项目简介:Pastebin是一个在线的文本存储平台,让用户可以存储和分享代码片段或者其他类型的文本。它支持多种编程和标记语言的语法高亮,用户可以选择让他们的"paste"公开或私有。无需注册就可以使用,但注册用户可以更方便地管理他们的"paste"。Pastebin常被开发者、系统管理员以及其他技术专业人员用于分享和协作。
现在让我们来设计一个类似Pastebin的网络服务,用户可以在这里储存纯文本。用户可以输入一段文本,并获取一个随机生成的URL来访问这段文本。
类似的产品有:pastebin.com,controlc.com,hastebin.com,privatebin.net
系统难度等级:初级
1、什么是Pastebin
Pastebin及类似服务让用户能够在网络(通常指的是互联网)上存储纯文本或图像,并生成唯一的URL来访问上传的数据。这样的服务也被用来快速地在网络上共享数据,用户只需传递URL,其他用户就可以查看其内容。
如果你以前没有使用过pastebin.com,建议尝试在那里创建一个新的“Paste”,并花些时间浏览他们服务提供的不同选项。这将在理解本章时有很大帮助。
对于类似于Pastebin这样的代码或文本分享平台,中国并未有一款特别知名或广泛使用的网站。很多开发者会使用GitHub Gist来分享代码片段,此外,国内也有一些代码托管平台,比如Coding.net和Gitee,也提供代码分享和协作的功能。
2、系统的需求和目标
Pastebin服务需要满足以下要求:
功能需求:
- 用户应能够上传或“粘贴”他们的数据,并获得一个独特的URL来访问它。
- 用户只能上传文本。
- 数据和链接将在特定的时间段后自动过期;用户应可以指定过期时间。
- 用户可以选择为他们的粘贴内容设置一个自定义的别名。
非功能性需求:
- 系统必须具有高度的可靠性,上传的任何数据都不应丢失。
- 系统必须始终可用。这是因为如果我们的服务暂停,用户将无法访问他们的粘贴内容。
- 用户应能实时访问他们的粘贴内容,延迟要最小。
- 粘贴的链接不能被轻易猜出(不能被预测)。
扩展需求:
- 分析,例如,一个粘贴内容被访问了多少次?
- 我们的服务也应该通过REST APIs供其他服务访问。
3、注意事项
Pastebin与URL缩短服务(系统设计上一个案例)有一些相同的需求,但是我们还应该考虑一些额外的设计因素。
用户每次粘贴的文本量应有何限制?我们可以限制用户不得粘贴超过10MB10MB10MB的数据,以防止服务被滥用。
我们是否应对自定义URL的大小设置限制?由于我们的服务支持自定义URL,用户可以选择他们喜欢的任何URL,但是提供自定义URL并非强制性的。然而,对自定义URL设置大小限制是合理的(而且通常是我们期望的),这样我们可以保持一致的URL数据库。
4、容量估计与约束
我们的服务将是读取密集型的;相比新建Paste,读取请求会更多。我们可以假设读取与写入之间的比例是5:1。
流量预估:Pastebin类似的服务并不预期有如微信或今日头条那样的流量,这里我们假设每天有一百万个新的粘贴内容添加到我们的系统中。这样算来,我们每天有五百万次的读取。
每秒新粘贴内容:
1M / (24 小时 * 3600 秒) ~= 12 粘贴/秒
每秒粘贴读取次数:
5M / (24 小时 * 3600 秒) ~= 58 读取/秒
存储预估:用户最多可以上传10MB的数据;一般来说,Pastebin类似的服务用于分享源代码、配置文件或日志。这些文本并不大,所以我们假设每个粘贴内容平均含有10KB10KB10KB。
按照这个速率,我们每天将存储10GB的数据。
1M * 10KB => 10 GB/天
如果我们想将这些数据存储十年,那我们总共需要36TB的存储容量。
每天有1M的粘贴内容,十年后我们将有36亿的粘贴内容。我们需要生成并存储键来唯一地标识这些粘贴内容。如果我们使用Base64编码([A-Z, a-z, 0-9, ., -]),我们将需要六个字符的字符串:
64^6 ~= 68.7亿个唯一字符串
如果存储一个字符需要一个字节,存储36亿个键所需的总大小将是:
3.6B∗6=>22GB
相比于36TB,22GB微不足道。为了保留一些余量,我们将假设一个70%的容量模型(意味着我们在任何时候都不希望使用超过总存储容量的70%),这将使我们的存储需求增加到 51.4TB。
带宽预估:对于写入请求,我们预计每秒新增12个粘贴内容,导致每秒进入120KB的数据。
12∗10KB=>120KB/s
至于读取请求,我们预计每秒58个请求。因此,总的数据出口(发送给用户)将是0.6MB/s。
58∗10KB=>0.6MB/s
尽管总的进出口并不大,我们在设计服务时应记住这些数字。
内存预估:我们可以缓存一些被频繁访问的热门粘贴内容。根据80-20原则,意味着20%的热门粘贴内容产生了80%的流量,我们希望将这20%的粘贴内容进行缓存。
既然我们每天有500万次的读取请求,要缓存这些请求中的20%,我们需要:
0.2∗5M∗10KB =10GB
因此,我们大约需要10GB的内存来缓存那些热门的粘贴内容。
5、系统API
我们可以有SOAP或REST API来公开我们服务的功能。以下是创建/检索/删除粘贴内容的API定义:
addPaste(api_dev_key, paste_data, custom_url=None user_name=None, paste_name=None, expire_date=None)参数:
api_dev_key (字符串): 已注册帐户的API开发者密钥。这将用于基于分配的配额对用户进行限流等操作。
paste_data (字符串): 粘贴的文本数据。
custom_url (字符串): 可选的自定义URL。
user_name (字符串): 可选的用于生成URL的用户名。
paste_name (字符串): 粘贴内容的可选名称。
expire_date (字符串): 粘贴内容的可选过期日期。
返回: (字符串)
成功插入返回可以访问粘贴内容的URL,否则,它将返回一个错误码。
类似地,我们可以有检索和删除粘贴内容的API:
getPaste(api_dev_key, api_paste_key)其中api_paste_key是一个表示要检索的粘贴内容的粘贴键的字符串。这个API将返回粘贴内容的文本数据。
deletePaste(api_dev_key, api_paste_key)成功删除返回true,否则返回false。
6、数据库设计
关于我们存储的数据性质,我们有一些观察:
- 我们需要存储数十亿条记录。
- 我们存储的每个元数据对象都很小(小于1KB)。
- 我们存储的每个粘贴对象大小适中(可以达到几MB)。
- 记录之间没有关系,除非我们要存储哪个用户创建了哪个粘贴内容。
- 我们的服务主要是读取操作。
数据库架构:
我们需要两个表,一个用于存储粘贴内容的信息,另一个用于存储用户的数据。
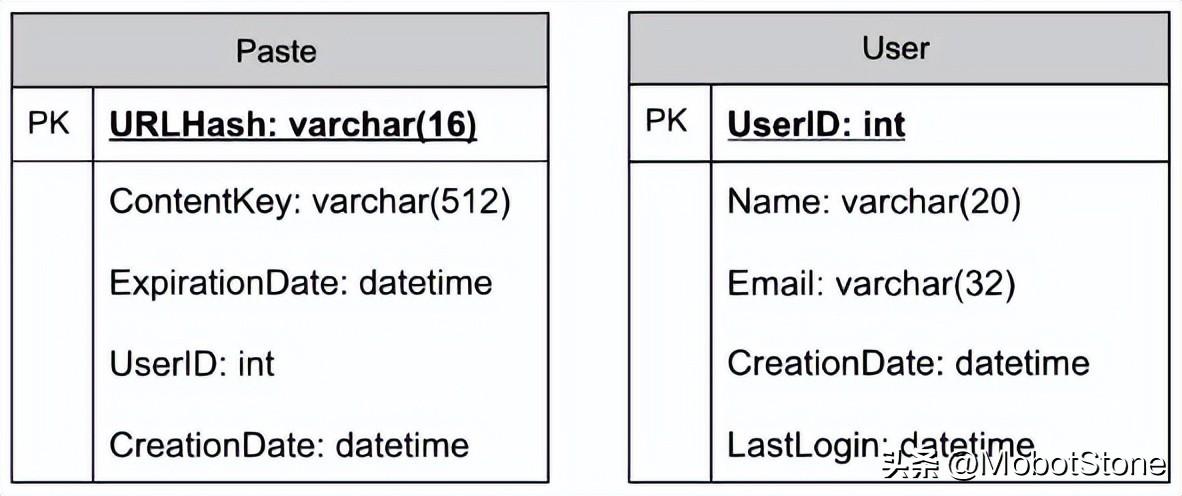
这里,URlHash是TinyURL的URL等效项,ContentKey是指向一个外部对象的引用,该对象存储粘贴内容的内容;我们将在本章后面讨论粘贴内容的外部存储。
7、顶层设计
在顶层设计上,我们需要一个应用层来处理所有的读取和写入请求。应用层将与存储层进行通信,以存储和检索数据。我们可以将存储层划分为两部分,一部分数据库存储与每个粘贴内容、用户等相关的元数据,另一部分将粘贴内容存储在某些对象存储中(如阿里云OSS)。这种数据的划分也允许我们单独进行扩展。

8、组件设计
A. 应用层
我们的应用层将处理所有的进出请求。应用服务器将与后端数据存储组件进行通信以服务这些请求。
如何处理写入请求?在收到写入请求后,我们的应用服务器将生成一个六位随机字符串,这将作为粘贴的键(如果用户没有提供自定义键)。然后,应用服务器将粘贴的内容和生成的键存储在数据库中。成功插入后,服务器可以将键返回给用户。这里可能存在的一个问题是由于键重复而导致插入失败。由于我们是生成一个随机键,所以新生成的键可能与现有的键相匹配。在这种情况下,我们应该重新生成一个新的键并再试一次。我们应该一直重试,直到我们不再因为重复键看到失败。如果用户提供的自定义键已经在我们的数据库中存在,我们应该向用户返回一个错误。
上述问题的另一种解决方案可能是运行一个独立的键生成服务(KGS),它提前生成随机的六位字符串,并将它们存储在数据库中(我们称之为key-DB)。每当我们想要存储一个新的粘贴,我们只需要取一个已经生成的键并使用它。这种方法将使事情变得非常简单和快速,因为我们不会担心重复或碰撞。KGS将确保所有插入key-DB的键都是唯一的。
KGS可以使用两个表来存储键,一个用于尚未使用的键,一个用于所有已使用的键。一旦KGS向应用服务器提供了一些键,它可以将这些移动到已使用的键表中。KGS可以始终在内存中保持一些键,以便每当服务器需要它们时,它可以快速提供。一旦KGS在内存中加载了一些键,它就可以将它们移动到已使用的键表中;这样我们就可以确保每个服务器获取到的键都是唯一的。如果KGS在使用所有加载到内存中的键之前死掉,我们将浪费这些键。我们可以忽略这些键,因为我们有大量的键。
KGS会出现单点故障吗?会的。为了解决这个问题,我们可以有一个备用的KGS副本,每当主服务器死掉时,它可以接管来生成和提供键。
每个应用服务器可以从key-DB中缓存一些键吗?是的,这肯定可以加快速度。虽然在这种情况下,如果应用服务器在消费所有键之前死掉,我们将最终丢失那些键。这可能是可以接受的,因为我们有68B个唯一的六位字母键,这比我们需要的要多得多。
如何处理粘贴读取请求?在收到读取粘贴请求后,应用服务层联系数据存储。数据存储搜索键,如果找到了,就返回粘贴的内容。否则,返回一个错误码。
B. 数据存储层
我们可以将我们的数据存储层分为两部分:
- 元数据数据库:我们可以使用像MySQL这样的关系数据库,或者像Dynamo或Cassandra这样的分布式Key-Value存储。
- 对象存储:我们可以将我们的内容存储在像阿里云OSS这样的对象存储中。每当我们感觉到我们的内容存储容量已经满了,我们可以通过平台直接扩容。

9、数据分区和复制
为了扩展我们的数据库,我们需要对其进行分区,以便它能存储数十亿个URL的信息。因此,我们需要设计一个分区方案,将我们的数据划分并存储到不同的数据库中。
A. 基于范围的分区:我们可以根据哈希键的第一个字母在不同的分区中存储URL。因此,我们将所有以字母“A”(和“a”)开头的URL哈希键存储在一个分区中,将以字母“B”开头的URL存储在另一个分区中,以此类推。这种方法被称为基于范围的分区。我们甚至可以将某些出现频率较低的字母组合到一个数据库分区中。因此,我们应开发一个静态分区方案,始终以可预测的方式存储/查找URL。
这种方法的主要问题是可能导致数据库服务器不平衡。例如,我们决定将所有以字母“E”开头的URL放入一个数据库分区,但后来我们发现以字母“E”开头的URL过多。
B. 基于哈希的分区:在这种方案中,我们对存储的对象进行哈希。然后,我们根据哈希值计算使用哪个分区。在我们的情况下,我们可以获取key或短链接的哈希值,以确定我们存储数据对象的分区。
我们的哈希函数将随机地将URL分配到不同的分区(例如,我们的哈希函数可以始终将任何key映射到[1...256]之间的一个数字)。这个数字将表示我们存储对象的分区。
这种方法仍然可能导致分区负载过大,这可以通过使用'一致性哈希'来解决。
10、缓存
我们可以缓存频繁访问的URL。我们可以使用任何现成的解决方案,比如Memcached,它可以存储完整的URL及其对应的哈希值。因此,应用服务器在访问后端存储之前,可以快速检查缓存是否有所需的URL。
我们应该有多少缓存内存?我们可以从日流量的20%开始,根据客户的使用模式,我们可以调整需要多少缓存服务器。如上所估计,我们需要170GB的内存来缓存日流量的20%。目前的一些服务器可以拥有256GB的内存,我们可以轻松将所有缓存放入一台机器。或者,我们可以使用几台小一点的服务器来存储所有这些热门URL。
哪种缓存驱逐策略最适合我们的需求?当缓存满了,我们想用一个新的/更热门的URL替换一个链接,我们应该如何选择?最近最少使用(LRU)可能是我们系统的一个合理策略。根据这个策略,我们首先丢弃最近最少使用的URL。我们可以使用Linked Hash Map或类似的数据结构来存储我们的URL和哈希值,这也会记录最近访问过的URL。
为了进一步提高效率,我们可以复制我们的缓存服务器来分配它们之间的负载。
每个缓存副本如何更新?每当有一个缓存未命中,我们的服务器会访问后端数据库。当这种情况发生,我们可以更新缓存,并将新的条目传递给所有的缓存副本。每个副本都可以通过添加新的条目来更新其缓存。如果副本已经有了该条目,它可以简单地忽略它。

11、负载均衡(LB)
我们可以在系统中的三个位置添加负载均衡层:
- 客户端与应用服务器之间
- 应用服务器与数据库服务器之间
- 应用服务器与缓存服务器之间
最初,我们可以使用一个简单的轮询方法,将进入的请求均等地分配到后端服务器。这种负载均衡方法简单易行,不会引入任何额外的开销。这种方法的另一个优点是,如果一个服务器死机,负载均衡器会将其从轮询中移除,停止向其发送任何流量。
轮询负载均衡的一个问题是,我们没有考虑到服务器的负载。如果一个服务器过载或运行缓慢,负载均衡器不会停止向该服务器发送新的请求。为了处理这个问题,我们可以放置一个更优的负载均衡解决方案,它定期查询后端服务器的负载,并根据负载情况调整流量。
12、清除或数据库清理
key条目是否应永久存在,还是应该被清除?如果达到用户设定的过期时间,链接应该怎么处理?
如果我们选择持续寻找过期链接并将其删除,这将对我们的数据库产生很大压力。相反,我们可以慢慢地删除过期的链接,进行懒人清理。我们的服务将确保只删除过期的链接,尽管有些过期链接可能会存在更长时间,但永远不会被返回给用户。
- 每当用户试图访问一个已过期的链接,我们可以删除该链接并向用户返回错误。
- 我们可以设置一个单独的清理服务,定期从我们的存储和缓存中删除过期的链接。这个服务需要非常轻量,只在预计用户流量较低的时候运行。
- 我们可以为每个链接设定一个默认的过期时间(例如两年)。
- 删除过期链接后,我们可以将该Key重新放回Key-DB,以供重复使用。
- 我们是否应删除一段时间(比如说六个月)内没有被访问过的链接?这可能有点不合适。由于存储成本越来越低,我们可以决定永久保存链接。

13、数据跟踪
我们如何统计短链接被使用的次数、用户的位置等信息?我们如何储存这些统计信息?如果它是数据库中的一部分,每次查看都需要更新,那么当一个流行的短链接被大量并发请求瞬间涌入时,会发生什么?
一些值得追踪的统计数据:访客的国家、访问的日期和时间、引导点击的网页、访问页面的浏览器或平台。
14、安全和权限
用户能否创建私有URL或者允许特定的用户组访问某个URL?
我们可以在数据库中每个URL的条目里存储访问权限级别(公开/私有)。我们也可以创建一个单独的表来存储有权访问特定URL的用户的UserID。如果一个用户没有权限但试图访问一个URL,我们可以返回一个错误(HTTP 401)。考虑到我们的数据储存在一个类似Cassandra的NoSQL宽列数据库中,储存权限的表的key将是‘哈希值’(或KGS生成的key)。列将储存有权查看URL的用户的UserID。