Shopee 是一家服务于全球多个市场的电商平台,致力于为消费者提供更加便捷,安全,快速良好的消费体验。Shopee 深耕多种不同的语言和市场,在这种国际化的服务平台上,需要处理多语言和混合语言的复杂语料。我个人的工作主要聚焦于电商平台商品有关的图谱以及图谱算法的构建,也希望通过本次分享能给大家带来一些收获。其中就包含了:商品知识图谱在多元市场的构建经验,商品知识图谱最新的进展以及新的应用,以及如何构建技术模型和技术框架来实现满足电商复杂应用的诉求。
一、知识建模
首先分享一下知识建模相关的内容。
1、Knowledge Ontology

从上图中可以看到,消费者使用 Shopee 电商 App,可以通过分类选项,找到具体分类下的商品,进行浏览和购买。分类体系是商品图谱中用来管理商品信息的非常重要的本体层。商品图谱的本体层,主要包含商品的分类和每个分类下具体的属性,通过这样的分类和属性的组合,来表示整个商品图谱中每一个商品实体的具体信息。
电商分类是一个树状的结构,从最粗的粒度到最细的粒度,不同的分类中有不同的深度。以移动电子类为例,在其下面又可以细分出可穿戴类的电子产品,在可穿戴类中又包括了移动手表等等。对于细分品类,我们会梳理出大家关心的属性项和属性值。以 T-shirt 为例,消费者和平台可能会比较关注 T-shirt 的品牌、材质等信息,这里的品牌、材质是属性项(Attribute Type)。我们会梳理出品牌、材质这些属性项对应的具体属性值(Attribute Value),比如材质里面包含纯棉 Cotten、真丝 Silk 等。
通过类目(category),属性项(Attribute Type),属性值(Attribute Value)这样一个组合体,就可以构建出商品知识图谱的本体层。用这样的本体来表达所有具体商品实体的信息。
2、Knowledge Ontology - Ontology and Entity
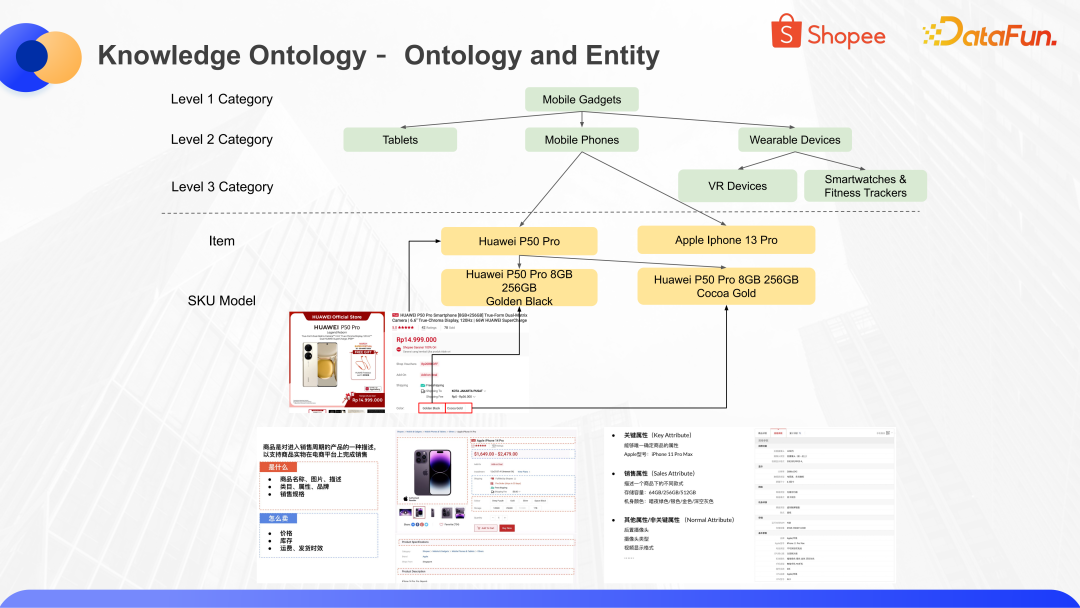
在这个图中,上面是本体,下面是每个商品的实体。当然在商品实体里,也会有不同的粒度。比如我们日常在买东西的时候看到的一个页面,其实是一个 item,这是商品维度。当我们选择了一个具体的型号去购买,就是选择了一个 SKU Model,这是最细粒度的商品信息。这样一个本体体系和商品实体的组合,就可以实现大规模商品信息的结构化管理和表示。
3、Knowledge Ontology - Uplift All in One

随着经济的发展,电商为了满足迅速变化的市场需求也在不断地演变,电商平台的本体层也不是一成不变的。
Shopee 建设初期,在各个语言市场有着自己的本体分类和设计。后来我们发现,统一的一套更加有利于多语言语料和多语言市场之间商品的互通,和商品信息在不同语言之间高效的转化,所以我们把不同语言之间的本体汇总成了 Global-Category-Tree 这样全球统一的体系。就可以在同样的分类体系,同样的属性体系下面,用不同版本的语言去管理所有市场的商品实体信息。
4、Knowledge Ontology - Uplift Continuously

在图谱本体方面,我们遇到的核心痛点是,本体如何与时俱进的去迭代变更。随着市场的发展,会不断涌现出新的品类、新的项和值。但是新品、新项和新值对于存量的语料来说是比较少的,那么如何能及时的捕捉到它们呢?这个技术的思想就要从 New Phrase Mining 开始。普通 NER 模型在 OOV 问题的表现上,并不能很好地满足我们的应用诉求,我们的核心思想是引入 MINER 模型,去缓解和改善 OOV 的问题。主要思想是:以 SpanNER 为基础模型,引入 information bottleneck 层,借助互信息的形式改造目标函数,帮助模型去优化对上下文的捕捉能力。从而提升模型的泛化能力。通过这样不断去挖掘新的品类词、属性项、属性值的技术,实现了 Span level accuracy 提升 4.5%+,Value level recall 提升 7.4%+,效果还是比较可观的。基于这样一套不断挖掘的思路,就可以帮助智能推荐本体层的调整建议,结合线上效果评估,基于新的语料去不断进行挖掘的迭代和循环。
二、知识获取
1、Challenges

在日常的知识获取工作中,我们也遇到了比较多的挑战,比如在处理商品语料的时候,会遇到各种各样的语言,甚至是各种复杂语言的混合体。同时还要处理细粒度的分类,分类体系可以达到上千类。在这样的细粒度分类之下,不同的分类有不同的语料特征,分类结合属性项维度能够达到 10K+ 的不同组合。再结合每个项下面不同的属性值,整体能够达到 260K+ 量级的规模。在这样的规模下,整体服务的精度还要维持在 90% 之上。
面对这样的挑战,我们需要更好的技术思路,基于有限的开发人员和研发时间,能够快速响应线上服务迭代的诉求,保证线上服务的效果,所以我们需要有一套 Scalable Technique Structure 来响应我们的应用诉求。
2、Item Category Classification

首先介绍下商品分类相关的 task 和解决方案。商品分类问题的核心目标就是理解商品的分类信息,并且提升和保障其准确性。同时还需要把分类的服务提供给商家商品发布的系统,保证系统的效率及稳定性。具体的问题可以拆分为几个 task:
① 如何对新发的商品做精准的推荐。
② 存量的商品牵引到新的分类体系下。
③ 及时捕捉和修正存量商品信息中的错误。

随着电商平台的发展,商品信息的表达也在不断变化来吸引用户的关注,这对于模型而言就是一个挑战,不仅要构建一个精准的模型,还要不断地迭代更新保持它的效果。
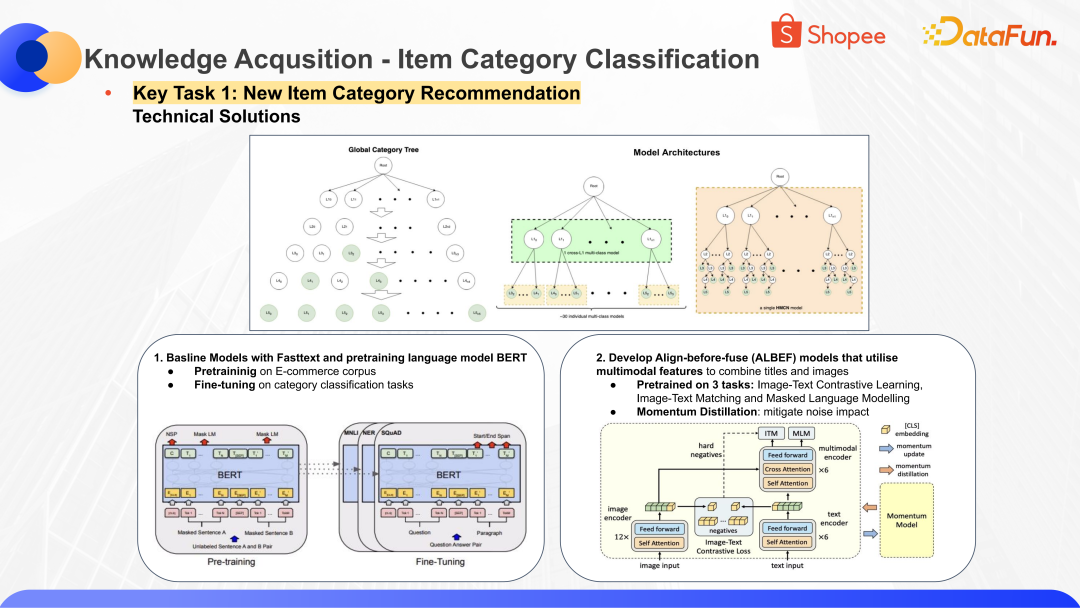
为了应对信息分类,需要设计一套模型的架构。这样的模型架构我们有好多种,比如说第一种就是把每个商品做一个粗粒度的分类,可能分到最粗的几十大类,在每个大类下有更细粒度的分类,这样每个子模型需要去分类的类别量是比较小的,分类效果也会比较精细。第二种是更加 end-to-end 的框架,我们直接把商品信息输入,去找到它使用的最细粒度的分类。
这两种架构各有其优缺点。第一种的缺点就是需要管理的模型是很多的,以一个语言市场为例,需要管理的模型就有几十个。再结合十多个语言市场,管理的模型量就达到上百量级。第二种模型更加端到端,但是在一些细分品类上的效果就可能各有参差,并且在细粒度品类的优化上也会同时影响其他品类的效果。这两种体系我们会根据实际效果做更科学的选择。
无论哪种体系,底层都依赖了文本类的分类方法和图文结合多模态的方法。常见的文本类模型有 Fasttext 和 BERT 等等。多模态部分我们在对比各种模型后,选择基于 Align-before-fuse 做商品类图文信息的综合识别,最终找到适合的分类。Align-before-fuse 模型的核心思想是先通过 Image-Text Contrastive Learning,Image-Text Matching 和 Masked Language Modelling 做预训练,再通过 Momentum Distillation 减轻脏数据的影响,从而实现比较好的分类效果。

随着模型的开发上线和应用,我们在各个市场的主要品类下面的精度可以维持在 85%~90%+。同时也能支持不同的发布体系的高频率调用。

第二个任务就是对类目体系做变更之后如何快速的响应,把商品转化到新的品类上。这里的业务背景是随着市场的发展,很多新品的涌现以及品类的壮大。如果一直用比较粗的分类方式,是不利于下游电商系统分发和客户消费体验的,需要进行细化的拆分。对技术就比较有挑战,因为新的分类是不能直接拿到天然的训练语料的,所以工作的重点就是如何能够智能化地构建训练语料,升级并且响应新的分类体系的要求。

上图展示了数据挖掘的流程和思路,核心思想是基于 Keywords-Mining 和 OOD-Detection 的方法,去挖掘有变化的或者新兴品类的关键词,基于关键词去做自动化样本的构建。比如挖掘出新兴品类的关键词之后,存量的商品或者市场上的商品能够被这样的关键词命中,且具备较高的执行度,那么就可以添加到训练语料当中,成为新品类的训练样本。对于低执行度或者有多种可能的数据语料,再进行简单的人工核验,就可以快速的构建训练样本,帮助模型高效地迭代。
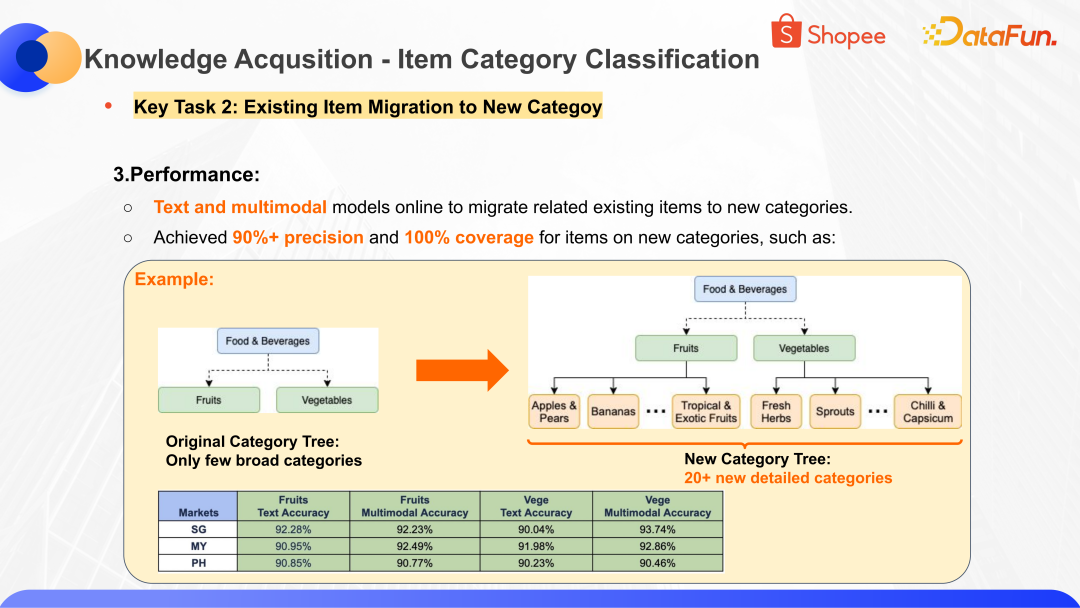
以上图的案例为例,原始的 Global Category Tree 有两个分类,在拓展到 20+ 的细粒度的分类之后,无论文本模型还是多模态模型在多个不同的市场都可以达到 90%+ 的精度,可以高效地响应分类调整问题。

第三个任务是如何对分类错误的商品去捕捉和修正。这里的业务背景是错放的商品信息无论是对消费者还是平台都带来了各种各样的负面影响。比如增加额外的物流成本,影响商家的销量,增加对商品管控的难度。技术上的难点是,这类错放商品,对于模型本来也是较为困难的案例,分类模型对这些数据较难精准地捕捉。
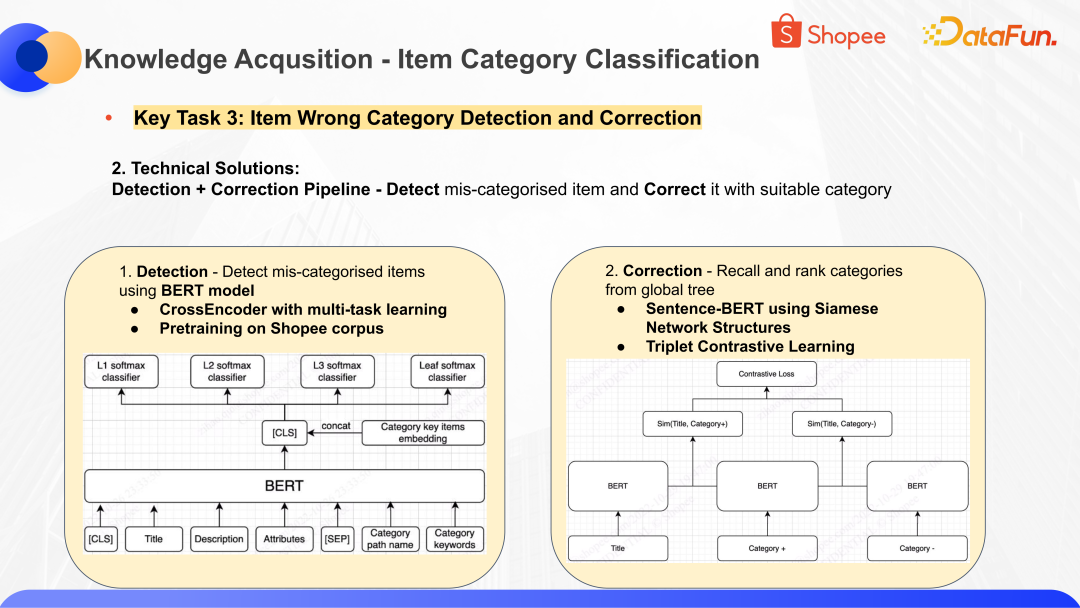
为了解决这个问题,我们构建了识别错放商品的模型 Detection,再结合识别出来的错放的商品做修正 Correction 的工作,找到一个更适合的分类。在 Detection 这个模型中,核心思想是基于 CrossEncoder with multi-task learning,对 Shopee 语料库进行预训练,然后做分类。通过对商品信息和分类信息做拼接,识别出在各个分类层上是否属于错误的分类。对于错放的商品,通过召回和排序的方式,找到最接近或者执行度最高的分类。核心思想是基于 Sentence-BERT using Siamese Network Structures 和 Triplet Contrastive Learning 优选出可信度最高的一个或多个分类,并进行修正。

这里面需要去处理或标注的存疑语料的规模是非常大的,那么如何通过只标识少量的数据就实现模型的提升呢?在这个问题之上,我们进行了数据语料优选的工作,可以理解为通过主动学习的方式,去学习语料的置信度,在经过三到四种模型,通过投票和优选的方法,学到哪些数据预料是异常值。在采样的时候对 centorid data、outlier data、random data 都进行采样,通过这样的方式缩小语料的标注量,从而实现模型的提升。

结合以上这些工作,识别商品是否类目错放的服务能够达到 98% 以上的精度。搜索查询相关的 badcase 在重点品类上减少了 50% 左右。
3、Item Attribute Recognition
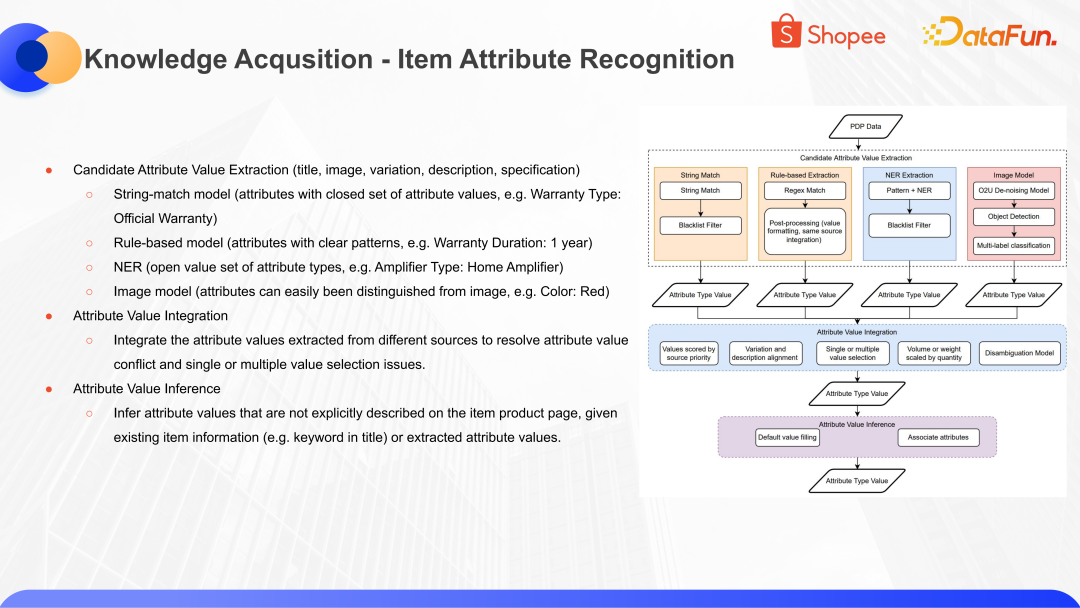
接下来介绍商品属性新增的识别。从上图可以看出,输入商品的信息之后,属性识别基于四种不同的思想:第一种是基于 String-match Model;第二种是基于 Rule-based Model,比如 Warranty Duration: 1 year,这种是符合语料的特征和规则;第三种是基于 NER model 去做属性的识别;第四种是基于Image model,视觉和多模态相关的模型。
基于这四种不同的识别思路,从商品信息中获取到多种可能的属性项和值。对于这些识别到的属性项和值,去做一层属性值整合,结合各种信息优选出置信度较高的项和值。比如学习来源的置信度等等。在学习出了置信度较高的属性值之后,还需要结合属性值之间的关系,补充出商品信息之外推理出的商品知识。

开放集属性值通常会有很多不同的表达,NER 模型比较适合去捕捉商品信息表达中已有的值。所以我们把商品信息属性的识别做了从 NER 模型到 MRC 模型的转换。通过 MRC 的解决思路,我们希望能够使用 Wordpiece tokenizer 去缓解 OOV 的问题,并且通过 LaBse PLM 去解决 multi-lingual 的一些问题,通过 MRC+CRF 完成文本属性和商品属性的识别抽取任务。

识别和抽取出了大量的属性值之后,会发现它的表达各种各样,会存在拼写错误或同义词的现象。就像三星这个案例,都是蓝色,但是会有 “blue” 和 “biru” 不同的表达,我们需要对这些词做归一,这样才能更好地响应下游的应用,并把所有的商品信息转化到标准的信息层,方便下游系统更高效地理解。

接下来我们还需要对这些信息做一层歧义的理解,因为我们发现从商品中抽出的信息会有冲突。比如商品标题信息里面颜色是 “red”,在详情信息里颜色是 “yellow”,“silver” 既可以标识颜色又可以表示材质,“red” 有可能是红色也有可能是红米品牌信息。受到 promat approach 的启发,我们把这一问题转化成了一个 generation task。基于 T5 的模型,上图是整体的流程图,重点是将数据转换成 Template 的格式,做 Encoder 和 Decoder,最终输出想要识别项对应的值。通过对比使用发现 T5 的表现还是不错的,相较于其他的模型有比较大的提升。
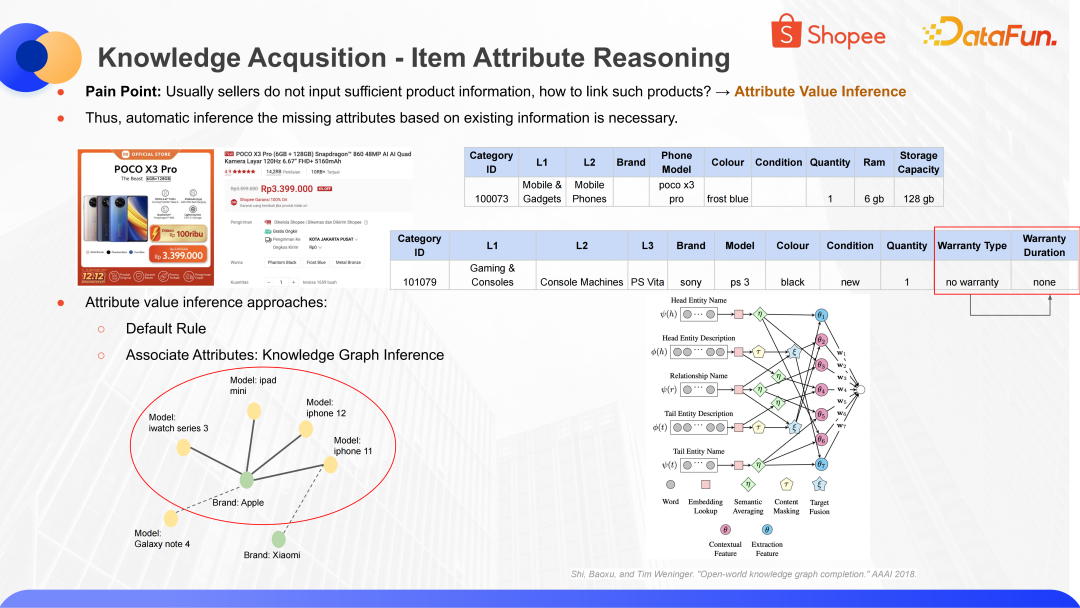
当识别出商品的信息之后,还可以利用这些信息做一些推理。比如保修类型是不保修,那保修时间这一项自然就是 None 了。这种推理可以通过挖掘知识图谱的关联属性去实现。
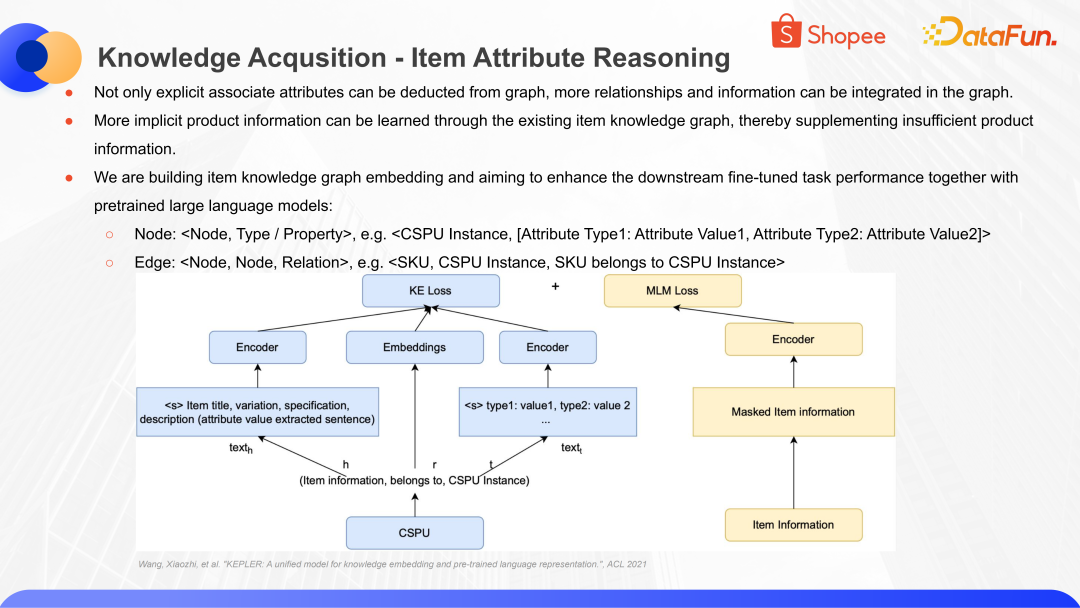
以此类推,不仅可以通过关联属性去补全商品信息,商品图谱包含商品和商品间的关系,商品和属性之间的关系,这些关系之间也可以去做一系列的信息的补全,我们也在此基础之上构建了图谱这样一个体系。
三、知识融合
接下来介绍知识融合的部分,分为本体融合,实体融合和信息融合。
1、Ontology Fusion

本体层融合可以理解为商品本体,比如 Shopee 的商品分类体系和市场上其它分类体系,它们之间可以做映射和关联,包含类目的映射、属性项的映射、属性值的映射。核心思想是有很多原子化的技术模块做支撑,比如在类目的映射关联上,可以基于商品的分类信息汇总到分类体系的映射关系。属性项可以结合相近词,同义词等等,在分类下面再去构建项和值的关联映射关系,这样的关联关系也会结合实际的条件做精度和条件上的限制。
2、Entity Fusion

重点介绍下实体层的融合,在电商层面可以理解为商品之间关系的识别和理解。比如同款商品、相似商品或相关商品。
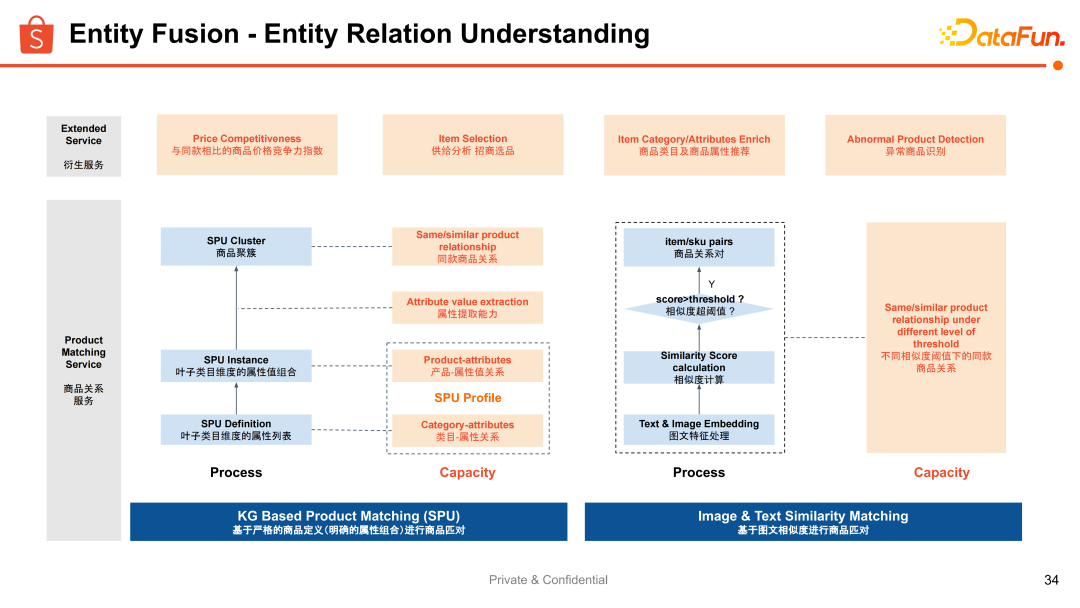
在不同关系的基础算法上,有一些经典的思路,常见的是基于图文相似度的匹配来找到它们的关系。更进一步的是基于商品图谱做商品信息属性项更细粒度的匹配,可以更加业务可解释地去拆解出来商品之间匹配关系的具体要求。比如我们想要知道两个商品是否满足品牌一致、材质一致、颜色一致,还是想要更细粒度或者更粗粒度,这样就更方便业务去定制化使用。
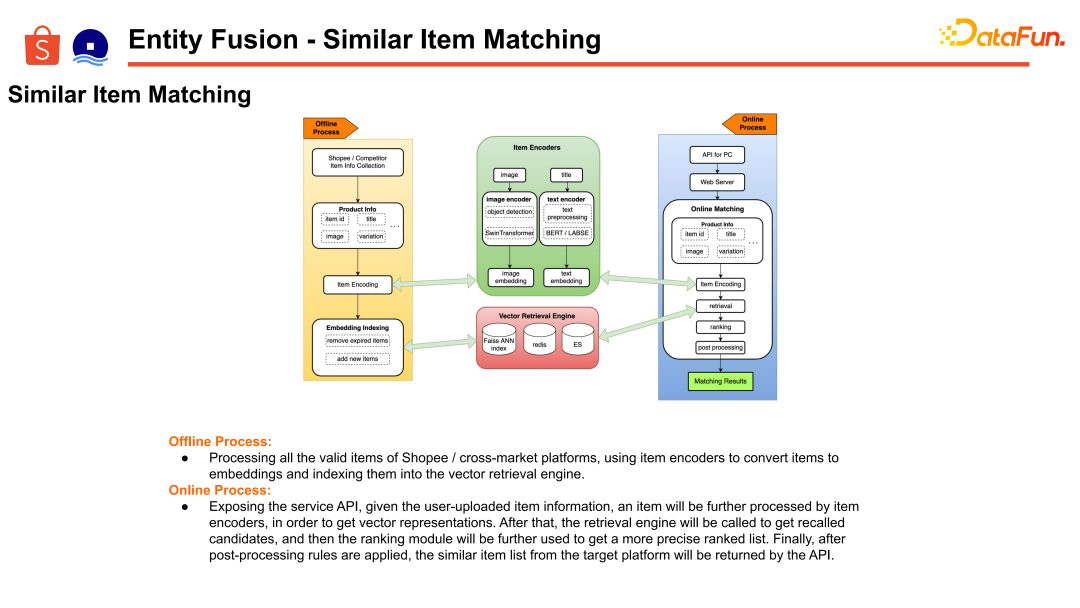
在基于图文相似的匹配上,主要是构建了基于召回排序的框架和方法。结合商品信息做 Embedding 构建,基于图文的 Embedding 去做检索召回和精排,来实现基于相似度的同款关系构建。

在这个基础之上,还希望构建更加精准的基于图谱的属性维度的同款关系,那么就诞生了一个概念:Standard Product Unit(spu) ,就是标准产品节点。从上图可以看出,在每个产品的细粒度分类之下,可以定义商品关系最关注的那些项和值。比如图上的 Apple iPhone 13 Pro 代表了一系列的产品节点,无论任何商家在任何地点售卖的 Apple iPhone 13 Pro 都是同一款产品。当然,这个产品节点还刻有更细粒度。当我们沉淀出这样的产品节点之后,就可以连接所有符合这个产品定义的商品,来实现一个产品粒度的商品聚合。

这样的优势是更加可解释,方便用户和平台内部运营的使用,以及定制不同粒度的聚合体。

整体的框架如上图所示,涉及到定义的细化以及基于定义的分类,属性的抽取,在基于定义的要求结合抽取出来的属性做商品维度的聚合。我们把所有的模块连接起来,就可以实现 SPU 数据资产的生产。最终不仅生产出所有的产品节点而且去连接好所有的商品信息,并且还可以把商品的信息汇到产品维度去实现最终信息层的知识融合。

所以我们就构建出了如上图所示的知识图谱,会有各种各样的产品节点以及对应的分类信息、属性信息,以及各个商品实体的连接。
四、知识应用
接下来再简单介绍下我们一系列的知识应用。

知识应用的服务比较广泛,比如帮助运营理解市场,做商品筛选,商品质量校验;帮助商家在发布的时候做类目的智能化识别,价格推荐,物流信息补全;帮助消费者推荐高性价比的活动会场,以及对搜索推荐做各种智能化支撑。
五、知识图谱展望
最后介绍下对未来知识图谱工作的展望。

从之前的图谱的图可以看出来,我们的商品图谱不只是可以连接到商品和商品属性分类等等这样的信息,还可以进一步拓展和用户、商家以及各个市场平台更高维度的信息的关联,并且实现信息之间精准的互通和推理,基于这样的补全去做更广泛的业务应用。

在当前的 AIGC 时代,大量新技术的诞生冲击着大家的思想,不断有各种各样的大规模语言模型诞生。随着 chatGPT 大模型的突破,AI 的发展已经到达了一定的阶段。chatGPT 的成功证实了,我们如果有足够量的数据和足够大的模型是能够实现较好的知识推理的。在这样的背景之下,做图谱相关工作的人和我们的工作又面临着怎样的发展机遇和挑战呢?
对于大模型而言,它能给图谱提供的帮助效果并不是特别好,并不能达到端到端的需求。特别是在垂直领域,各个公司都有自己的运转模式和业务标准。如上图所示,我们做一个商品细粒度识别,在这个例子中,准确率大概达到 50%,还没有达到 end-to-end 的商业应用的诉求,还需要去做细粒度的子模型的构建。并且大模型的计算在现有的算力消耗上也并不是高性价比的选择,垂直领域的模型依然存在优势。但是大模型可以辅助我们对垂直领域模型的优化,比如对于训练数据的增强、样本生成,能够帮助垂直领域模型快速提升。
在大模型的潮流下,我们也需要思考知识图谱能起到什么样的作用。其实当前的大模型仍然存在着一些问题,比如大模型可能会提供非实时但看似合理的预测,以及在推理能力上对较为复杂的逻辑推理和数学推理还存在进步的空间。知识图谱其实是在推理能力上具备一些优势的,所以未来我们可以去探索,是否可以将知识图谱的结构与现有的方法论做结合,并且与大模型的训练方法做结合。
从当前的应用上来看,New Bing 已经在用搜索引擎去补充和增强 chatGPT-4 的效果了,在一定程度上也减少了知识型的错误。举个例子,对于独特的业务知识,我们是不是可以借助零微调的技术将知识图谱的知识表达作为 prompt 去提示 GPT 大模型,来生成更符合业务场景的答案。当然这只是一些浅层的思路和应用,我相信随着对于模型理解的不断深入,还会有更好的结合方法。