAGW后,可以有效降低85%以上的访问流量。

参考
1. The Tail at Scale:https://research.google/pubs/pub40801/
2. GraphQL: From Excitement to Deception:https://betterprogramming.pub/graphql-from-excitement-to-deception-f81f7c95b7cf
3. View Enum:https://google.aip.dev/157
本期作者

黄山成
哔哩哔哩资深开发工程师
夏琳娟
哔哩哔哩资深开发工程师

赵丹丹
哔哩哔哩资深开发工程师