一、识别网络爬虫流量的必要性
在互联网上识别用户身份和获取用户资料是一种寻常的行为,为特定用户推送和定制不同内容也较为普遍。但事实上,在互联网存在海量的虚假流量,它们通常被用来大批量、分布式地采集网页信息,进行模拟登陆,模仿用户行为进而规避被封禁的风险。虚假流量的主体是网络爬虫,网络爬虫(Web Crawlers)是机器人的一种,用于将公开化的网络数据的搜集自动化[1]。虽然有些爬虫会在被爬取网站的同意下搜集信息,但是大多数网络爬虫并不遵循网络条款。
目前应用最广的网络条款是robots.txt,其目的在于告诉爬虫机器人网站的哪些页面可以爬取,哪些页面不允许被爬取,该条款只用于声明,而不能强制迫使网络爬虫遵循其规定。如下图是百度的部分robots.txt:
 图片
图片
图1 百度部分robots.txt展示
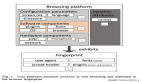
二、使用浏览器指纹识别网络爬虫的必要性
目前网络上针对网络爬虫有多种反制措施,比如网络爬虫头部信息检测、JavaScript加密参数、各种验证码识别、网页代码混淆等。
1.网络爬虫头部信息检测
这种措施主要是针对爬虫程序启动时没有完全模拟浏览器头部信息的情况。比如打开Edge浏览器的开发者工具,在网络面板刷新页面后可以抓到网络数据包,打开访问百度页面的数据包,可以看到大量请求标头:
 图片
图片
图2 数据包请求标头
其中最为常用的便是Cookie,在Cookie中存在用户的唯一标志符,为了防止爬虫复用该信息,通常里边会存在一些拥有时效性的时间戳。这种方法因有可能侵犯隐私而受到一些抵制。此外,User-Agent也被用来防范网络爬虫,因为默认的网络爬虫对于这一头部信息是缺失的,使用正常浏览器访问页面会自带浏览器的信息,而且该信息还被用来区分移动端和浏览器端,面对不同浏览终端,会给用户返回不同的页面效果。但是这种反爬虫措施的效果较弱,只要爬虫将信息复制完整,在一定时间内依然能够发起大量的访问请求。
2.JavaScript加密参数
JavaScript加密参数指的是在用户访问网站的时候,头部会携带一些由网站的JavaScript代码计算生成的值,该值每次计算结果都不尽相同,其主要应用常用的前端加密库CryptoJS进行加密计算。
这种反爬虫措施虽然提高了门槛,但是对于会阅读JavaScript代码的程序员来说,依然没有任何难度。主要原因在于网站的前端代码可以直接被用户获取,虽然可以有多种禁止用户单击右键或者打开开发者工具的措施,但是对于有编程基础的人来说形同虚设。
针对这种反爬虫措施,用户只需将网站的JavaScript加密参数相关代码通过阅读进行复现,或者直接拷贝下来进行执行,再与自己编写的爬虫代码进行耦合,依然能够实现对网站的访问请求。
3.各种验证码检测
目前验证码检测已经十分广泛,从早期的英文数字验证码,到现在的汉字点选验证码、滑块验证码等,有众多的公司专门提供对应的服务,如网易易盾、极验、顶象等,如下图所示:
 图片
图片
图3 文字点选验证码
但是随着人工智能技术的发展,这些验证码也逐渐拜倒在爬虫技术之下。在github上已经存在一些成熟的验证码识别库用于通过验证码检测,比如dddocr,已经可以直接调包识别英数验证码、滑块验证码、文字点选验证码等。即便是没有对应的识别库,也可以通过自己搭建深度学习环境来训练验证码模型。
4.网页代码混淆
网页代码混淆是用来拔高JavaScript参数破解门槛的,包括验证码识别在内,在提交参数的时候,都可以通过JavaScript脚本进行参数加密。网页的前端代码是用户可以直接获取的,没有秘密可言。网页代码混淆便是使得代码不可读,进而提高参数破解难度。下图是网易易盾的网页混淆代码:
 图片
图片
图4 网易易盾混淆页面
网页代码混淆通常是通过Babel库来实现的,因此也存在还原的方法,利用Bbael库AST抽象语法树进行还原目前已是成熟的技术。虽然做不到对复杂混淆代码的完全还原,但也足以攻克加密参数了。
上述反爬虫措施都存在或大或小的漏洞,爬虫总是可以通过这样或者那样的方法来模拟用户行为,进而发起网络请求。而接下来本文介绍的浏览器指纹技术则是很好的解决方案。
三、浏览器指纹技术概要
浏览器指纹是关于给定的浏览器、设备、操作系统和用户的环境和位置信息的一组信息。[2]这些信息可以直接通过JavaScript搜集并发送给网站服务器。网络爬虫无法避开这些信息的发送,如果爬虫直接复制了浏览器的相关指纹参数,那么网站主机就可以根据指纹来确定流量是否来自同一用户,进一步根据发送频率来限制流量。而且,浏览器指纹也可以获取跨浏览器指纹,主要是操作系统信息和一些图形卡信息,因此同一台主机发起的请求完全可以被识别为同一用户。而这种技术的好处在于无法感知,因为这些信息可以直接通过编程语言的接口来获取,不会留下任何痕迹。
一些常用的指纹主要包括如下几个方面:
- 设备的功能(包括设备内存、颜色深度、逻辑核心、触控支持、屏幕参数等);
- 操作系统的参数(操作系统版本、支持的字体列表、时区等);
- 浏览器的特征(浏览器头部版本、插件列表、屏幕分辨率、数据库信息等);
- 图形卡信息(canvas画布、WebGL渲染器等)。
获取上述信息之后,通常不会把这些信息直接发送出去,而是对其进行哈希编码。哈希是指从一个可变大小的输入中获得一个固定长度的输出的过程。相同的输入会有相同的输出,而且哈希函数拥有不错的抗碰撞能力,即两个不同的输入很难获得相同的输出结果。利用这一特性,可以很轻易地辨别较长的浏览器指纹是否是来自同一用户。
如果要辨别流量是否来自于同一浏览器,只需要把浏览器对应的信息搜集后哈希,然后放置于cookie或者一个单独的参数中,发送给网站主机即可。这样一来,网站面对来自同一指纹的频繁请求,可以及时进行流量拦截。
如果爬虫程序伪造了不同的浏览器头部信息,网站也可以进一步搜集图形卡信息和操作系统参数,因为同一台电脑的这些信息是相同的,这样即便开启多个浏览器或者伪造不同的浏览器头部也可以轻易被识别出来。
四、浏览器指纹技术的缺陷
浏览器指纹技术也存在限制,主要在于用户的设备是可以更新和升级的,一旦进行更新和升级,指纹将发生很大变化。而且如果爬虫程序识别到了浏览器指纹识别技术,也可以通过编写JavaScript,完全伪造一套指纹环境,并且不断随机其中的参数,从而达到生成新指纹的效果。这样一来,网站针对同一指纹的请求频率来识别的方案将会失效。
但是不论如何,浏览器指纹依然是目前抵制网络爬虫最坚实的方案。因为浏览器指纹信息是极其繁杂的,网站的浏览器指纹检测方案可以不断改进,并搭配JavaScript参数加密和混淆,进而可以极大增加破解难度。如下图所示的浏览器本身的信息:
 图片
图片
图5 浏览器信息
这些信息都直接包含在浏览器的window当中。浏览器指纹技术不仅可以检测各类信息,也可以侦测用户请求网站的时候,是否存在这些函数方法。这样一来,除非爬虫程序完全将浏览器的接口自己实现,进行繁重的补环境操作,否则也没有什么爬取数据的捷径可行。
参考文献:
[1] Vastel, A., Rudametkin, W., Rouvoy, R., Blanc, X. (2020, February). FP-Crawlers: Studying the Resilience of Browser Fingerprinting to Block Crawlers. In NDSS Workshop on Measurements, Attacks, and Defenses for the Web (MADWeb’20).
[2] Browser Fingerprint Coding Methods Increasing the Effectiveness of User Identification in the Web Traffic [J] . Marcin Gabryel,Konrad Grzanek,Yoichi Hayashi. Journal of Artificial Intelligence and Soft Computing Research . 2020 (4)