













译者 | 布加迪
审校 | 重楼

每周都有新的大语言模型(LLM)出现,越来越多的聊天机器人可供我们使用。然而,很难找出哪一个LLM是最好的、每一个LLM方面的进展以及哪一个LLM最有用。
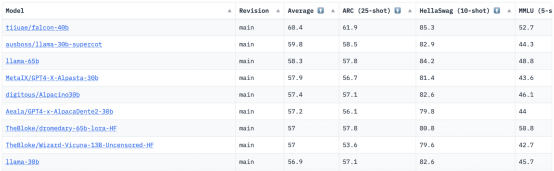
HuggingFace有一个开放的LLM排行榜,负责跟踪、评估和排名新发布的LLM。它使用一个独特的框架来测试生成式语言模型处理不同评估任务的表现。
之前,LLaMA(大语言模型Meta人工智能)在排行榜上名列前茅,但最近已被一个新的预训练LLM:Falcon 40B所取代。
关于科技创新研究所
Falcon LLM由科技创新研究所(TII)创立和开发,该公司隶属阿布扎比政府先进技术研究委员会。政府监督整个阿联酋的技术研究,该研究所的科学家、研究人员和工程师团队专注于提供变革性技术和科学发现。
Falcon 40B简介
Falcon-40B是一个具有400亿个参数的基础LLM,在一万亿token上进行训练。Falcon 40B是一种自回归纯解码器模型。自回归纯解码器模型意味着该模型经过训练,可以在给定前一个token的序列中预测下一个token。GPT模型就是一种典型的自回归纯解码器模型。
结果证明,Falcon的架构在训练计算预算仅为GPT-3 75%的情况下上明显优于GPT-3,而且只在推理时需要计算。
大规模的数据质量是科技创新研究所团队关注的一个重要方向,因为我们知道LLM对训练数据的质量非常敏感。该团队建立了一条数据管道,可以扩展到数万个CPU核心,以进行快速处理,并能够使用广泛的过滤和重复数据删除从网上提取高质量的内容。
科技创新研究所还有另一个简化版:Falcon-7B,它有70亿个参数,在15000亿个token上训练。如果你在寻找一个随时可用的聊天模型,可以使用Falcon-40B-Instruct和Falcon-7B-Instruct。
Falcon 40B能做什么?
与其他LLM相似,Falcon 40B可以:
- 生成创意内容
- 解决复杂问题
- 客户服务运作
- 提供虚拟助手
- 提供语言翻译
- 提供情绪分析
- 减少和自动化“重复性”工作
- 帮助阿联酋公司提高效率
Falcon 40B是如何训练的?
在两个多月的时间里,它在1万亿个token上进行训练,在AWS上使用384个GPU,并在RefinedWeb的10000亿token上进行训练。其中,RefinedWeb是一个由TII构建的大型英语网络数据集。
预训练数据由来自网上的公共数据集合组成,使用CommonCrawl。该团队经历了一个彻底的过滤阶段,删除了机器生成的文本和成人内容,并进行了重复数据删除,以生成一个拥有近5万亿个token的预训练数据集。
RefinedWeb数据集建立在CommonCrawl之上,显示模型比在精选数据集上进行训练的模型具有更好的性能。RefinedWeb也是对多模态友好的。
Falcon LLM已开源
他们已向公众开放了Falcon LLM的源代码,使Falcon 40B和7B更容易被研究人员和开发人员使用,它是基于Apache许可证2.0版本发布的。
该LLM曾经只用于研究和商业用途,现在已经开源,以满足全球全面获取AI的需求。由于阿联酋致力于改变AI领域的挑战和极限,因此它没有商业使用限制方面的版税。
Apache 2.0旨在AI领域促进一个协作、创新和共享知识的生态系统,确保了开源软件的安全性。
如何使用Falcon- 7B Instruct LLM?
如果您想试试简化版的Falcon-40B,它更适合聊天机器人风格的通用指令,不妨先使用Falcon-7B。
让我们开始吧。
如果还没有安装,请安装以下软件包:
一旦您安装了这些软件包,就可以继续运行为Falcon 7B Instruct提供的代码:
结语
作为目前最好的开源模型,Falcon摘得了LLaMA的桂冠,人们惊叹于其强大的优化架构、采用独特许可证的开源以及40B和7B参数这两种规格。
原文标题:Falcon LLM: The New King of Open-Source LLMs,作者:Nisha Arya































